@JsonProperty注解源码分析(双向自定义别名)
引言
导入指引:import com.fasterxml.jackson.annotation.JsonProperty;
maven指引:
<dependency>
????????<groupId>com.fasterxml.jackson.core</groupId>
????????<artifactId>jackson-annotations</artifactId>
????????<version>2.12.4</version>
</dependency>
这是一个开源的对JSON数据进行操作的库(Jackson库)
是一家专于java的公司FasterXML的产品
简易版
我们设置成这样

就会这样

正文
-
我们都知道,在字段上加上注解@JsonProperty(“name”),再指定它的name,就可以在序列化和反序列化时采用我们使用的别名,那么它的源码是怎样的呢?
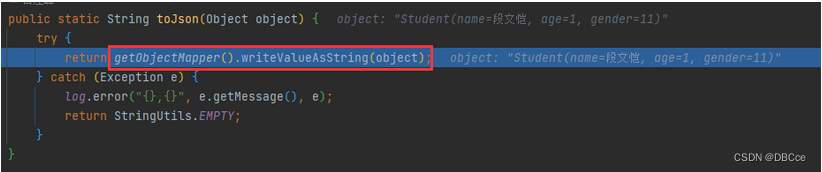
-
那我们直接进入它的json构造过程吧

-
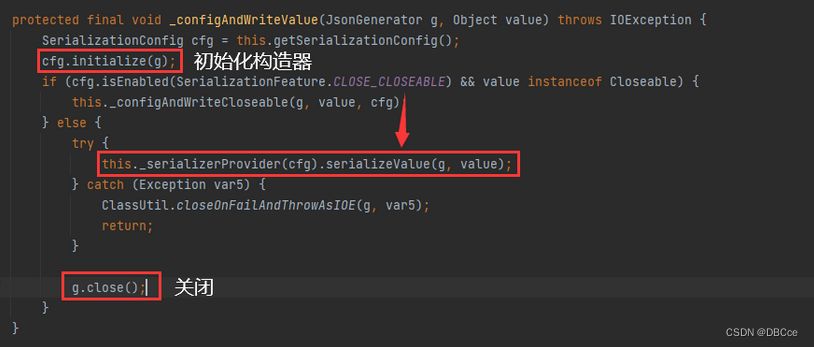
首先先是使用了一个sw(不重要,估计是构造的方式,和选的方法有关,是生成String),生成了一个json的构造器
-
-
进来后呢,它对构造器进行了正确性判断和初始化,然后对比我序列化的类是否为需要关闭的类(我用的是Student,显然不需要关闭)

-
这边常规检查,确定我们序列化有没有差错和例外(这就是考虑所有情况的困难之处)
-
确保没有问题开始序列化

-
这是个抽象方法,代表每个类型的JsonSerializer都有不同的实现方法
-
所以我们得回去找是匹配了哪个构造器

-
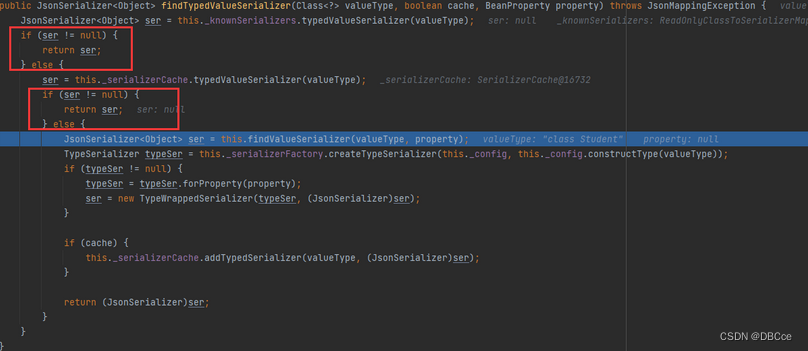
这边看到它还进行了一系列hash计算,甚至还专门配了个桶来给你定位(那我们不好算了,得用点手段)

-
好好好,算了半天我的Student它没有给分类,被定义为Bucket{null}
-
我们继续为null,往下走

-
这边给上了一个BeanSerializer for Student,这个是生成的自定义构造器
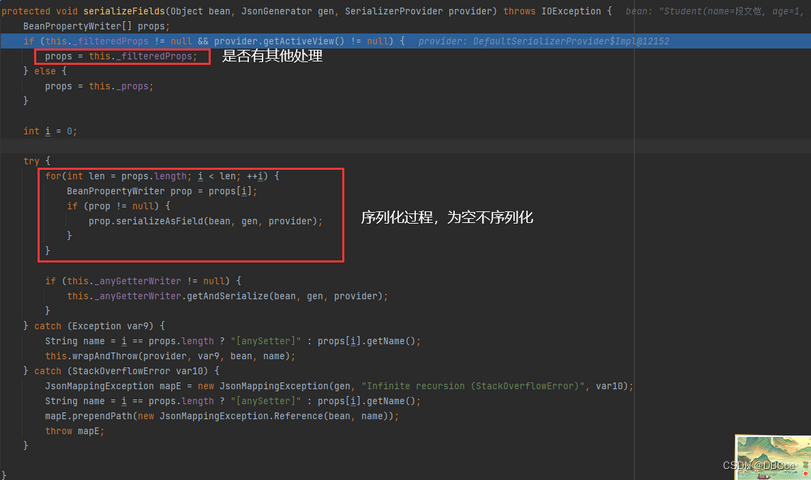
-
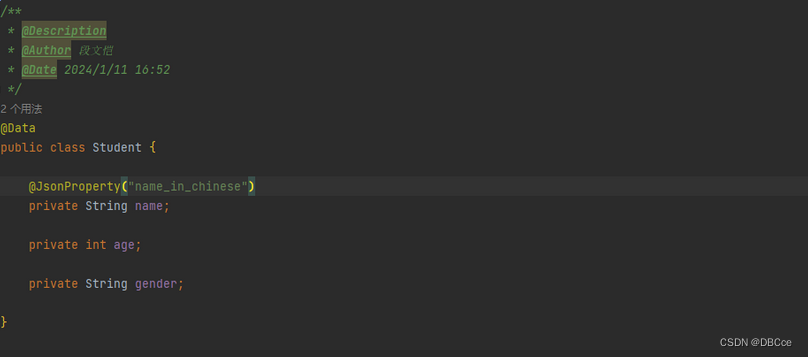
我们通过给的构造器分类进入了最终的加工工程,根据是否有处理过类分为_props和_filteredProps。我们的字段name就被处理过,改成了("name_in_chinese"),所以我们就是_filteredProps

-
在这里识别出来了,我加了name_in_chinese处理
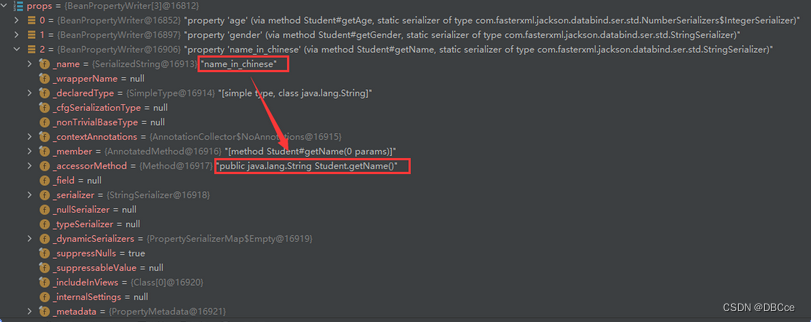
-
我们在DeBug也能看到,它调用了getName()方法
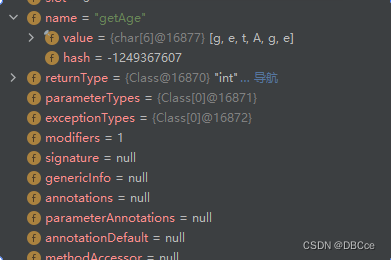
-
也对方法进行了反射处理,将方法的名字保存下来了。

-
我们的注解此时也被读下来了,有别名,序号等
-
相信大家也可以看出,最后是怎样进行json的拼接了
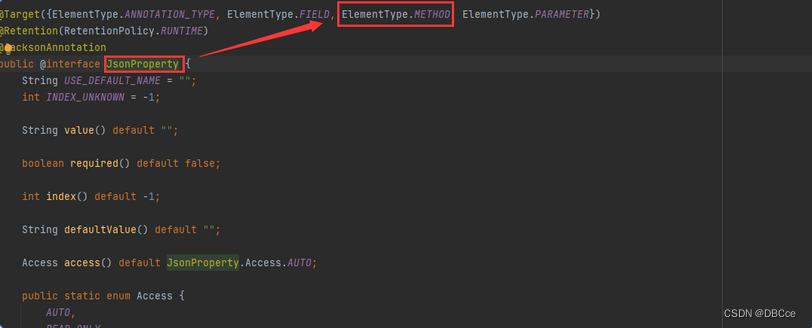

-
我们有看到,该注解支持方法,那我们试试将注解注到方法上会有什么不一样?

-
从字段上的反射组到了方法的反射组,那说明基本是没有什么影响的。
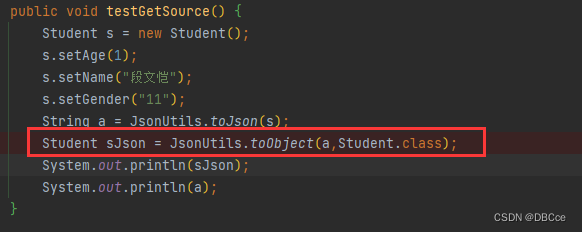
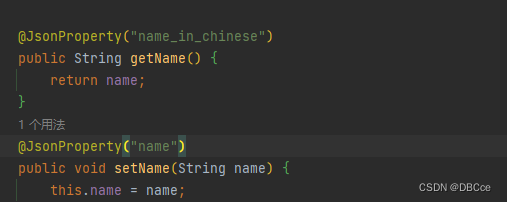
-
我们这样设置
-
将这个json转换回去

-
获取不到,这说明反序列化时name_in_chinese字段并没有被读到name
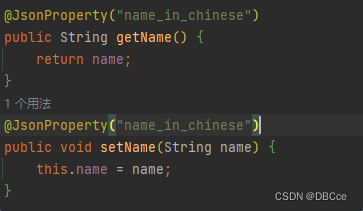
-
设置成一样的呢?

总结
在序列化和反序列化的场景下,我们时常需要灵活处理,所以可以对其get,set方法定义不同的注解,以应对我们的需求。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 3rd 库(x86, linux)的编译,源码目录
- C++枚举类型可以作为返回值类型吗
- ioDraw在线图表工具 - 轻松制作专业图表,只需3步!
- 数据类型和局部/全局变量
- MAC使用python下载字幕
- Python字符串处理全攻略(合集篇):常用内置方法轻松掌握
- vue使用i18n实现国际化
- pytest -- 进阶使用详解
- DBA技术栈(二):MySQL 存储引擎
- Baumer工业相机堡盟工业相机如何联合NEOAPI SDK和OpenCV实现获取图像并对图像进行边缘检测(C++)