mask rcnn训练基于labelme生成的数据集
发布时间:2023年12月22日
1.下载mask rcnn源码
此处使用的mask rcnn源码来自于B站博主霹雳吧啦Wz
2.安装labelme
sudo apt install python3-pyqt5
pip install labelme
如果运行出现QT的错误,可能是与我一样遇到自己装了C++版本的QT
解决:运行命令 unset LD_LIBRARY_PATH
2.使用labelme对自己的图片进行标注
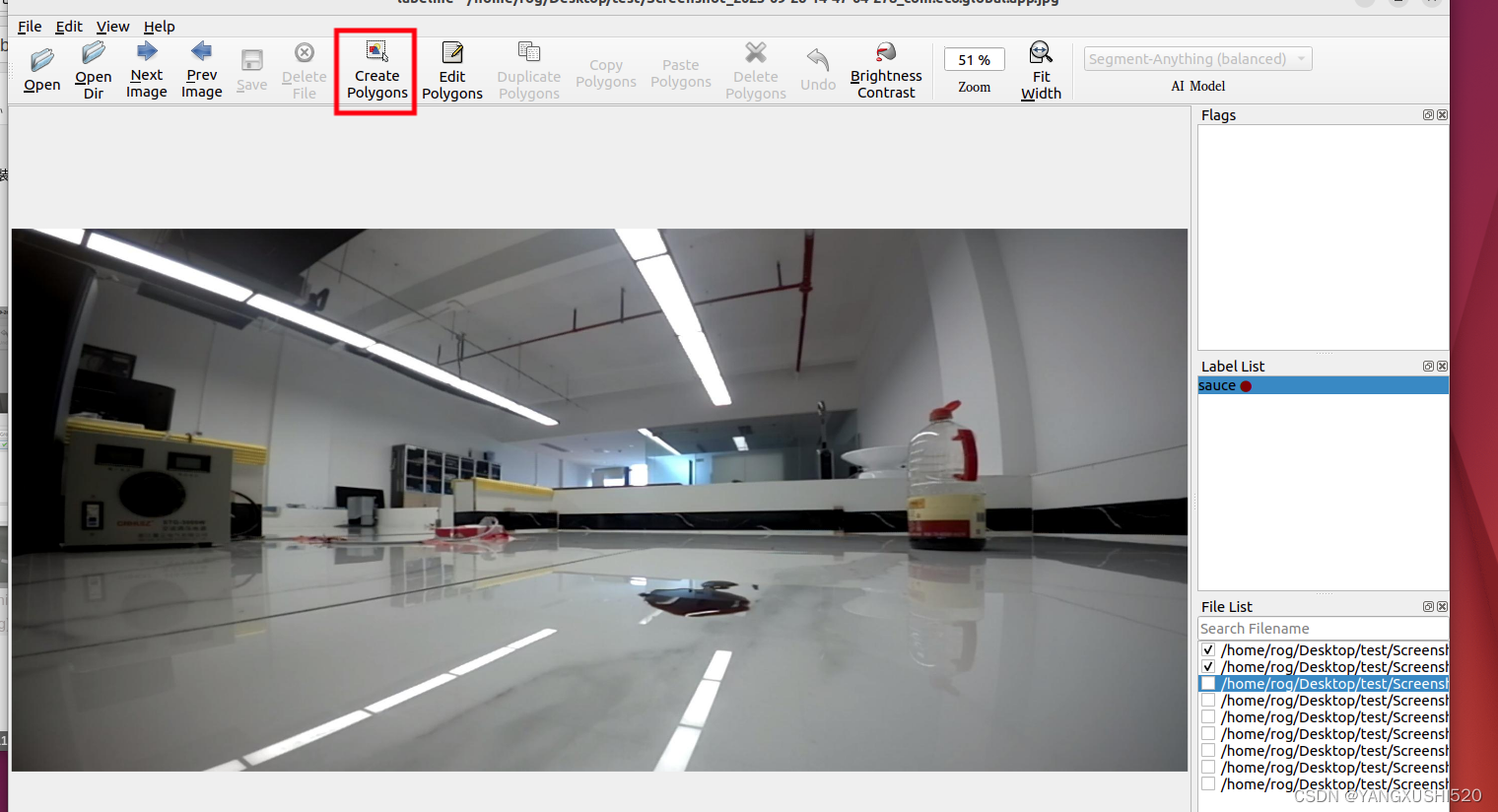
2.1 使用labelme打开自己的图片文件夹,点击如下的选项进行标注
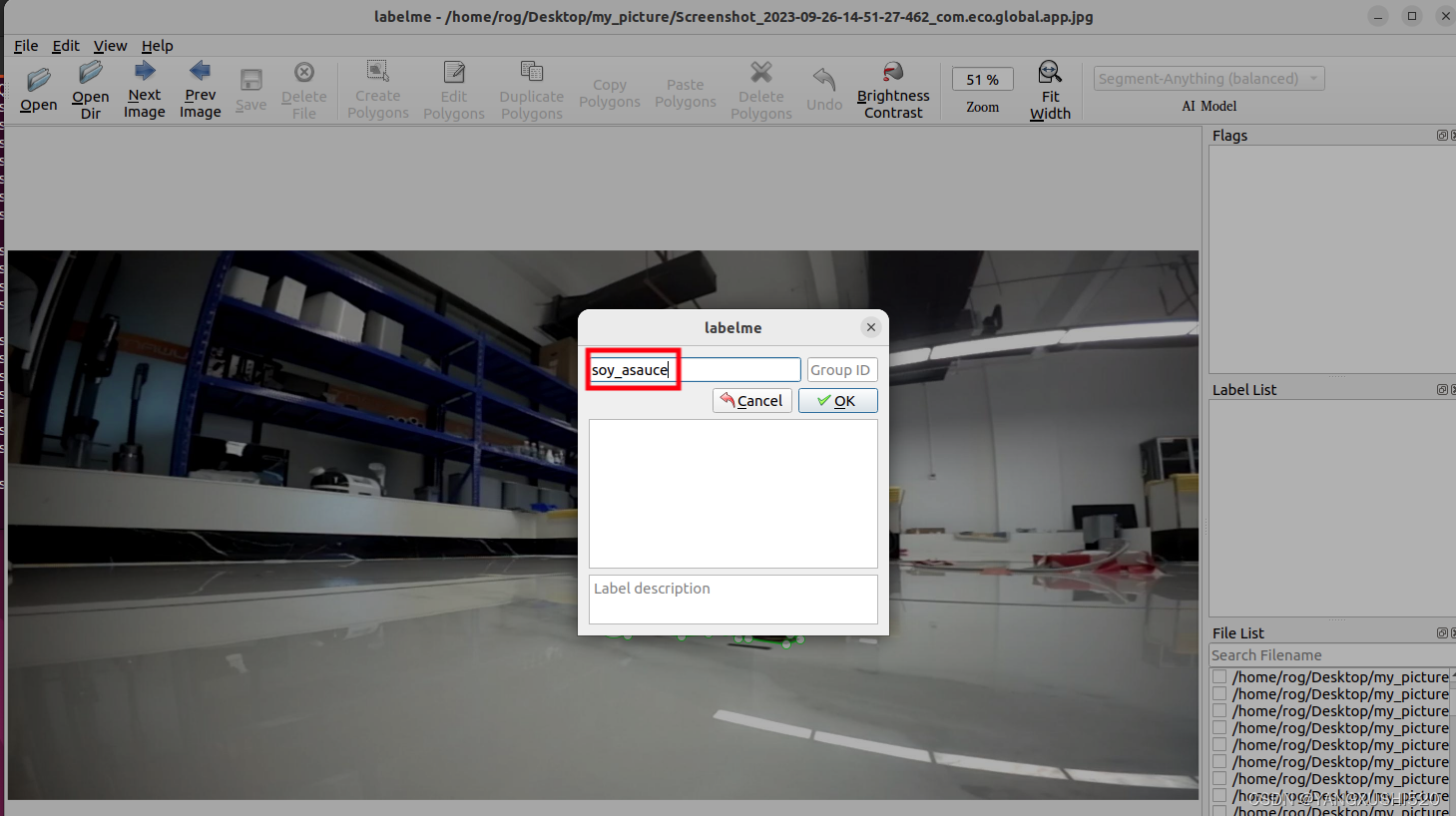
 2.2 标注完输入类别名
2.2 标注完输入类别名
2.3 点击保存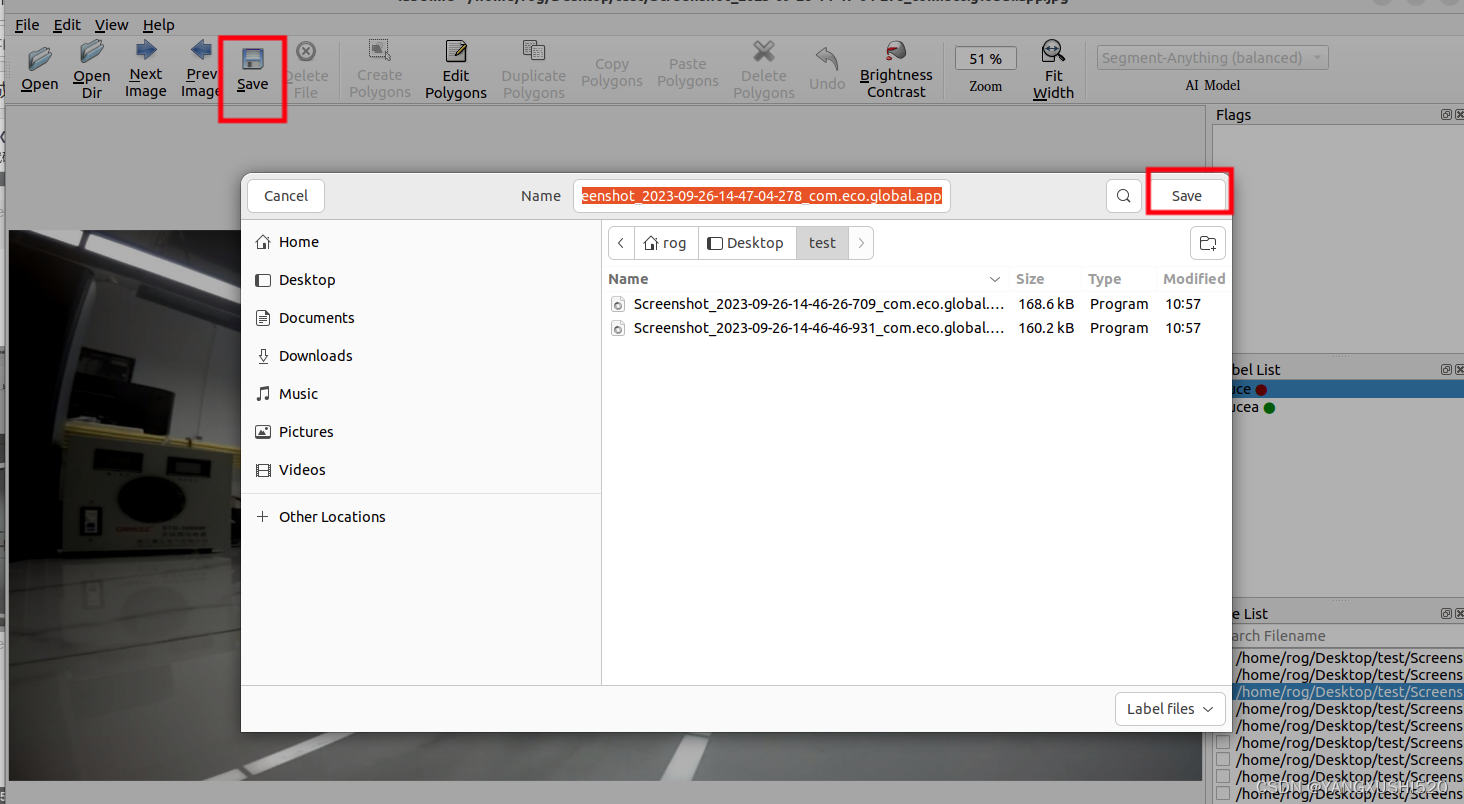
3.将labelme标注的数据格式转换为coco格式
转换代码提供如下:(参考:https://blog.csdn.net/qq_40243750/article/details/129843910)
在转换前先创建转换输出的文件夹 coco_test 在该文件夹下创建 annotations train val
mkdir coco_test
mkdir coco_test/annotations
mkdir coco_test/train
mkdir coco_test/val
执行转换命令:
python tools_x2coco.py --dataset_type labelme --json_input_dir ./image --image_input_dir ./image --output_dir ./coco_test --train_proportion 0.8 --val_proportion 0.2 --test_proportion 0.0
参数解释:
dataset_type:是将labelme转为coco,锁着这里默认就是labelme
json_input_dir:指向labelme的json文件所在路径
image_input_dir:指向labelme的img文件所在路径(在这里json和img都是相同的路径)
output_dir :转为coco后输出的文件夹路径
train_proportion、val_proportion、test_proportion:划分数据集比例,总之三者之和必须为1
#!/usr/bin/env python
# coding: utf-8
# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# 参考:https://blog.csdn.net/qq_40243750/article/details/129843910
import argparse
import glob
import json
import os
import os.path as osp
import shutil
import xml.etree.ElementTree as ET
import numpy as np
import PIL.ImageDraw
from tqdm import tqdm
import cv2
label_to_num = {}
categories_list = []
labels_list = []
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
def images_labelme(data, num):
image = {}
image['height'] = data['imageHeight']
image['width'] = data['imageWidth']
image['id'] = num + 1
if '\\' in data['imagePath']:
image['file_name'] = data['imagePath'].split('\\')[-1]
else:
image['file_name'] = data['imagePath'].split('/')[-1]
return image
def images_cityscape(data, num, img_file):
image = {}
image['height'] = data['imgHeight']
image['width'] = data['imgWidth']
image['id'] = num + 1
image['file_name'] = img_file
return image
def categories(label, labels_list):
category = {}
category['supercategory'] = 'component'
category['id'] = len(labels_list) + 1
category['name'] = label
return category
def annotations_rectangle(points, label, image_num, object_num, label_to_num):
annotation = {}
seg_points = np.asarray(points).copy()
seg_points[1, :] = np.asarray(points)[2, :]
seg_points[2, :] = np.asarray(points)[1, :]
annotation['segmentation'] = [list(seg_points.flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = image_num + 1
annotation['bbox'] = list(
map(float, [
points[0][0], points[0][1], points[1][0] - points[0][0], points[1][
1] - points[0][1]
]))
annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3]
annotation['category_id'] = label_to_num[label]
annotation['id'] = object_num + 1
return annotation
def annotations_polygon(height, width, points, label, image_num, object_num,
label_to_num):
annotation = {}
annotation['segmentation'] = [list(np.asarray(points).flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = image_num + 1
annotation['bbox'] = list(map(float, get_bbox(height, width, points)))
annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3]
annotation['category_id'] = label_to_num[label]
annotation['id'] = object_num + 1
return annotation
def get_bbox(height, width, points):
polygons = points
mask = np.zeros([height, width], dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
left_top_r = np.min(rows)
left_top_c = np.min(clos)
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
return [
left_top_c, left_top_r, right_bottom_c - left_top_c,
right_bottom_r - left_top_r
]
def deal_json(ds_type, img_path, json_path):
data_coco = {}
images_list = []
annotations_list = []
image_num = -1
object_num = -1
for img_file in os.listdir(img_path):
img_label = os.path.splitext(img_file)[0]
if img_file.split('.')[
-1] not in ['bmp', 'jpg', 'jpeg', 'png', 'JPEG', 'JPG', 'PNG']:
continue
label_file = osp.join(json_path, img_label + '.json')
print('Generating dataset from:', label_file)
image_num = image_num + 1
with open(label_file) as f:
data = json.load(f)
if ds_type == 'labelme':
images_list.append(images_labelme(data, image_num))
elif ds_type == 'cityscape':
images_list.append(images_cityscape(data, image_num, img_file))
if ds_type == 'labelme':
for shapes in data['shapes']:
object_num = object_num + 1
label = shapes['label']
if label not in labels_list:
categories_list.append(categories(label, labels_list))
labels_list.append(label)
label_to_num[label] = len(labels_list)
p_type = shapes['shape_type']
if p_type == 'polygon':
points = shapes['points']
annotations_list.append(
annotations_polygon(data['imageHeight'], data[
'imageWidth'], points, label, image_num,
object_num, label_to_num))
if p_type == 'rectangle':
(x1, y1), (x2, y2) = shapes['points']
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [[x1, y1], [x2, y2], [x1, y2], [x2, y1]]
annotations_list.append(
annotations_rectangle(points, label, image_num,
object_num, label_to_num))
elif ds_type == 'cityscape':
for shapes in data['objects']:
object_num = object_num + 1
label = shapes['label']
if label not in labels_list:
categories_list.append(categories(label, labels_list))
labels_list.append(label)
label_to_num[label] = len(labels_list)
points = shapes['polygon']
annotations_list.append(
annotations_polygon(data['imgHeight'], data[
'imgWidth'], points, label, image_num, object_num,
label_to_num))
data_coco['images'] = images_list
data_coco['categories'] = categories_list
data_coco['annotations'] = annotations_list
return data_coco
def voc_get_label_anno(ann_dir_path, ann_ids_path, labels_path):
with open(labels_path, 'r') as f:
labels_str = f.read().split()
labels_ids = list(range(1, len(labels_str) + 1))
with open(ann_ids_path, 'r') as f:
ann_ids = [lin.strip().split(' ')[-1] for lin in f.readlines()]
ann_paths = []
for aid in ann_ids:
if aid.endswith('xml'):
ann_path = os.path.join(ann_dir_path, aid)
else:
ann_path = os.path.join(ann_dir_path, aid + '.xml')
ann_paths.append(ann_path)
return dict(zip(labels_str, labels_ids)), ann_paths
def voc_get_image_info(annotation_root, im_id):
filename = annotation_root.findtext('filename')
assert filename is not None
img_name = os.path.basename(filename)
size = annotation_root.find('size')
width = float(size.findtext('width'))
height = float(size.findtext('height'))
image_info = {
'file_name': filename,
'height': height,
'width': width,
'id': im_id
}
return image_info
def voc_get_coco_annotation(obj, label2id):
label = obj.findtext('name')
assert label in label2id, "label is not in label2id."
category_id = label2id[label]
bndbox = obj.find('bndbox')
xmin = float(bndbox.findtext('xmin'))
ymin = float(bndbox.findtext('ymin'))
xmax = float(bndbox.findtext('xmax'))
ymax = float(bndbox.findtext('ymax'))
assert xmax > xmin and ymax > ymin, "Box size error."
o_width = xmax - xmin
o_height = ymax - ymin
anno = {
'area': o_width * o_height,
'iscrowd': 0,
'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id,
'ignore': 0,
}
return anno
def voc_xmls_to_cocojson(annotation_paths, label2id, output_dir, output_file):
output_json_dict = {
"images": [],
"type": "instances",
"annotations": [],
"categories": []
}
bnd_id = 1 # bounding box start id
im_id = 0
print('Start converting !')
for a_path in tqdm(annotation_paths):
# Read annotation xml
ann_tree = ET.parse(a_path)
ann_root = ann_tree.getroot()
img_info = voc_get_image_info(ann_root, im_id)
output_json_dict['images'].append(img_info)
for obj in ann_root.findall('object'):
ann = voc_get_coco_annotation(obj=obj, label2id=label2id)
ann.update({'image_id': im_id, 'id': bnd_id})
output_json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
im_id += 1
for label, label_id in label2id.items():
category_info = {'supercategory': 'none', 'id': label_id, 'name': label}
output_json_dict['categories'].append(category_info)
output_file = os.path.join(output_dir, output_file)
with open(output_file, 'w') as f:
output_json = json.dumps(output_json_dict)
f.write(output_json)
def widerface_to_cocojson(root_path):
train_gt_txt = os.path.join(root_path, "wider_face_split", "wider_face_train_bbx_gt.txt")
val_gt_txt = os.path.join(root_path, "wider_face_split", "wider_face_val_bbx_gt.txt")
train_img_dir = os.path.join(root_path, "WIDER_train", "images")
val_img_dir = os.path.join(root_path, "WIDER_val", "images")
assert train_gt_txt
assert val_gt_txt
assert train_img_dir
assert val_img_dir
save_path = os.path.join(root_path, "widerface_train.json")
widerface_convert(train_gt_txt, train_img_dir, save_path)
print("Wider Face train dataset converts sucess, the json path: {}".format(save_path))
save_path = os.path.join(root_path, "widerface_val.json")
widerface_convert(val_gt_txt, val_img_dir, save_path)
print("Wider Face val dataset converts sucess, the json path: {}".format(save_path))
def widerface_convert(gt_txt, img_dir, save_path):
output_json_dict = {
"images": [],
"type": "instances",
"annotations": [],
"categories": [{'supercategory': 'none', 'id': 0, 'name': "human_face"}]
}
bnd_id = 1 # bounding box start id
im_id = 0
print('Start converting !')
with open(gt_txt) as fd:
lines = fd.readlines()
i = 0
while i < len(lines):
image_name = lines[i].strip()
bbox_num = int(lines[i + 1].strip())
i += 2
img_info = get_widerface_image_info(img_dir, image_name, im_id)
if img_info:
output_json_dict["images"].append(img_info)
for j in range(i, i + bbox_num):
anno = get_widerface_ann_info(lines[j])
anno.update({'image_id': im_id, 'id': bnd_id})
output_json_dict['annotations'].append(anno)
bnd_id += 1
else:
print("The image dose not exist: {}".format(os.path.join(img_dir, image_name)))
bbox_num = 1 if bbox_num == 0 else bbox_num
i += bbox_num
im_id += 1
with open(save_path, 'w') as f:
output_json = json.dumps(output_json_dict)
f.write(output_json)
def get_widerface_image_info(img_root, img_relative_path, img_id):
image_info = {}
save_path = os.path.join(img_root, img_relative_path)
if os.path.exists(save_path):
img = cv2.imread(save_path)
image_info["file_name"] = os.path.join(os.path.basename(
os.path.dirname(img_root)), os.path.basename(img_root),
img_relative_path)
image_info["height"] = img.shape[0]
image_info["width"] = img.shape[1]
image_info["id"] = img_id
return image_info
def get_widerface_ann_info(info):
info = [int(x) for x in info.strip().split()]
anno = {
'area': info[2] * info[3],
'iscrowd': 0,
'bbox': [info[0], info[1], info[2], info[3]],
'category_id': 0,
'ignore': 0,
'blur': info[4],
'expression': info[5],
'illumination': info[6],
'invalid': info[7],
'occlusion': info[8],
'pose': info[9]
}
return anno
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
'--dataset_type',
help='the type of dataset, can be `voc`, `widerface`, `labelme` or `cityscape`')
parser.add_argument('--json_input_dir', help='input annotated directory')
parser.add_argument('--image_input_dir', help='image directory')
parser.add_argument(
'--output_dir', help='output dataset directory', default='./')
parser.add_argument(
'--train_proportion',
help='the proportion of train dataset',
type=float,
default=1.0)
parser.add_argument(
'--val_proportion',
help='the proportion of validation dataset',
type=float,
default=0.0)
parser.add_argument(
'--test_proportion',
help='the proportion of test dataset',
type=float,
default=0.0)
parser.add_argument(
'--voc_anno_dir',
help='In Voc format dataset, path to annotation files directory.',
type=str,
default=None)
parser.add_argument(
'--voc_anno_list',
help='In Voc format dataset, path to annotation files ids list.',
type=str,
default=None)
parser.add_argument(
'--voc_label_list',
help='In Voc format dataset, path to label list. The content of each line is a category.',
type=str,
default=None)
parser.add_argument(
'--voc_out_name',
type=str,
default='voc.json',
help='In Voc format dataset, path to output json file')
parser.add_argument(
'--widerface_root_dir',
help='The root_path for wider face dataset, which contains `wider_face_split`, `WIDER_train` and `WIDER_val`.And the json file will save in this path',
type=str,
default=None)
args = parser.parse_args()
try:
assert args.dataset_type in ['voc', 'labelme', 'cityscape', 'widerface']
except AssertionError as e:
print(
'Now only support the voc, cityscape dataset and labelme dataset!!')
os._exit(0)
if args.dataset_type == 'voc':
assert args.voc_anno_dir and args.voc_anno_list and args.voc_label_list
label2id, ann_paths = voc_get_label_anno(
args.voc_anno_dir, args.voc_anno_list, args.voc_label_list)
voc_xmls_to_cocojson(
annotation_paths=ann_paths,
label2id=label2id,
output_dir=args.output_dir,
output_file=args.voc_out_name)
elif args.dataset_type == "widerface":
assert args.widerface_root_dir
widerface_to_cocojson(args.widerface_root_dir)
else:
try:
assert os.path.exists(args.json_input_dir)
except AssertionError as e:
print('The json folder does not exist!')
os._exit(0)
try:
assert os.path.exists(args.image_input_dir)
except AssertionError as e:
print('The image folder does not exist!')
os._exit(0)
try:
assert abs(args.train_proportion + args.val_proportion \
+ args.test_proportion - 1.0) < 1e-5
except AssertionError as e:
print(
'The sum of pqoportion of training, validation and test datase must be 1!'
)
os._exit(0)
# Allocate the dataset.
total_num = len(glob.glob(osp.join(args.json_input_dir, '*.json')))
if args.train_proportion != 0:
train_num = int(total_num * args.train_proportion)
out_dir = args.output_dir + '/train'
if not os.path.exists(out_dir):
os.makedirs(out_dir)
else:
train_num = 0
if args.val_proportion == 0.0:
val_num = 0
test_num = total_num - train_num
out_dir = args.output_dir + '/test'
if args.test_proportion != 0.0 and not os.path.exists(out_dir):
os.makedirs(out_dir)
else:
val_num = int(total_num * args.val_proportion)
test_num = total_num - train_num - val_num
val_out_dir = args.output_dir + '/val'
if not os.path.exists(val_out_dir):
os.makedirs(val_out_dir)
test_out_dir = args.output_dir + '/test'
if args.test_proportion != 0.0 and not os.path.exists(test_out_dir):
os.makedirs(test_out_dir)
count = 1
for img_name in os.listdir(args.image_input_dir):
if count <= train_num:
if osp.exists(args.output_dir + '/train/'):
shutil.copyfile(
osp.join(args.image_input_dir, img_name),
osp.join(args.output_dir + '/train/', img_name))
else:
if count <= train_num + val_num:
if osp.exists(args.output_dir + '/val/'):
shutil.copyfile(
osp.join(args.image_input_dir, img_name),
osp.join(args.output_dir + '/val/', img_name))
else:
if osp.exists(args.output_dir + '/test/'):
shutil.copyfile(
osp.join(args.image_input_dir, img_name),
osp.join(args.output_dir + '/test/', img_name))
count = count + 1
# Deal with the json files.
if not os.path.exists(args.output_dir + '/annotations'):
os.makedirs(args.output_dir + '/annotations')
if args.train_proportion != 0:
train_data_coco = deal_json(args.dataset_type,
args.output_dir + '/train',
args.json_input_dir)
train_json_path = osp.join(args.output_dir + '/annotations',
'instance_train.json')
json.dump(
train_data_coco,
open(train_json_path, 'w'),
indent=4,
cls=MyEncoder)
if args.val_proportion != 0:
val_data_coco = deal_json(args.dataset_type,
args.output_dir + '/val',
args.json_input_dir)
val_json_path = osp.join(args.output_dir + '/annotations',
'instance_val.json')
json.dump(
val_data_coco,
open(val_json_path, 'w'),
indent=4,
cls=MyEncoder)
if args.test_proportion != 0:
test_data_coco = deal_json(args.dataset_type,
args.output_dir + '/test',
args.json_input_dir)
test_json_path = osp.join(args.output_dir + '/annotations',
'instance_test.json')
json.dump(
test_data_coco,
open(test_json_path, 'w'),
indent=4,
cls=MyEncoder)
if __name__ == '__main__':
"""
python tools/x2coco.py \
--dataset_type labelme \
--json_input_dir ./image/ \
--image_input_dir ./image/ \
--output_dir ./mycoco/ \
--train_proportion 0.8 \
--val_proportion 0.2 \
--test_proportion 0.0
"""
main()
转换结束,可以看到coco_test/annotations coco_test/train coco_test/val 三个文件夹下都有coco格式数据了

4.修改mask rcnn源码训练生成的coco数据集
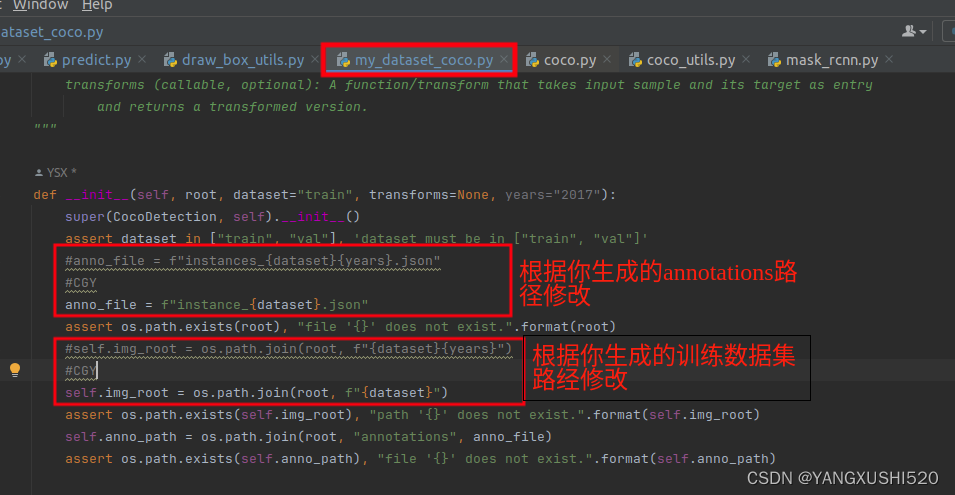

比如我转换后的数据集路径:
 不载入预训练权重、
不载入预训练权重、
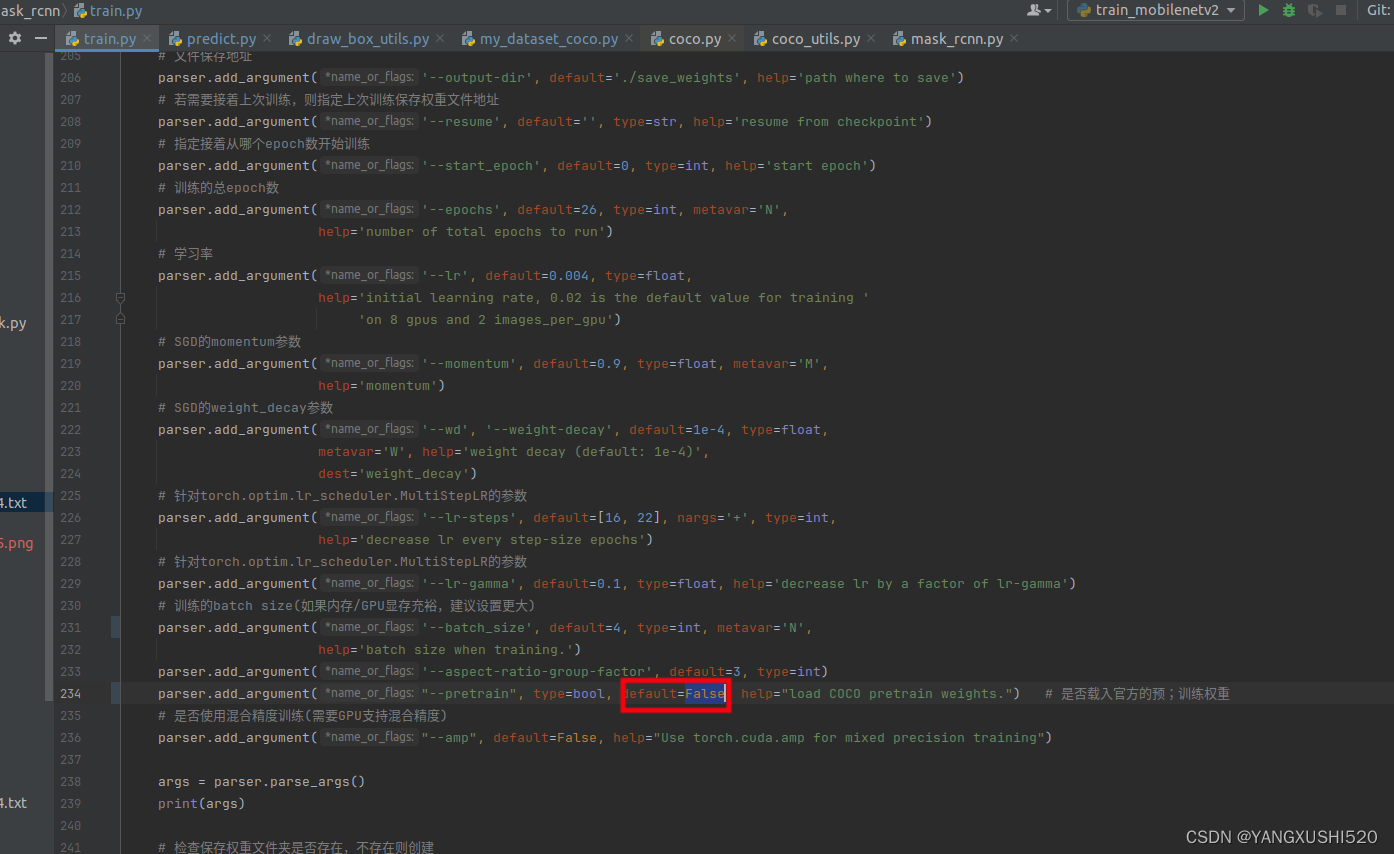
预测修改:

完!
文章来源:https://blog.csdn.net/yangshixu520/article/details/135145678
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 探索 Coinbase 二层链 Base 的潜力与风险
- 如何利用docker来部署war包项目
- QT下载、安装详细教程[Qt5.15及Qt6在线安装,附带下载链接]
- IDEA 修改 jdk 版本
- 两数之和 ? 三数之和? 四数之和? 统统搞定
- 医疗行业信息化发展趋势
- 7.7复原IP地址(LC93-M)
- python+pytest接口自动化测试之参数关联
- 网络安全(黑客)自学
- [Flutter]WindowsPlatform上运行遇到的问题总结