CentOS安装Flume
一、简介
????????Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
????????Flume是一种分布式、高可靠且高可用的服务,用于高效地收集、聚合和转移不同来源的大量日志数据。Event是Flume定义的一个数据流传输的最小单元。Agent是一个Flume的实例,本质是一个JVM进程,该JVM进程控制Event从外部日志生产者那里将数据传输到目的地或者下一个Agent。
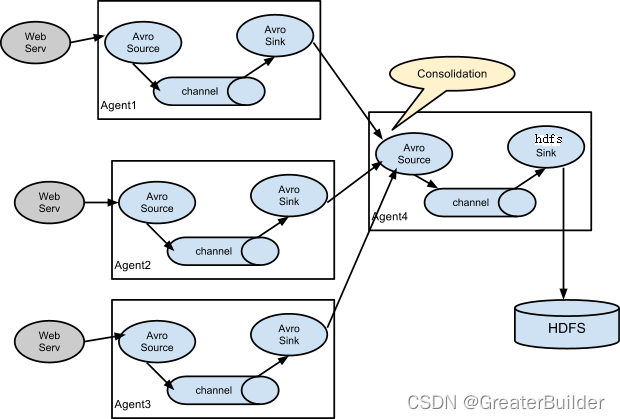
????????一个完整的Agent中包含了必须的三个组件Source、Channel和Sink,Source是指数据源的获取方式,Channel是一个数据的缓冲池,Sink定义了数据输出的方式和目的地(这三个组件是必须有的,另外还有很多可选的组件interceptor、channel selector、sink processor等)。完整流程可以参考下图:

????????Flume也可以设置多级Agent连接的方式传输Event数据,完整流程可以参考下图:
二、安装
1、下载
本次使用版本V1.11.0
apache-flume-1.11.0-bin.tar.gz
2、解压
tar -zxvf apache-flume-1.11.0-bin.tar.gz
3、创建配置文件
本次目标将指定的log文件数据读取出来同步到hdfs中,创建配置文件file2hdfs.conf,具体配置如下:
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=taildir
a1.sources.r1.filegroups=f1
a1.sources.r1.filegroups.f1=/wz_program/flume1.11.0/data/111.log
a1.sources.r1.positionFile=/wz_program/flume1.11.0/data/taildir.json
a1.sources.r1.fileHeader=true
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://hadoop001:8020/tmp/flume3
a1.sinks.k1.hdfs.rollSize=1048576
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.minBlockReplicas=1
a1.sinks.k1.hdfs.fileType=DataStream
a1.channels.c1.type=memory
a1.channels.c1.capacity=100
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
配置说明如下:
- 如上配置文件指定了一个名为a1的Agent,其中a1的source为r1,sink为k1,channel为c1。
- r1的类型为taildir,该类型的source监控指定的一些文件,并在检测到新的一行数据产生的时候几乎实时地读取它们。
- c1类型为memory,该类型的channel是把 Event 队列存储到内存上,队列的最大数量就是 capacity 的设定值。
- k1的类型为hdfs,该类型的sink是将Event写入Hadoop分布式文件系统。
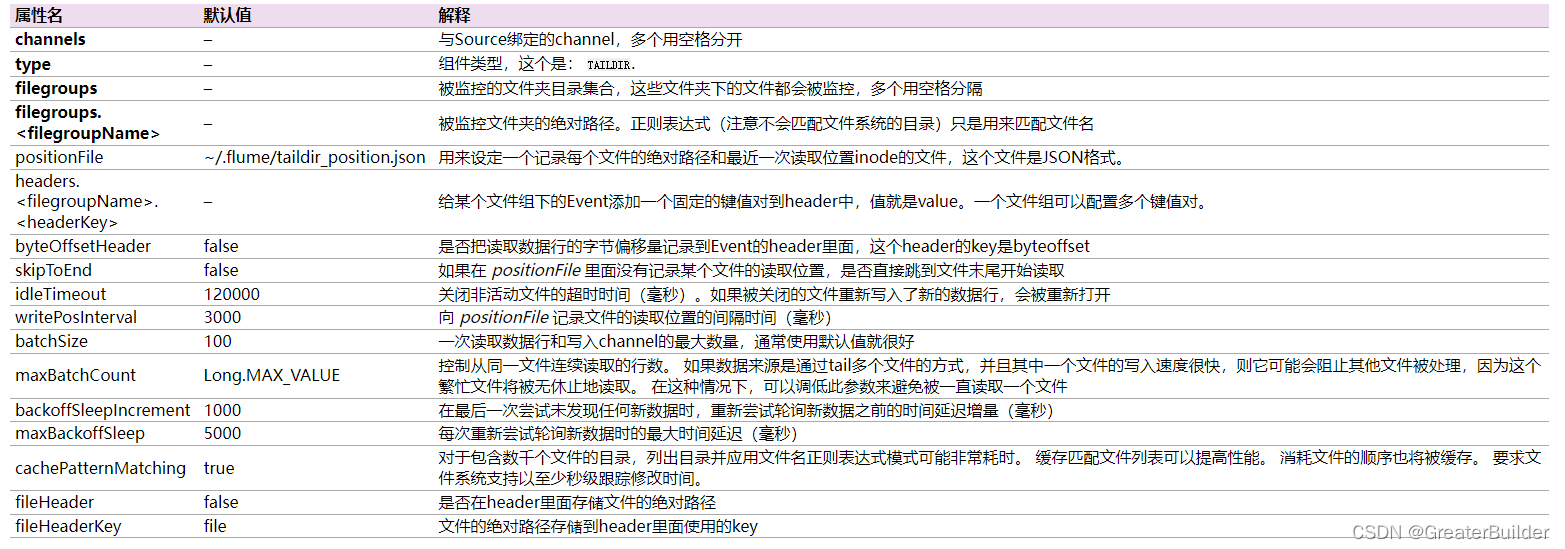
Taildir Source说明:
Memory Channel说明如下:

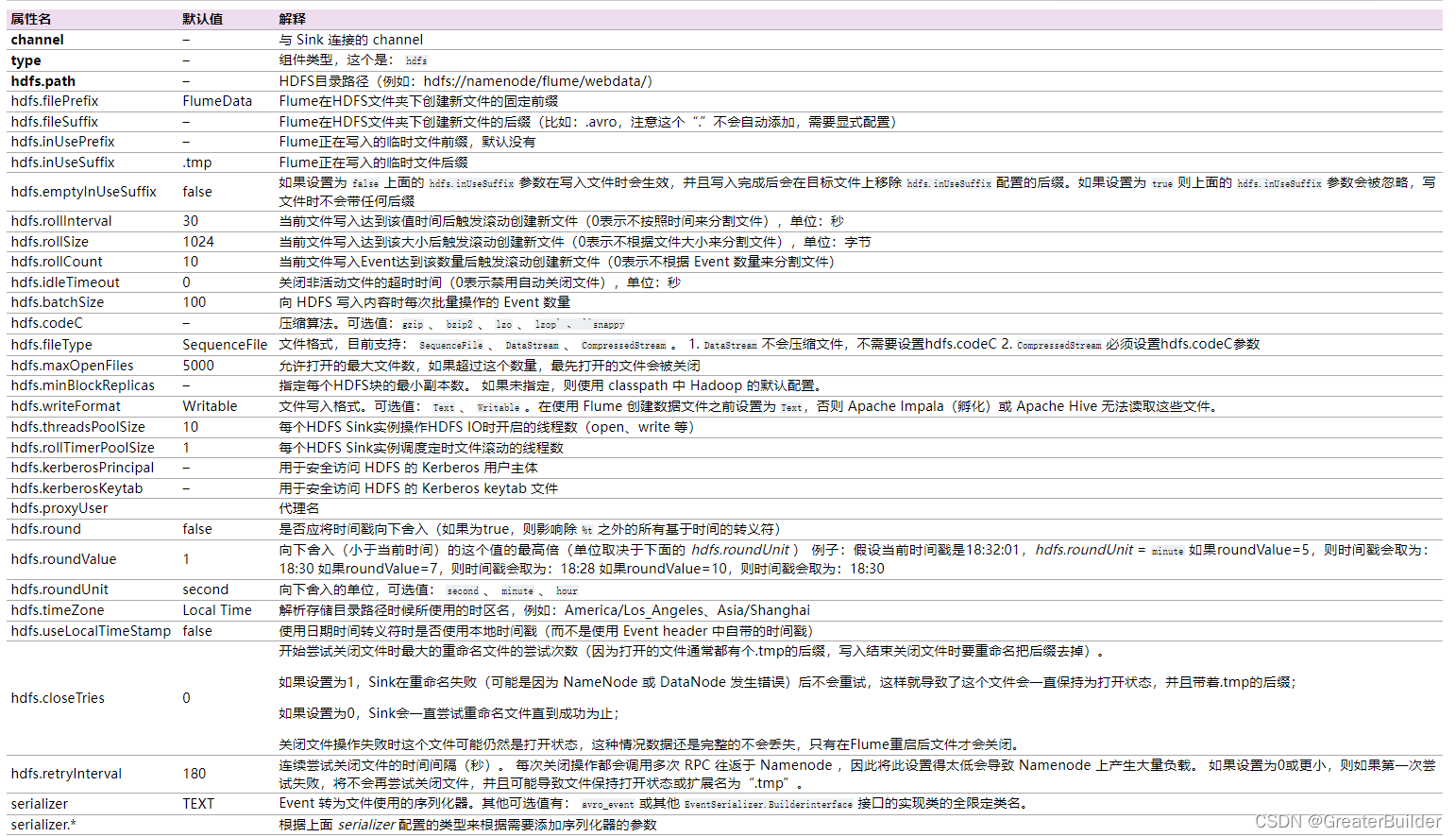
HDFS Sink说明如下:
4、启动flume agent
进入到flume的解压目录下执行如下命令,注意更换配置文件的路径:
./bin/flume-ng agent --conf ./conf --conf-file ../file2hdfs.conf --name a1 &
解压目录下可查询flume运行的日志记录:

启动命令说明如下:
--name 后面的名称需要配置为自己的agent名称,也就是自己--conf-file文件中配置的第一个单词,我的配置为a1
5、验证
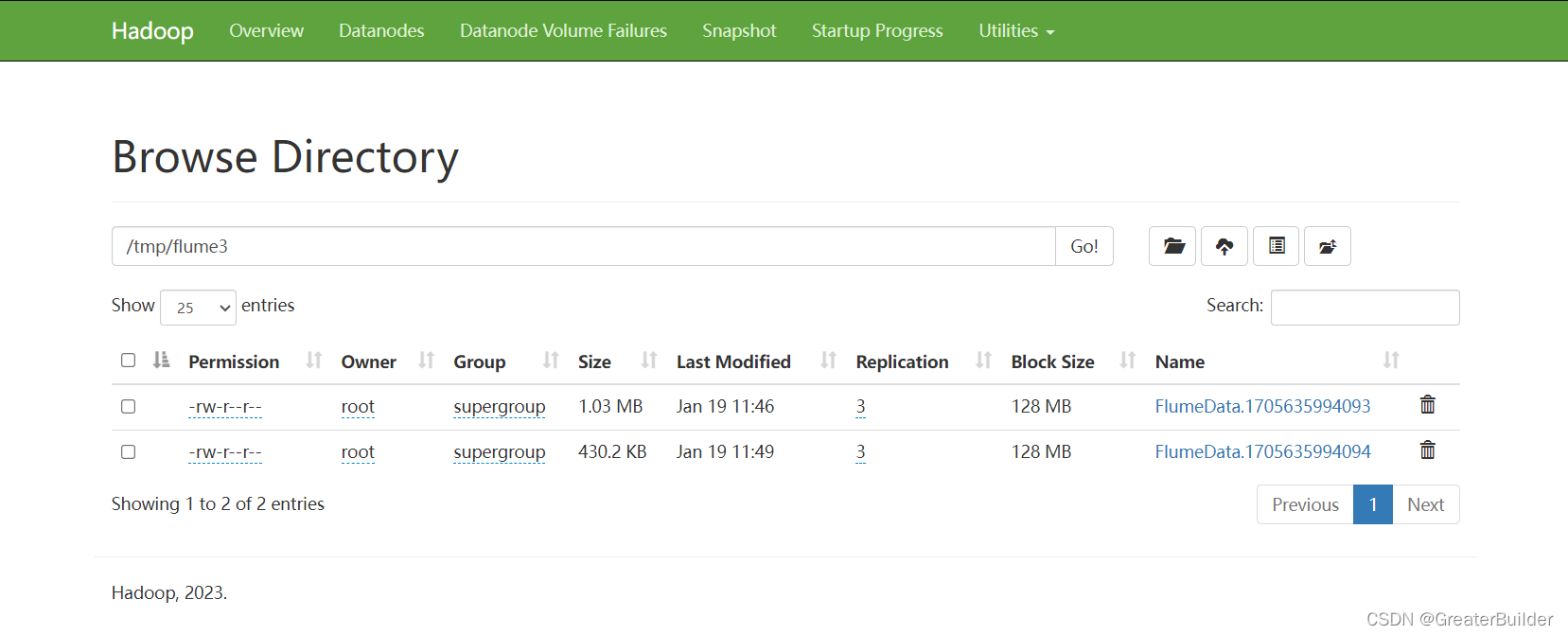
不断向111.log文件中写入内容,进入到hdfs中查看log文件是否已同步到指定的路径中:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!