利用Pandas进行高效网络数据获取
利用Pandas进行高效网络数据获取
背景:
? 最近看到一篇关于使用Pandas模块进行爬虫的文章,觉得很有趣,这里为大家详细说明。
基础铺垫:
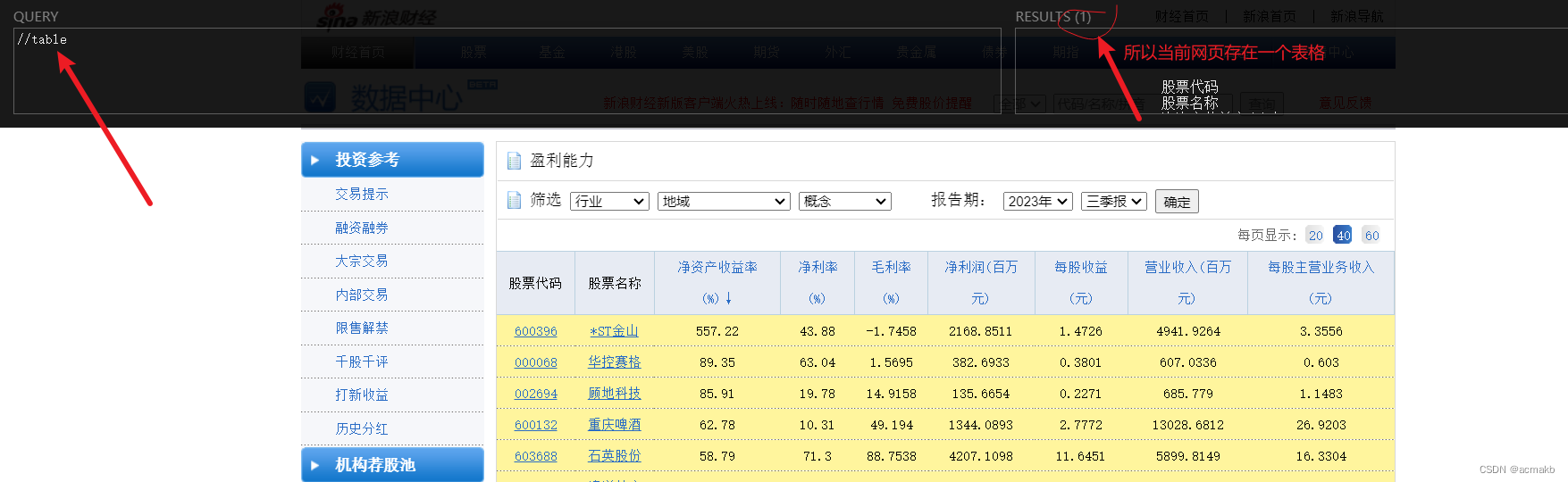
? pd.read_html pandas 库中的一个函数,用于从 HTML 页面中读取表格数据并返回一个包含 DataFrame 对象的列表。那么说明是表格数据呢,就是table标签的,如下图!
? 我们可以使用XPath快速判断当前页面是否具有使用Pandas进行爬虫的前提条件。
? pd.read_html(io, match=‘.+’, flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False, thousands=‘,’, encoding=None, decimal=‘.’, converters=None, na_values=None, keep_default_na=True, displayed_only=True)
参数说明:
io: 接受的输入数据,可以是一个 HTML 字符串、一个 URL、一个文件路径或一个文件对象。match(可选): 一个正则表达式,用于匹配要提取的表格的 HTML 属性。flavor(可选): 解析器的名称,例如'html5lib'、'lxml'、'html.parser'等。- 其他参数:例如
header、index_col、skiprows等参数用于控制读取表格数据的方式和格式。
案例实战:
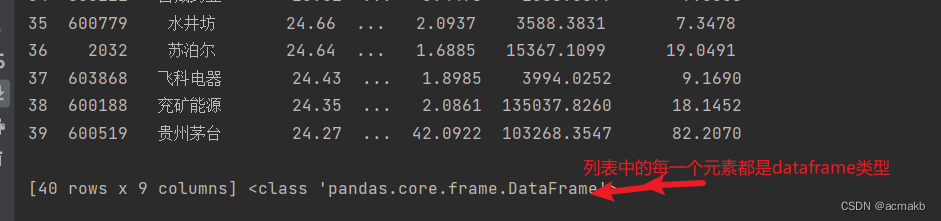
pd.read_html 函数会尝试从输入数据中提取所有的表格,并返回一个包含 DataFrame 对象的列表,就是一个列表里存在多个dataframe类型,每个 DataFrame 对象对应一个表格。
import pandas as pd
# 从 HTML 页面中读取表格数据
url = 'https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml?p=1'
tables = pd.read_html(url)
print(tables,type(tables),len(tables))
# 选择第一个表格的 DataFrame 对象
df = tables[0]
# 打印 DataFrame
print('---------------------------------------')
print(df,type(df))

? 那么如果爬取多页呢? 写个for循环,然后使用concat拼接起来,不会拼接的看一下我不久前写的博客。
import pandas as pd
data_list = []
for i in range(1, 6):
url = f'https://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/profit/index.phtml?p={i}'
data = pd.read_html(url)[0] # 这里注意提取 返回的是一个列表
data_list.append(data) # 每一个data都是一个dataframe类型
print("个数为",len(data_list))
# 合并数据
df = pd.concat(data_list,ignore_index=True)
print(df.head())
# 保存到本地
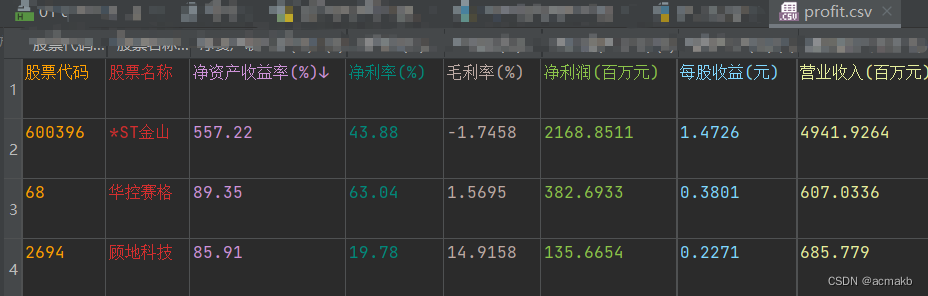
df.to_csv("profit.csv",index=False)
看一下结果:

细节问题:
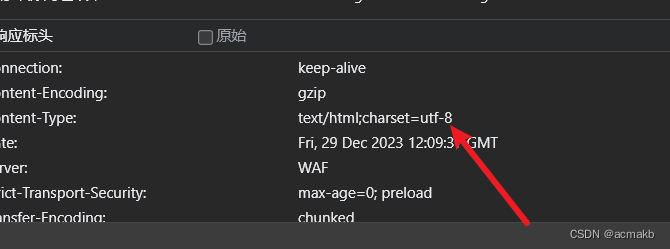
这里还要注意一个问题,有的时候还要设置一下编码,可能爬下来的是乱码,如下:

设置一下编码方式即可。
df = pd.read_html(url,encoding='utf-8')[0]
print(df.head())
如果大家想深层了解为什么有的时候需要设置,有的时候不需要设置,你要需要看这个响应回来的编码格式。
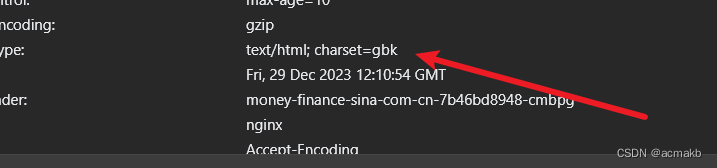
温馨提示:
? 本文提供的内容仅供学习和研究目的,请在合法和道德的框架内使用所获取的知识和技巧。在进行网络爬虫活动时,请遵守相关法律法规,并尊重网站的使用条款和隐私政策。确保在进行任何爬取操作之前获得合适的授权,并确保不会给目标网站或他人造成不必要的干扰或损害。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Nessus】容器化使用Nessus网络漏洞扫描工具
- 安装jupyter notebook,jupyter notebook的简单使用
- 自定义类型详解
- 「Verilog学习笔记」自动售卖机
- STM32_串口下载程序
- 记一次多平台免杀PHP木马的制作过程
- nodejs微信小程序+python+PHP汽车租赁管理网站-计算机毕业设计推荐
- x-cmd-mod | zuz - 压缩或解压文件
- 【JAVA-Day69】抛出异常的精髓:深度解析 throw、throws 关键字,优雅处理异常问题
- 2023年腾讯云服务器活动:4核8G12M轻量应用服务器646元15个月