Linux信号
目录
1. 什么是信号
在日常生活中,有那些信号相关的场景呢?
例如:红绿灯、转向灯、闹钟、王者荣耀信号等等;
上面都是一些生活中的一些信号;
那么问题来了: 你为什么可以识别这些信号呢?
我们之所以能够识别一个信号,是因为:我们记住了对应场景下的信号 以及 当这个信号产生之后,后续是有 "动作" 需要我们去执行的!
由于我们具有识别信号的能力,如果特定信号没有产生,但是我们依旧知道应该如何处理这个信号!
当我收到某个信号的时候,可能不会立即处理这个信号,即不会立即去执行该信号的后续处理动作,因此,信号本身,在我们无法立即处理信号的时候,需要将该信号临时保存下来以便稍后处理!
?2.?什么是Linux信号
Linux信号本质是一种通知机制,用于通知进程某些事件已经发生。这些事件可以是各种不同的情况,如终端按键输入、系统调用、软件条件、硬件异常等。用户 or 操作系统 (本质上所有的信号都是OS发送的) 向目标进程发送一个信号,该进程可以在收到信号后根据需要执行某些操作,比如处理信号,终止进程,忽略信号等。通过这种机制,操作系统可以与进程进行交互,并允许进程根据发生的事件采取适当的行动。值得注意的是,有些信号可以由用户(或其他进程)发出以向目标进程发送特定的通知,但是所有的信号本质上都是由操作系统发送的。上面的潜台词:信号接收的载体是进程!
2.1.?结合进程,Linux信号的结论
1、 进程要处理信号,那么进程必须具备信号 "识别" 的能力!
2、 凭什么进程能够 "识别" 这些信号呢?程序员赋予进程的识别能力!进程可以知道这个信号以及当这个信号产生之后,后续处理动作是什么?
3、?信号产生是随机的,进程可能正在执行自己的代码逻辑?(当前进程执行的任务优先级更高 ),所以,信号的后续处理,可能不是立即处理的!
4、 既然不是立即处理,那么进程必须要临时保存对应的信号,以便后续处理!
5、 在什么时候处理呢? 这里有个笼统的概念:在合适的时候 (后续会解释)!
6、 一般而言,信号的产生相当于进程而言是异步的!
同步和异步是在计算机编程中常见的两种执行方式,它们描述了如何处理和等待任务的完成。
同步:同步是指一个任务必须等待另一个任务完成后才能继续执行。在同步执行中,任务按照顺序逐个执行,中间的任务需要等待前一个任务完成后才能开始。这样可以确保任务的执行顺序和结果的准确性,但是如果某个任务需要较长时间才能完成,会导致整体的执行效率降低。
异步:异步是指一个任务的执行不会阻塞后续任务的执行,任务可以继续执行而无需等待前一个任务完成。在异步执行中,任务被提交后会立即返回,然后通过回调函数、事件或轮询等方式等待任务的完成通知。异步执行能够提高系统的响应性和并发性,对于一些耗时的操作特别有效,但是对于任务之间的顺序和结果控制会更加复杂。
因此,区别在于同步执行需要等待任务完成,而异步执行可以继续执行其他任务而不需等待。同步通常简单可控,适用于简单的操作和顺序执行的场景,而异步适用于需要处理并发、提高响应性或处理耗时操作的场景。选择使用哪种方式取决于具体的需求和任务特点。
2.2. 信号处理的常见方式
a. 默认处理方式:当进程收到信号时,操作系统会根据信号类型和操作系统的默认信号处理方式来处理信号。例如,对于 SIGINT 信号 (Ctrl+C 产生的信号),默认处理方式是终止进程 (Term)。
b. 忽略 (也是信号处理的一种方式)
c. 自定义信号处理方式(捕捉信号):进程也可以通过调用 signal 函数,将信号处理方式设置成自定义信号处理方式。这种方式需要编写自定义的信号处理函数,用于处理信号求并采取适当的措施。例如,可以通过自定义信号处理函数来实现对 SIGINT 信号的捕获和处理,比如给用户一个提示,询问是否要退出程序。
需要注意的是,对于某些信号,如 SIGKILL(9号信号) 和 SIGSTOP(19号信号),无法忽略或自定义信号处理方式,这些信号总是会终止进程或挂起进程。
2.3. 常见的Linux信号
kill -l 可以查看 Linux所支持的信号列表!如下:

我们发现,上面的信号是没有0号信号,也没有32、33号信号!我们将 1 ~ 31号信号称之为普通信号,共31个普通信号;而带了RT字段的信号,即34 ~ 64信号,我们称之为实时信号,共31个实时信号;我们在本主题更关注的是普通信号,实时信号不考虑;?
操作系统主要分为实时操作系统和分时操作系统两种,它们主要的区别在于对于任务处理时的响应时间要求不同。
实时操作系统:实时操作系统主要用于处理对响应时间要求非常高的任务。这些任务需要以确定的时间间隔持续运行,并在规定的时间内完成。实时操作系统需要对任务的执行时间进行精确的掌控和调度,以满足其响应时间和时间限制等性能要求。通常,在实时操作系统中,短期响应和实时性至关重要,而长期性能则不太受关注。
分时操作系统:分时操作系统主要用于为多个并发程序提供共享计算机资源。分时操作系统提供处理器时间片分配机制,以保证每个程序都能在合理的时间内执行其任务。分时操作系统有多种调度算法来保证公平性、优先级、响应时间、节约系统资源等。分时操作系统最重要的性能指标是系统的稳定性和吞吐量。
实时操作系统和分时操作系统在调度方式和系统实现都有各自的差异。实时操作系统更注重响应时间和时间敏感性,会采用一些高效并实时的调度算法,同时避免一些会阻塞或延迟的操作,比如在I/O 操作上等待数据的到来。相反,分时操作系统更注重公平性和资源利用率,并更容易实现一些复杂的特性,比如多用户访问、多道程序设计等。
man 7 signal 可以查看信息的详细信息!
对于 1 ~ 31 的普通信号,我们需要了解一些非常常见的信号:
SIGHUP (Hangup):当终端连接断开时发送给进程的信号。通常在用户注销或终止终端会话时生成。默认行为Term;
SIGINT (Interrupt):当用户通过在终端键入 "?Ctrl+C "?时发送给前台进程组的信号。通常用于中断该进程的执行。默认行为Term;
SIGQUIT (Quit):当用户通过在终端键入 "?Ctrl+ \ "?时发送给前台进程组的信号。与 SIGINT 类似,但会生成一个包含进程转储(core dump)的信号。默认行为Core;
SIGABRT (Abort):由应用程序自身或库函数调用发送给进程的信号,用于异常终止进程并生成一个包含进程转储(core dump)的信号。默认行为Core;
SIGFPE (Floating Point Exception):在出现浮点运算错误时发送给进程的信号。比如除以零、溢出等。默认行为Core;
SIGSEGV (Segmentation Violation):在出现内存访问违规时发送给进程的信号,比如非法的内存访问、栈溢出等。默认行为Core;
SIGPIPE (Broken Pipe):在进程向无读取进程或已关闭写入端的管道写数据时发送给进程的信号。默认行为Term;
SIGCHLD (Child Status Change):在子进程变更状态时发送给父进程的信号。父进程通常使用这个信号来等待和处理子进程的退出状态。默认行为Ign;
SIGCONT (Continue):用于恢复被暂停的进程(通过 SIGSTOP 或 SIGTSTP 信号)。通常由作业控制命令(如 bg)发送。默认行为Cont;
SIGSTOP (Stop):用于暂停进程的执行。无法被进程自己捕获或忽略。默认行为Stop;
SIGIO (I/O Possible):用于异步 I/O 事件通知给进程,特别是在套接字或文件上的可读或可写操作准备好时。默认行为Term;
SIGALRM (Alarm Clock):由 alarm 或设置的计时器到期时发送给进程的信号。通常用于定时器功能;默认行为Term;
SIGKILL:也被称为强制杀死信号,它是一种不能被捕获、阻塞或忽略的信号。使用 SIGKILL 信号可以立即终止一个进程的执行。当进程收到 SIGKILL 信号时,它将立即被操作系统终止,无论它当前正在执行什么任务。这是一种最后手段,常用于强制终止那些出现问题或无法响应其他信号的进程。
与其他信号不同,SIGKILL 无法被进程捕获和处理,也无法被系统进程或管理员阻止。因此,在使用 SIGKILL 时需要非常谨慎,因为它会直接终止进程并可能丢失未完成的工作。
要使用 SIGKILL 终止进程,可以使用 kill 命令或 kill() 系统调用,传递进程的 PID (进程标识符),例如:kill -9 PID。注意,-9 是终止信号的编号,也就是 SIGKILL 的编号。
2.4. 如何理解组合键变成信号呢?
我们之前说过," Ctrl + c " 可以终止前台进程,其 " Ctrl + c " 本质上就是操作系统通过识别并解释键盘组合键向目标进程发送2号信号,现象就是终止了前台进程 (本质上就是OS终止了该进程);那么组合键是硬件 (键盘输入),而信号是软件,如何将组合键变成信号的呢?
我们要知道键盘的工作方式是通过:中断方式进行的!操作系统可以识别并解释组合键,然后查找进程列表,得到前台运行的进程,OS将对应的信号发送给该前台进程!
中断是CPU与外部设备之间的一种通信机制。当一个外部设备(如键盘)需要CPU的处理时,它会产生一个中断请求,并向CPU发送一个中断信号。CPU在接收到这个中断信号后,立即暂停当前的任务,跳转到一个特定的中断处理程序(或称中断服务例程)来处理该中断请求。
对于键盘输入,当按下键盘上的一个键时,键盘控制器会生成一个中断请求,并向CPU发出中断信号。CPU接收到中断信号后,会中止当前正在执行的任务,立即跳转到键盘的中断处理程序。这个处理程序会读取键盘的输入数据,并将其传送给操作系统或相应的应用程序。
通过使用中断方式处理键盘输入,操作系统可以实现即时响应用户的键盘输入,而不需要等待CPU轮询键盘状态。这样可以提高系统的响应速度和效率。
2.5. 如何理解信号被进程保存呢?
信号被保存,我们要解决两个问题:其一,是什么信号? 其二,该信号是否产生?;
进程要保存信号,那么进程必须具有保存信号的相关数据结构,该数据结构需要保存不同的信号,并且还要表示某个信号是否产生,那么我们可以用什么数据结构用来保存信号呢?答案就是位图 (bitmap) !我们就可以用一个unsigned int ,它有32个bit,那么我们就可以用不同位置上的比特位表示不同的信号,其比特位上的值 (1/0) 代表该信号是否产生!那么这个位图结构在哪里呢?我们知道,信号是发送给进程的,并且进程需要保存该信号,因此,实际上,这个位图结构保存在PCB内核数据结构的内部,即PCB内部保存了信号位图字段!!!
2.6. 如何理解信号发送的本质
因为信号位图是在 task_struct 内核数据结构维护起来的,而task_struct 属于内核数据结构,因此发送信号等于修改 task_struct 内核数据结构中的某个字段,即修改内核数据,那么只有谁有资格呢? 答案就是操作系统,只有操作系统才具有修改内核数据的资格!因此,即便信号产生的方式有很多种,但是本质上都是操作系统去发送这个信号的,因为只有OS才有权力去修改内核数据结构PCB中的相关字段!
信号发送的本质:操作系统向目标进程写信号! 说白了,就是操作系统直接修改PCB中的指定的位图结构!完成 " 发送 " 信号的过程!因此,所有信号的发送,本质上都是OS去修改特定进程的PCB中的信号位图中的某个比特位,将其由 0 -> 1,就完成了信号发送的过程,而这就是发送信号的本质!
3. 产生信号的方式
3.1. 通过终端按键产生信号
我们说过, 操作系统通过识别并解释 " Ctrl + c "组合键就可以向特定进程发送2号信号 (SIGINT),而SIGINT的默认处理动作是 (Term) 终止进程;为了验证这个现象,我们可以通过signal系统调用捕捉SIGINT信号,自定义后续处理动作,以便证明 Ctrl + c 的确会向目标进程发送二号信号!
man 2 signal
NAME
signal - ANSI C signal handling
SYNOPSIS
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
RETURN VALUE
returns the previous value of the signal handler;
On error, Return SIG_ERR;
#define SIG_ERR ((__sighandler_t) -1) /* Error return. */
#define SIG_DFL ((__sighandler_t) 0) /* Default action. */
#define SIG_IGN ((__sighandler_t) 1) /* Ignore signal. */
#ifdef __USE_UNIX98
# define SIG_HOLD ((__sighandler_t) 2) /* Add signal to hold mask. */
#endifsignum:你要捕捉那一个信号。
handler:是一个函数指针,在这里就是一个回调函数,代表着该信号的自定义动作!
return value:旧的处理动作,也是一个函数指针,如果出错,返回SIG_ERR;
万事俱备,那么我们的思路就是:捕捉SIGINT信号,自定义后续处理动作,此时我们 " Ctrl + c " 的后续处理动作就不再是默认动作Term了,而是我们自己定义的动作,因此我们看到的现象就是 " Ctrl + c "不会终止该进程了;代码如下:
void handler(int signum)
{
std::cout << "收到了一个信号: " << signum << std::endl;
}
void Test1(void)
{
// 捕捉2号信号,自定义后续处理动作
// 如果此时产生了SIGINT,那么会将SIGINT对应的宏值
// 作为参数传递给handler这个回调函数
signal(SIGINT, handler);
std::cout << "PID: " << getpid() << " Process Running" << std::endl;
while(1)
{
sleep(1);
}
}
现象如下:?
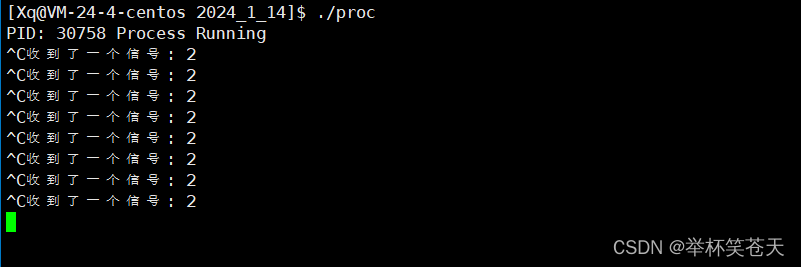
可以清晰地看到,当我们 "Ctrl + c" 的时候,此时该进程并没有被终止,而是执行了我们自己定义的后续处理动作;这也间接的证明了 "Ctrl + c" 的确会向目标进程发送2号信号 。

同时我们发现,如果此时没有 SIGINT 信号发送给当前进程,那么此时handler不会被调用,该进程就会自己执行自己的代码逻辑!也就是说,signal函数,仅仅是修改当前进程对特定信号的后续处理动作,并不是直接调用对应的处理动作!
signal?函数的主要作用是注册信号处理函数,它用于修改当前进程对特定信号的后续处理动作。换句话说,当接收到指定信号时,操作系统会通过调用相应的信号处理函数来处理该信号。然而,如果没有相应的信号被发送给当前进程,那么信号处理函数就不会被调用。相反,进程将继续执行自己的代码逻辑,不会中断或被中止。信号处理函数仅在接收到相应信号时由操作系统调用,以执行特定的操作或响应特定事件。
因此,在使用?
signal?函数时,我们可以将其视为注册一个函数,以便在将来某个时间点(即接收到特定信号时)执行特定操作。当没有相应的信号到达时,进程将继续正常运行而不会受到任何干扰。需要注意的是,在某些情况下,信号处理函数可能会中断正在执行的进程代码(例如?
SIGKILL),但这是比较特殊的情况。一般来说,信号处理函数的调用是由操作系统控制和触发的,进程会在接收到相应信号时才会调用信号处理函数。
3.1.2. 核心转储
核心转储(Core Dump)是指将进程在错误发生时的内存映像保存到一个文件中。换句话说,当发生错误后,核心转储会将内存中的数据转存到磁盘上;它包含了进程的内存状态、寄存器的值、堆栈跟踪等信息,可以帮助开发者诊断和调试发生错误的进程。
核心转储的生成是由操作系统负责的。当进程出现严重错误(如段错误、非法操作等)导致进程终止时,操作系统会自动生成一个核心转储文件。这个文件保存了进程在错误发生时的内存映像。
通过分析核心转储文件,开发者可以了解到错误发生时进程的状态,识别导致错误的原因。他们可以查看堆栈跟踪信息,判断在错误发生之前的函数调用链。还可以查看内存中的数据、寄存器的值等,帮助定位和修复问题。
在某些情况下,开发者还可以通过调试工具加载核心转储文件,并进行进一步的调试。他们可以回溯到错误发生的地方,查看变量的值、执行路径,并进行步进调试来分析代码的执行过程。
总而言之,核心转储是一个非常有用的工具,可以帮助开发者分析和调试进程中的错误,以便更好地理解问题,并进行修复。
我们之前也说过, " Ctrl + \ " 会向目标进程发送3号信号 (SIGQUIT),而SIGQUIT的默认处理动作是终止进程并且core dump;
core dump 标志: 是否发生了核心转储!
那么我们预期的现象:当一个进程正在被调度的时候,如果此时向该进程发送3号信号,那么该进程会被终止并发生核心转储 (将内存中的数据转存到磁盘上),那我们此时应该可以多看见一个文件,这个文件就是核心转储生成的文件,于是,测试如下:

但是不好意思啊,没有这个核心转储文件!那么这是为什么呢?
答案是: 我们所使用的云服务器的核心转储功能默认是被关闭的!
在这里我们说一个原因:
存储空间和成本考虑:核心转储文件通常会占用一定的存储空间。对于云服务器来说,存储资源是有限的,云服务提供商可能关闭核心转储功能以减少存储成本。
我们也能想到,核心转储 (将内存中的数据dump到磁盘上)是很消耗磁盘空间的,对于配置不高的云服务器而言,这无疑是一项很大的负担,故一般的云服务器都会默认关闭核心转储功能!
可是,我今天就是想在云服务器开启核心转储功能,可以吗? 答案是可以!
ulimit -a?是一个用于显示当前用户或当前Shell所允许的资源限制的命令。它可以列出各种资源限制的当前值,例如进程数量、内存大小、文件大小等。请注意,某些资源限制可能需要特权用户才能够查看或更改。?
[Xq@VM-24-4-centos 2024_1_14]$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7908
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 100001
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7908
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited下面是对每个参数的解释:
- core file size (blocks, -c) 0:核心转储文件的最大大小限制设置为 0 ,表示不生成核心转储文件,其单位为blocks,一个块的大小是512字节、1KB或其他大小!
- data seg size (kbytes, -d) unlimited:数据段的最大大小没有限制。
- scheduling priority (-e) 0:进程的静态调度优先级设置为 0,表示默认优先级。
- file size (blocks, -f) unlimited:文件的最大大小没有限制。
- pending signals (-i) 7908:可以在待处理信号队列中等待的最大信号数量为 7908。
- max locked memory (kbytes, -l) unlimited:锁定的内存的最大大小没有限制。
- max memory size (kbytes, -m) unlimited:进程的最大内存限制没有限制。
- open files (-n) 100001:同时打开的最大文件数为 100001。
- pipe size (512 bytes, -p) 8:管道(pipe)的缓冲大小为 8 个 512 字节块。
- POSIX message queues (bytes, -q) 819200:POSIX 消息队列的最大大小为 819200 字节。
- real-time priority (-r) 0:实时调度优先级设置为 0,表示默认优先级。
- stack size (kbytes, -s) 8192:栈的最大大小为 8192 Kbytes。
- cpu time (seconds, -t) unlimited:CPU 时间的限制没有限制。
- max user processes (-u) 7908:允许的最大用户进程数为 7908。
- virtual memory (kbytes, -v) unlimited:进程的虚拟内存大小没有限制。
- file locks (-x) unlimited:文件锁定的数量没有限制。这些参数是通过使用 `ulimit` 命令查看当前进程的资源限制。不同操作系统和配置可能会有所不同,以上解释是基于一般的 Linux 环境下的常见设置。
ulimit -c 10240 // 在当前终端打开 core dump这种机制
ulimit -c 10240?表示将核心转储文件的最大大小限制设置为 10240 个 1K 块(或者 10MB),单位是 blocks,此时核心转储功能就被打开了!

可以观察到,当核心转储功能打开后,如果此时该进程收到了3号信号,则该进程在被终止时会将内存中的相关核心数据转存到磁盘中,并生成core文件。这个core文件的命名通常是
core.<PID>,其中<PID>是生成该文件的进程PID。core dump 标志: 当进程出现某种异常的时候,是否由 OS 将当前进程在内存中的相关核心数据,转存到磁盘中!
那么核心转储的核心目的是什么呢?
其核心目的:为了方便调试;
示例如下:
void Test2(void)
{
std::cout << "PID: " << getpid() << " Process running " << std::endl;
sleep(1);
int i = 10 / 0;
(void)i;
}
上面的代码,我们在学习语言的时候都知道,一旦执行到 10 / 0,该进程就会被终止,本质上是该进程会受到 SIGFPE信号,而SIGFPE信号的默认处理动作是core;那么正常情况下,一旦这个进程跑起来,一秒之后,就会被异常终止,并生成core文件!测试如下:
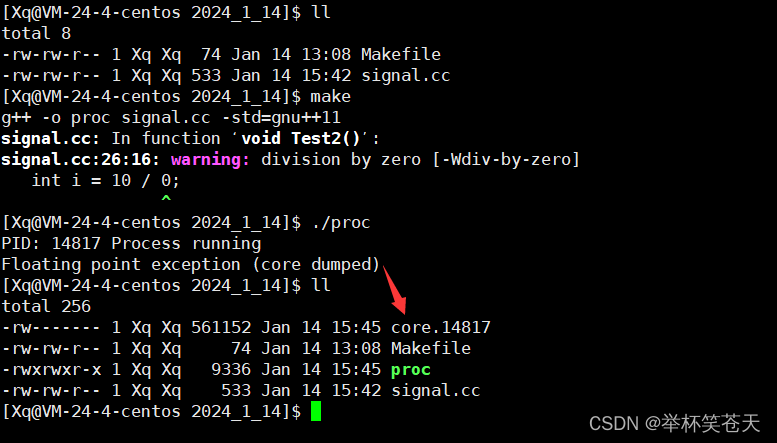
从结果来看,与我们的预期一致!那么你说了方便调试,那么怎么方便调试呢??
geb 调试的时候:core-file 对应的 core文件,core-file 对应的core文件帮助我们定位错误,这种方案,可以快速找出导致程序错误的原因;
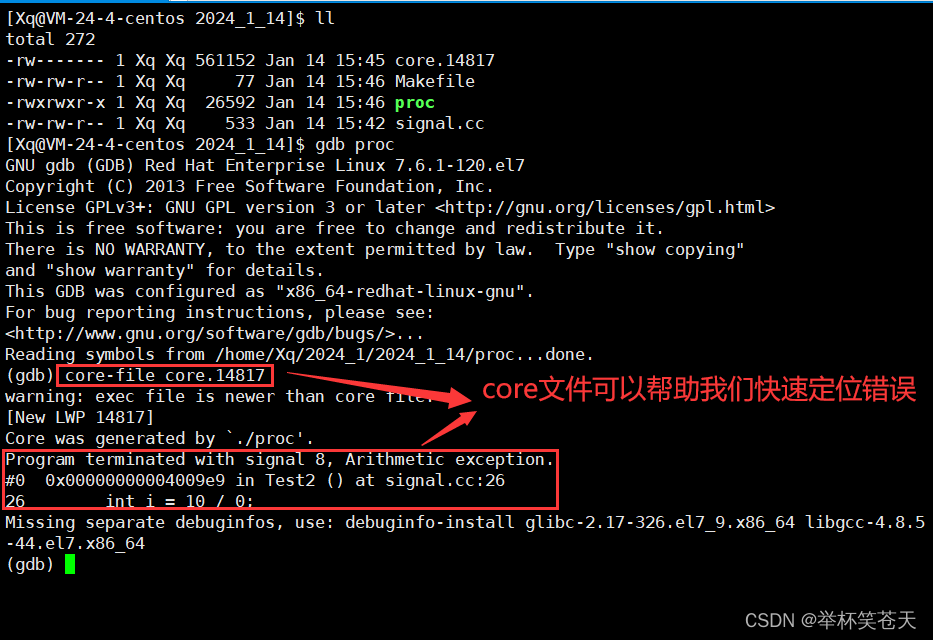
?3.1.3. 验证进程等待中的core dump标志
?在学习进程等待的时候,我们看过下面这个图:

?core dump标志: 当进程收到某种信号导致进程终止,是否已 core dump 的方式终止的,即是否发生了核心转储!
有没有把内存中的数据真正的给我们dump到磁盘中,如果有,我们就将 core dump 标志位设置为1;
那么我们就可以验证,在开启核心转储功能的前提下,当向进程发送3号信号后,获取此时的core dump标志,我们应该可以看到此时的core dump标志位是1;
验证思路如下:创建子进程,子进程一直运行,从终端通过命令向子进程发送3号信号,父进程等待子进程退出,同时获取子进程的退出信号以及core dump标志:
代码如下:
void Test3(void)
{
pid_t id = fork();
if(id == 0)
{
std::cout << "i am a child process, PID: " << getpid() << std::endl;
while(true) sleep(1);
}
int status = 0;
waitpid(id, &status, 0);
std::cout << "exit signal: " << (status & 0x7F) << " core dump: " << ((status >> 7) & 0x1) << std::endl;
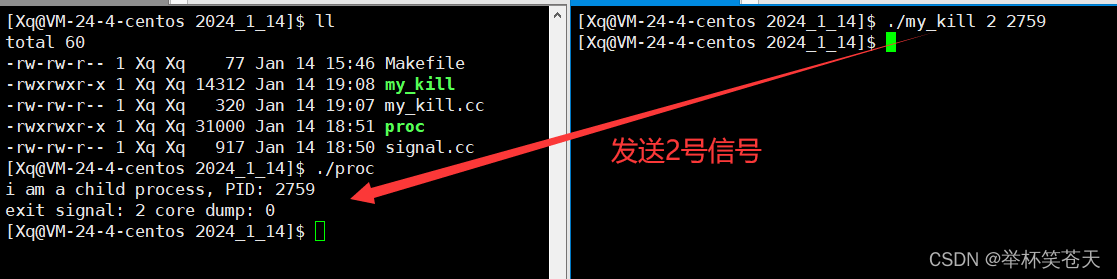
}现象如下:
?
符合我们的预期,此时core dump标志位 就为1,即终止进程时发生了核心转储。
3.2. 通过系统调用接口发送信号
3.2.1. kill 系统调用
man 2 kill
NAME
kill - send signal to a process
SYNOPSIS
#include <sys/types.h>
#include <signal.h>
int kill(pid_t pid, int sig);
RETURN VALUE
On success, zero is returned.
On error, -1 is returned, and error is set appropriately.实质上,我们的 kill 命令本质上就是调用的这个 kill 系统调用!我们也可以通过 kill 系统调用实现一个自己的 kill 命令!简单实现如下:
void Usage(void)
{
std::cout << "Usage: \n";
std::cout << " proc num PID " << std::endl;
}
int main(int argc,char* argv[])
{
if(argc != 3)
{
Usage();
exit(1);
}
kill(std::stoi(argv[2]),std::stoi(argv[1]));
}
现象如下:?
3.2.2. raise 调用
man 3 raise
NAME
raise - send a signal to the caller
SYNOPSIS
#include <signal.h>
int raise(int sig);
RETURN VALUE
raise() returns 0 on success, and nonzero for failure.raise() 可以向调用者发送sig信号!
3.2.3. abort 调用
man 3 abort
NAME
abort - cause abnormal process termination
SYNOPSIS
#include <stdlib.h>
void abort();
abort 调用会向调用者自身发送6号信号 (SIGABRT),abort 相当于 raise(6); 也可以理解为 kill (getpid(),6);
abort 通常用来终止进程!
?3.2.4. 如何理解通过系统调用接口发送信号
用户调用系统接口 ---> 执行OS对应的系统调用代码 ---> OS提取参数,或者设置特定的数值 ---> 操作系统向目标进程写信号 ---> 修改对应进程的信号标记位 (本质是修改PCB里面的信号位图) ---> 进程后续会处理信号 ---> 执行对应的处理动作。?
3.3. 由软件条件产生信号
3.3.1. 管道问题
在学习管道的时候,我们说过,管道通信有一种特殊情况,管道的读端被关闭了,但是管道写端还一直在写,那么此时写端进程就会被操作系统终止掉,而本质上,操作系统会向写端进程发送SIGPIPE信号!那么如何验证呢?
验证思路如下:
1、 创建匿名管道,并构建单向通信的匿名管道;
2、 让父进程做读端,子进程做写端;
3、 父进程关闭读端,并且父进程waitpid()等待子进程退出;
4、 子进程(写端进程)被操作系统终止,父进程就可以得到子进程的status;
5、 父进程提取退出信号!
在这里有一个问题,为什么父进程做读端,子进程做写端呢?
之所以让父进程做读端,子进程做写端,原因是因为:当读端被关闭了,那么写端进程就会被OS发送信号(具体为SIGPIPE --- Term),导致写端进程异常终止!而由于子进程退出需要父进程等待,防止产生僵尸进程;并且我们的目的是为了获取写端进程的退出信号,那么自然也需要子进程做写端进程,父进程做读端,这才能获取子进程(写端进程)读端退出信号。故子进程最好做写端,父进程做读端!
那么为什么OS在这种情况下要给写端进程发送 SIGPIPE 信号呢?
原因是:管道此时已经没有进程读取数据了(读端被关闭了),此时再向管道写入数据就是没有意义的,OS发现了这个问题,故OS会向写端进程发送一个信号,具体为SIGPIPE,只是写端进程被终止。
测试代码如下:
void Test4(void)
{
int pipefd[2] = {0};
int ret = pipe(pipefd);
assert(ret != -1);
(void)ret;
pid_t id = fork();
if(id == 0)
{
// child process writing end
close(pipefd[0]);
// write continuously on the writing end
std::string message("hello");
while(true)
{
write(pipefd[1], message.c_str(), strlen(message.c_str()));
sleep(1);
}
abort();
}
// parent process reading end
close(pipefd[1]);
// two seconds later, turn off the reader
sleep(2);
close(pipefd[0]);
int status = 0;
waitpid(id, &status, 0);
std::cout << "child process exit signal: " << (status & 0x7F) << std::endl;
}
现象如下:
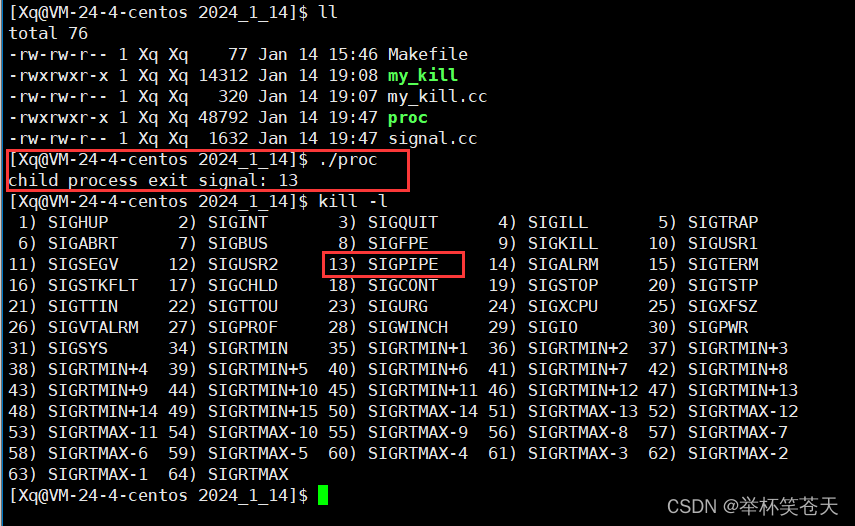
通过现象,我们可以清楚的看到,当读端关闭,写端一直在写,那么此时OS会向写端进程发送13号信号 (SIGPIPE --- Term),操作系统这样做,我们也能理解,读端都被关闭了,此时写端在向管道写数据就毫无意义,因此操作系统此时向写端发送SIGPIPE信号终止写端进程,也是情理之中了。?
管道是软件,因为管道是基于操作系统提供的文件系统在内存级别的实现,操作系统识别到管道的读端都被关闭并且还有进程向该管道写入数据,那么这种场景我们就称之为软件条件不满足!由于软件条件不满足,操作系统会向目标进程发送特定的信号,处理目标进程!
3.3.2. 闹钟问题
首先我们看一下alarm函数:
man 2 alarm
NAME
alarm - set an alarm clock for delivery of a signal
SYNPOSIS
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
DESCRIPTION
alarm() arranges for a SIGALRM signal to be delivered
to the calling process in seconds seconds.
简而言之,alarm函数是一个操作系统提供的定时器功能,它可以设置一个定时器,在指定的秒数后,操作系统会给当前进程发送 SIGALRM信号,该信号的默认处理动作时终止当前进程 (Term)!?
那么我们就可以通过alarm() 这个接口验证1秒内,我们的云服务器一共可以进行多少次count++;测试代码如下:
void Test5(void)
{
alarm(1); // 1S后,会向该进程发送SIGALRM信号,终止该进程
int count = 0;
while(true)
{
std::cout << "count: " << count++ << std::endl;
}
}现象如下:?
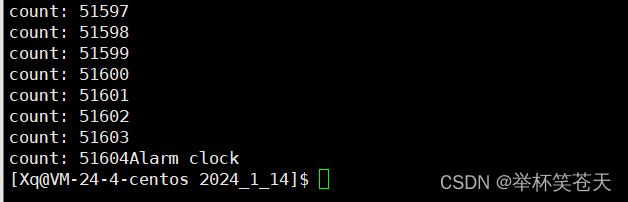
不对啊,怎么才51604呢? 就算我的云服务器配置在低,也不至于1秒中只计算了几万次吧。怎么会这么慢呢?并且我们只执行了一个整形加加的逻辑啊,这是为什么呢???
主要原因是因为:IO,我们进行了打印,并且我们是云服务器,所有的数据都是来自网络发送的,而它们都是阻塞式的IO,这就导致了我们CPU的处理数据的能力严重受到限制!?
因此,如果我们想单纯的计算算力呢?
因此,我们可以利用signal() 函数捕捉SIGALRM信号,1秒之后,打印count的值即可,代码如下:
int count = 0;
void handler(int signum)
{
std::cout << "PID: " << getpid() << " 收到了一个信号 " << signum << std::endl;
std::cout << "count: " << count << std::endl;
abort();
}
void Test6(void)
{
// 由于SIGALRM的默认处理动作是终止进程
// 因此为了更好的观察现象,我们捕捉一下SIGALRM信号
signal(SIGALRM, handler);
alarm(1);
while(true)
{
++count;
}
}
现象如下:?
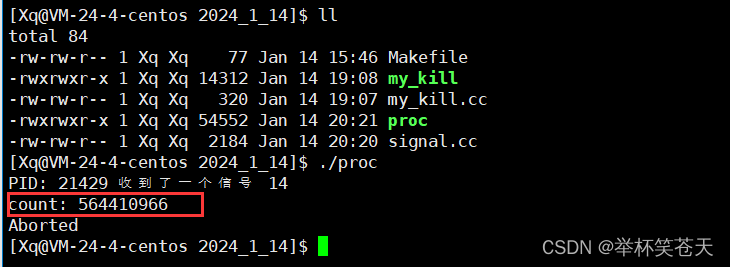
此时count已经达到了亿级别,是阻塞式的 10^4倍,这个差别是非常大的,就类似于CPU和内存处理数据能力,?这样我们也能间接理解 IO 的效率其实非常低,尤其涉及到网络,那就更低了!
我们要知道,设定了一个闹钟之后,一旦这个闹钟触发,就自动移除了;
那么如果我想做一个定时器功能呢,按秒为单位记录count的值,那么我们可以通过重设闹钟的思路实现,当一个闹钟出发,执行SIGALRM的自定义处理动作,在这个自定义处理动作中,我们进行重设闹钟,以达到轮询式的效果!代码如下:
uint64_t count = 0;
void handler(int signum)
{
std::cout << "PID: " << getpid() << " 收到了一个信号 " << signum << std::endl;
std::cout << "count: " << count << std::endl;
alarm(1); //重设闹钟
}
void Test6(void)
{
// 由于SIGALRM的默认处理动作是终止进程
// 因此为了更好的观察现象,我们捕捉一下SIGALRM信号
signal(SIGALRM, handler);
alarm(1);
while(true)
{
++count;
}
}现象如下:
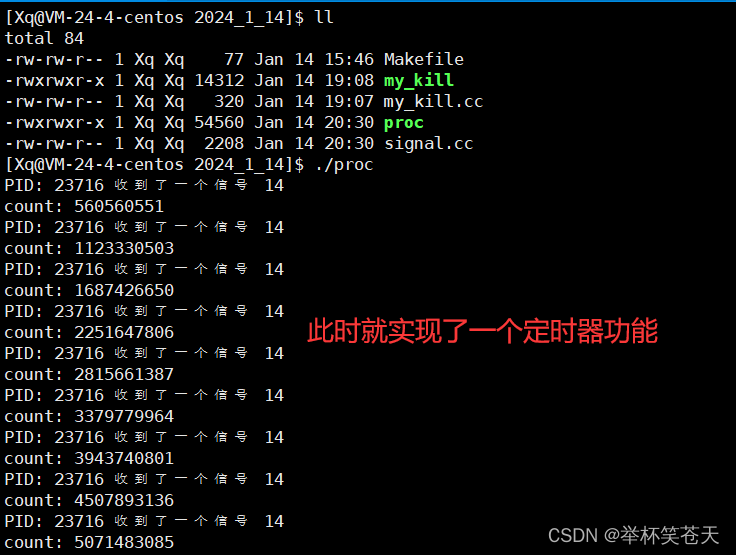
通过现象,我们可以了解到定时器的简单实现,具体来说,我们可以使用定时器来触发某个函数或任务,然后在任务完成后重新设置下一个定时器,等待下一个触发时间到来。通过这种方式,您可以实现周期性地执行某个任务或函数,并且可以根据具体需求设置执行时间、间隔、任务内容等。
那么如何理解软件条件给进程发送信号呢?
a. 操作系统先识别到某种软件条件触发或者不满足;
b. 操作系统构建信号, 发送给指定的进程。
?3.4. 硬件异常产生信号
3.4.1. 除0异常的理解
除0这种错误我们在学习语言的时候都知道,一旦进程进行了除0操作,那么就会导致进程异常终止,可是究竟是为什么呢?
而今天,我们首先要知道,一旦进程执行除0操作,那么操作系统就会向该进程发送8号信号 (SIGFPE),而SIGFPE的默认处理行为是Core,进而导致进程终止。验证如下:
void handler(int signum)
{
std::cout << "PID: " << getpid() << " 收到一个信号: " << signum << std::endl;
sleep(1);
}
void Test1(void)
{
// 由于SIGFPE的默认处理动作是Core
// 因此为了更好地观察现象,我们需要捕捉该信号
signal(SIGFPE, handler);
int i = 0;
sleep(1);
i /= 0; // 除0
while(true)
sleep(1);
}现象如下:?
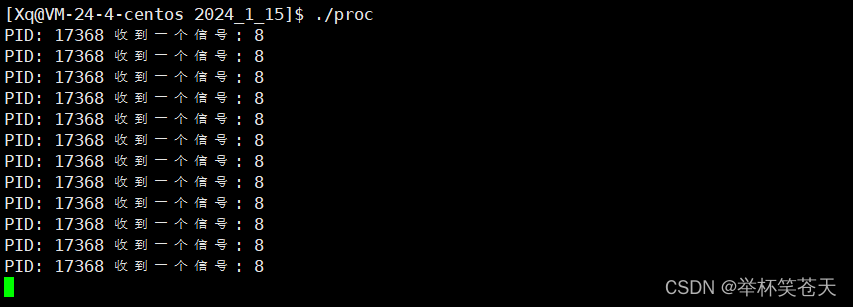
首先,我们从上面的现象可以看出,一旦进程进行了除0操作,那么操作系统会向该进程发送8号信号SIGFPE,这符合我们的预期。可是,为什么我们自定义的动作在死循环的执行呢?可是我们只是进行了一次除0操作啊,按道理说,只会进行一次自定义动作的调用啊,这是为什么呢?
答案是:除0错误,属于硬件异常!那么如何理解呢?
1、 首先,我们要知道进行数据计算的是CPU这个硬件。CPU负责执行指令和进行数据操作。
2、 CPU内部是有寄存器的,状态寄存器 (不进行数值保存,保存当前计算的计算状态),有对应的状态标记位 ,如溢出标记位,用于指示计算中是否发生了溢出。OS会自动进行计算完毕之后的检测! 如果溢出标记位是1,OS里面识别到有溢出问题,立即找到当前谁在运行并提取PID,操作系统会向该进程发送相应的信号(SIGFPE),进程会在合适的时候,进行处理。
3、 出现硬件异常并不一定导致进程立即退出。操作系统提供了信号处理机制,进程可以捕捉信号并重新定义后续处理动作。默认情况下,对于某些硬件异常(如除零错误),操作系统可能会终止进程。但是,进程可以通过自定义信号处理函数来处理异常并决定是否继续执行。
4、 为什么会死循环?原因就是:CPU内部的寄存器中的异常标志一直没有被解决!OS一直识别到了这个异常,故OS会一直发送SIGFPE这个信号,signal就会死循环式的捕捉该信号,并执行自定义动作!
3.4.2. 如何理解野指针或者越界问题
作为C/C++的学习者,我认为,野指针问题、内存问题是一直伴随我们整个学习生涯的!而在Linux上,野指针问题 && 越界问题,我们称之为段错误 (Segmentation fault)。当出现段错误时,其本质是操作系统会向目标进程发送11号信号 (SIGSEGV),而今天,我们就要站在系统角度理解野指针、越界问题;
首先,我们先看代码:
void handler(int signum)
{
std::cout << "PID: " << getpid() << " 收到一个信号: " << signum << std::endl;
sleep(1);
}
void Test2(void)
{
signal(SIGSEGV, handler);
int* ptr = nullptr;
sleep(1);
*ptr = 0;
while(true)
sleep(1);
}现象如下:?

通过现象,我们可以清楚的看到,当进程出现了野指针错误,此时操作系统就会向该进程发送11号信号 (SIGSEGV)?,可是我们有观察到一个奇怪的现象,此时依旧在循环式的执行handler,即我们的自定义处理动作,可是我们只执行了一次野指针调用,因此,我们今天依旧要在系统角度理解野指针问题:
1、 是的,解引用指针需要通过地址找到目标位置。指针保存了某个对象的内存地址,解引用操作即根据该地址获取对象的值。
2、 在大多数编程语言中,我们使用的地址都是虚拟地址。虚拟地址是在程序运行时由操作系统和硬件共同提供的,它对应于实际的物理内存地址,但是进程并不直接访问物理内存地址。
3、 当我们访问某段物理内存时,首先要将虚拟地址转化为物理地址。这个转换过程通常由操作系统的页表和MMU(内存管理单元,Memory Management Unit)硬件来完成。MMU将虚拟地址映射为物理地址.
4、 野指针和越界访问都指出该虚拟地址是非法的。因此,当MMU将虚拟地址转换为物理地址时,会检测到错误并触发异常!
5、当MMU转换出错时,操作系统会识别到MMU的错误,并将其转换为特定的信号发送给当前进程。例如,在Linux中,当发生虚拟地址无效或越界访问时,操作系统会向进程发送SIGSEGV信号(段错误信号),以指示非法内存访问或操作
在计算机里,不要只认为CPU才有寄存器,几乎所有的外设都可能存在寄存器!!!
因此越界 && 异常也属于硬件异常!
那么 这里为什么也会死循环呢?
这是因为MMU内部的异常仍然存在,操作系统会一直发送SIGSEGV信号,而进程中的信号处理函数又会不断捕捉和处理该信号,导致死循环的现象
有了这些信号产生方式的理解,我们可以知道,所有的信号,有它的来源 (无论它是终端按键、系统调用、软件条件、硬件异常产生信号)!但最终都是由操作系统识别、解释并发送的!
4. 信号是如何被保存的
4.1. 信号的相关概念
将实际执行信号的处理动作,我们称之为信号递达 (Delivery)。
信号从产生到递达之间的状态,我们称之为信号未决 (Pending)。
进程可以选择阻塞 (Block) 某个信号
被阻塞的信号产生后将保持在未决状态,直到进程解除对该信号的阻塞,才会执行递达动作
注意:阻塞和忽略是不同的;
忽略:已经将该信号递达了,只不过信号的后续处理动作是忽略。
阻塞:信号都不会被递达,被阻塞的信号产生时将保持在未决状态,直到进程解除对该信号的阻塞,才会执行递达动作;否则,该信号永远都不会被递达!
4.2. 信号在内核中的表示?
信号在内核中的示意图:
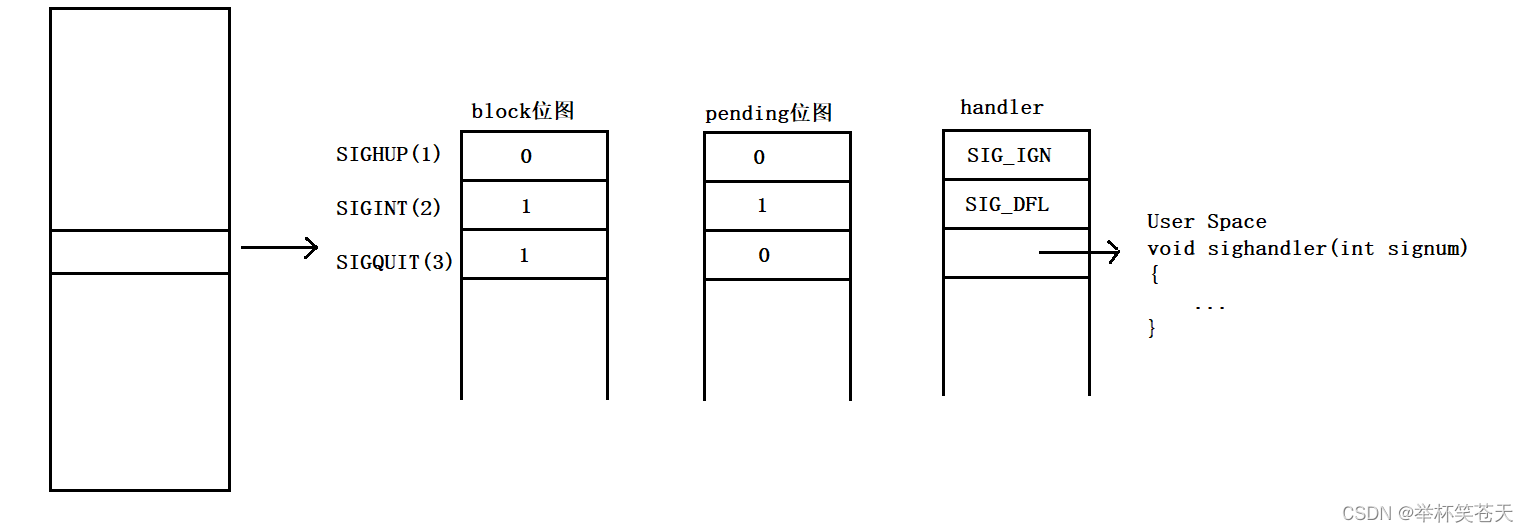
每个信号都有两个标志位分别表示阻塞 (block)和 未决(pending),还有一个函数指针表示处理动作。信号产生时,内核在进程控制块 (PCB)中设置该信号的未决标志,直到信号递达才会清除该标志!
注意:block 位图 结构和 pending位图一摸一样!只不过它们不同比特位的值所代表的意义不一样罢了!
pending 位图:pending位图也称之为pending信号集,其不同的比特位代表不同的信号;而某个比特位的值 (1/0) 代表是否产生了该信号 (操作系统是否向当进程发送该信号);
Block 位图:block位图也称之为信号屏蔽字,其不同的比特位代表不同的信号;而某个比特位的值 (1/0) 代表对应的信号是否被阻塞!
handler 表:handler 称之为 handler处理方法表,我们可以将handler理解成一张映射表;
typedef ( *handler_t )(int) ;
handler_t handler[32];
(int)handler[signal] == 0 ---> default ,表示使用默认的处理动作
(int)handler[signal] == 1 ---> ignore,表示忽略该信号
(int)handler[signal] == -1 ---> error,表示发生错误,通常不会出现
如果 handler 表中某个位置对应的值不是上述三种情况,那么它就是一个有效的函数指针,指向用户自定义的信号处理函数。当信号发生时,内核会在 handler 表中查找相应信号的处理函数,如果找到了有效的处理函数,就会调用这个函数来处理信号。
因此 signal(signum,handler);
本质上是将 handler 这个函数指针填入 handler表中的特定位置即 handler[signum]中,而并不是直接去调用handler这个方法!
在上图的例子中:
SIGHUP信号,没有被阻塞,也没有产生。一旦进程在执行过程中,得到SIGHUP信号,且由于此时 SIGHUP信号未被阻塞,故SIGHUP信号被递达时执行信号忽略动作!
SIGINT信号:此时SIGINT信号已经产生,但由于此时该信号正在被阻塞,所以不会被递达。直至该信号解除阻塞后,才会执行递达动作;否则,永远都不会被递达,也就不会执行后续处理动作;
SIGQUIT信号:SIGQUIT信号未产生过,但是此时该信号正在被阻塞,尽管此时产生了SIGQUIT信号,该信号也不会被递达,如果在进程解除对该信号的阻塞之前,该信号产生过多次,那么如何处理?在Linux系统下,常规信号在递达之前产生多次只记录一次,而实时信号在递达之前产生多次可以放在一个队列里,但是我们目前不讨论实时信号!
4.3. 信号的处理流程是什么
一个信号被处理,是怎样的一个处理过程呢?
首先操作系统识别到了某种异常,因此会向特定进程发送信号。
发送信号第一步是找到特定进程的pending位图, 将特定信号对应的比特位由 0 -> 1,至此,操作系统的任务就结束。
随后,进程会再合适的时间检测pending位图,发现pending位图中有比特位为1的,此时,进程并不会直接去调用handler表中对应的处理方法,而是会先去block位图中检查该信号是否被阻塞,如果被阻塞了,那么该进程并不会去执行该信号的后续处理动作,即该信号会处于未决状态,直至进程解除对该信号的阻塞,才会去递达,执行该信号的后续处理动作,即 handler[signum];如果没有被阻塞,那么进程会直接调用 handler表中对应的方法!
因此,Linux处理信号流程是:先检测pending位图,(条件满足的情况下)在检测 block 位图 ,(条件满足的情况下)在去执行handler表中对应的执行方法 。?
4.4. sigset_t
我们现在直到,每个信号只有一个比特位的未决标志,非0即1,对于普通信号,我们不记录该信号产生了多少次,阻塞标志也是这样表示的。 因此,实际上,未决和阻塞标志可以用相同的数据类型 sigset_t 来存储,我们将sigset_t 称之为信号集,该类型可以表示每个信号的 "有效" 或者 "无效"状态,在未决信号集中 "有效" 和 "无效"的含义是该信号是否处于未决状态(即是否产生了该信号),而对于阻塞信号集中 "有效" 和 "无效" 的含义是该信号是否被阻塞,阻塞信号集也叫做当前进程的信号屏蔽字 (Signal Mask),这里的 ”屏蔽“ 我们应该理解为阻塞而非忽略!
sigset_t 是一个位图结构,它是操作系统为我们提供的一种数据类型,sigset_t虽然是操作系统提供的,但是用户是可以直接使用该类型的,类似于 pid_t,key_t等等,正因为它是操作系统提供的,我们对sigset_t的类型数据进行操作时,一定需要操作系统提供的系统调用,来完成对应的功能,其中系统接口需要的参数,可能就包含了sigset_t 定义的变量或者对象。
4.5. 信号集操作函数
sigset_t类型对于每种信号用一个比特位来表示 "有效" 或 "无效" 状态,至于这个类型内部如何存储这些比特位是由操作系统内部实现的,从使用者的角度不必关心,使用者只能调用以下接口来操作sigset_t类型的数据,而不应该对它的内部数据做任何解释,例如直接用位操作进行按位与或者按位或sigset_t变量是没有任何意义的。
# 全部在3号手册
NAME
sigemptyset, sigfillset, sigaddset, sigdelset, sigismember
- POSIX signal set operations.
SYNOPSIS
#include <signal.h>
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
int sigaddset(sigset_t *set, int signum);
int sigdelset(sigset_t *set, int signum);
int sigismember(const sigset_t *set, int signum);
RETURN VALUE
sigemptyset(), sigfillset(), sigaddset(), and sigdelset()
return 0 on success and -1 on error.
sigismember() returns 1 if signum is a member of set, 0 if signum is not a member,
and -1 on error. On error, these functions set errno to indicate the cause.int sigemptyset(sigset_t *set);? 将所有的bit位清空,即全部置为0;
int sigfillset(sigset_t *set); 填充所有比特位,即全部置为 1;
int sigaddset(sigset_t *set, int signum); 将特定的信号 signum 添加到 set 信号集中,即将特定位置的比特位置为1;
int sigdelset(sigset_t *set, int signum); 从特定的信号集set中删除特定信号 signum;即将特定位置的比特位置为0;
int sigismember(const sigset_t *set, int signum); 判定特定信号signum是否在set信号集中!
4.5.1. sigpending系统调用?
man 2 sigpending
NAME
sigpending - examine pending signals
#include <signal.h>
int sigpending(sigset_t *set);
RETURN VALUE
sigpending() returns 0 on success and -1 on error.
In the event of an error, errno is set to indicate the cause.int sigpending(sigset_t *set);? 获取当前进程的 pending 信号集, 通过调用 sigpending 接口,用户可以将内核中关于 pending 信号集的信息返回给用户。
使用 sigpending 函数时,用户需要提供一个 sigset_t 类型的指针,用于接收 pending 信号集的信息。一旦调用 sigpending 函数,内核会将当前进程的 pending 信号集的状态信息填充至提供的 sigset_t 结构中,从而使得应用程序能够获取到该信号集的详细信息。
4.5.2. sigprocmask系统调用?
man 2 sigprocmask
NAME
sigprocmask - examine and change blocked signals
SYNPOSIS
#include <signal.h>
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);
RETURN VALUE
sigprocmask() returns 0 on success and -1 on error.
In the event of an error, errno is set to indicate the cause.sigprocmask 是一个用于改变进程信号屏蔽字的系统调用。信号屏蔽字是一个位掩码,用于指定那些信号在调用该系统调用的过程中要被阻塞。具体来说,sigprocmask 系统调用允许进程修改其信号屏蔽字,从而控制在某些关键代码段的执行过程中是否接收或处理特定的信号。
其中,how 参数表示屏蔽字的修改方式,有三个可能的值,假设当前的信号屏蔽字为mask:
- SIG_BLOCK:将 set 指定的信号集合添加到当前屏蔽字中。相当于 mask = mask | set;
- SIG_UNBLOCK:从当前屏蔽字中移除 set 指定的信号集合。相当于 mask = mask &~ set。
- SIG_SETMASK:将当前屏蔽字设置为 set 指定的信号集合。相当于 mask = set;简而言之,就是赋值。
set 参数是一个指向新的信号屏蔽字的指针 (用户定义的),oldset?是一个输出型参数,如果不为空,那么返回老的信号屏蔽字。
通过 sigprocmask 调用,进程可以动态地修改自己的信号屏蔽字,从而控制在某些关键代码段的执行过程中是否接收或处理特定的信号。这种机制对于确保关键代码段的原子性执行以及避免不希望被处理的信号的干扰是非常重要的。
4.5.3. 验证一
1、 如果我们对所有的信号都进行了自定义捕捉 --- 我们是不是就写了一个不会被异常或者用户杀掉的进程呢? 测试代码如下:
signal.cc 的代码如下?
// signal.cc
void Test3(void)
{
for(size_t i = 1; i <= 31; ++i)
signal(i, handler);
std::cout << "PID: " << getpid() << "进程正在运行..." << std::endl;
while(true)
sleep(1);
}put_signal.sh 的代码如下??
#!/bin/bash
i=1
id=$(pidof proc)
while [ $i -le 31 ]
do
kill -$i $id
echo "kill -$i $id"
let i++
sleep 1
done
现象如下:?
?
从上面的现象可以看出, 9 号信号无法被捕捉。我们更改以下put_signal.sh的代码将9号信号跳过,继续观察现象:
更改后的 put_signal.sh 的代码如下???
#!/bin/bash
i=1
id=$(pidof proc)
while [ $i -le 31 ]
do
if [ $i -eq 9 ];then
let i++
continue
fi
kill -$i $id
echo "kill -$i $id"
let i++
sleep 1
done现象如下:
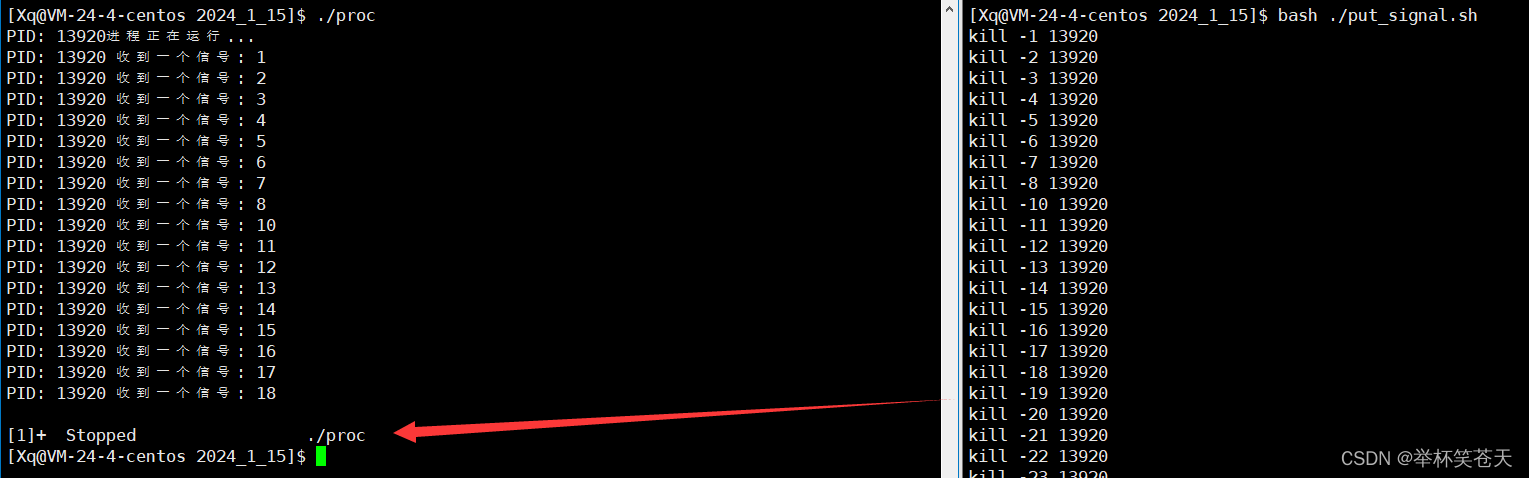
从上面的现象可以看出, 19 号信号同样也无法被捕捉。我们更改以下put_signal.sh的代码将9号信号和19号信号跳过,继续观察现象:
更改后的 put_signal.sh 的代码如下???
#!/bin/bash
i=1
id=$(pidof proc)
while [ $i -le 31 ]
do
if [ $i -eq 9 ];then
let i++
continue
fi
if [ $i -eq 19 ];then
let i++
continue
fi
kill -$i $id
echo "kill -$i $id"
let i++
sleep 1
done测试现象如下:
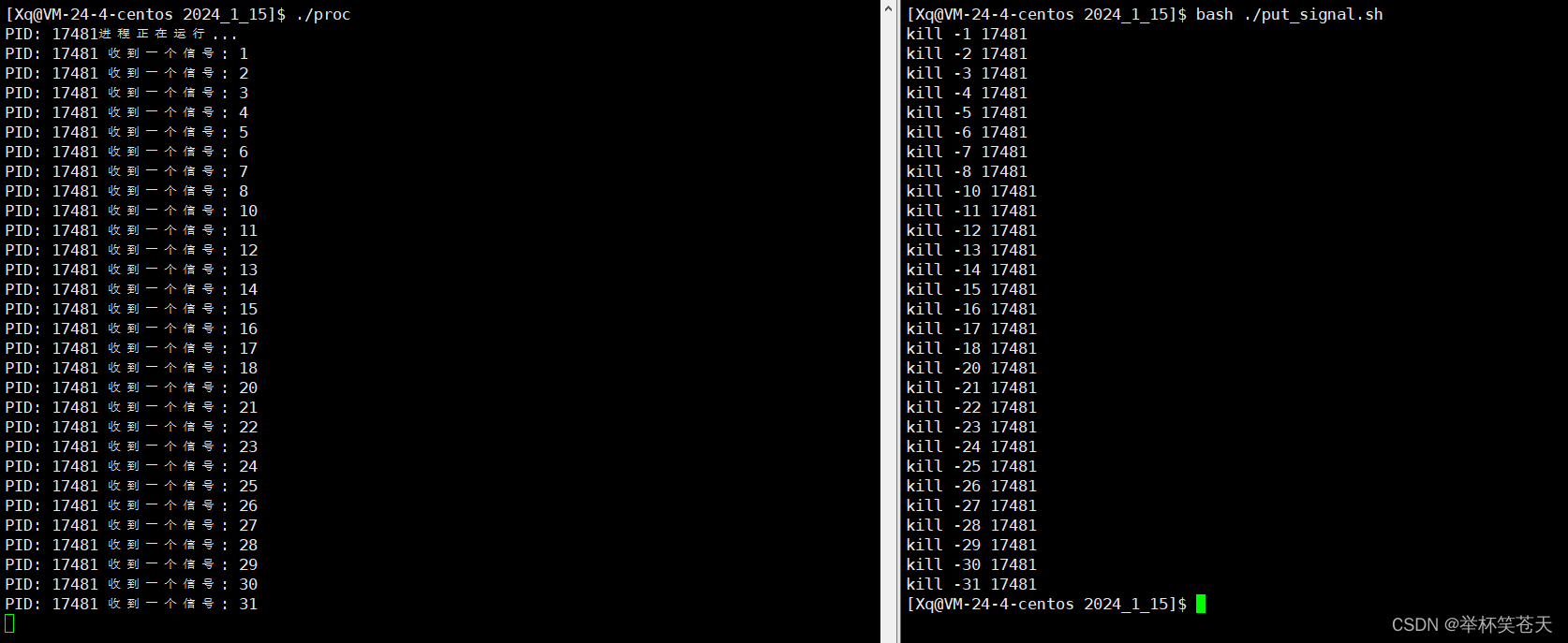
根据上面的现象,我们可以得知, 尽管我们对所有的信号都进行了自定义捕捉,但是实际上,9号信号和19号信号不会被捕捉!
4.5.4. 验证二
如果我们将2号信号进行屏蔽,并且不断的获取并打印当前进程的pending信号集,如果此时我们突然发送一个2号信号,我们就应该肉眼看到 pending 信号集中,有一个比特位由 0 - > 1。
当屏蔽了2号信号之后,此时只是 block 位图中 代表SIGINT的比特位由0 -> 1,并不代表此时收到了SIGINT信号,即 pending 位图中代表SIGINT的比特位不一定由0->1。
如果此时操作系统向该进程发送了SIGINT信号,那么 pending 位图中代表SIGINT的比特位将由0->1,且由于此时SIGINT信号已被阻塞,故SIGINT信号不会被递达,在没有解除SIGINT的阻塞之前,进程不会处理该信号,即该信号会一直在pending位图中。
如果此时解除了 SIGINT 的屏蔽,那么该信号SIGINT就会被递达,但由于SIGINT的默认处理动作是 Term,故为了看到 pending位图中 由1 -> 0 我们要捕捉SIGINT,自定义SIGINT的后续处理动作;
测试代码如下:
void print_pending(sigset_t& pending)
{
for(size_t i = 1; i <= 31; ++i)
{
if(sigismember(&pending, i))
std::cout << "1";
else
std::cout << "0";
}
std::cout << " PID: " << getpid() << std::endl;
}
int i = 0;
void handler(int signum)
{
std::cout << "PID: " << getpid() << " 收到一个信号: " << signum << std::endl;
sleep(1);
}
void sighandler(int signum)
{
sigset_t pending;
sigemptyset(&pending);
sigpending(&pending);
print_pending(pending);
alarm(1);
++i;
}
void Test4(void)
{
// 由于SIGINT的默认处理动作是Term
// 因此在这里为了观察现象,我们捕捉该信号
signal(SIGINT, handler);
signal(SIGALRM, sighandler);
sigset_t best;
sigset_t o_best;
// 清空比特位,全部设置为0
sigemptyset(&best);
sigemptyset(&o_best);
// 将SIGINT添加到best这个信号集中
int ret = sigaddset(&best, SIGINT);
assert(ret == 0);
(void)ret;
// 将best信号集添加到该进程的block信号集中
int mask_ret = sigprocmask(SIG_BLOCK, &best, &o_best);
assert(mask_ret != -1);
(void)mask_ret;
alarm(1);
while(true)
{
if(i == 7)
{
std::cout << " 解除SIGINT信号的屏蔽" << std::endl;
sigprocmask(SIG_SETMASK, &o_best, nullptr);
}
sleep(1);
}
}现象如下:?

如我们预期一致,当进程阻塞了SIGINT时,此时如果操作系统向该进程发送了SIGINT信号,那么此时该进程的pending位图就会有一个bit位由0 -> 1;当该进程解除了对SIGINT信号的阻塞时,此时该信号就会执行递达过程,进而我们会看到pending位图有一个比特位由1 -> 0;
4.5.5. 验证五
3、 如果我们对所有的信号都进行block (阻塞) --- 那么我们是不是就写了一个不会被异常或者用户杀掉的进程呢? 可以吗?测试代码如下:
signal.cc 代码如下:?
void print_pending(sigset_t& pending)
{
for(size_t i = 1; i <= 31; ++i)
{
if(sigismember(&pending, i))
std::cout << "1";
else
std::cout << "0";
}
std::cout << std::endl;
}
void Test5(void)
{
sigset_t best;
sigemptyset(&best);
// 将best信号集全部置为1
sigfillset(&best);
sigprocmask(SIG_SETMASK, &best, nullptr);
sigset_t pending;
sigemptyset(&pending);
while(true)
{
int ret = sigpending(&pending);
assert(ret != -1);
(void)ret;
print_pending(pending);
sleep(1);
}
}
?put_signal.sh 代码如下:
#!/bin/bash
i=1
id=$(pidof proc)
while [ $i -le 31 ]
do
if [ $i -eq 9 ];then
let i++
continue
fi
if [ $i -eq 19 ];then
let i++
continue
fi
kill -$i $id
echo "kill -$i $id"
let i++
sleep 1
done
现象如下:
?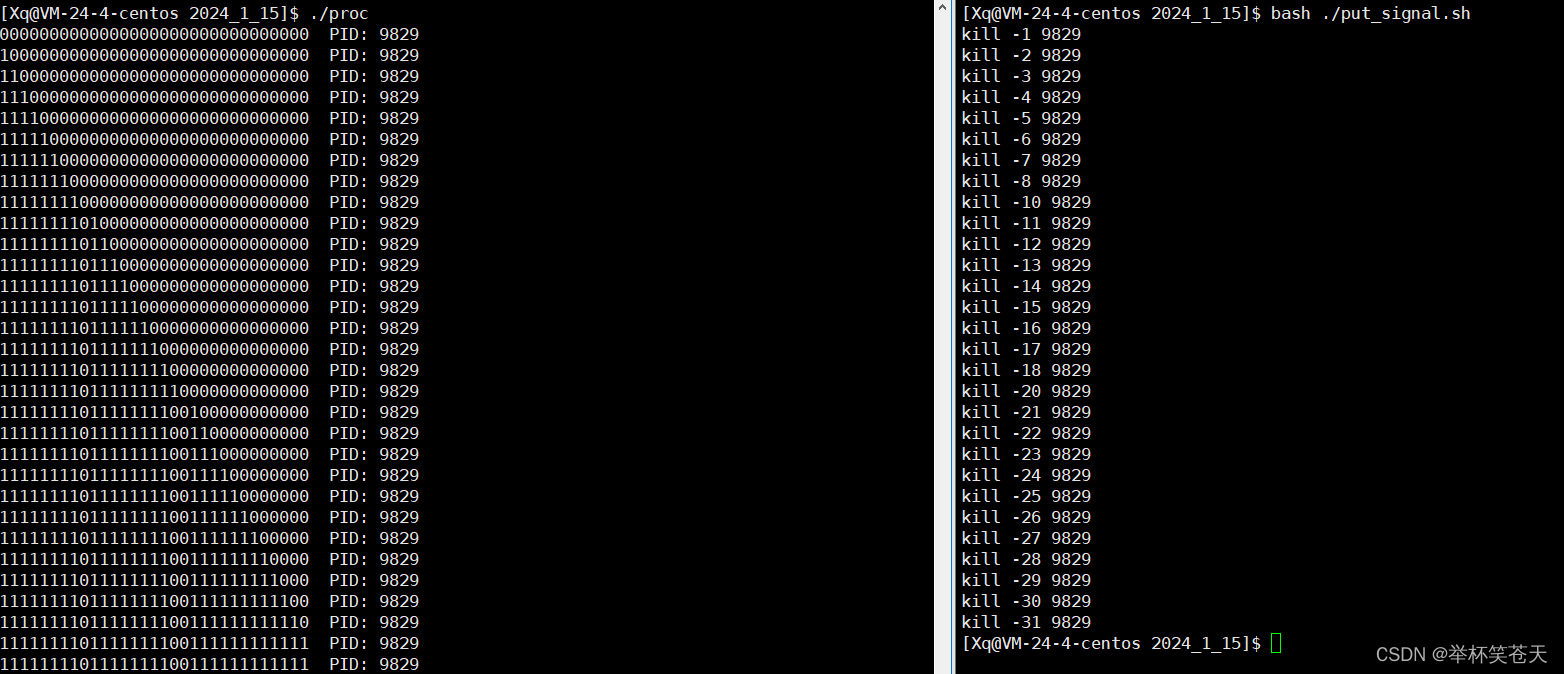
结论: 9号信号和19号信号不可被阻塞!综上所述, 9号信号和19号信号不可被捕捉也不可被阻塞!?因此即便我们将所有信号捕捉或者屏蔽,我们不用担心该进程无法被终止,因为9号信号和19号信号是不可被捕捉和屏蔽的。
?5. 信号处理
5.1. 信号处理的时机
我们之前说过,信号产生之后,信号可能无法立即被处理,而是在 "合适的时候" 处理,可是这个 "合适的时候" 究竟是什么呢?
首先,经过前面的一些理解,我们知道信号相关的数据字段都是在进程PCB内部!而PCB属于内核数据结构,即信号属于内核范畴。
作为普通用户没有权限去检测信号,因此,要处理信号,进程必须处于内核状态!
进程执行的时候,进程可以分为处于内核状态或者用户状态。
比如:进程进行系统调用,或者访问内核数据时,我们称之为进程处于内核态;而进程执行用户代码的时候,我们称之为用户态!
那么什么时候处理信号呢?
在内核态中,从内核态返回用户态的时候,进行信号检测和处理!从内核态返回的时候,会进行一些检测,比如信号检测和信号处理!
那么问题来了,进程为什么会进入内核态?
通过系统调用、异常、中断,可以让进程陷入内核!
在汇编层面上,我们有一个中断编号叫做 80,有一条汇编指令 int 80,称之为 80号中断,用于触发一个软中断,可以让进程陷入内核,当进程执行 int 80 指令时,它会将控制权转移到内核态,并进入内核执行在系统调用表中注册的相应处理程序。
用户态 (User):当进程执行用户代码时,它被认为处于用户态。在用户态下,进程的权限和特权较低,受到操作系统的保护,并且无法直接访问系统的敏感资源。进程只能通过系统调用的方式请求内核来执行特权操作,而不能直接执行,用户态受到访问权限的约束。
内核态 (kernel):当进程执行内核代码、进行系统调用或访问内核数据时,它被认为处于内核态。在内核态下,进程拥有更高的权限和更多的特权,可以执行一些敏感的操作,如修改系统配置、进行硬件控制等。在内核态下,进程可以执行特权指令,并直接访问操作系统内核的资源,内核态具有非常高的优先权,几乎不受权限的约束 。
操作系统通过特定的机制来管理和切换进程的执行模式。进程从用户态切换到内核态通常是通过触发特殊的事件(如系统调用)或指令(如int 80)来完成。当事件或指令触发时,操作系统会进行相应的处理,并将进程的执行模式从用户态切换到内核态,以便进程可以执行特权操作。
需要注意的是,进程在用户态和内核态之间的切换是受限和受控的,并受到操作系统的严格管理。这个机制可以确保操作系统的安全性和稳定性,并防止进程滥用系统资源或干扰其他进程的正常执行。
在学习地址空间的时候,我们说过,32位机器的地址空间如下:
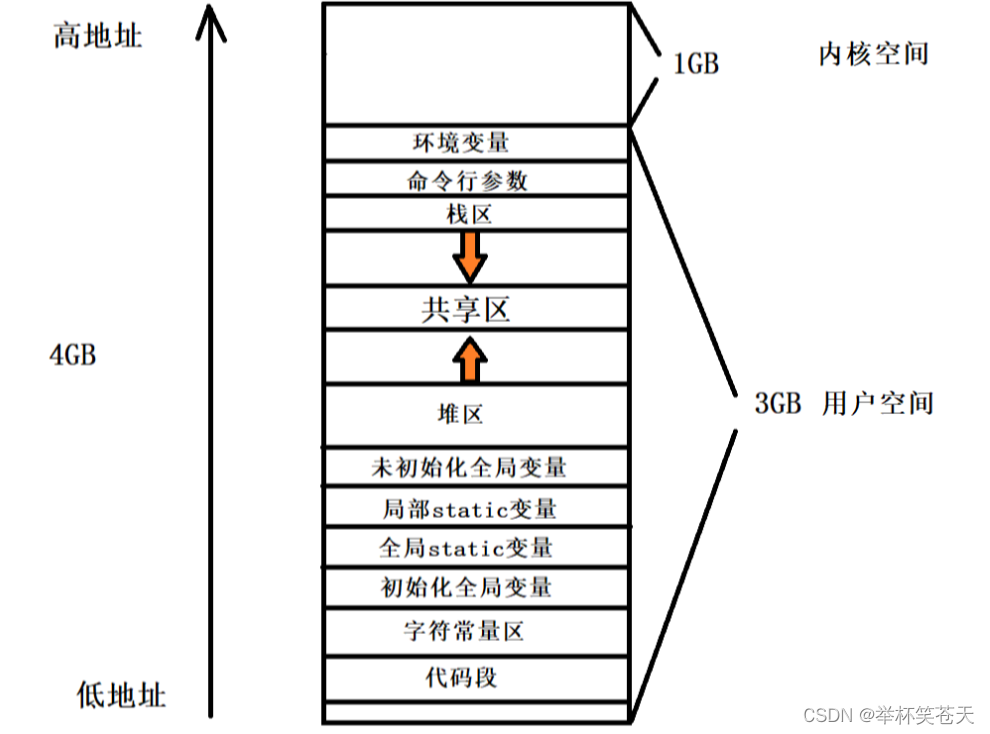
每一个进程有 0 ~ 3GB的空间,这段空间我们称之为用户地址空间,也有 3 ~ 4GB的地址空间,我们称之为内核空间,这段空间是给内核用的,内核如何使用?
实际上, 页表分为用户级页表和内核级页表。
用户级页表是每个进程独有一份的 (进程具有独立性)!
而内核级页表可以被所有进程看到!内核级页表只需一份即可!
内核级页表可以将内核地址空间中的操作系统的代码和数据映射到物理内存中! 每个进程看到的都是同一张内核级页表!
任何一个进程调用系统调用接口, 那么从用户地址空间跳转到内核地址空间找到内核地址空间中的系统调用,通过内核级页表映射到物理内存,执行系统调用!
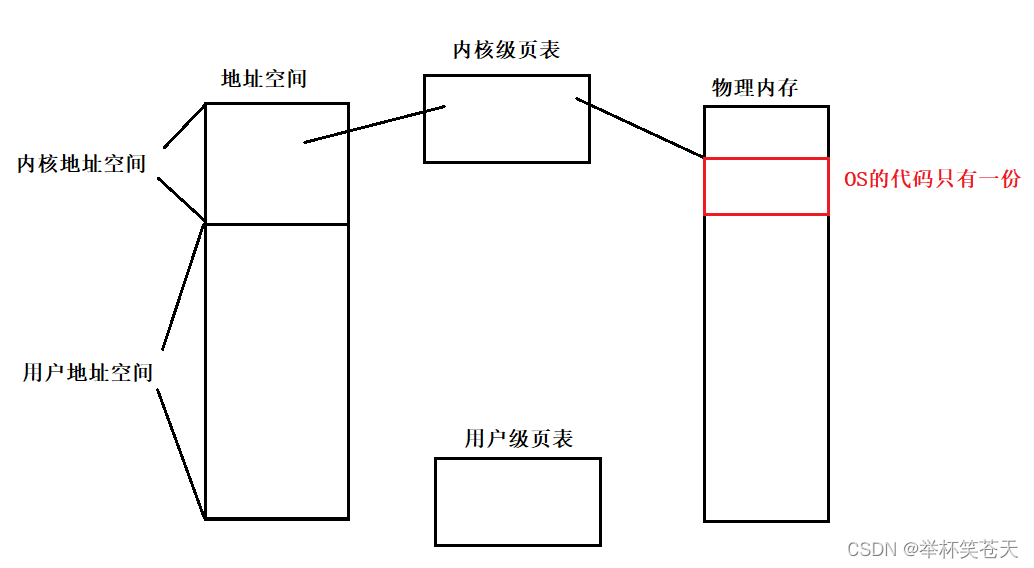
因此不要觉得内核很神奇,内核也是在所有进程的地址空间上下文中跑的!
那么我们可以执行进程切换的代码吗?
可以啊,操作系统内部有对应的系统调用接口 ,当进程的时间片到达, 操作系统底层硬件给我们发送时间中断,操作系统就会去CPU找当前正在执行的进程,通过该进程的地址空间 (内核地址空间),找到对应的系统调用 (进程切换的系统调用) ,因为此时在你这个进程进行上下文切换,因此就在你的地址空间中进行切换,并将此时CPU内部的临时数据全部保存到当前进程的PCB中,进而将该进程剥离CPU,进而CPU调度下一个进程!
因此,内核和进程切换也都是在进程的地址空间上跑的!!!
可是我凭什么有权利执行操作系统提供的代码呢?
依据就是进程是处于内核态 还是 用户态!
可是我们如何确认进程此时是用户态还是内核态呢?
CPU寄存器有两套,一套可见的;另一套不可见,CPU自用!
CPU内部有一个CR3寄存器,CR3寄存器 ---> 表示当前CPU的执行权限
例如:1 表示 内核态、 3 表示用户态
换句话说,CPU内部的寄存器就表明了进程当前处于什么状态!
5.2. 信号处理的整个流程
众所周知,操作系统是软硬件资源的管理者,任何用户,无法绕过操作系统直接访问软硬件资源! 用户是不能也不可以这样做的!
而信号处理,需要先进入内核态 (用户->内核),之所以要从用户态转到内核态是因为用户在有些情况需要访问软硬件资源,而受到了操作系统的限制,因此我们必须先从用户态变成内核态,再访问这些资源!
内核 -> 用户,为什么?怎么办?
之所以需要从内核态转为用户态,我们在这里说两个原因:
其一: 用户的代码没有被执行完。
其二: 用户的若干个进程没有被调度完毕。
这一个计算机中,操作系统本质上是为了给用户提供服务的!
执行用户代码为主!内核代码为辅。
进入内核态是一种临时状态,它必须要返回到用户态,继续调度用户代码。
为什么信号处理的时机是:从内核态返回到用户态的时候处理,而不是一进入内核态就处理呢?
我为什么会进入内核态呢? 原因是我们需要执行内核的代码逻辑,而往往这些代码逻辑优先级更高、更重要的事情,因此我们之前说过,当进程收到一个信号时,操作系统往往可能正在处理优先级更高的事情、或者更重要的事情,怎么体现?
就是从内核态返回到用户态的时候处理信号体现的! 此时潜台词就是操作系统已经把内核的事情处理完了,在去处理信号。
信号捕捉的基本流程:
首先我们要知道,进程是会周期性的陷入内核,最典型的就是操作系统发现进程时间片到达,操作系统会进行进程调度,调度就是在当前进程的上下文中 (内核地址空间) 调用对应的系统调用接口,在调度该系统调用之前,当前执行流必须先陷入内核!这是因为进程调度涉及到管理和操作内核数据结构,例如进程控制块、调度队列和状态切换等,这些操作需要在内核态下才能执行。
当进程在执行用户代码的时候,由于某些原因 (异常、中断、系统调用等等)使进程陷入内核,进入内核后,操作系统调度完优先级高的、更重要的事情后,当准备返回用户态的时候,操作系统会去处理当前进程中可以递达的信号,内核处理信号,无非就是操作系统去检测当前进程PCB中的 pending 位图、block位图、handler处理表!
如果此时检测 pending 位图的所有比特位全部为0,那么此时直接返回到用户态。并继续调度用户代码即可!??
如果,此时检测 pending 位图中有比特位为1的 (即操作系统向该进程发送了某个信号),那么操作系统会先确认是哪一个比特位 (那一个信号),再去 block 位图中找到相应的比特位,查看该信号是否被屏蔽!
如果当前信号被屏蔽,那么此时也就直接返回用户态即可。
如果此时该信号没有被屏蔽,那么就要去执行该信号的处理动作 (handler表中的某个调用),
如果此时该信号对应的 handler 表中的方法是忽略,那么将该进程的 pending 位图的代表该信号的比特位由1->0,然后直接返回用户态,继续调度用户代码即可!
如果该信号的处理方法是默认,比如SIGINT信号,该信号的默认处理动作是Term,那么将该进程的相关内核数据结构( PCB、地址空间、用户级页表等等)以及代码和数据释放掉,并将pending位图中相关的比特位由1->0,就完成了该进程的终止工作。
对于内核态处理信号 (默认 && 忽略), 是很好理解的,信号处理中最不好理解的是捕捉动作,因此我们在这里主要以捕捉动作为例:
在这之前,有两个问题:
问题一 : 当前操作系统检测到某个信号需要被捕捉, 即需要去执行对应的信号捕捉动作 (用户空间),那么我当前是什么状态呢?
问题二: 我当前的状态,能不能执行用户态的 handler方法 (自定义处理动作)!
先说问题一: 此时进程的状态处于内核态!
再说问题二:对于内核态而言,我们之前说过,内核态是几乎不受权限约束的,也就是说,操作系统是能执行用户态中 handler 的方法 (操作系统不受权限的约束),但是操作系统是不要(不愿意)执行用户态 handler的方法!操作系统能做到帮用户执行对应的handler,但是操作系统不愿意,也不想这样做? (能不能和要不要的差别)!
如果让内核态 (kernel) 执行用户层的 handler,那么如果此时这个 handler 里面有非法操作呢,例如 rm、内存问题等等!
而我们之前就说过,操作系统不相信任何用户!正因为操作系统不相信任何用户,因此才能为用户提供更好、更安全的服务!
因此在这里虽然能用内核态执行用户的代码,但是操作系统是不要去执行用户态的代码!
因此我们需要用户态执行用户自己的代码!
当进程要去执行对应信号的自定义动作 (用户态的自定义信号处理方法),此时包含一个隐含的逻辑:进程需要从内核态变成用户态!即需要用户态执行用户自己的代码!
当执行完该信号的自定义动作,此时还需要在进入内核态进行信号收尾动作,比如我们还需要将pending位图中被处理的信号的比特位由1->0,因此当自定义动作处理完成之后,我们依旧需要在陷入内核,进行信号处理的收尾工作,处理完毕之后,在返回到用户态,继续执行用户自己的代码逻辑!‘
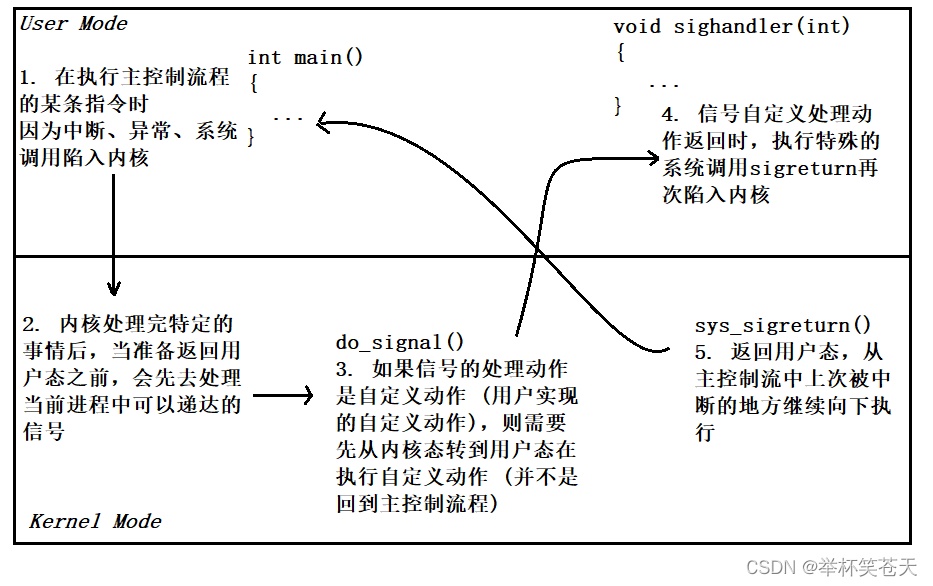
?为了方便理解,我们可以记住下面的图,其代表了信号捕捉的整个流程,如下:
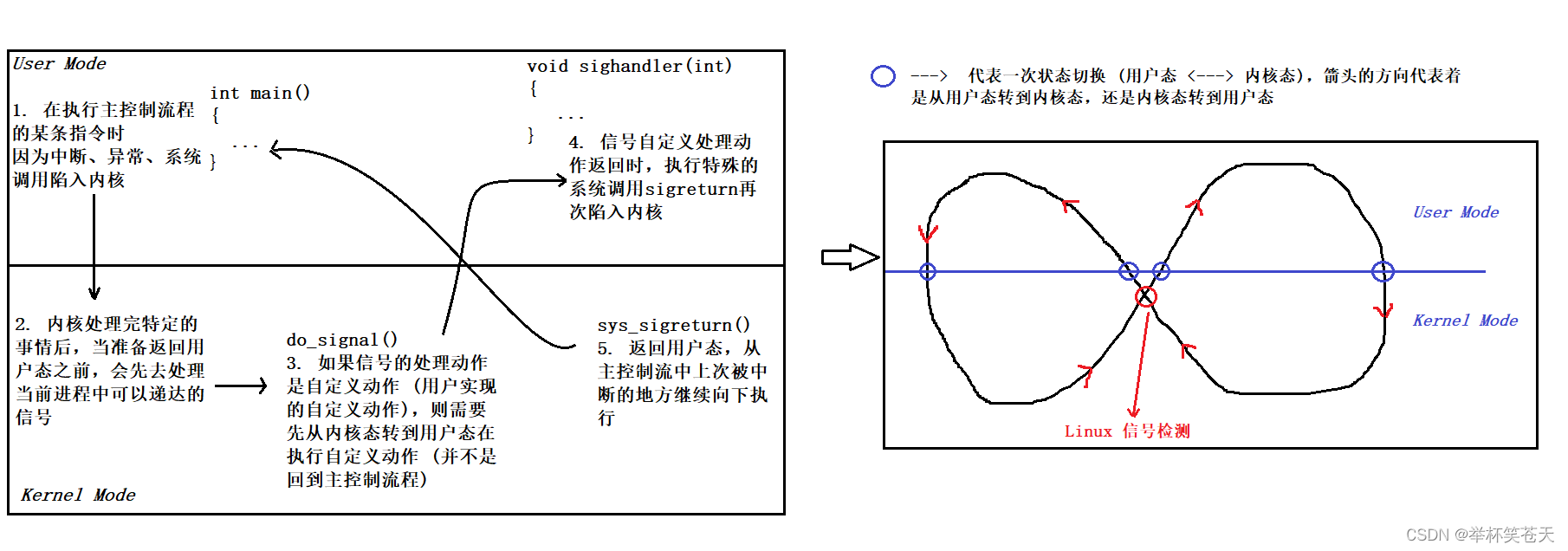
信号捕捉的整个处理流程:
进程正在调度自己的代码 (用户态) ---> 由于某些原因 (异常、中断、系统调用),导致进程陷入内核态,当内核态要返回用户态的时候,进行处理信号,如果该信号已经产生,并且未被阻塞,且信号的处理动作是用户自定义动作,那么就会返回用户态 (内核态) ----> 执行用户层自定义的处理动作 (用户态) ---> 自定义动作执行完,在执行特殊的系统调用再次陷入内核 (内核态) ---> 进行信号收尾处理工作,处理完毕后,进而返回用户态,从主控制流程中上次被中断的地方继续向下调度 (用户态);
5.3. 信号的操作
5.3.1. signal 系统调用
man 2 signal
NAME
signal - ANSI C signal handling
SYNOPSIS
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
RETURN VALUE
signal() returns the previous value of the signal handler,
or SIG_ERR on error. In the event of an error,
errno is set to indicate the cause.对于signal系统调用,我们以及使用过多次,在这里就不再举例了。
5.3.2. sigaction 系统调用
man 2 sigaction
NAME
sigaction - examine and change a signal action
SYNOPSIS
#include <signal.h>
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
RETURN VALUE
sigaction() returns 0 on success; on error,
-1 is returned, and errno is set to indicate the error.
signum:要修改或获取处理方式的信号编号。可以使用预定义的宏(如?SIGINT、SIGTERM?等)或信号编号来指定。act:一个指向?struct sigaction?结构体的指针,用于设置新的信号处理方式。若传入?nullptr,则表示忽略信号(即将对应信号的处理方式设置为默认处理方式)。oldact:一个指向?struct sigaction?结构体的指针,用于保存之前的信号处理方式。若不需要获取之前的处理方式,可以将该参数设置为?nullptr。
struct sigaction {
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};struct sigaction 是一个用于设置和处理信号的结构体,在 Linux 中使用。它包含以下字段:
sa_handler:指向一个函数的指针,用于处理信号。当信号到达时,调用 sa_handler 指向的函数进行信号处理。
sa_sigaction:如果设置了 sa_sigaction 字段,则优先于 sa_handler 字段使用。sa_sigaction 指向的函数具有更多的功能,它可以接收附加的信号信息和指向 ucontext_t 结构的指针。
sa_mask:指定在处理当前信号时需要被屏蔽(阻塞)的信号集合。即,在 sa_handler 或 sa_sigaction 函数执行期间,通过设置 sa_mask 字段可以防止其他指定的信号被中断。
sa_flags:用于指定信号处理的一些标志。常见的标志包括 SA_RESTART(在信号处理函数返回时自动重新启动被中断的系统调用)和 SA_NOCLDSTOP(当子进程停止时不会收到 SIGCHLD 信号)等。
sa_restorer:早期的 Unix 系统中用到的字段,目前已不再使用,通常设为 NULL。
通过填充和设置这些字段,可以使用 sigaction() 函数来注册和处理信号处理程序。这样,当指定的信号到达时,将调用相应的处理函数进行信号处理。此结构体提供了更精确和灵活的信号处理方式,相比使用 signal() 函数注册信号处理程序来说更加强大和可靠。
我们用sigaction捕捉信号,测试如下:
void handler(int signum)
{
std::cout << "PID: " << getpid() << " get a signal: " << signum << std::endl;
}
void Test1(void)
{
struct sigaction act, oldact;
act.sa_handler = handler;
sigaction(SIGINT, &act, &oldact);
while(true)
sleep(1);
}
现象如下:?
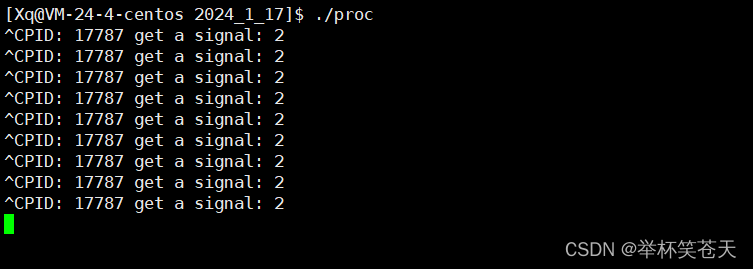
可以看到,sigaction也可以捕捉信号。?但我们今天的重点不是这个。
处理信号的时候,执行自定义动作,如果在处理信号期间,又来了同样的信号,OS如何处理?
实际上,当某个信号的处理函数被调用时,内核会自动将当前信号加入进程的信号屏蔽字,当信号处理函数返回时自动恢复到原来的信号屏蔽字,这样就保证了在处理某个信号时,如果这种信号再次产生,那么它会被阻塞到当前处理结束为止!测试如下:
void sighandler(int signum)
{
std::cout << "PID: " << getpid() << " get a signal: " << signum << std::endl;
sleep(20);
}
void Test2(void)
{
struct sigaction act;
act.sa_handler = sighandler;
sigaction(SIGINT, &act, nullptr);
while(1)
sleep(1);
}现象如下:?
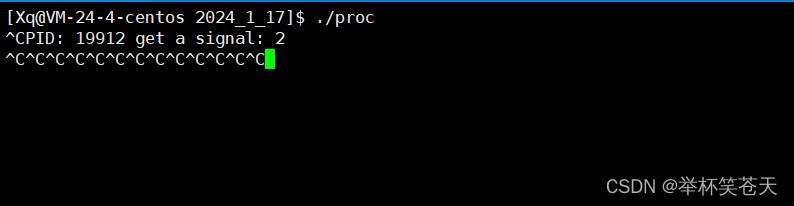
可以看到,当在执行信号处理函数时,?如果此时再产生了该信号,那么实际上该信号是会自动被阻塞的 (当前信号屏蔽字中屏蔽了该信号),现象与我们的预期一致!这也就是操作系统为什么对信号要有block这个位图,其主要原因之一是避免信号处理函数中的递归调用。当一个信号被触发时,如果没有屏蔽该信号,且处理函数尚未返回,又来了一个同样的信号,那么处理函数就会被递归调用。这可能会导致不可预料的行为和系统崩溃。通过屏蔽信号,可以防止同一信号的递归处理。
那么如果在调用信号处理函数时,除了当前信号被自动屏蔽之外,如果我们还希望自动屏蔽另外一些信号,那么我们就可以利用sa_mask这个字段,sa_mask这个字段表面了那些信号是额外屏蔽的信号,当信号处理函数返回时自动恢复原来的信号屏蔽字,测试如下:
?signal.cc的代码如下:
void print_pending(sigset_t& pending)
{
for(size_t i = 1; i <= 31; ++i)
{
if(sigismember(&pending, i))
std::cout << "1";
else
std::cout << "0";
}
std::cout << "\n";
}
void sighandler(int signum)
{
std::cout << "PID: " << getpid() << " get a signal: " << signum << std::endl;
sigset_t pending;
sigemptyset(&pending);
while(true)
{
sigpending(&pending);
print_pending(pending);
sleep(1);
}
}
void Test2(void)
{
struct sigaction act;
act.sa_handler = sighandler;
// 先设置好mask这个字段,在调用sigaction 系统调用
for(size_t i = 3; i <= 7; ++i)
sigaddset(&act.sa_mask, i);
sigaction(SIGINT, &act, nullptr);
std::cout << "信号屏蔽字设置成功" << std::endl;
while(1)
sleep(1);
}
put_signal.sh 代码如下:?
#!/bin/bash
i=2
id=$(pidof proc)
while [ $i -le 7 ]
do
kill -$i $id
echo "kill -$i $id"
let i++
sleep 1
done现象如下:?

可以看到,如果进程正在用户自定义的信号处理函数中,并且设置了sa_mask这个字段,那么此时被写入进sa_mask中的信号,即便产生了,也不会被递达,只有当信号处理函数返回时,才会继续处理这个过程中产生的信号! ?
6. 补充
6.1.?可重入函数
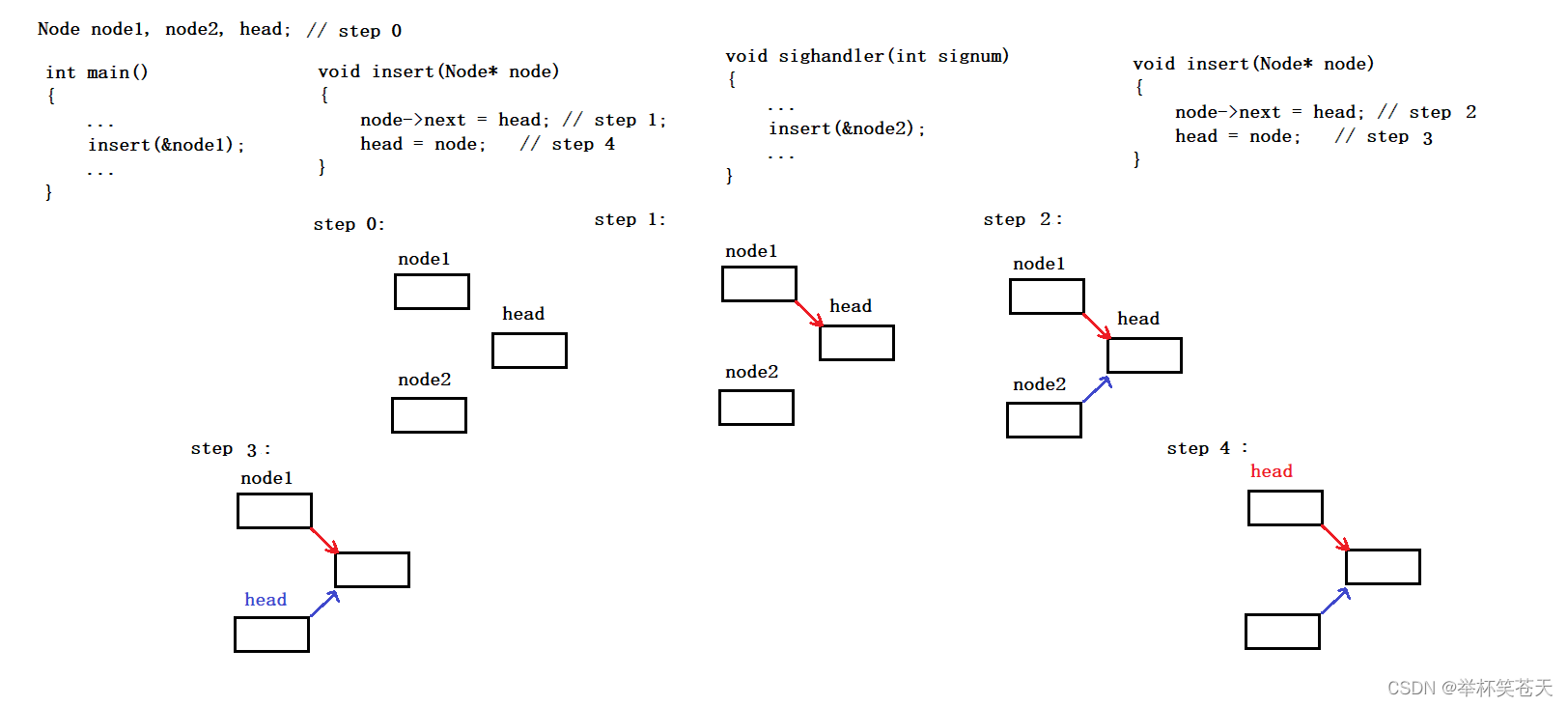
可重入函数的情景如上,分析过程如下:现有三个节点,head为链表的头节点,node1、node2 是两个有效节点,当进程在主函数执行时,遇到了insert,进而调用,当完成上图中的step 1时,此时该进程由于某种原因 (中断、异常等等)陷入了内核,当操作系统处理完相应的任务准备返回到用户态时,此时回去处理信号,检测到当前进程已经收到了某个信号,正好该信号被该进程捕捉了,因而该进程从内核态返回到用户态准备调用相应的自定义处理动作,好巧不巧,这个信号处理动作中也有一个insert,进而调用insert,当自定义动作处理完毕并做好相应的动作后返回到用户态(从上次被中断的地方继续调度),进而完成 step 4,结束后,此时造成的结果就是,node2不见了,造成了内存泄露问题。可关键是,这份代码没有任何问题,只是因为由于特定原因,操作系统调度进程的时序的变化导致了上面这种问题。而我们将一个函数,在特定的时间内,被多个执行流重复进入,这种现象我们称之为函数被重入了。一个函数被重入了,如果没有问题,我们称之为可重入函数;反之,则称之为不可重入函数!
可重入函数 &&不可重入函数,是函数的一种特征!目前,我们用的大部分的函数都是不可重入的!
可重入函数:
没有使用静态数据:可重入函数不会使用全局变量或静态变量保存状态信息,而是将状态信息以参数的形式传入函数中,或者通过指针参数指向的可重入数据结构。
没有使用非可重入的库函数:可重入函数不会调用内部使用静态数据结构的非可重入的库函数,因为这可能导致不同线程之间的竞争条件。
函数局部变量不共享:可重入函数的局部变量是每次调用都有自己的副本,不会被其他线程共享或干扰。
不可重入函数:
使用全局变量或静态变量:不可重入函数使用全局变量或静态变量来保存状态信息,这可能导致不同线程之间的竞争条件。
使用非可重入的库函数:不可重入函数可能调用内部使用静态数据结构的非可重入的库函数,导致竞争条件。
函数局部变量被共享:不可重入函数的局部变量可能被多个线程共享,容易导致数据错误或不一致。
6.2.?volatile
在C语言我们见过该关键字,但今天我们要站在信号的角度重新理解volatile (易变的、不稳定的)。代码如下:
int flag = 0;
void changeFlag(int signum)
{
std::cout << "change flag: 0 -> 1" << std::endl;
flag = 1;
std::cout << "change success" << std::endl;
}
void Test3(void)
{
signal(SIGINT, changeFlag);
while(!flag);
std::cout << "进程正常终止" << std::endl;
}现象如下:?
?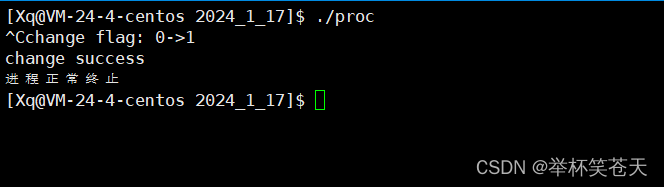
该现象很好理解,当收到了SIGINT信号,进程就会将flag由0->1,进而导致循环终止,进程退出!
可是在未来,我们所编写的代码可能是在不同的编译环境下,而编译器有时候会给我们进行各种代码优化! 例如,在g++,有-O3这个优化选项,于是我们在编译该代码时,加上这个选项,然后我们看现象:
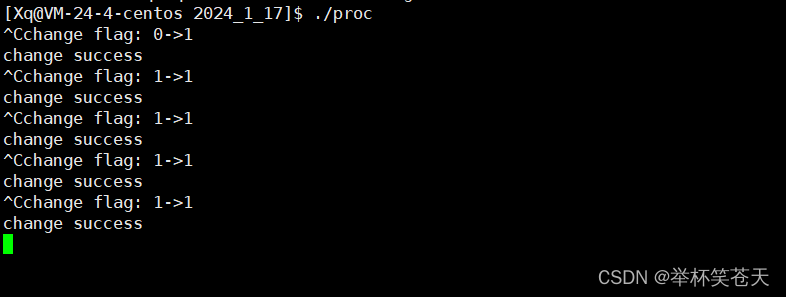
我们发现,当进程收到了SIGINT信号时,已经完成了对flag的修改 (0->1),可令人奇怪的是,为什么进程没有终止呢?即为什么这个循环没有退出呢?按道理说,应该当flag = 1的时候,循环会退出,进而进程也会终止的啊!这是为什么呢?
我们知道,CPU内部是有寄存器的,而编译器有时候会给我们进行代码优化,发现这个flag是一个全局变量,但是在整个调用过程中没有做过任何的修改!因此编译器认为,CPU每次去访问内存太慢了,故在编译的时候,编译器就将 flag 的值缓存到CPU内部的某一个寄存器 (例如edx),从此往后,当这个循环作检测时,CPU就直接去访问 edx 这个寄存器,而不会去访问内存!尽管此时产生信号,并执行相应的自定义处理动作 (flag:0 -> 1),此时只是更改内存上的值,而并不会影响寄存器中的值,因此这个循环也不会被终止 (寄存器中的值始终为0),因为此时CPU并不会去内存去访问 flag,这就导致了内存被遮盖的现象。因此为了保持内存的可见性!故有了 volatile 关键字!表面该对象是易变的、不稳定的,以后访问该对象,不允许编译器做这种优化,必须通过内存访问flag (确保内存的可见性),这样可以避免编译器对变量的优化,保证每次访问都是最新的值,从而避免出现不一致性的问题。于是更改代码如下:
volatile int flag = 0;
void changeFlag(int signum)
{
std::cout << "change flag: " << flag;
flag = 1;
std::cout << "->" << flag << std::endl;
std::cout << "change success" << std::endl;
}
void Test3(void)
{
signal(SIGINT, changeFlag);
while(!flag);
std::cout << "进程正常终止" << std::endl;
}现象如下:?
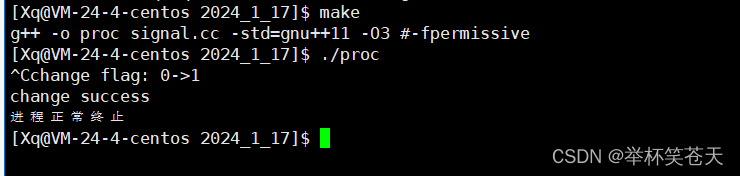
总之,
volatile?关键字可以防止编译器对变量的优化,保证每次访问都是从内存中读取最新的值,从而保证内存的可见性。这就是我们对volatile的重新认识。
6.3. SIGCHLD信号
在进程控制,我们就详谈过进程等待,在这里就不做过多赘述了,实际上,子进程在终止时会通过操作系统向父进程发送17号信号SIGCHLD,该信号的默认处理动作是忽略。
既然你这样说,那么验证代码如下:
void sig_handler(int signum)
{
std::cout << "get a signal: " << signum <<std::endl;
}
void Test4(void)
{
signal(SIGCHLD, sig_handler);
if(fork() == 0)
{
sleep(1);
exit(0);
}
wait(nullptr);
}现象如下:?
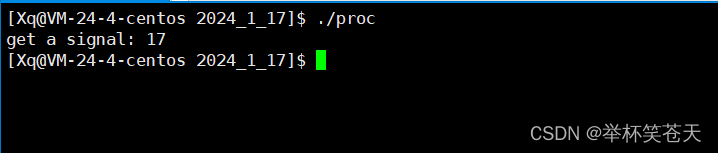
通过代码 + 现象,我们可以确认,当子进程退出时,子进程会通过操作系统向父进程发送17号信号(SIGCHLD);
在信号处理函数中,可以通过非阻塞方式循环等待所有子进程的退出状态。通过调用?
waitpid()?函数,并设置?WNOHANG?选项,可以立即返回子进程的退出状态,而不阻塞父进程的执行。通过循环检查所有子进程的退出状态,如果所有子进程都已退出,就可以避免产生僵尸进程。这种方式可以有效地管理子进程的退出,防止产生大量的僵尸进程,并且不会阻塞父进程的调度。父进程可以及时处理子进程的退出状态,并根据需要做进一步的处理,比如重新启动子进程或清理资源等。
需要注意的是,父进程在捕捉到 SIGCHLD 信号后,需要在信号处理函数中正确地处理多个子进程退出的情况。可以通过循环检查子进程的退出状态并处理,直到所有子进程都已退出为止。
总之,通过在信号捕捉函数中进行非阻塞等待所有子进程退出,可以防止产生僵尸进程,并且不会影响父进程的调度。这是一种常用的处理子进程退出的方法。
代码如下:
void handler(int signum)
{
int status = 0;
int id = 0;
while((id = waitpid(-1, &status, WNOHANG)) > 0) // 循环式的非阻塞等待所有子进程
{
std::cout << "wait success,PID: "<< id << std::endl;
std::cout << "退出信号: " << (status & 0x7F) << std::endl;
}
std::cout << "child process exit success" << std::endl;
}
void Test1(void)
{
signal(SIGCHLD, handler);
pid_t id = fork();
if(id == 0)
{
sleep(1);
exit(0);
}
while(true)
{
std::cout << "父进程正在被调度" << std::endl;
sleep(1);
}
}有时候,如果我们不想等待子进程,也不想获取子进程的退出信息,并且我们还想让子进程退出之后,自动释放僵尸子进程!那该怎么做呢?
我们可以对SIGCHLD信号自定义捕捉,捕捉方式:SIG_IGN,表示忽略该信号。这样我们就可以达到上面的目的,子进程退出之后,操作系统会为子进程自动处理释放资源的工作,包括清理僵尸进程的工作!代码如下:
void Test2(void)
{
signal(SIGCHLD, SIG_IGN);
if(fork() == 0)
{
sleep(3);
exit(0);
}
while(true)
{
std::cout << " 父进程正在被调度" << std::endl;
sleep(1);
}
}现象如下:
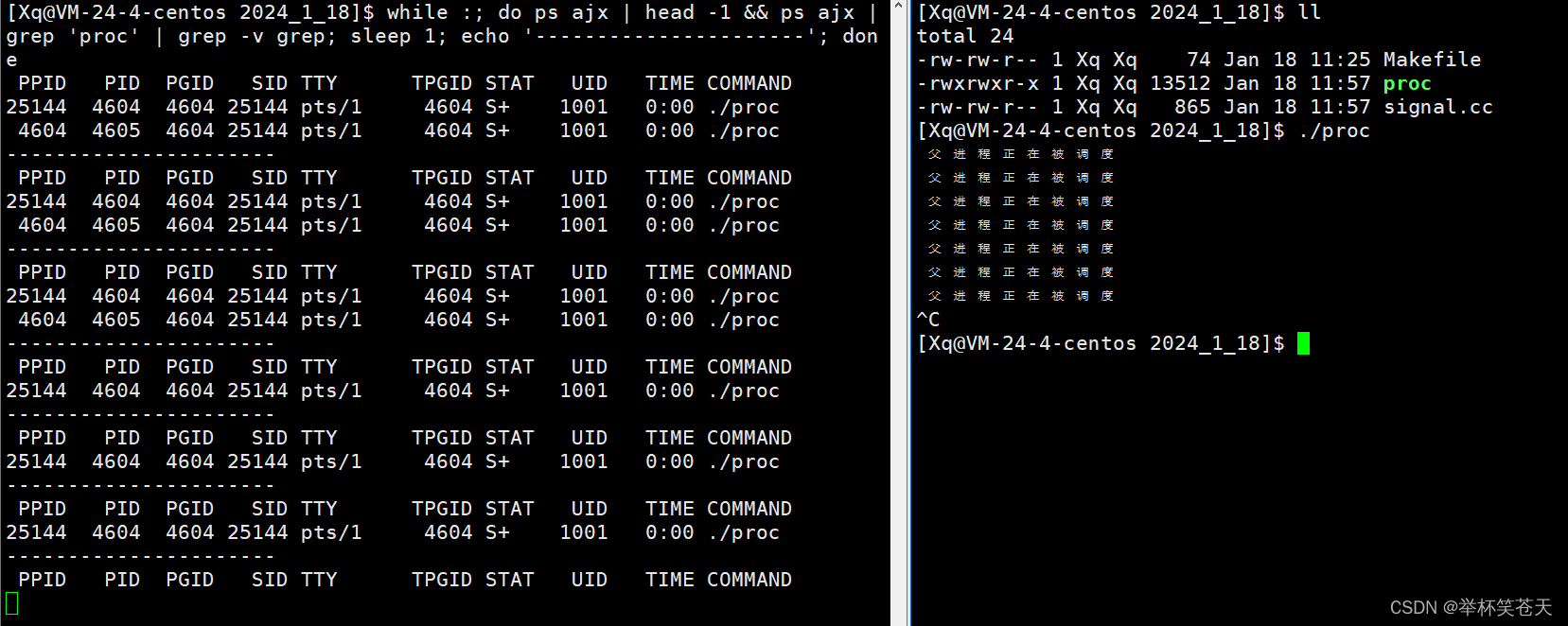
通过现象,我们可以得出,当对SIGCHLD信号捕捉后,并将其后续处理动作设置为SIG_IGN,子进程退出后,自动会被回收,不会产生僵尸进程。可是,问题来了,SIGCHLD信号的默认处理动作不就是忽略 (Ign --- Child stopped or terminated) 吗?为什么我们还要显式传递SIG_IGN呢? 这两个忽略有什么差异呢?
我们可以简单地理解为:
默认处理动作 (Ign) 表示对该信号什么都不做,即不注册任何处理函数。当信号发生时,操作系统将按照默认动作处理该信号,而对于 SIGCHLD 信号,默认的处理动作是忽略该信号,子进程退出时,该僵尸就僵尸。
而显式设置 SIG_IGN 的方式是告诉操作系统,对该信号不注册任何处理函数,并且希望操作系统自动回收子进程退出后的资源,避免产生僵尸进程。实际上,SIG_IGN 是一种特殊的处理函数,它的功能就是忽略信号。
因此,当我们将 SIGCHLD 信号的处理方式设置为 SIG_IGN 时,我们告诉操作系统对 SIGCHLD 信号不做任何处理,并且希望操作系统自动回收子进程资源,避免产生僵尸进程。
总结起来,SIG_IGN 是一种特殊的处理方式,用于告诉操作系统对信号不做任何处理,但是对于特定的信号(比如 SIGCHLD)会有额外的处理行为,如自动回收子进程的资源。而默认处理动作 (Ign) 就是对该信号什么都不做,包括子进程资源的回收,从而可能产生僵尸进程。
最后再补充一点,子进程被暂停时,也会向父进程发送 17号信号(SIGCHLD);
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 6.2 声音编辑工具GoldWave5简介(2)
- Windows 10中蓝牙相关的问题,至少有11种可能的解决办法
- 大数据技术原理及应用课实验4: NoSQL和关系数据库的操作比较
- 浅谈归并排序:合并 K 个升序链表的归并解法
- 基于领域驱动设计的低代码平台的设计与实现
- 亚马逊自养号运营的重要性和优势详解
- Jtti:网站主机的数据库技术有哪些
- Docker 部署
- 基于OpenCV的视频流处理方法
- The Grid – Responsive WordPress Grid响应式网格插件