Shell 脚本基础
Shell脚本
脚本以#!/bin/bash开头
执行方式
-
直接使用文件名执行:文件需要执行权限
-
以
bash xxx.sh来执行, 本质上是bash解析器去执行, 文件作为一个输入, 因此可以不需要执行权限
变量
系统变量
自定义变量
定义变量
# 定义一个变量username, 注意不能有多余的空格
username=ROOT

# bash中变量默认类型都是字符串
x=1+1
echo $x

# 将变量提升为全局变量, 使得其他的shell程序可以使用
export <变量名>
特殊变量
$n:表示第 n 个参数, 其中$0表示文件名$#:获取所有的输入参数的个数, 即 n 的值$*:获取所有的输入参数, 将输入参数看作是一个整体(本质上:将空格看作是参数的一个字符)$@:获取所有的输入参数, 把每个参数区分对待$?:判断上一条命令是否正确执行,- 如果返回值为0, 则说明上一条命令执行成功
- 返回值非0, 则说明上一条命令执行失败
运算符
-
expr <表达式>
-
$[<表达式>](推荐)
执行表达式 (3 + 2) * 4 的案例


条件判断
[ <条件判断> ](注意前后需要方括号的前后需要添加空格)
-
字符串比较
-lt:小于-le:小于等于-gt:大于-ge:大于等于-eq:等于-ne:不等于

-
按照文件权限进行判断
-r:有读权限-w:写权限-x:执行权限
-
按照文件类型进行判断
-e:文件存在-f:文件存在, 且是一个普通文件-d:文件存在, 且是一个目录文件

流程控制
if分支
if [ <条件判断表达式> ];then
# if分支
elif
# else分支
fi
case语句
case <变量引用> in
<情况一>)
# 分支一, 必须要加")"
;;
<情况二>)
# 分支二
;;
*)
# 默认分支, 相当于default
;;
esac
for循环
for(( <初始值>;循环控制条件;变量变化 ))
do
# 程序主体
done
案例应用:计算1到100的累和
#!/bin/bash
sum=0
for((i=1;i<=100;i++))
do
# 不支持+=的方式, 其中$[]表示运算表达式
sum=$[$sum + $i]
done
echo $sum
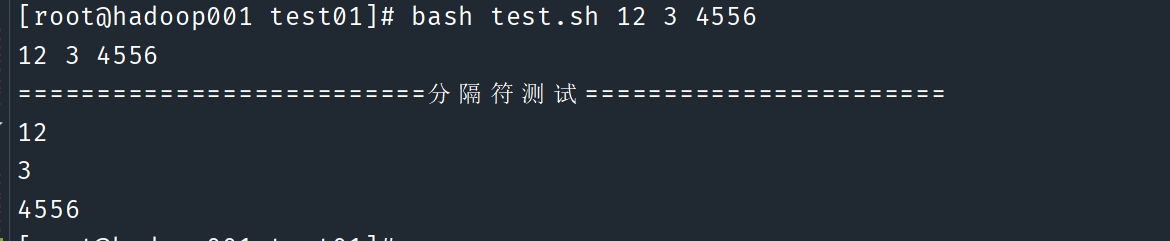
案例应用:打印所有的输入参数 (比较 $ 和 $@)*
#!/bin/bash
for i in "$*"
do
echo $i
done
echo "==========================分隔符测试======================="
for i in "$@"
do
echo $i
done
while循环
#!/bin/bash
sum=0
i=0
while [ $i -le 100 ]
do
sum=$[$sum + $i]
i=$[$i + 1]
done
read读取控制台输入
相当于读取一个输入变量
#!/bin/bash
second=7
read -t $second -p "提示信息: 请在 $second 秒内输入 name 的值. " name
echo "您输入的 name 的值为: $name"
函数
系统函数
# 获取最后一个"/"后面的字符串
basename <文件路径>
# 获取最后一个"/"前面的字符串
dirname
案例应用: 获取当前文件夹所在的 basename 和 dirname
#!/bin/bash
# 反引号表示其中的字符串当作bash命令进行执行
echo `pwd | xargs -I {} dirname {}`
echo `pwd | xargs -I {} basename {}`
自定义函数
函数不可以写形参, 只能通过
$1,$2这种形式来获取传入函数的值
#!/bin/bash
# 注意: 函数不能写形参列表, 因此()内部必须是空, 甚至也可以不写()
function <函数名>()
{
# 函数主体, 可以有返回值
}
案例应用:计算两个输入值的和
#!/bin/bash
# 定义add()函数
function add()
{
# 传入两个值, 将其相加
result=$[$1 + $2]
echo $result
}
# 准备工作, 读取数据
read -p "请输入x的值: " x
read -p "请输入y的值: " y
# 调用add()函数
add $x $y
shell工具 (重点)
cut
cut [选项参数] <文件路径>
-
-f:指定提取第几列-f 3:表示获取第3列-f 3-:表示获取第3列及其之后的数据的原始结果-f -3:表示获取第3列及其之前的数据的原始结果-f m-n:表示获取从第m列到第n列的数据的原始结果
-
-d:指定分隔符, 默认分隔符是制表符
注意cut并不能使用正则表达式的功能, 只能生硬的格式匹配
可以和grep搭配使用, 先进行一些数据的过滤, 然后在进行切分
sed (文件处理工具)
按行处理文件, 并将处理结果发送到控制台上, 源文件的内容默认并不会发生改变, 除非将输出结果重定向到源文件中
案例应用
-
将“hello world”插入到指定文件的第 2 行下面
# 2: 表示第2行 # a: 表示插入模式 sed "2a hello world" data.txt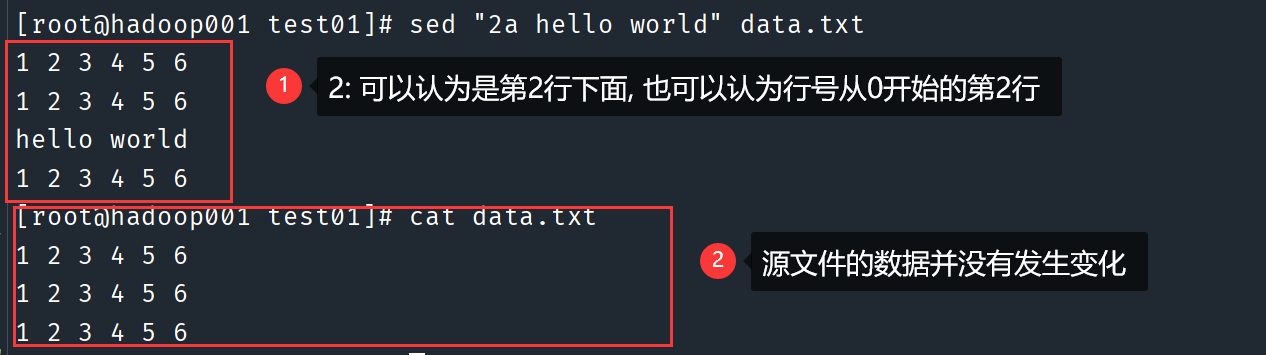
# 使用 -i 选项可以将输出流重定向到源文件中, 因此控制台不会产生输出, 并且源文件发生修改 sed -i "2a hello world" data.txt
-
删除指定文件中包含“hello”的行
# /hello/: 表示"hello"字符串, 注意用两个斜杠包围起指定的字符串 # d: 表示删除模式 sed "/hello/d" data.txt
-
替换指定文件中的“2”为 “7”
# s: 表示替换模式 # g: 全局替换, 默认情况下只替换第一次出现的 sed "s/2/7/" data.txt sed "s/2/7/g" data.txt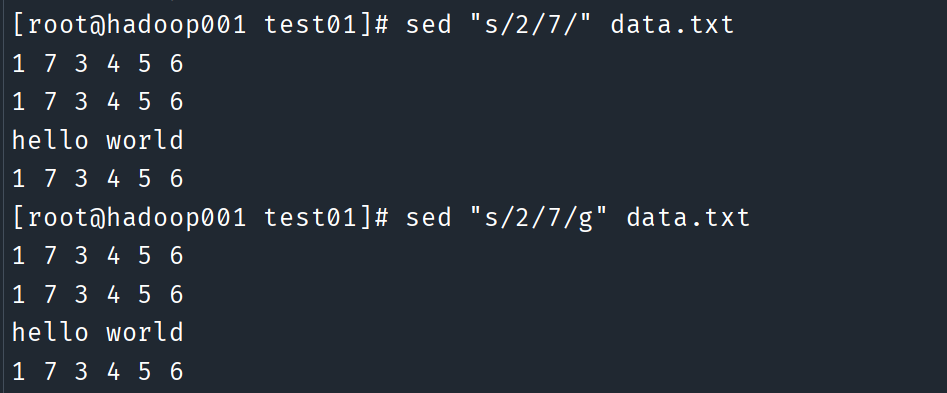
awk
格式:awk [选项参数] '<命令1> <命令2> <...>' <文件名>
-
-F:指定输入文件的分隔符, 默认是空格 -
-v:可以定义一个变量并为其赋值, 之后在动作中可以使用该变量, 例如-v i=1定义了一个变量i, 其值为1内置变量, 可以直接在动作中使用
- FILENAME:文件名
- NR:已读的记录数(模式匹配时光标所处的行号)
- NF:浏览记录的域的个数(即切割后, 列的个数)
-
<命令>:命令由模式匹配+动作组成, 模式匹配中可以使用正则表达式
案例应用
-
搜索 passwd 文件中以root开头的所有行, 并输出该行的第1列和第7列
-
原始文件
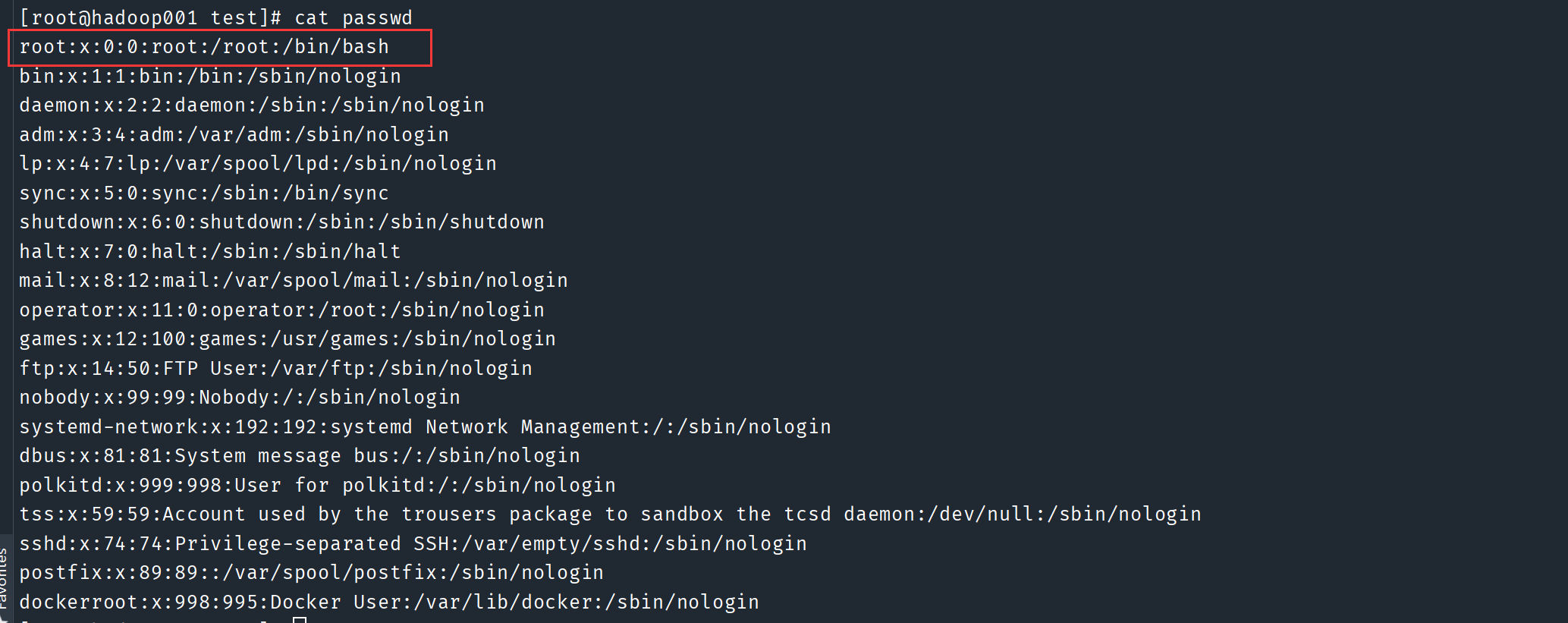
-
代码
# 从原始文件可以看作, 使用":"进行分隔 # 1. 使用 -F : 来指定使用":"进行分割 # 2. /^root/ 表示模式匹配部分, 两个"/"之间的内容是正则表达式, ^root表示以root开头 # 3. {} 中包含着要执行的动作, $1和$7分别表示分割后的第1列和第7列, # 4. 特别原始的字符串拼接 $1","$7 = $1 + "," + $7 # 5. 只有匹配了^root的行, 才会执行后面的{}中的动作 awk -F : '/^root/{print $1","$7}' passwd -
效果展示

-
-
只显示passwd文件的第1列和第7列, 以逗号分隔, 并且在所有行的前面添加一个列名, 在所有行的末尾新添加一行数据
多个需求的应用展示
awk -F : 'BEGIN{print "user,filepath"} END{print "hello,world"} {print $1","$7}' passwd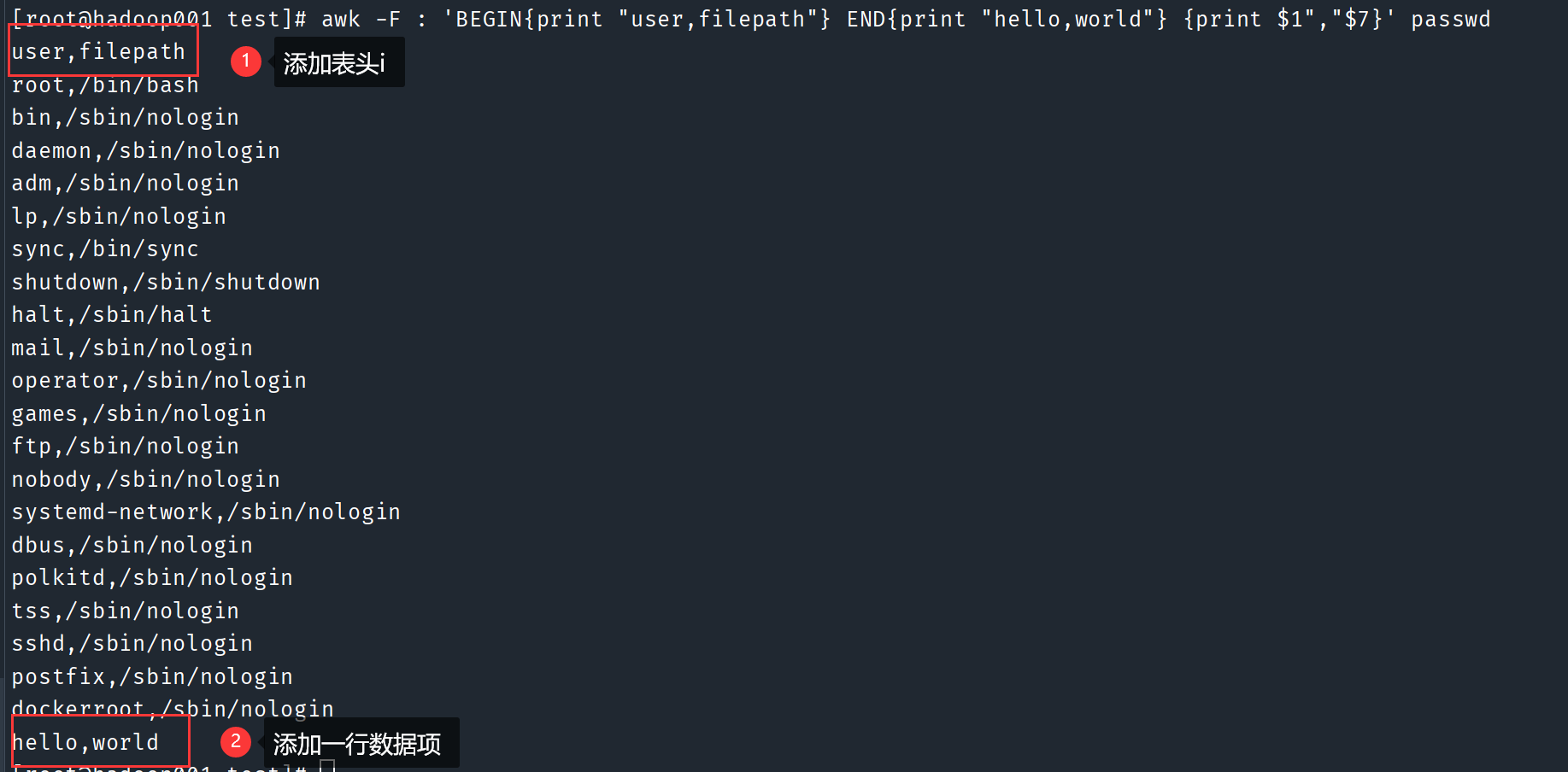
-
读取空行所在的全部行号
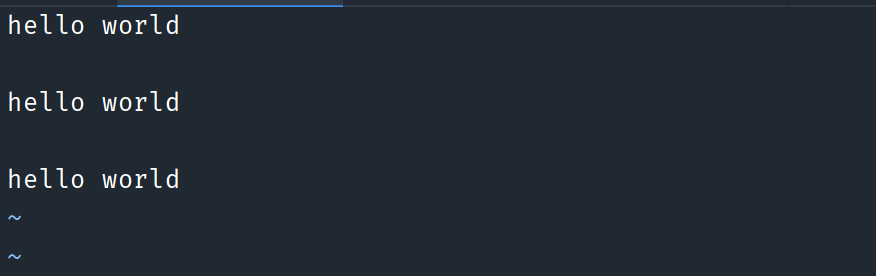
# 正则表达式^$表示空行 # NR表示当前读取到的光标的位置, 用来输出行号 awk '/^$/{print NR}' data.txt
sort
排序不改变源文件, 除非重定向
-n:按数值大小进行排序-r:逆序排序-t:设置排序时所用的分隔符-k:指定按哪一列进行排序
案例应用
-
数据文件
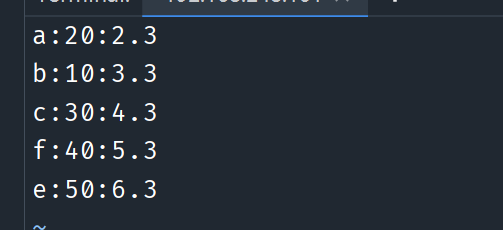
-
按
:进行分隔, 按切分后的第3列进行逆序排序sort -t : -n -r -k 3 sort.data # 没有带输入参数的选项可以合并, 因此可以简写为 sort -t : -nrk 3 sort.data
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- gazebo+URDF文件
- 理德外汇名人故事:欧洲股神——安东尼·波顿
- 2024年美国大学生数学建模思路 - 案例:最短时间生产计划安排
- 【斗破年番】炎盟危机,三宗之围,魔兽山脉突破斗皇,剧情火爆
- 提升设备巡检效率:易点易动设备管理系统的应用
- 【Python进阶实战】全局变量的进阶使用(线程并发)
- 中间件框架知识进阶
- Spring Bean 生命周期的执行流程?
- 深入研究矫正单应性矩阵用于立体相机在线自标定
- 线上研讨会 | 智能供应链计划与高级排程APS助力转型变革