Redis“垃圾”过期死键管理与优化
【作者】付磊
Redis死键的定义不尽相同,通常有两种:
-
写到Redis里后,由于过期时间过长或者压根没有过期时间,加之长期不访问,这类key可以被称为死键。
-
明明已经过了过期时间,但还占用Redis内存(没有真的删除),这类key也可以被称为死键。
注:本文讨论第二种情况
一、两个例子
下面两个列子中的键值均有过期时间,同时有些键值已过期
1. 对某Redis集群进行全量scan后,键值数和容量的变化:
| 键值数 | 容量GB | |
|---|---|---|
| 扫描前 | 5,628,636,513 | 1116 |
| 扫描后 | 4,206,662,303 | 798 |
2. 两个同名不同版本的Redis集群的键值数和容量(全部为string类型)
| 版本 | 键值数 | 容量GB |
|---|---|---|
| Redis 4.0.14 | 821,131,528 | 831 |
| Redis 6.0.15 | 821,131,528 | 433 |
初步结论:
-
scan操作可能会加速Redis的过期键值删除。
-
Redis 6版本比Redis 4在同等数据下更节省空间,考虑到Redis成本优化-版本升级-1.SDS优化历史一文中提到4.0~7.0字符串类型在容量上并没有过多优化,因此初步判定Redis 6可能在过期上做过优化
二、基础知识-Redis过期
1. Redis过期数据怎么存?
每个Redis有多个redisDb(但正常只用db0),每个redisDb包含两个dict:dict存key-value、expires存key的过期时间
typedef?struct?redisDb?{
????dict?*dict;?????????????????/*?The?keyspace?for?this?DB?*/
????dict?*expires;??????????????/*?Timeout?of?keys?with?a?timeout?set?*/
????...
}?redisDb;
具体如图所示
(1) 正常的dict图:(该图来自《Redis设计与实现》)

(2) 抽象的表现dict和expires表可以使用如下图:(来源于google图片)
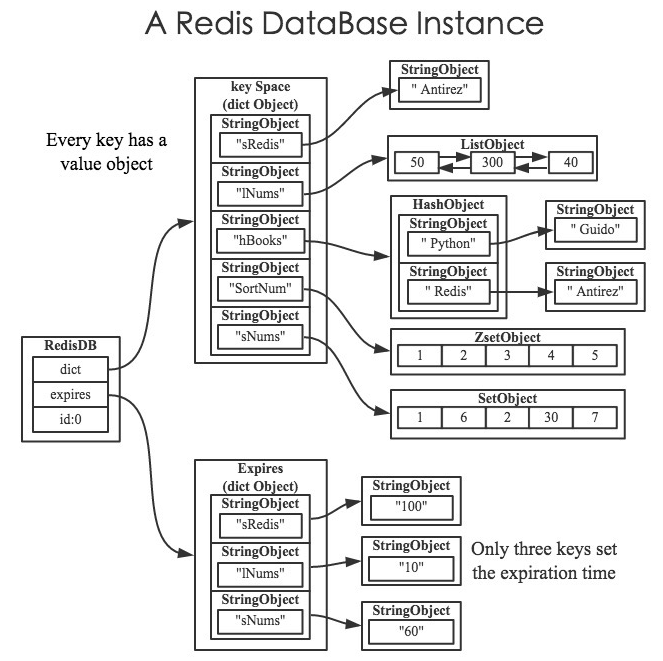
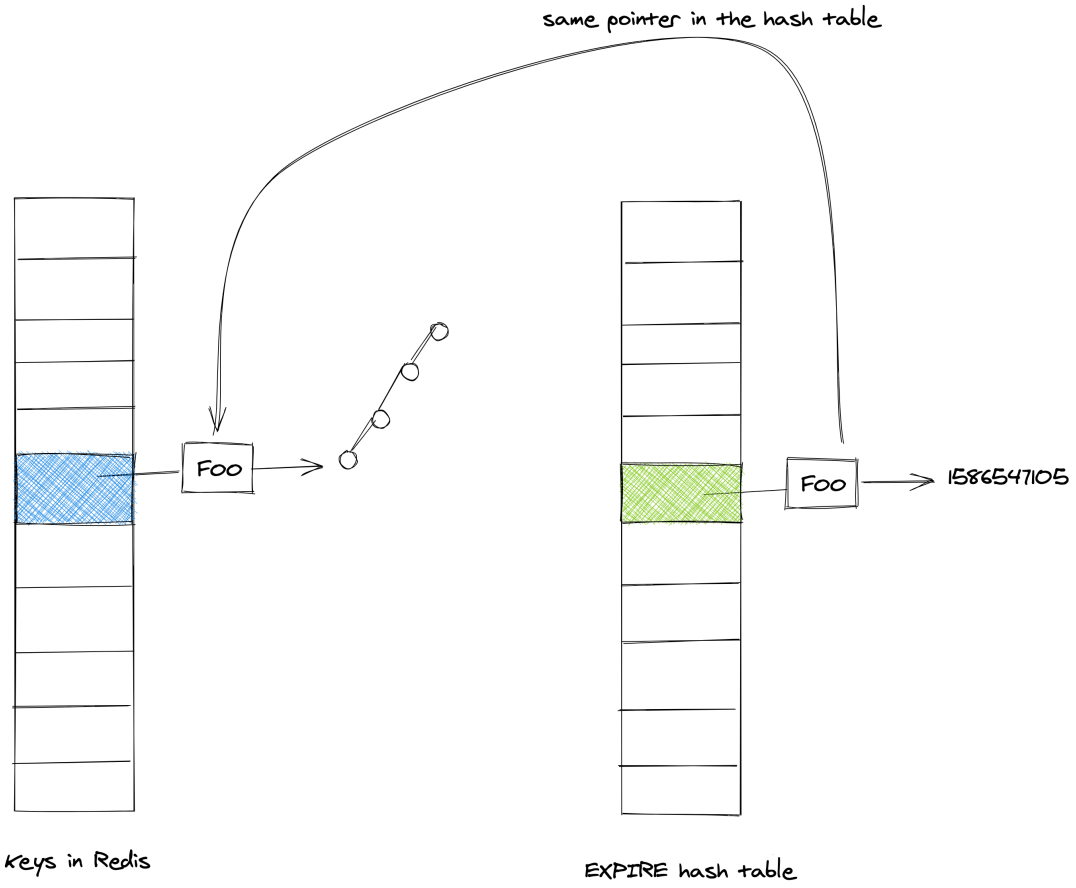
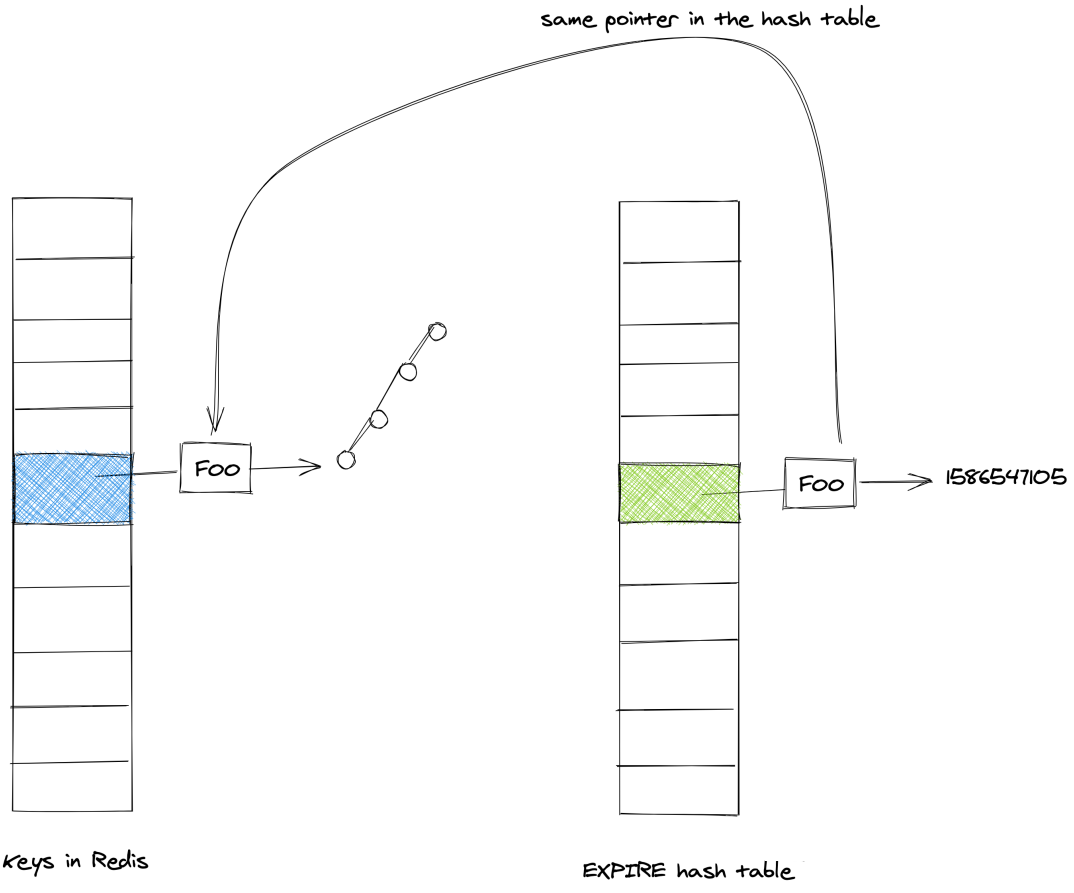
再次借个图:expires中key stringobject和dict中的 key stringobject是同一个:
2. Redis过期策略
由于Redis单线程(work thread)的特性,如果精准实时删除每个过期键值,会耗费大量CPU。所以Redis折中实现两种过期删除策略:惰性删除和定期删除。
(1) 惰性删除
客户端执行key相关命令时(以get为例子),首先会去检测key是否在expires表里:
-
如果在expires表里
-
如果已经过期:直接删除,并返回空
-
如果没有过期:从dict表里获取value
-
-
如果不在expires表里,从dict表里获取value
(2) 定期删除
惰性删除的问题是依赖于主动访问,如果一直不访问,数据将长期保存,造成内存浪费,于是需要添加新的策略:定期删除。
Redis会每100毫秒(如果hz默认是10),会对expires表中已过期数据进行自适应算法删除(具体方法下面会详细介绍)。
三、Redis版本优化
为了更生动的表现Redis 6在死键上的升级,可以做如下实验:写入500万条string,key和value都是16字节,过期时间在1-18秒
| 版本 | 全部数据过期耗时 |
|---|---|
| Redis 4.0.14 | 38262ms |
| Redis 6.0.15 | 19267ms |
1. Redis 6.0之前:
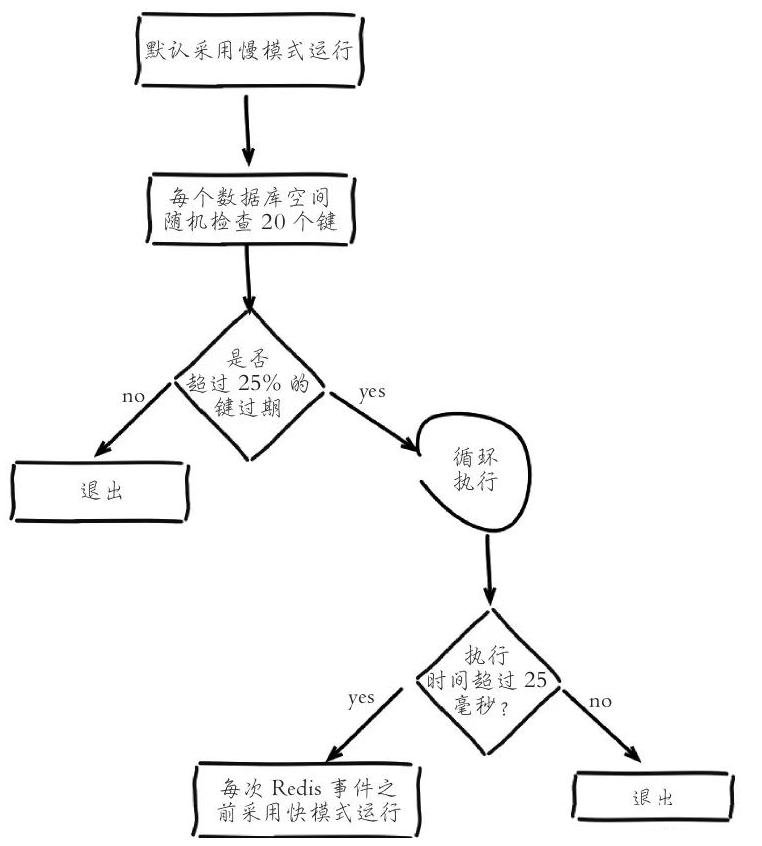
Redis定期删除过期有两种模式:快模式和慢模式(默认)
注意:
1. 快模式:希望每次定期删除快速结束,防止占用Redis处理正常命令的CPU。
2. 快模式和慢模式在执行过程中自适应的进行转换,本质都是防止占用Redis处理正常命令的CPU。
3. 快模式和慢模式:只是超时时间不同,删除逻辑是一样的
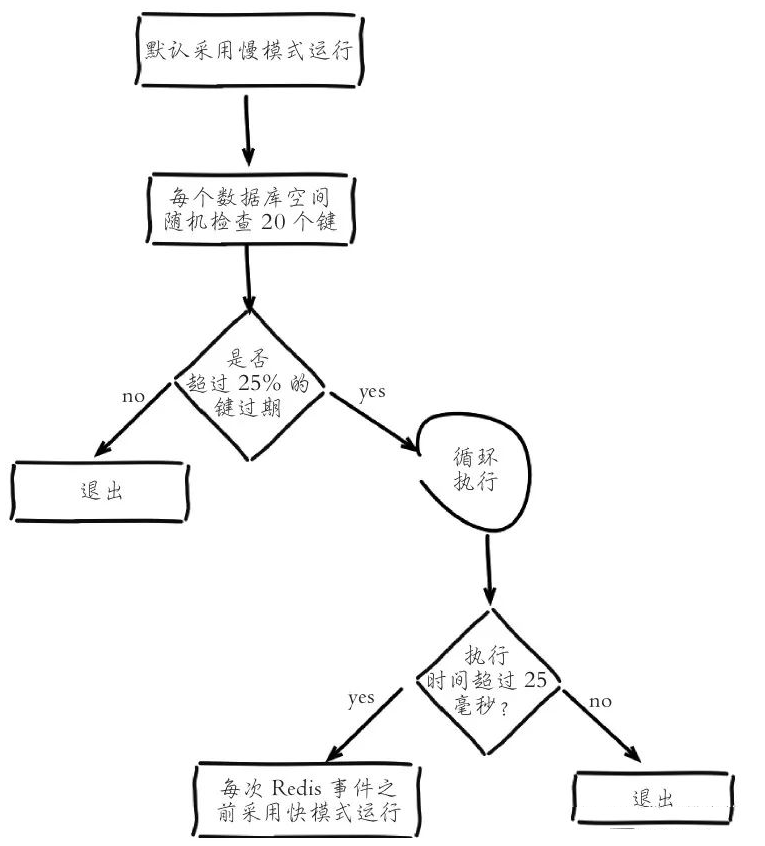
默认进入慢模式:
(1) 循环遍历全部redisDb,随机抽取20个键值,如果发现过期就直接删除。
(2) 判断20个键值中的25%(也就是5个)是否过期
-
如果小于等于25%,则退出当前redisDb的循环,继续下一个redisDb
-
如果大于25%,继续抽取20个键值进行循环,每次判断总的执行时间是否超过25毫秒
-
超过25毫秒,过期进入快模式(超时时间会变短)
-
没超过25毫秒,则退出当前redisDb的循环,继续下一个redisDb
-
几个重要参数:
#define?ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP?20?/*?上述的20个键值?*/
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /*?慢模式超时时间:25%的CPU时间?*/
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000?/*?快模式超时时间:1ms */
2. Redis 6.0优化
(1) 每次随机-->记录遍历游标
Redis 6.0之前每次执行定期删除都是随机抽取20个键值,如果当前Redis有过期时间的键值数量较多(例如几百万、几千万),那么这个随机会导致很多key不会被扫描到,因此在Redis 6.0中在redisDb加了一个游标(expires_cursor),记录上一次扫描的位置,可以保证最终全部的键值会被扫描到,有效的提升效率。
typedef?struct?redisDb?{
????dict?*dict;?????????????????/*?The?keyspace?for?this?DB?*/
????dict?*expires;??????????????/*?Timeout?of?keys?with?a?timeout?set?*/
????unsigned?long?expires_cursor;?/*?Cursor?of?the?active?expire?cycle.?*/
???.......
}?redisDb;
(2) 判断20个键值中的25%(也就是5个)-->10%(也就是2个)
Before 6.0:
do?{
???num?=?ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP
???while?(num--)?{
????????//检测每个key的过期时间,并做相关记录,如果已经过期expired++
????}
}?while?(expired?>?ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
After 6.0,config_cycle_acceptable_stale可调配
do?{
???num?=?ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP
???while?(num--)?{
????????//检测每个key的过期时间,并做相关记录,如果已经过期expired++
????}
}
}?while?((expired*100/sampled)?>?config_cycle_acceptable_stale);
(3) 添加增强系数
新增active_expire_effort配置,可以适当增强定期删除粒度,它的值范围在1-10。
unsigned?long?effort?=?server.active_expire_effort-1,?/*?Rescale?from?0?to?9.?*/
//增加每次扫描key的个数
config_keys_per_loop?=?ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP?+??ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
//增加快模式的超时时间
config_cycle_fast_duration?=?ACTIVE_EXPIRE_CYCLE_FAST_DURATION?+??ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
//增加慢模式的超时时间
config_cycle_slow_time_perc?=?ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC?+?2*effort,
//上述while中的比率
config_cycle_acceptable_stale?=?ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-?effort;
四、为什么会有死键、危害是什么
1. 为什么会有死键
(1) 惰性删除:如果很多key不会被二次访问,就会产生死键
(2) 定期删除:如果过期键值生产速度大于定期删除速度
针对(2)有两种情况:
第一种:当前Redis有大量写入同时键值过期时间都很短。
第二种:当前Redis包含大量键值(例如百万级别),但已经过期的数据只占很小的比率,这种相对诡异。
我们还是举个例子:线上某集群
| 键值数Million | 容量GB | |
|---|---|---|
| 扫描前 | 991.18 | 396.37 |
| 扫描后 | 814.58 | 296.90 |
我们可以分析它的键值空间:短过期时间只占很少的比率,它无法自行完成死键的快速过期。
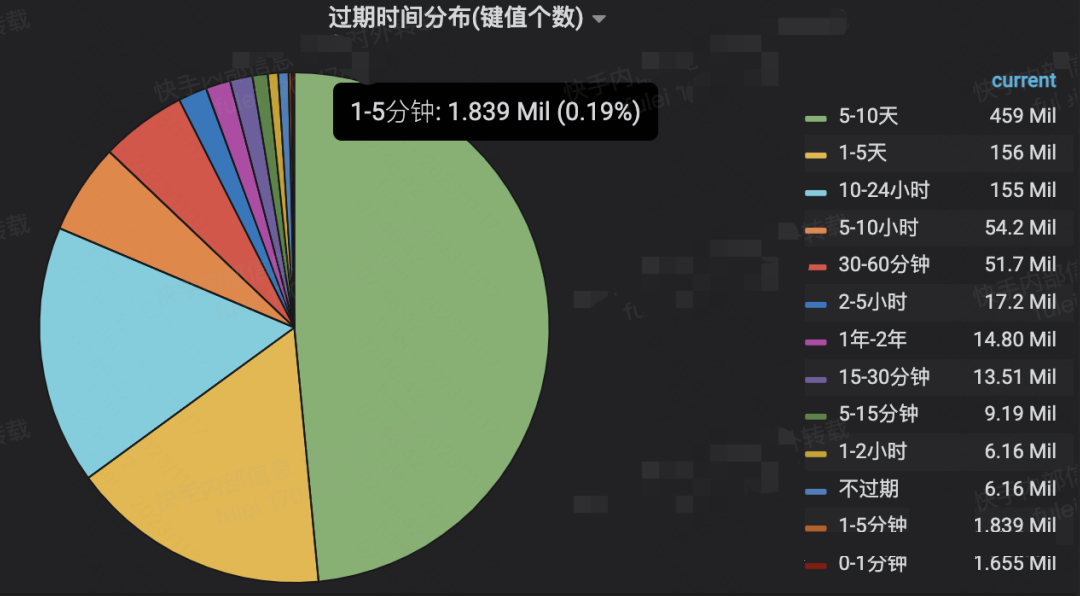
我们回到之前分析的流程图就很容易得出答案:每次遍历redisdb有个核心条件是是否超过25%的键值过期了,从上面的键值分析图可以判断,每次扫描大部分可能就循环一次。
2.死键的危害
危害本质:例如当前集群100GB, 键值如果没有死键只有50G,如果有死键可能就是90GB。
(1) 增加运维次数:业务侧可能会频繁提交扩容。
(2) 浪费成本:
(3) 可能产生逐出:不可预期的使用容量,可能会造成数据逐出(大部分逐出算法都是近似算法,例如lru)
五、如何解决
关于这个比较有意思的是看到官方给出的一个方法是重启,这个对线上环境不太现实(即使有failover)。我们在生产中可以使用如下方法:
1.适度调整active_expire_effort参数(针对Redis 6.0+)
怎么叫适度呢?我们要理解本质上Redis是要对外提供服务的,所以我们必须保证有足够多的CPU时间给正常的命令访问,Redis 4.0之后有个核心指标stat_expired_time_cap_reached_count可以作为参考,其实它就是记录了超时次数,代表在过期删除上投入过多CPU时间。
/*?We?can't?block?forever?here?even?if?there?are?many?keys?to
?*?expire.?So?after?a?given?amount?of?milliseconds?return?to?the
?*?caller?waiting?for?the?other?active?expire?cycle.?*/
if?((iteration?&?0xf)?==?0)?{?/*?check?once?every?16?iterations.?*/
????elapsed?=?ustime()-start;
????if?(elapsed?>?timelimit)?{
????????timelimit_exit?=?1;
????????server.stat_expired_time_cap_reached_count++;
????????break;
????}
}
可以对齐进行监控。
2.定期scan
当识别到某些集群有如下特点,可以借助外力scan(其实就是惰性删除)帮助过期键值数据删除,但是也要力度适度,例如要结合当前Redis的CPU繁忙程度进行sleep时间设定。

3. hz:
这个建议不要乱调整。。hz影响的地方不止这个,所以不要乱调(网上各种文章让调整这个,一定要慎重)
六、如何识别?
说句实话这个问题比较复杂,我也琢磨了挺长时间,可以大概归结成6点(欢迎大佬来喷)
1.expires表要“大”:
需要有一定规模(不然死键问题不存在),一般认为超过100万(但这个不绝对,比如第2中情况)
2.批量生成大量短过期时间的键值:
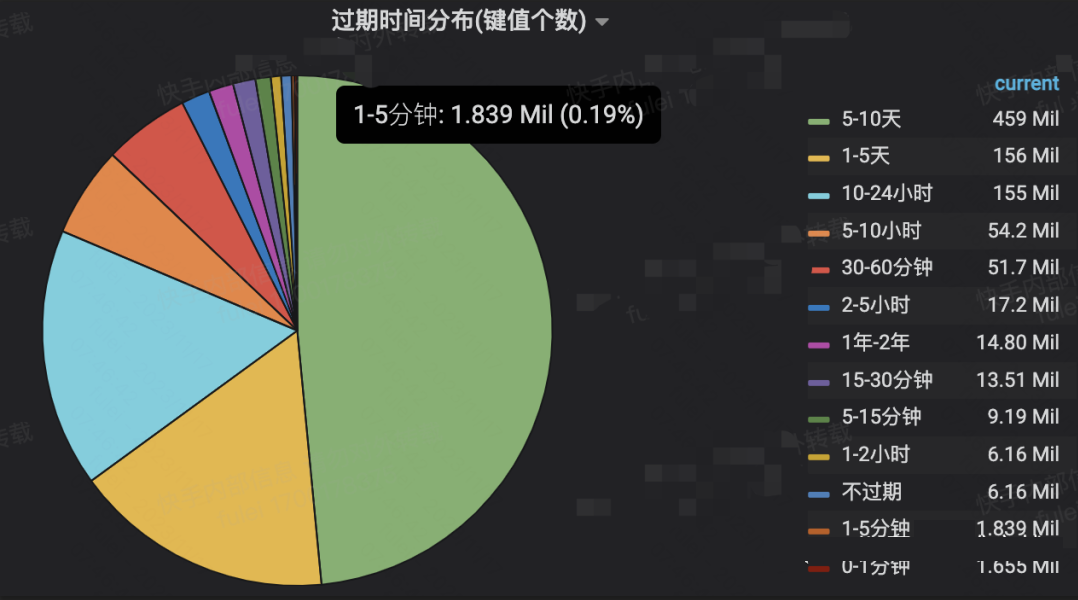
avg_ttl的例子如下:
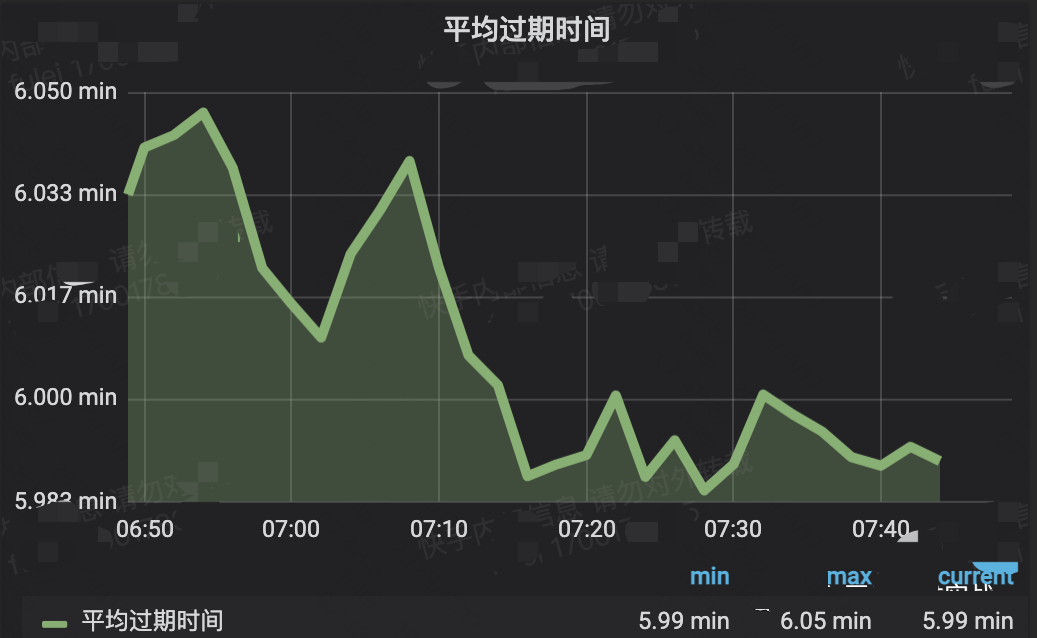
键值分析的效果如下:
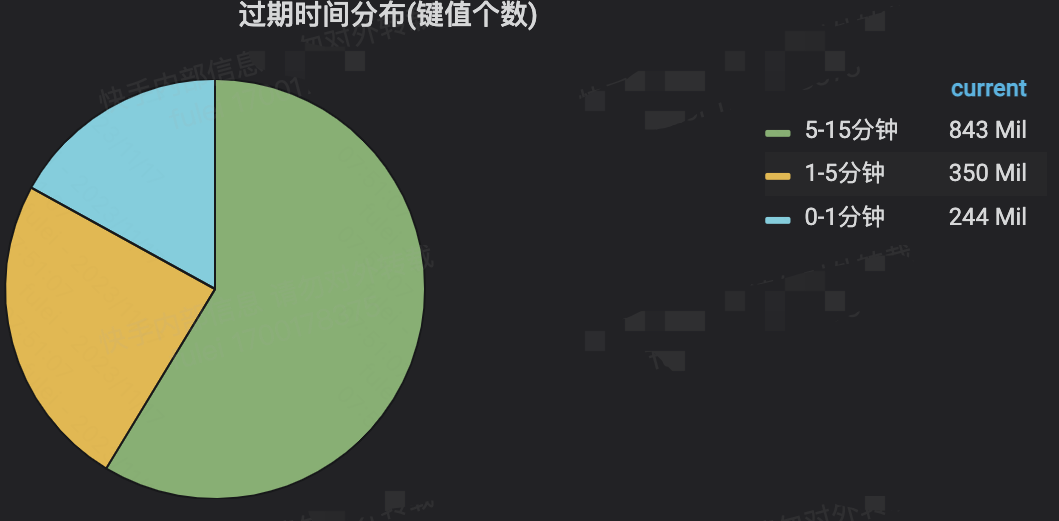
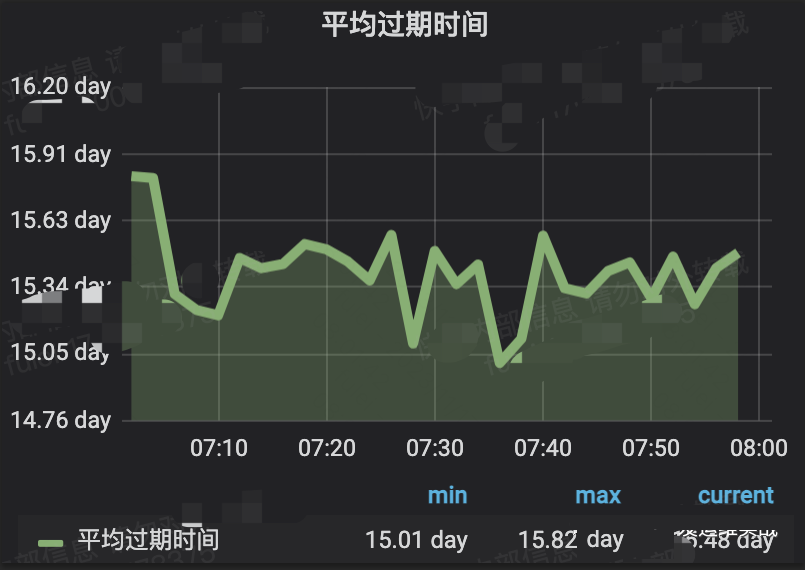
3.avg_ttl不可靠
avg_ttl是一个近似值,同时它会受到非常长过期时间的干扰(俗称“被平均”),上述中例子就是个典型,avg_ttl是15day,但是确实包含了大量死键
4.利用stat_expired_time_cap_reached_count定位
stat_expired_time_cap_reached_count比较频繁说明过期键值很多,因为已经超时了,可以把全部实例绘图监控或者告警
5.键值分析结合stat_expired_stale_perc指标
stat_expired_stale_perc是total_expired/total_sampled的近似比率,如果偏高说明过期键值很多,如果偏低,需要结合键值分析看是否受到了整体的干扰。
double?current_perc;
if?(total_sampled)?{
????current_perc?=?(double)total_expired/total_sampled;
}?else
????current_perc?=?0;
server.stat_expired_stale_perc?=?(current_perc*0.05)+
?????????????????????????????????(server.stat_expired_stale_perc*0.95);
6. 终极绝招:scan后给集群打标签
低峰期对每个可疑集群进行清理scan,记录前后键值容量变化,对集群进行标签后,开启定期scan

请控制好redis实例的键值个数
参考Redis开发规范解析(三)--一个Redis最好存多少key
七、最后一个小实验
如何证明expires中的key和dict中的key是同一个。
实验:在Redis 6.0.15插入两组数据
| key数量 | 键值 | 过期时间 | used_memory_human |
|---|---|---|---|
| 500万 | string类型,key和value都是16字节 | 不过期 | 598.158MB |
| 500万 | string类型,key和value都是16字节 | 过期时间1天 | 776.599MB |
| 多出:178.44MB |
现在对第二组数据执行debug htstats
127.0.0.1:12615>?debug?HTSTATS?0
[Dictionary?HT]
Hash?table?0?stats?(main?hash?table):
?table?size:?8388608
?number?of?elements:?5000000
?different?slots:?3766504
?max?chain?length:?10
?avg?chain?length?(counted):?1.33
?avg?chain?length?(computed):?1.33
?Chain?length?distribution:
???0:?4622104?(55.10%)
???1:?2755189?(32.84%)
???2:?820438?(9.78%)
???3:?163161?(1.95%)
???4:?24475?(0.29%)
???5:?2930?(0.03%)
???6:?278?(0.00%)
???7:?32?(0.00%)
???10:?1?(0.00%)
[Expires?HT]
Hash?table?0?stats?(main?hash?table):
?table?size:?8388608
?number?of?elements:?5000000
?different?slots:?3766504
?max?chain?length:?10
?avg?chain?length?(counted):?1.33
?avg?chain?length?(computed):?1.33
?Chain?length?distribution:
???0:?4622104?(55.10%)
???1:?2755189?(32.84%)
???2:?820438?(9.78%)
???3:?163161?(1.95%)
???4:?24475?(0.29%)
???5:?2930?(0.03%)
???6:?278?(0.00%)
???7:?32?(0.00%)
???10:?1?(0.00%)
下面分别计算:
(1) table size: 8388608,每个需要8个字节指针 ?= 8388608 * 8 / 1024 / 1024 = 64MB
(2) number of elements: 5000000,刨除dictEntry中的key(这里假设是共享的),value = 16字节(一个int编码的redisobj,为什么是16字节(redis 6),请参考Redis成本优化-版本升级-1.SDS优化历史加上一个8字节next指针,最终折合=5000000 * (16 + 8 ) /1024/1024=114.44MB
最终我们可以验证expires中的key和dict中的key是共享的。
八、几个思考
1.为什么Redis的过期不能立即删除
2.为什么不能用过期事件功能:用事件通知删除。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前端工程化及其实践1
- 【51单片机】LED 点阵
- 解析动态规划
- fetch、axios 和 XMLHttpRequest的区别
- 【乱七八糟的经验】【个人】打羽毛球如何球球都接稳
- Java使用POI库读取Excel表格代码实战详解
- 服务端开发中的数据库交互与数据存储
- STM32-HAL库11-SPI通讯(F103C6T6做主机,F103C8T6做从机)
- 只更新软件,座椅为何能获得加热功能?——一文读懂OTA
- SQLServer设置端口,并设置SQLServer和SQLServer Browser服务