MongoDB - 索引底层原理和使用,聚合的使用(案例 + 演示)
目录
一、MongoDB 索引
1.1、说明
MongoDB 中的索引和 MySQL 索引十分类似,能够极大的提高查询效率,如果没有索引,就需要扫描全集数据,效率非常低.? 索引是一种特殊的数据结构,存储在一个易于遍历的读取的数据集合中,是对数据库表中一列或多列值进行排序的一种结构.
1.2、原理
下图来自于 MongoDB 官方文档:Indexes — MongoDB Manual
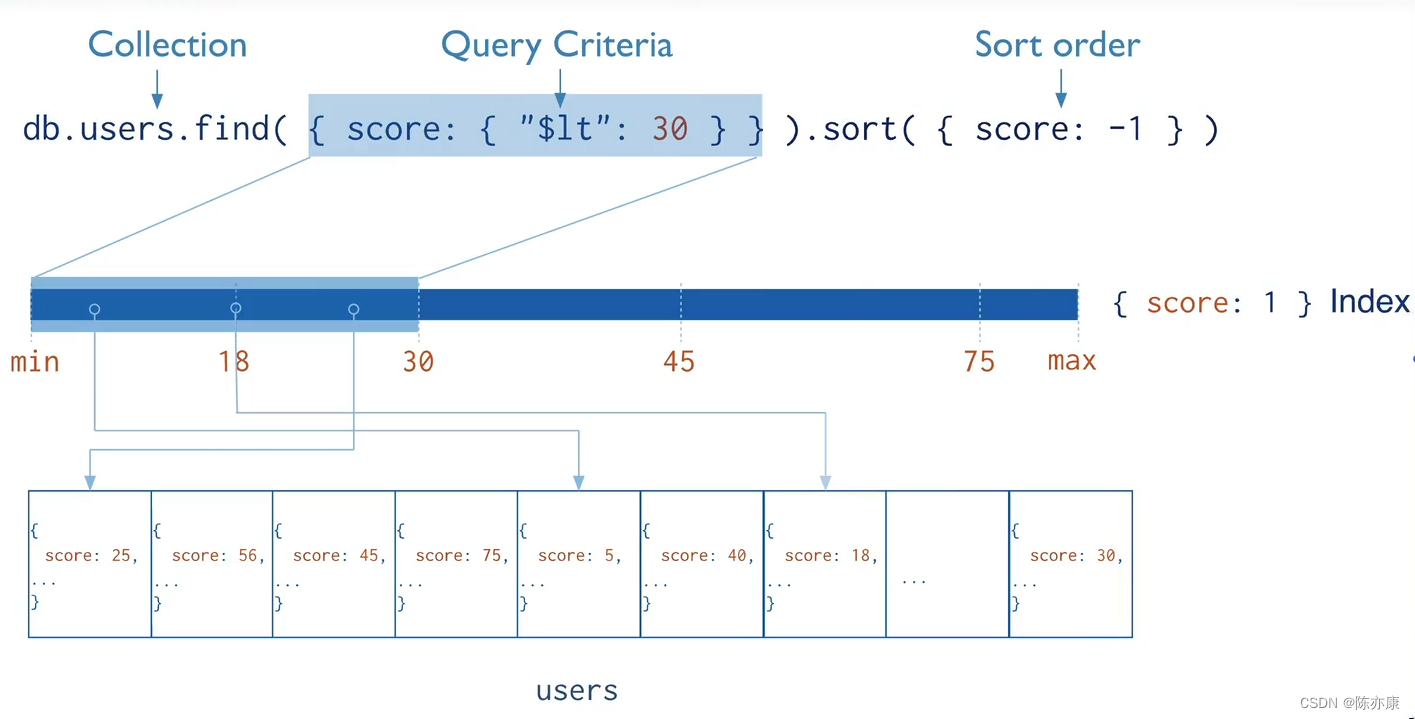
解释:
例如有一个 users 集合,每一个元素都含有 score 这个属性,现在如果需要查询分数小于 30 的文档,在没有索引的情况下就需要扫描全集数据,将符合条件的放到结果集中.
为了提升查询效率,我们就可以对 score 建立索引,建立索引的过程中就会对成绩按照我们建立索引的指定的参数,对分数进行升序或者降序排序,保存到索引库中.? 这样,当查询分数小于 30 的文档时,就可以直接从排好序的分数索引中拿到分数对应的指针,进而拿到文档.
1.3、操作
1.3.1、创建索引
语法如下
db.集合名.createindex(keys, options)?示例如下
> db.index.find();
{ "_id" : 0, "name" : "cyk0", "age" : 20 }
{ "_id" : 1, "name" : "cyk1", "age" : 21 }
{ "_id" : 2, "name" : "cyk2", "age" : 22 }
{ "_id" : 3, "name" : "cyk3", "age" : 23 }
{ "_id" : 4, "name" : "cyk4", "age" : 24 }
{ "_id" : 5, "name" : "cyk5", "age" : 25 }
{ "_id" : 6, "name" : "cyk6", "age" : 26 }
{ "_id" : 7, "name" : "cyk7", "age" : 27 }
{ "_id" : 8, "name" : "cyk8", "age" : 28 }
{ "_id" : 9, "name" : "cyk9", "age" : 29 }
>
> db.index.createindex({name: 1, age: -1})
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
语法中的 key 表示要创建的索引对象,1 表示按照升序创建索引,-1 表示降序创建索引.
options 表示一些可选参数,如下(黄色标记为常用参数):
| Parameter | Type | Description |
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 有时候创建的索引特别大,就可能会阻塞,因此需要后台创建. |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
例如指定索引的名称:
> db.index.createIndex({age: 1}, {name: 'age_index'});
{
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"createdCollectionAutomatically" : false,
"ok" : 1
}
>
> db.index.getIndexes();
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_"
},
{
"v" : 2,
"key" : {
"age" : 1
},
"name" : "age_index"
}
]
> 1.3.2、查看集合索引列表
db.集合名.getIndexes()

1.3.3、查看集合索引大小
db.集合名.totalIndexSize()?
?
1.3.4、删除集合所有索引
db.集合名.dropIndexes()
Ps:id 索引不会被删除.
1.3.5、删除集合指定索引
db.index.dropInde('索引名')
1.3.6、创建复合索引
与 MySQL 的复合索引一样,一个索引值是由多个 key 进行维护的索引就是复合索引.
db.集合名.createIndex({key, key, ......})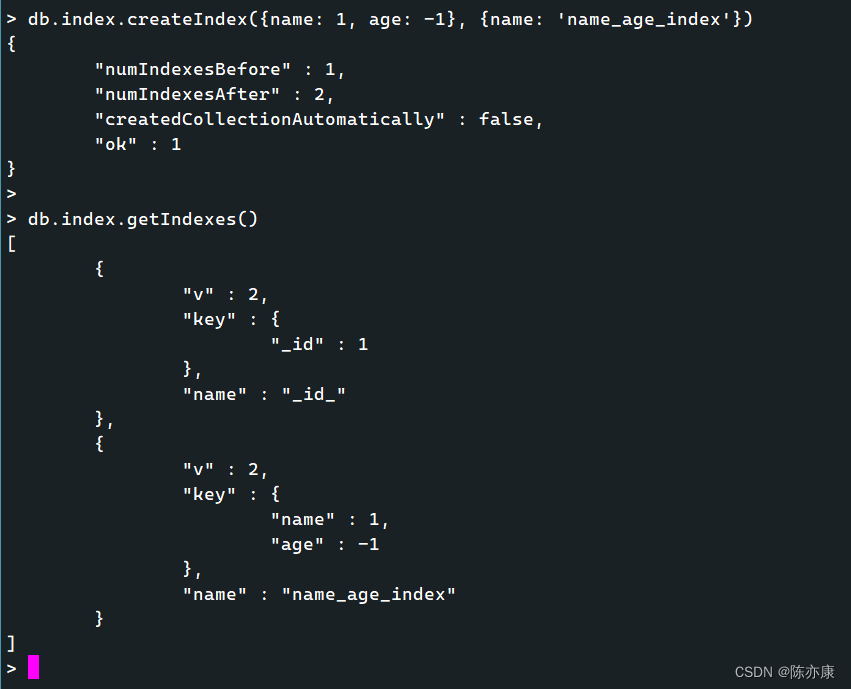
1.4、聚合
MongoDB 中的聚合主要用于处理 例如 求和、求差、平均值 等,并返回计算结果. 类似于 MySQL 中的 max()、count(*).
db.集合名.aggregate([{$group: {_id: '$要分组的字段', 自定义组名: {聚合表达式}}}])| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 将值加入一个数组中,不会判断是否有重复的值。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
例如数据如下:
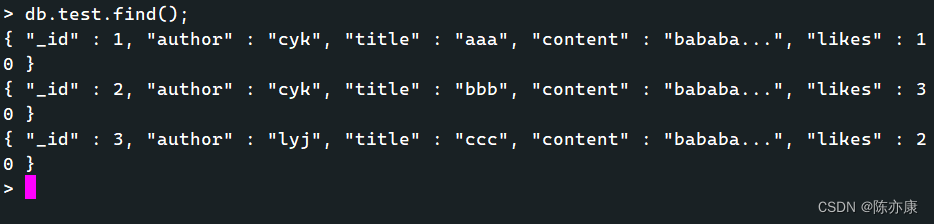
作者 cyk 写了文章 aaa 和 bbb,作者 lyj 写了文章 ccc.? likes 表示点赞量.
a) 统计每个作者写的文章数

当然有需要,也可以对聚合的结果乘上一个倍数.
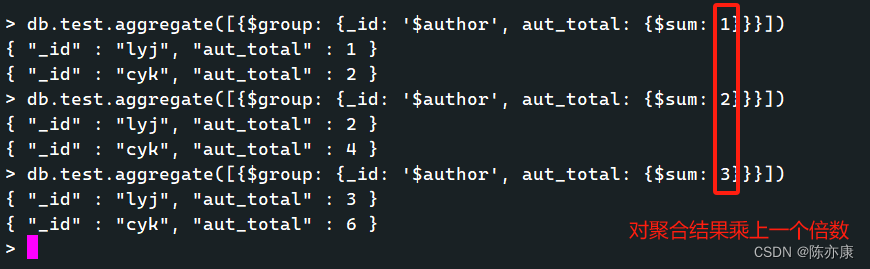
b)统计每个作者各自文章中点赞量的最大值

c)统计每个作者各自文章中点赞量的最小值

d)?统计每个作者的平均点赞量

e)统计每个作者的所有文章内容(不会去重)

f)统计每个作者的所有文章内容(去重)

g) 获取每个作者第一个文章标题.

?
h)获取每个作者最后一个文章标题.


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!