【Pytorch】学习记录分享8——PyTorch自然语言处理基础-词向量模型Word2Vec
发布时间:2023年12月28日
【Pytorch】学习记录分享7——PyTorch自然语言处理基础-词向量模型Word2Vec
1. 词向量模型Word2Vec)
1. 如何度量这个单词的?
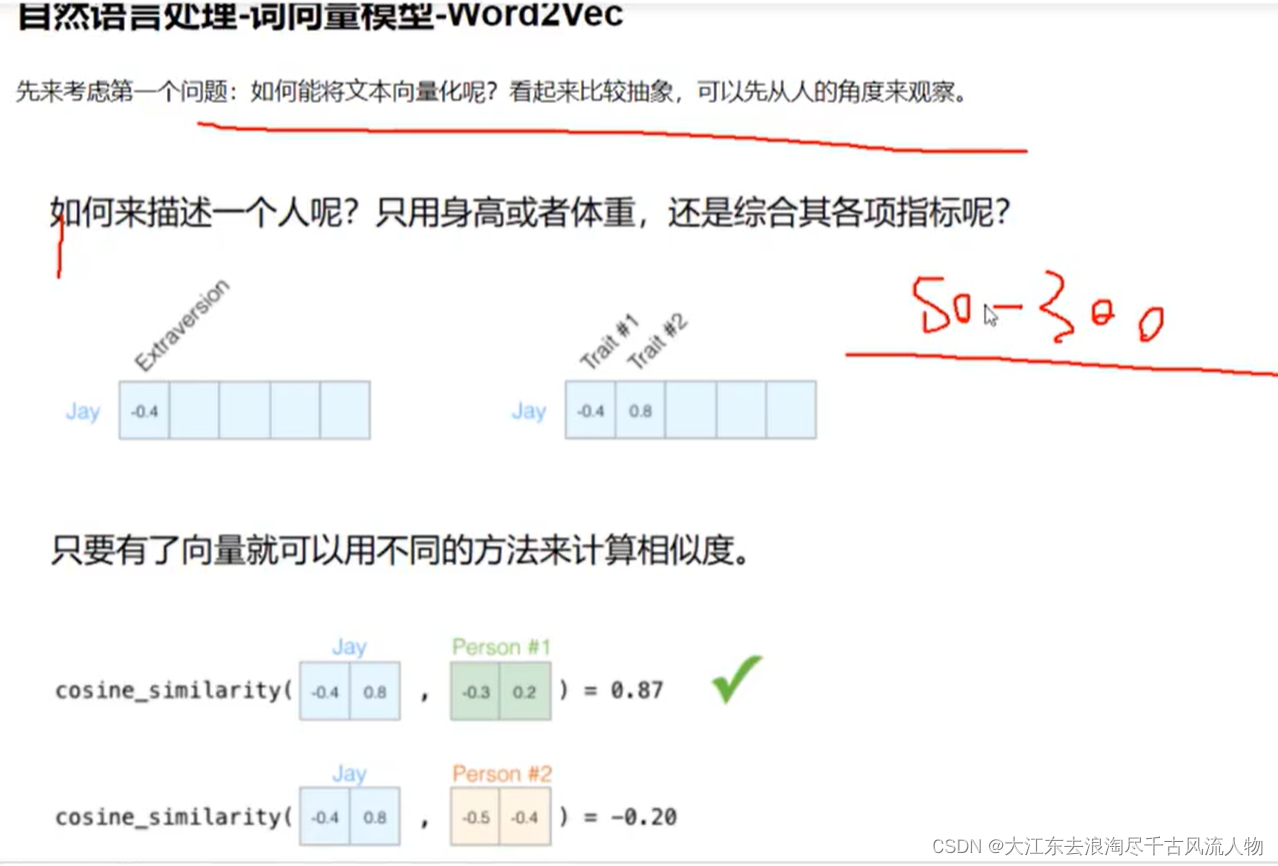
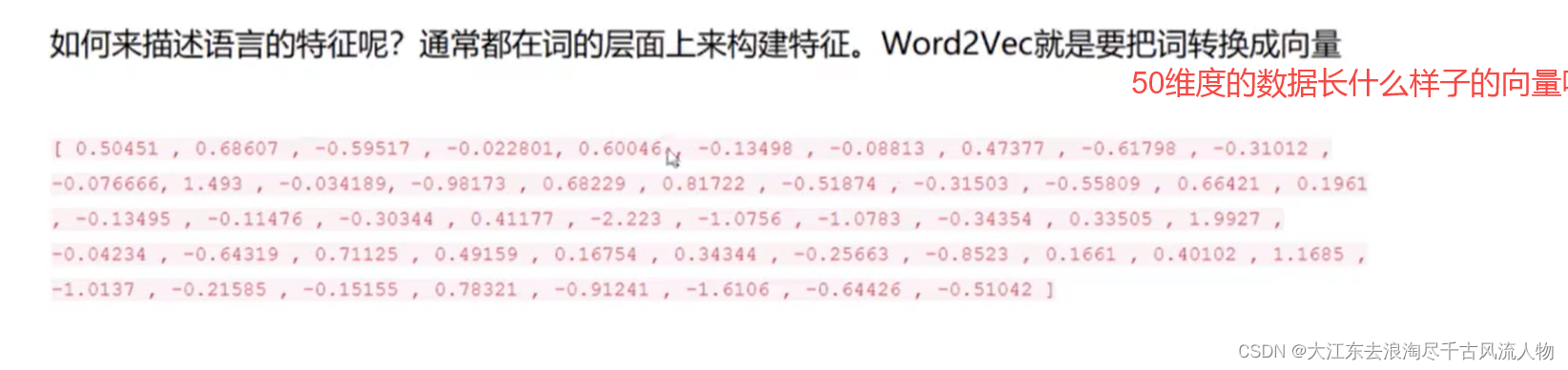
2.词向量是什么样子?
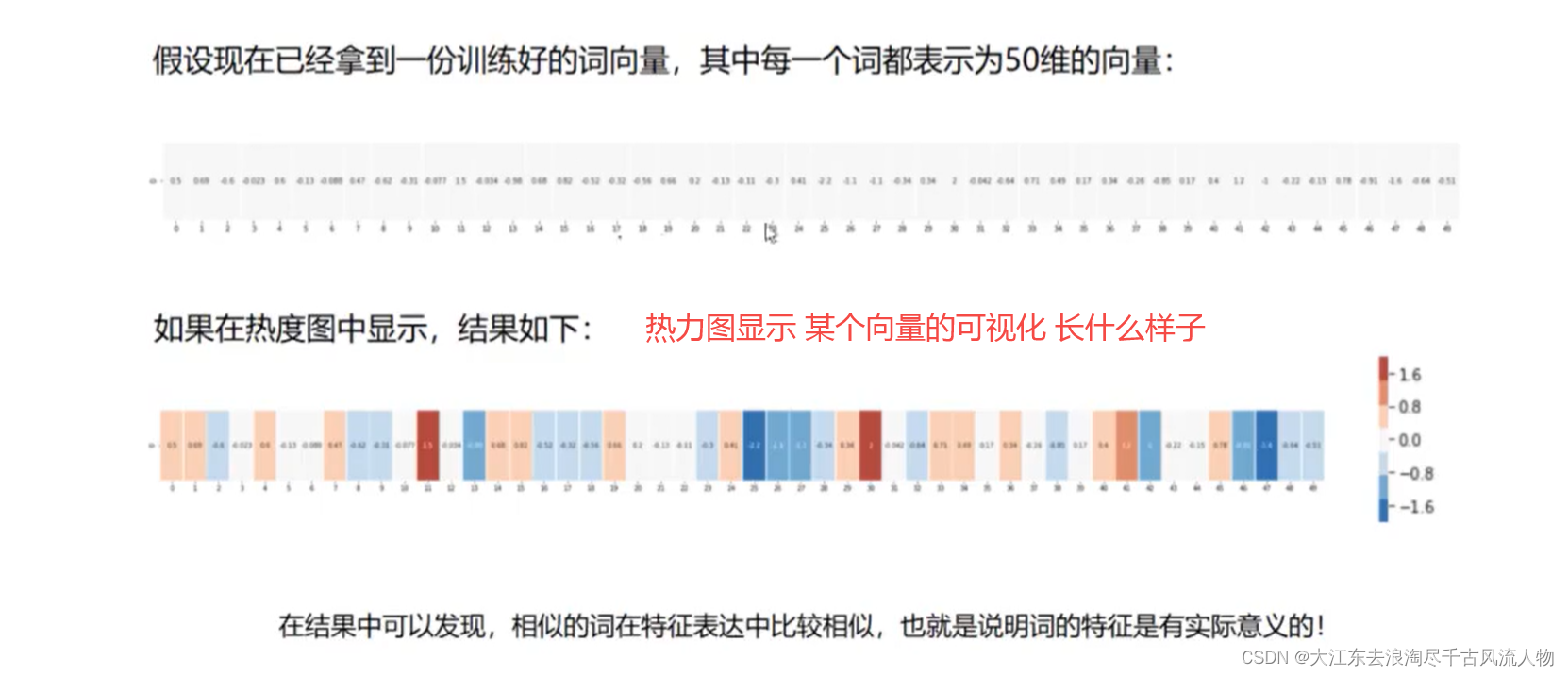
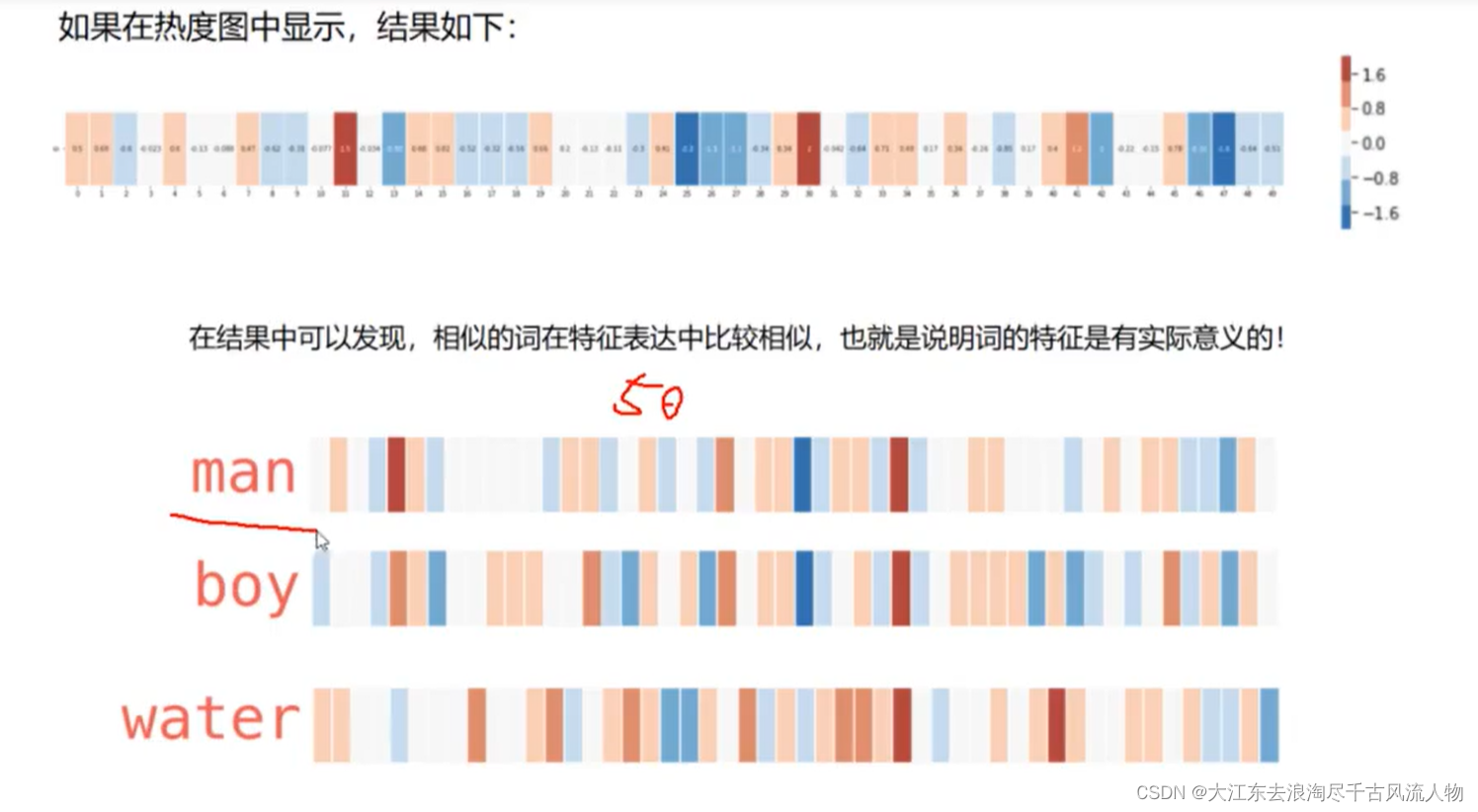
3.词向量对应的热力图:
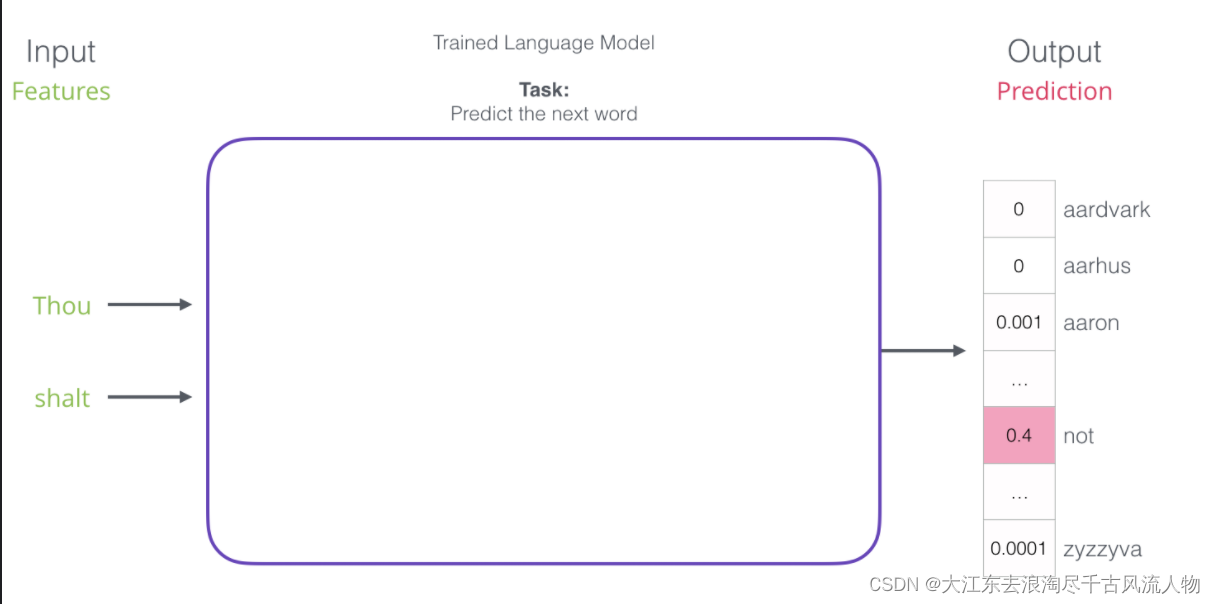
4.词向量模型的输入与输出
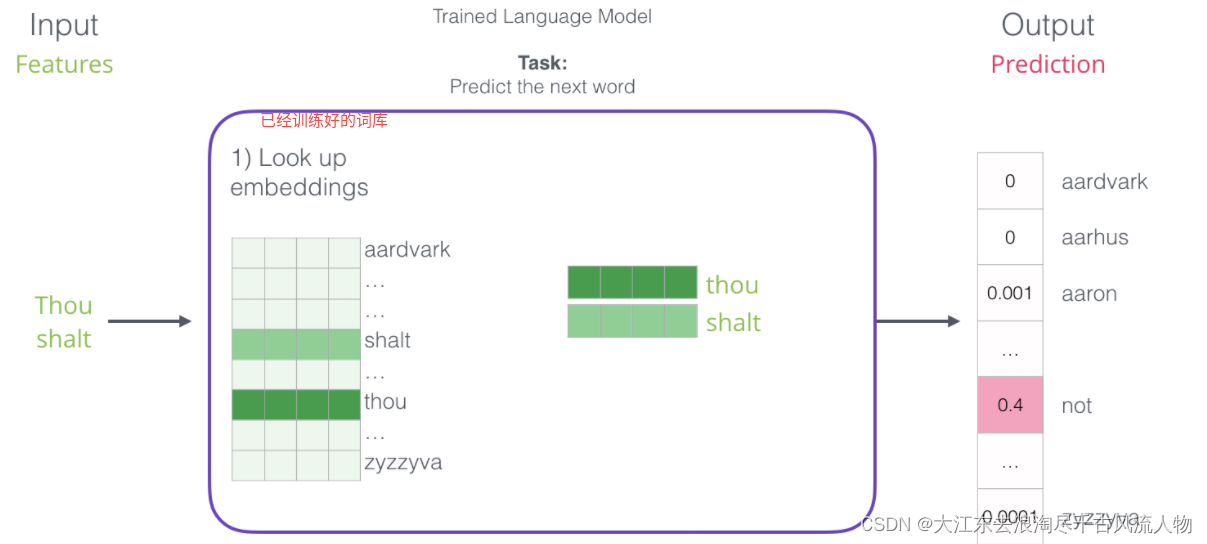
2.如何构建训练数据
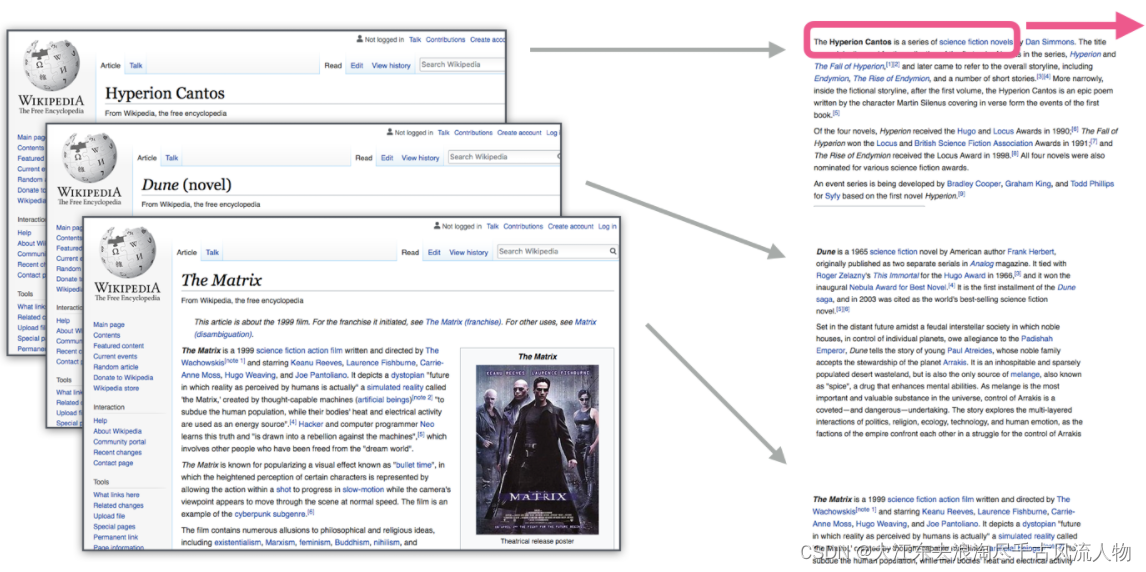
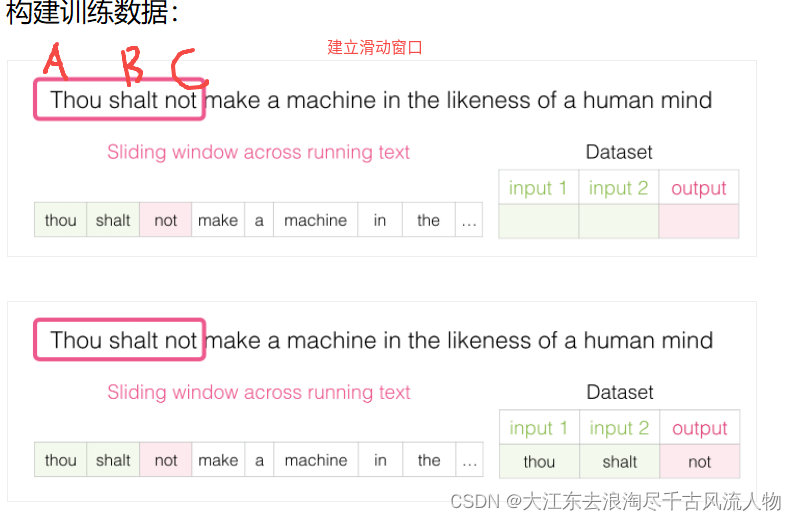
2.1 构建训练数据
类似wiki与合乎说话逻辑的文本均可以作为训练数据
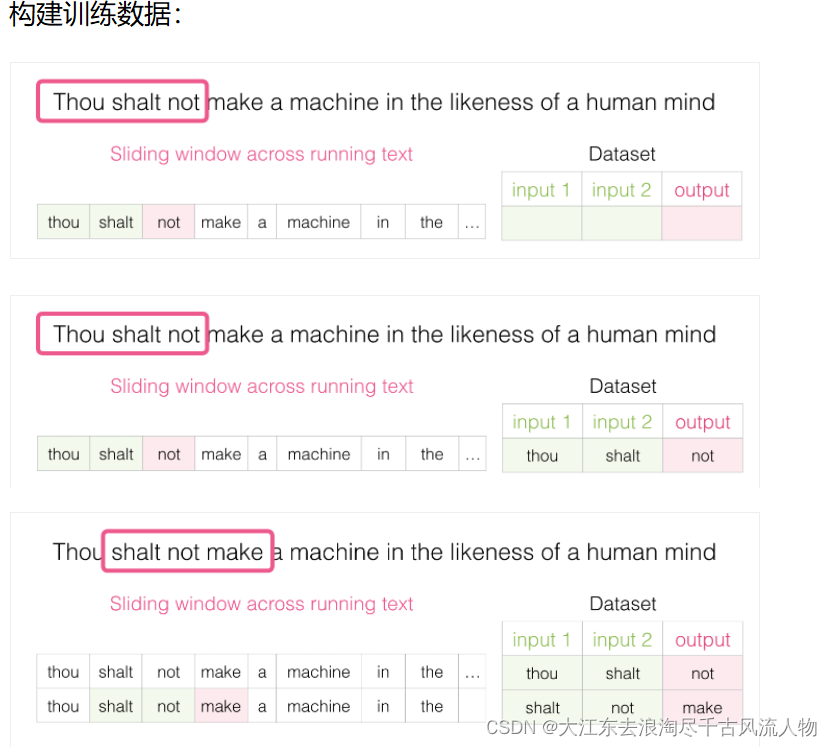
2.2 不同模型对比(传入中间词预测上下文,传入上下文,预测中间词汇)
CBOW:
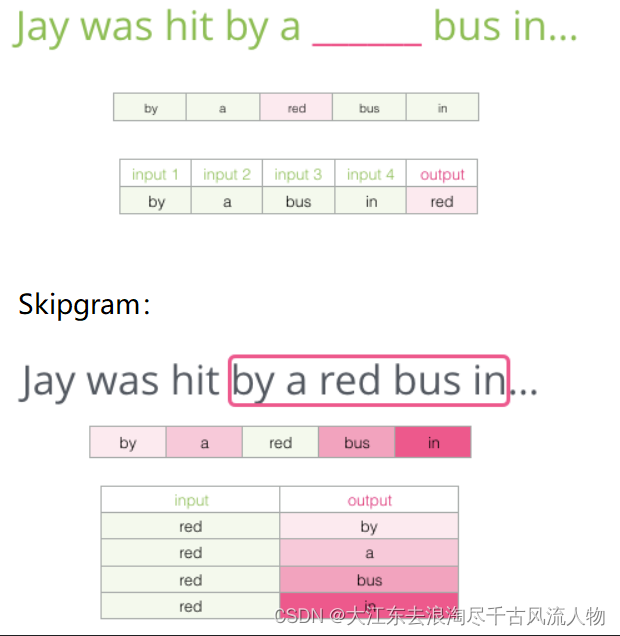
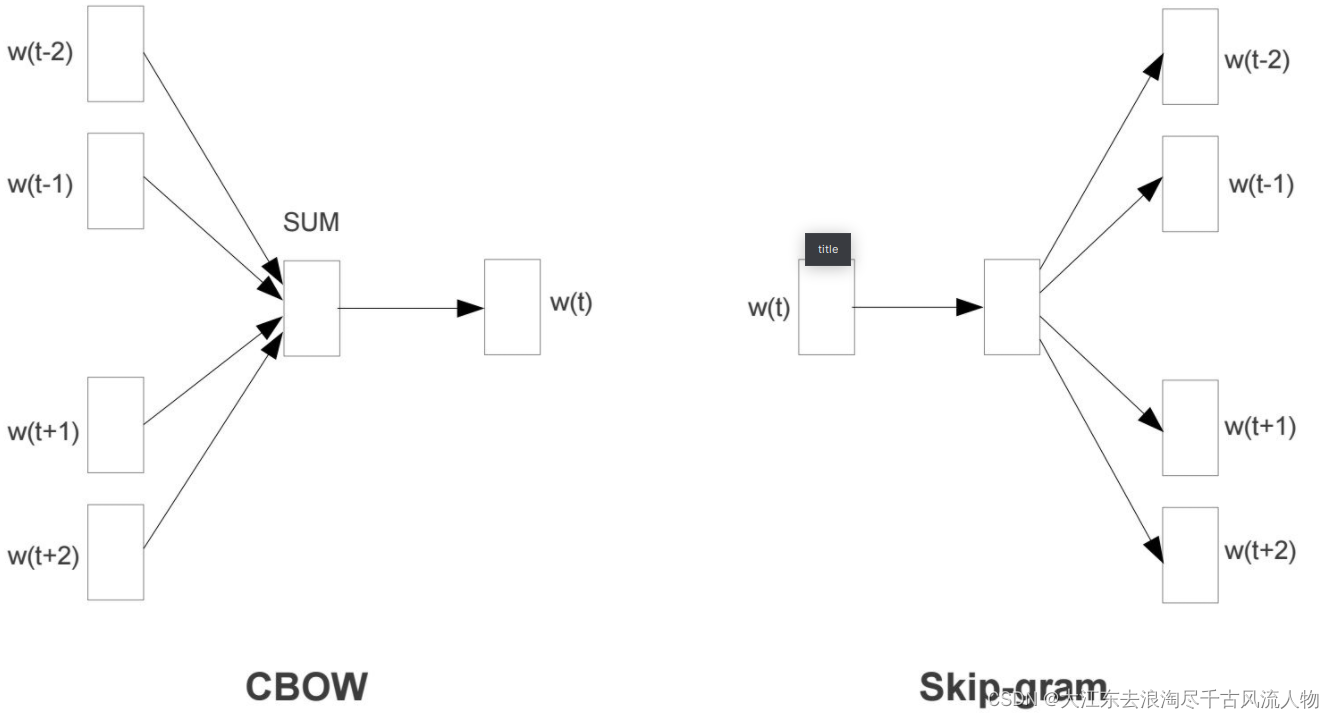
Skip-gram模型所需训练数据集 :
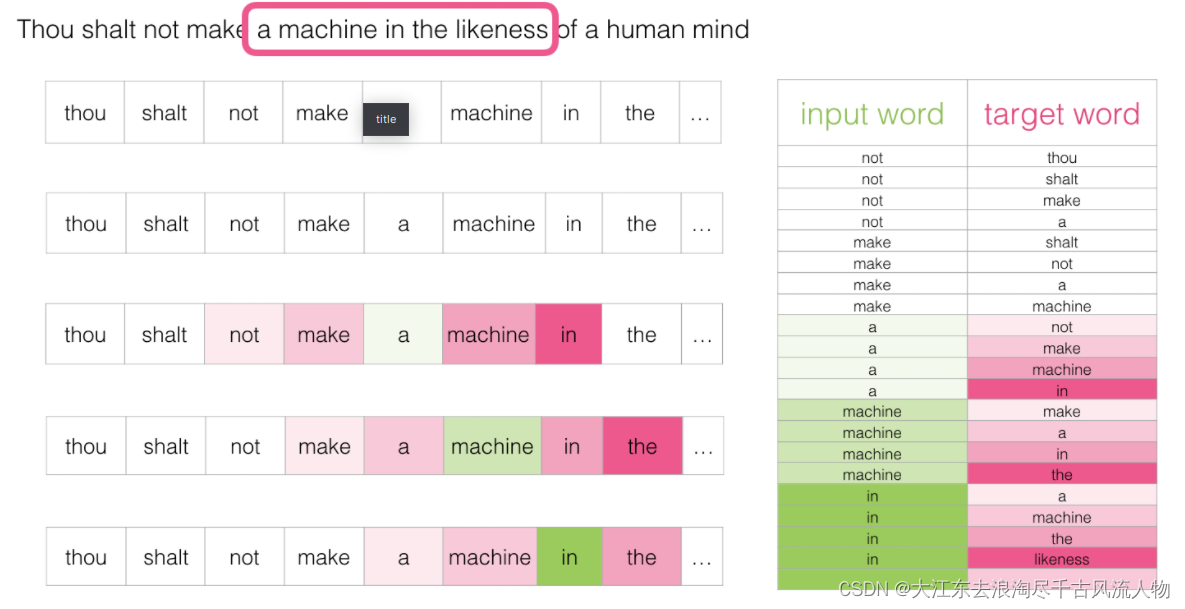
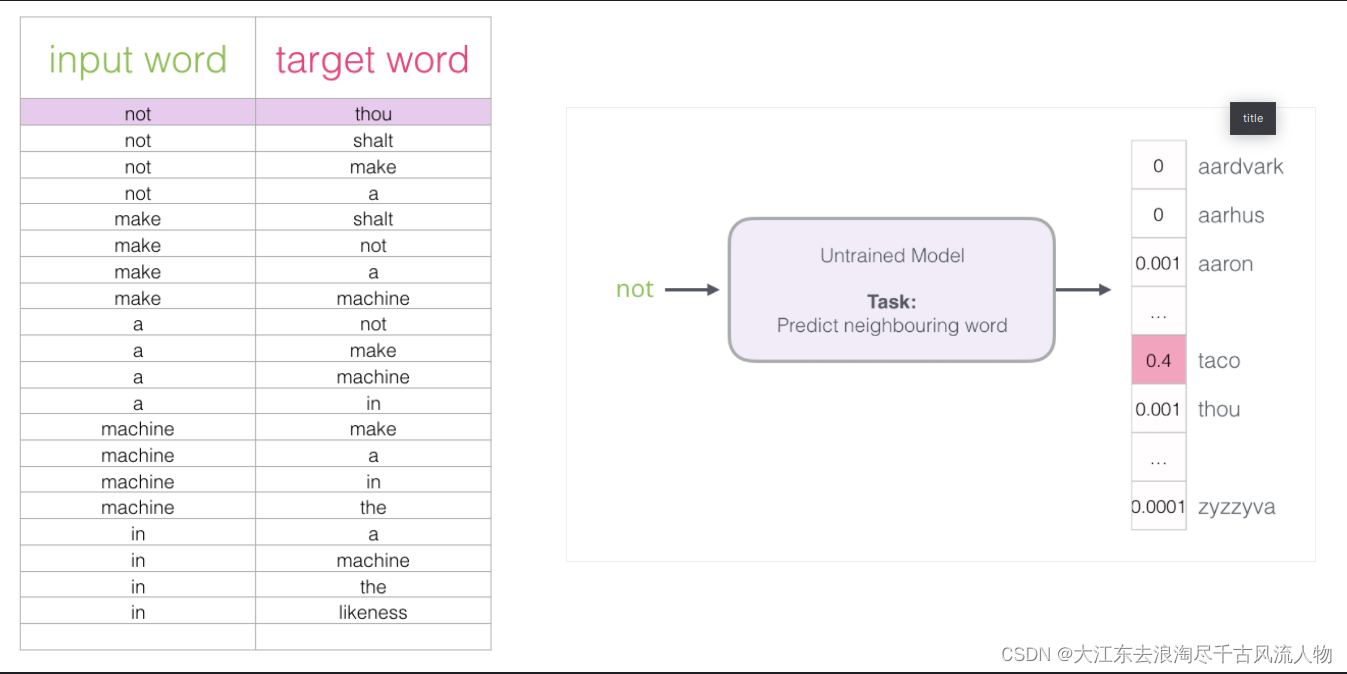
3.如何训练
3.1 如何设计驯联网络
如果一个语料库稍微大一些,可能的结果简直太多了,最后一层相当于softmax,计算起来十分耗时,有什么办法来解决嘛?
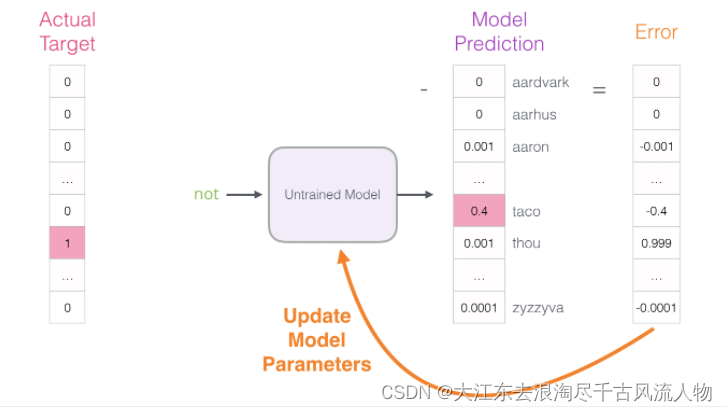
初始方案:输入两个单词,看他们是不是前后对应的输入和输出,也就相当于一个二分类任务,但是这样做之后

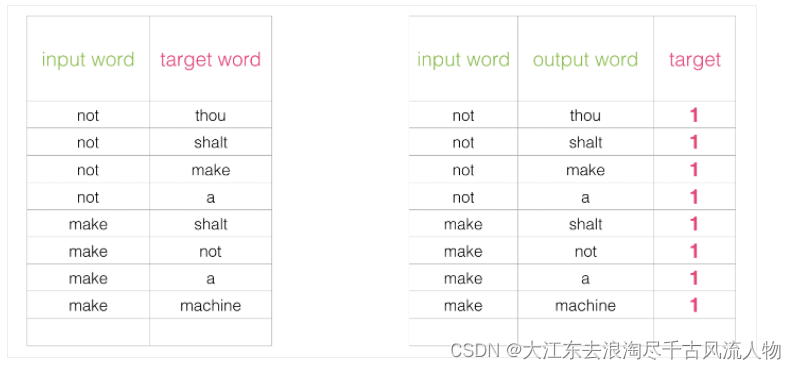
出发点非常好,但是此时训练集构建出来的标签全为1,无法进行较好的训练
3.2 改进方案:加入一些负样本(负采样模型)
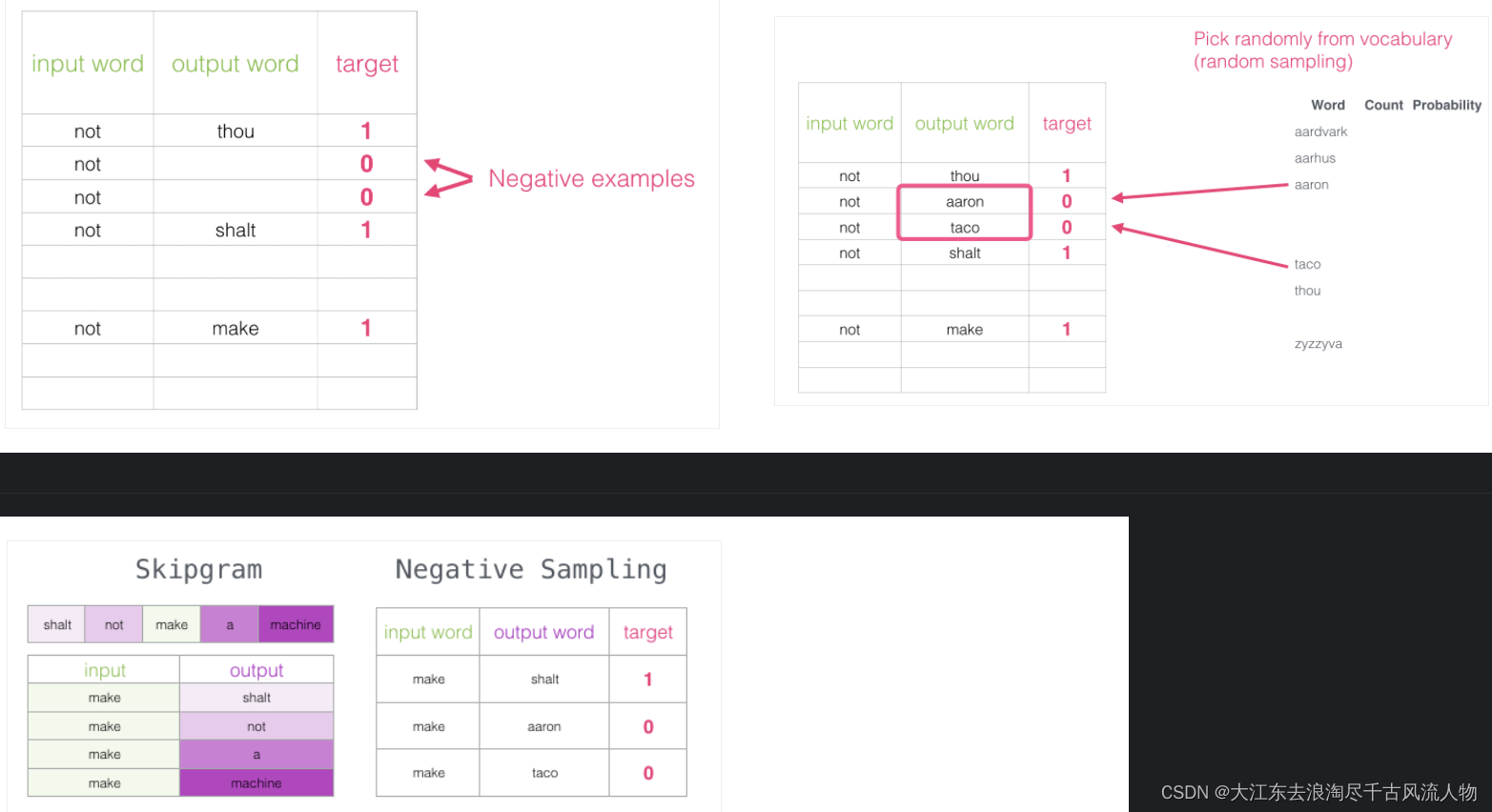
3.3 词向量训练过程
1.初始化词向量矩阵
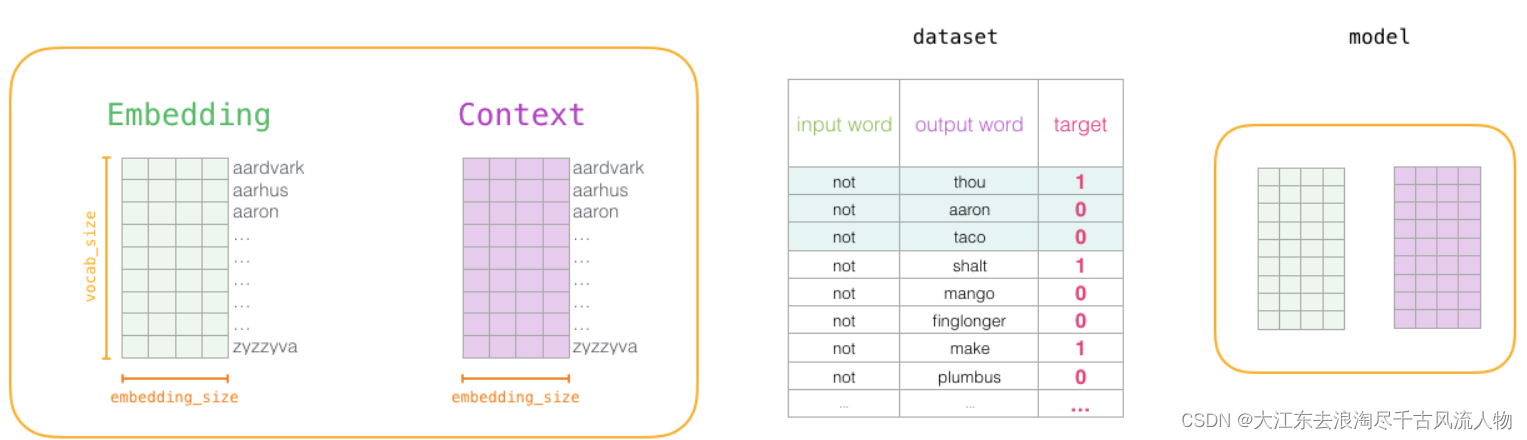
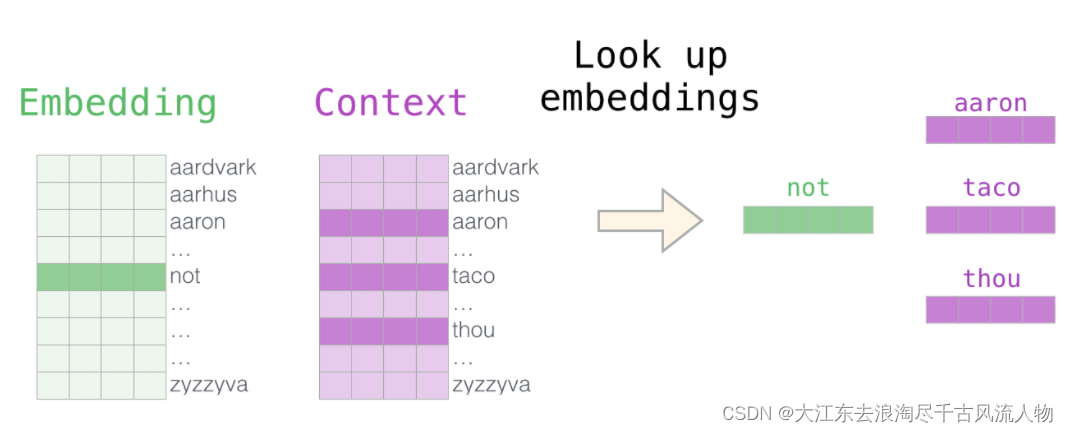
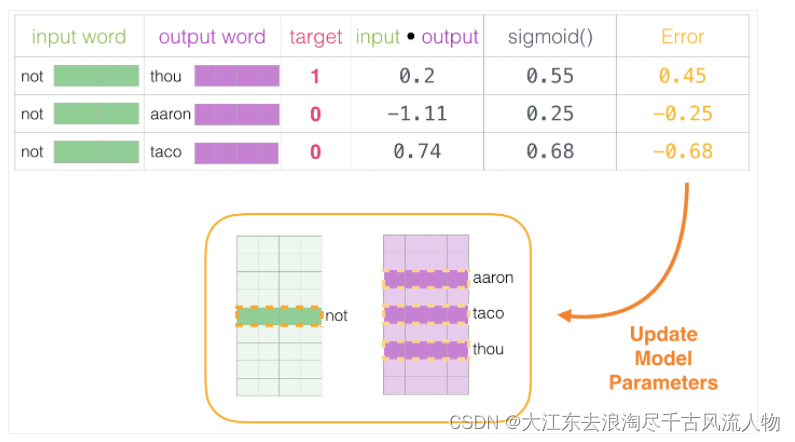
2.通过神经网络返向传播来计算更新,此时不光更新权重参数矩阵W,也会更新输入数据
文章来源:https://blog.csdn.net/Darlingqiang/article/details/135236919
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 借着期末作业,写一个JavaWeb项目
- 思腾云计算
- 【流复制环境PostgreSQL-14.1到PostgreSQL-16.1大版本升级】
- 大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解
- 深度学习 pytorch的使用(张量2)
- 228.【2023年华为OD机试真题(C卷)】传递悄悄话(优先搜索(DFS)-Java&Python&C++&JS实现)
- 解读 Sobit v2:铭文资产跨链更注重安全、易用性
- C++I/O流——(3)文件输入/输出(第二节)
- 为什么Certum旗下的多域名证书会过期
- 【工具】windeployqt 在windows + vscode环境下打包