知识图谱学习
文章目录
总览

思维导图阅读方式
1 知识图概述

2 知识图谱概念

3 知识图谱的逻辑结构

4 知识图谱的数据存储

5 知识图谱的构建过程

6 练习题

文本阅读方式
1 知识图谱概述
知识图谱本质上是一种结构化的语义网络
-
其节点代表实体或概念
-
边代表实体/概念之间的各种语义关系
知识图谱(Knowledge Graph)也叫语义网络(Semantic NetWork)。其初衷是为了提升搜索引擎的能力,增强用户的搜索质量以及搜索体验。
2 知识图谱相关概念
知识图谱的定义
-
知识图谱又称科学知识图谱,用各种不同的图形等可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互关系。
-
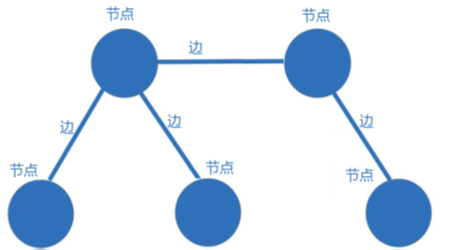
知识图谱是用图谱的形式表示知识
-
知识图谱可以看作一张图,节点表示实体或概念、边表示属性或关系构成
-
实体:具有可区别性且独立存在的某种事物
-
概念(语义类):具有同种特性的实体构成的集合
-
内容:通常作为实体和语义类的名字、描述、解释等,可以由文本、图像、音视频等来表达
-
属性值:描述资源之间的关系,即知识图谱中的关系
-
关系:把k个图节点(实体、语义类、属性值)映射到布尔值的函数
-
3 知识图谱的逻辑结构
逻辑划分为两个层次
-
数据层
- 数据层主要由一系列的事实组成,知识以事实(fact)为单位存储在图数据库,通常以“实体1-关系-实体2”或者“实体-属性-属性值”三元组作为事实(fact)的基本表达方式。存储在图数据库中的所有数据将构成庞大的实体关系网络,形成知识的“图谱”。

-
模式层
- 模式层在数据层之上,是知识图谱的核心。
在模式层存储的是经过提炼的知识,通常采用本体库来管理知识图谱的模式层。
数据模型是按照本体论的思想勾画出来的数据组织模式,数据模型可以展示数据的组织方式和相互关系。例如:创建动植物的数据模型,可以按照动植物的通用分类标准,使用七个主要级别:界、门、纲、目、科、属、种 。
- 模式层在数据层之上,是知识图谱的核心。
逻辑结构的构建方式
-
根据是先确定数据模型再收集具体数据,还是先收集具体数据再确定数据模型,将知识图谱分为自顶向下和自下向上的构建方式
-
自顶向下的构建方式,指先确定知识图谱的数据模型,再根据模型去填充具体数据。
-
数据模型的设计,是知识图谱的顶层设计,根据知识图谱的特点确定数据模型,就相当于确定了知识图谱收集数据的范围,以及数据的组织方式。
-
适用于行业知识图谱的构建,对于一个行业来说,数据内容,数据组织方式相对来说比较容易确定。比如对于法律领域的知识图谱,可能会以法律分类,法律条文,法律案例等的方式组织。
-
-
自下向上的构建方式,是指先按照三元组的方式收集具体数据,然后根据数据内容来提炼数据模型。
-
一般公共领域的知识图谱采用这种方式。
-
先把所有的数据收集起来,形成庞大的数据集,然后再根据数据内容,总结数据的特点,将数据进行整理、分析、归纳、总结,形成数据模型
-
4 知识图谱的数据存储
知识图谱的存储方式
-
知识图谱的原始数据类型一般来说有三类
-
结构化数据(Structed Data):如关系数据库
-
半结构化数据(Semi-Structed Data):如XML、JSON、百科
-
非结构化数据(UnStructed Data):如图片、音频、视频、文本
-
-
如何存储这三类数据类型
-
基于表结构的存储采用二维数据表的方式存储数据,例如三元组表、属性表以及关系数据库
-
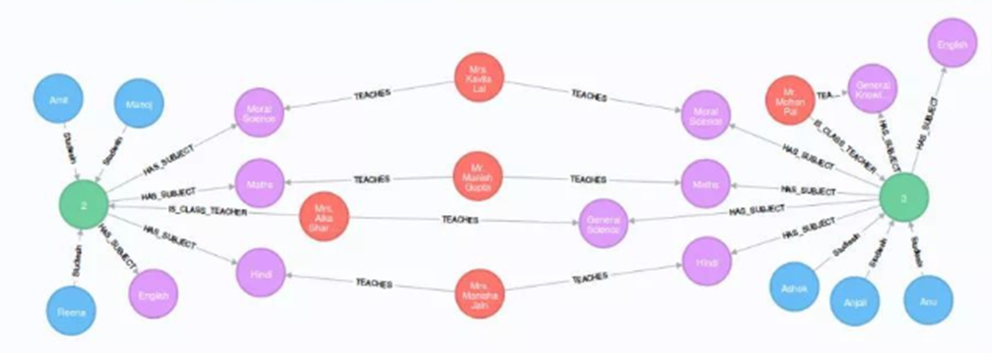
基于图结构的存储可以使用图数据库
-
-
RDF(Resource Description Framework)存储
- RDF本质是一个数据模型,它提供了一个统一的标准,用于描述实体/资源。RDF形式上表示为主谓宾SPO三元组。表示实体与实体间的关系(实体1-关系-实体2),或者实体的某个属性的值是什么(实体-属性-属性值)
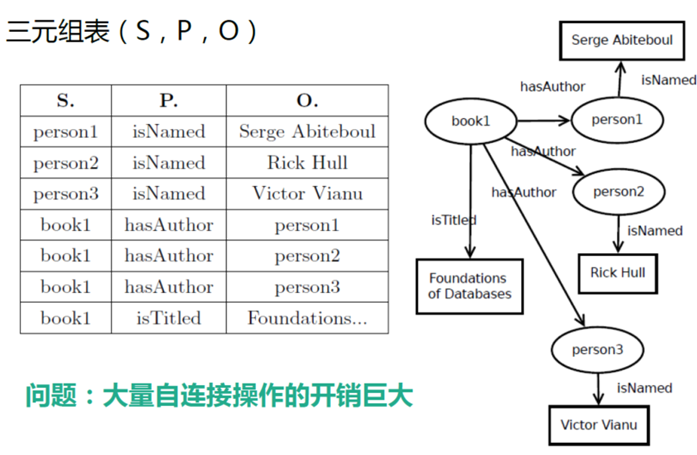
- Subject:通常是实体、事实或者概念中的任何一个。
- Predicate:通常是关系或者属性。
- Object:既可以是实体、事件、概念,也可以是普通的值。
-
图数据库存储
- 图数据库的结构定义相比RDF数据库更为通用,实现了图结构中的节点\边以及属性来进行图数据的存储,典型的开源图数据库就是Neo4j。

- 节点(node):通常表示实体,例如人员、账户、事件等,节点可以有属性和标签
- 边(edge):又被称为关系(relationships),具有名字和方向,并有开始节点和一个结束节点,边是图数据库中最显著的一个特征,在RDBMS中没有对应实现。
- 属性(properties):类似KV数据库中的键值对,节点和边都可以有属性
5 视图图谱的构建过程
从原始的数据到形成知识图谱,经历[知识抽取、知识表示、知识融合和知识推理]四个过程
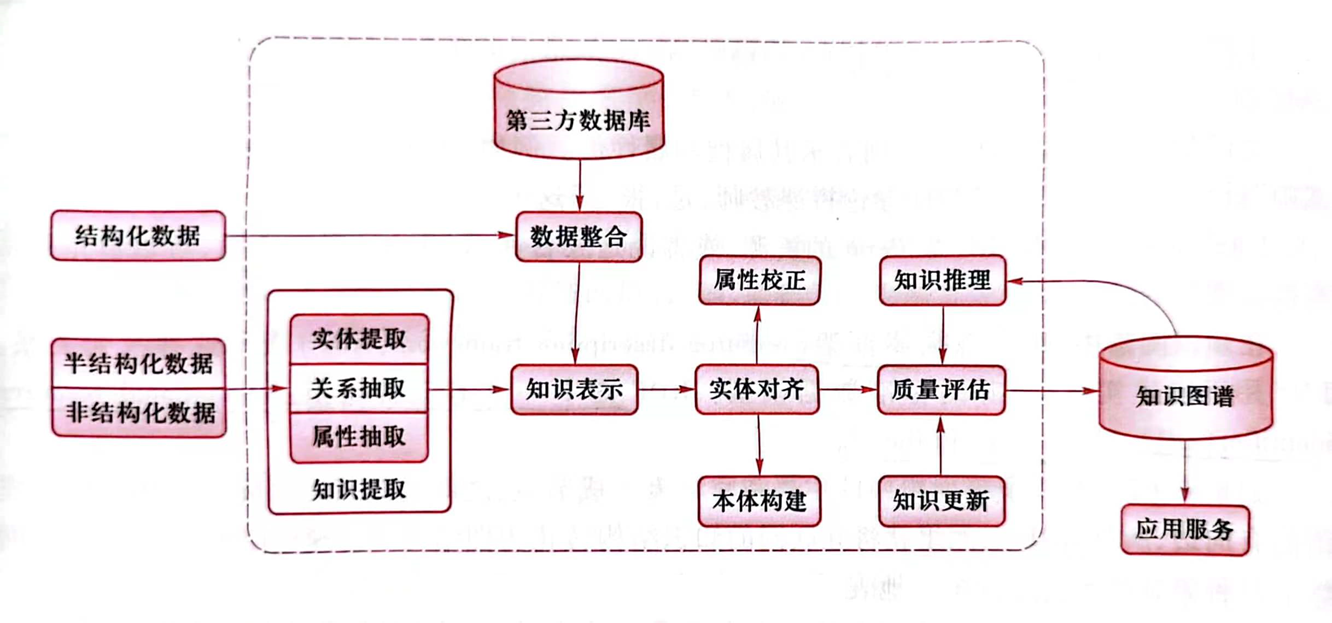
1 知识抽取
-
从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱
-
结构化数据处理
- 结构化数据,通常是关系型数据库的数据,把关系型数据库中的数据转换为RDF数据(linked data),普遍采用的技术是D2R技术。D2R主要包括D2R Server,D2RQ Engine和D2RRQ Mapping语言。
-
半结构化数据处理
-
采用包装器的方式进行处理
-
包装器是一个能够将数据从HTML网页中抽取出来,并且将它们还原为结构化的数据的软件程序
-
包装器归纳主要包括网页清洗、网页标注、包装器空间生成、包装器评估、包装器归纳结果等步骤
-
-
非结构化数据处理
-
实体抽取(命名实体识别):实体包括概念,人物,组织,地名,时间
-
关系抽取:实体和实体之间的关系
-
属性抽取:实体的属性信息
-
-
子主题 5
2 知识融合
-
将多个来源的关于同一个实体或概念的描述信息融合起来
-
知识融合的目的就是将不同知识库对实体的描述进行整合,从而获得实体的完整描述。
-
挑战
-
数据质量的挑战
-
数据规模的挑战
-
3 知识加工
-
知识加工主要包括三方面内容:本体抽取、知识推理和质量评估
-
本体抽取
-
本体(ontology)是指公认的概念集合、概念框架,如“人”、“事”、“物”等
-
人工编辑
-
自动化本体构建
- 实体并列关系相似度计算 → 实体上下位关系抽取 → 本体的生成。
-
-
知识推理
- 知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系
-
质量评估
- 可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量
6 例题
1 在知识图谱的构建中,知识提取包括
-
[实体抽取]
-
[关系抽取]
-
[属性抽取]
2 在知识图谱中先搜集数据然后建立本体的构建过程,采用了[自下向上]的构建方式
3 知识图谱在逻辑上可以由“实体—关系—实体”三元组,或者“实体-属性—属性值”构成,实体间通过关系相互联结,构成网状的知识结构
4 从知识图谱数据组织的架构来看,可以把知识图谱的数据分为两个层次,一个是[模式层],另一个是[数据层]
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 电口模块SFP-GE-T常见问题解答
- 8868体育助力马德里竞技 傲娇格子成队史射手王
- R 批量对多个变量进行单因素方差分析 批量计算均值±标准差
- Linux tar 命令
- 30天零售应用构建挑战:低代码平台的惊人潜力
- 编程笔记 html5&css&js 005 网页上都有哪内容、形式和操作
- redis远程连接不上解决办法
- 【信息安全】hydra爆破工具的使用方法
- Mybatis3系列课程-foreach
- Create Gantt Scheduling