关于Hive架构原理,尚硅谷
发布时间:2024年01月21日
? ? ? ?最近学习hive 时候,在做一个实操案例,具体大概是这样子的:
? ? ? ?我在dataGip里建了一个表,然后在hadoop集群创建一个文本文件里面存储了数据库表的数据信息,然后把他上传到hdfs后,dataGrip那个表也同步了我上传到hdfs数据信息,这一下子让我有点懵了,为什么可以实现同步呢?
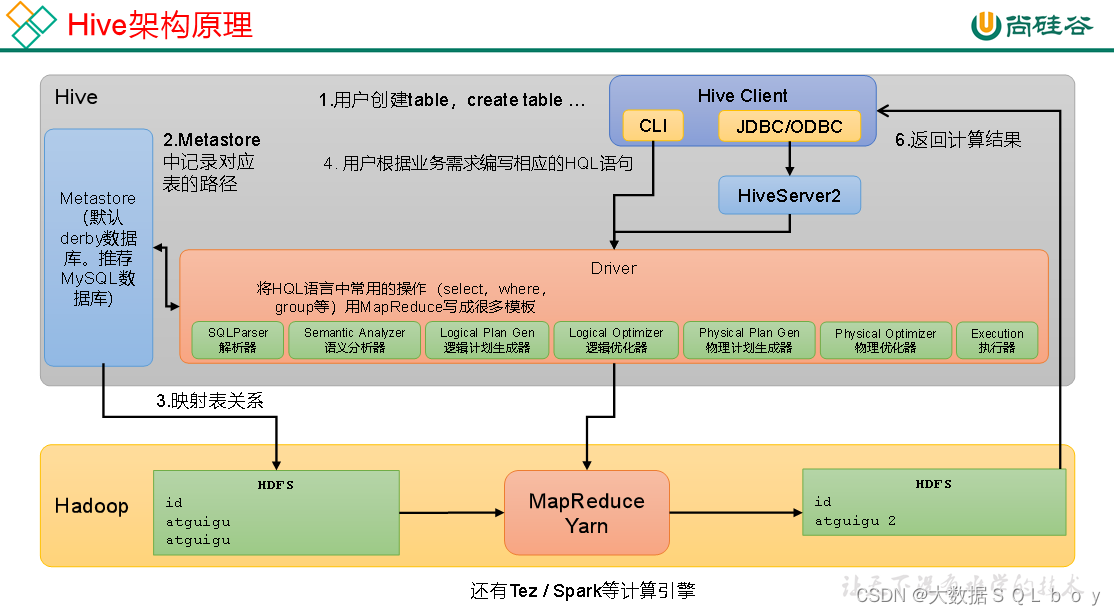
? ? ? 首先hive的定义为,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,Hive中每张表的数据存储在HDFS
 ?
?
? ?·用户接口:Client?, 其中包括CLI(command-line?interface)、JDBC/ODBC。
? ?·元数据:Metastore,包括:数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
? ?·hiveserver2是hive中的服务,其作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
? ? ? 另外对于hiveserver2访问
? ? ? ? ? ? ? ·可以使用命令行客户端beeline进行远程访问
? ? ? ? ? ? ? ·或者使用Datagrip等图形化客户端(类似于navicat)进行远程访问
? ? ? ?这里关键在于理解真正的表数据信息在hdfs,而在dataGrip的表实际上是根据matestored 元数据以及hdfs数据信息映射到数据库得到的一张张表。
而且datagrip实际上根据hdfs路径找到对应的数据信息的
? ? ? ? 因此回到我上面讲的实操案例,具体流程:
- 我在首先创建一个表(注意:建表是有默认hdfs路径),比如teacher,这个表的元数据信息(如表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等、hdfs对应路径信息存储在mesatore,即MySQL
- 我从集群上传表的数据,然后此时hdfs上我所上传指定的位置路径(也是建表时的指定hdfs路径(我现在使用默认的))
- 之后,dataGrip通过hdfs路径上获得了表的数据,并利用映射关系将数据与元数据结构化得到对应的表及数据,从而实现所谓的“同步”。
文章来源:https://blog.csdn.net/m0_70437378/article/details/135729174
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【网络安全】upload靶场pass1-10思路
- 2024年【陕西省安全员A证】考试题及陕西省安全员A证模拟考试题库
- ssm高校图书馆管理网站(开题+源码)
- HTML--CSS--超链接样式以及鼠标样式自定义
- Python之列表中常见的方法
- 测试熟悉新技术
- 逐步分解,一文教会你如何用 jenkins+docker 实现主从模式
- lwip发送组播数据问题
- YOLOv8使用自定义改进后的模型同时《加载官方预训练权重》教程,附代码
- 深入理解Java中的ThreadLocal