目标检测-Two Stage-RCNN
前言
在前文:目标检测之序章-类别、必读论文和算法对比(实时更新)已经提到传统的目标检测算法的基本流程:
图像预处理 => 寻找候选区 => 特征提取 => 分类器分类 => 后处理
传统目标检测的主要问题是:
- 1)寻找候选区的方法缺陷:基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余,速度慢
- 2)手工设计的特征对于多样性的变化没有很好的鲁棒性
2012年,卷积神经网络(CNN)开始大放异彩,开启了基于深度学习算法图像分类的热潮。
2014年,RBG(Ross B. Girshick)使用Region Proposal + CNN代替传统目标检测使用的滑动窗口+手工设计特征,设计了R-CNN框架,使得目标检测取得巨大突破,并开启了基于深度学习目标检测的热潮。
为了解决上述传统目标检测需要遍历图像的缺陷,出现了候选区域(Region Proposal)法:即利用图像中的纹理、边缘、颜色等信息,预先找出图中可能含有物体的候选区域/框,可以保证在选取较少窗口(几千甚至几百)的情况下保持较高的召回率(Recall),文中使用的是Selective Search候选区域法。
R-CNN在PASCAL VOC 2010上实现了53.7%的平均精度(mAP),并在VOC 2011/12 test(测试集)中实现了类似的性能(53.3% mAP)
提示:以下是本篇文章正文内容,下面内容可供参考
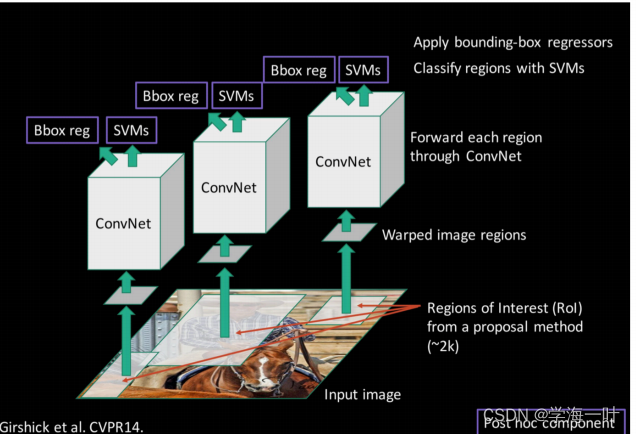
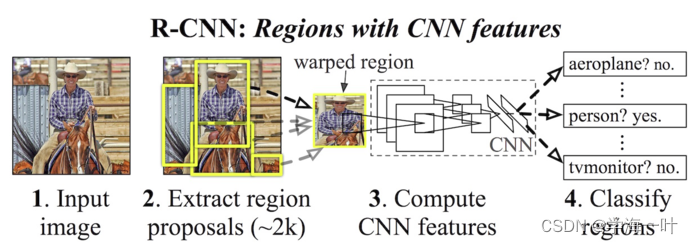
一、R-CNN的网络结构及步骤
- 提取候选区域(Region Proposal)
ps:利用Selective Search算法在图像中从下到上提取2000个左右的可能包含物体且大小不一的候选区域Region Proposal
- 预训练分类模型(如AlexNet)+ 微调(fine-tuning) / 从头开始训练模型
- 利用训练好的模型进行特征提取,获取候选区特征图
ps:将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN网络,将CNN网络的输出作为特征
- 训练一个SVM分类器,根据CNN特征图进行分类,利用非极大值抑制(NMS)去除冗余候选区
- 训练一个线性回归模型,精修正确的候选框位置及大小
二、RCNN的创新点
- 使用候选区域法(Region Proposal)代替穷尽策略,大大缩小了计算量
- 利用CNN参数共享和特征提取的优势,改善了提取特征的速度和质量
候选区域法

有很多候选区域法,当时最出色的是选择性搜索(selective search)。它的工作原理是将图片中的每一个像素作为一组,然后计算每个像素的纹理,将相近的的组合起来形成更大的像素组,然后继续合并各个像素组。下图中展示了像素组是如何扩大的,蓝色矩形代表了真实图片各像素组合并后的外界矩形框。

特征提取-CNN网络
原文中使用的是AlexNet,当然也可以使用其他卷积神经网络。
总结
R-CNN虽然不再像传统方法那样穷举,但R-CNN流程的第一步中对原始图片通过Selective Search提取的候选框region proposal多达2000个,且这2000个候选框每个框都需要进行CNN提特征+SVM分类,计算量很大,导致R-CNN检测速度很慢,GPU上大于13s/image,CPU上大于53s/image。
其次,将所有候选区域统一缩放到统一大小(CNN输入大小是确定的)会导致图像变形失真,从而降低精度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 国外创意二维码案例:法国大众汽车的招聘二维码!
- Hive分组取满足某字段的记录
- 第二百一十九回
- C#中的.NET与.NET Framework区别
- 如果你希望在过滤操作之后清空endorsementIds1集合,你可以使用clear()方法。以下是修改后的代码:
- Jenkins配置发邮件
- [LitCTF 2023] Web类题目分享
- STM32 JLINK SWD调试器手动复位才能烧写的问题
- C语言学习笔记-函数
- 模板代码大全(持续更新ing...)