Flink-容错机制checkpoint
发布时间:2023年12月19日
检查点的保存
周期性的触发保存
“随时存档”确实恢复起来方便,可是需要我们不停地做存档操作。如果每处理一条数据就进行检查点的保存,当大量数据同时到来时,就会耗费很多资源来频繁做检查点,数据处理的速度就会受到影响。所以在Flink中,检查点的保存是周期性触发的,间隔时间可以进行设置。
保存的时间点
我们应该在所有任务(算子)都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。
这样做可以实现一个数据被所有任务(算子)完整地处理完,状态得到了保存。
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了。当然这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;kafka就是满足这些要求的一个最好的例子。
检查点算法
在Flink中,采用了基于Chandy-Lamport算法的分布式快照,可以在不暂停整体流处理的前提下,将状态备份保存到检查点。
检查点分界线(Barrier)
借鉴水位线的设计,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。收到保存检查点的指令后,Source任务可以在当前数据流中插入这个结构;之后的所有任务只要遇到它就开始对状态做持久化快照保存。由于数据流是保持顺序依次处理的,因此遇到这个标识就代表之前的数据都处理完了,可以保存一个检查点;而在它之后的数据,引起的状态改变就不会体现在这个检查点中,而需要保存到下一个检查点。
这种特殊的数据形式,把一条流上的数据按照不同的检查点分隔开,所以就叫做检查点的“分界线”(Checkpoint Barrier)。

分布式快照算法(Barrier对齐的精准一次)
具体实现上,Flink使用了Chandy-Lamport算法的一种变体,被称为“异步分界线快照”算法。算法的核心就是两个原则:
- 当上游任务向多个并行下游任务发送barrier时,需要广播出去;
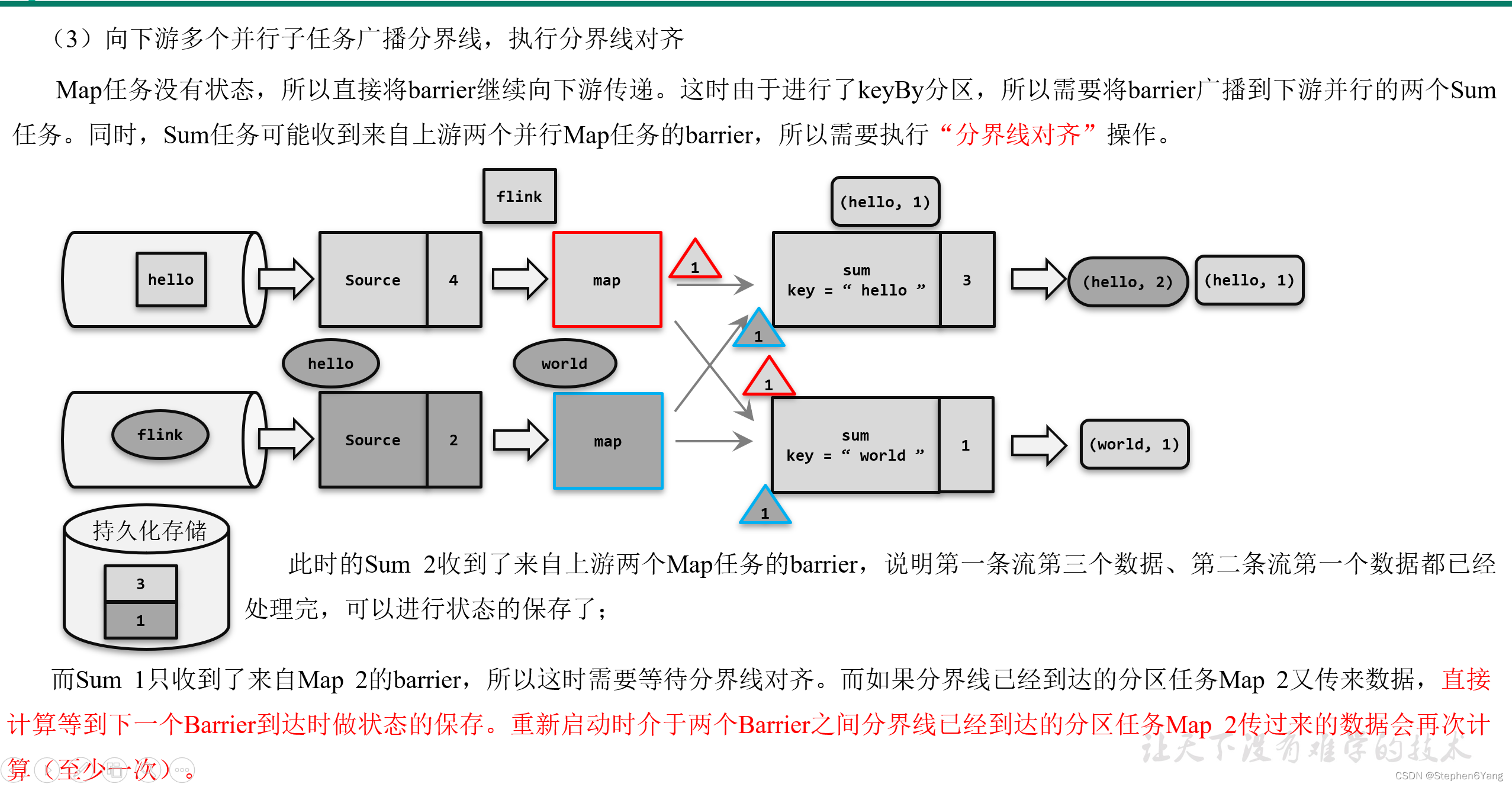
- 而当多个上游任务向同一个下游任务传递分界线时,需要在下游任务执行“分界线对齐”操作,也就是需要等到所有并行分区的barrier都到齐,才可以开始状态的保存。
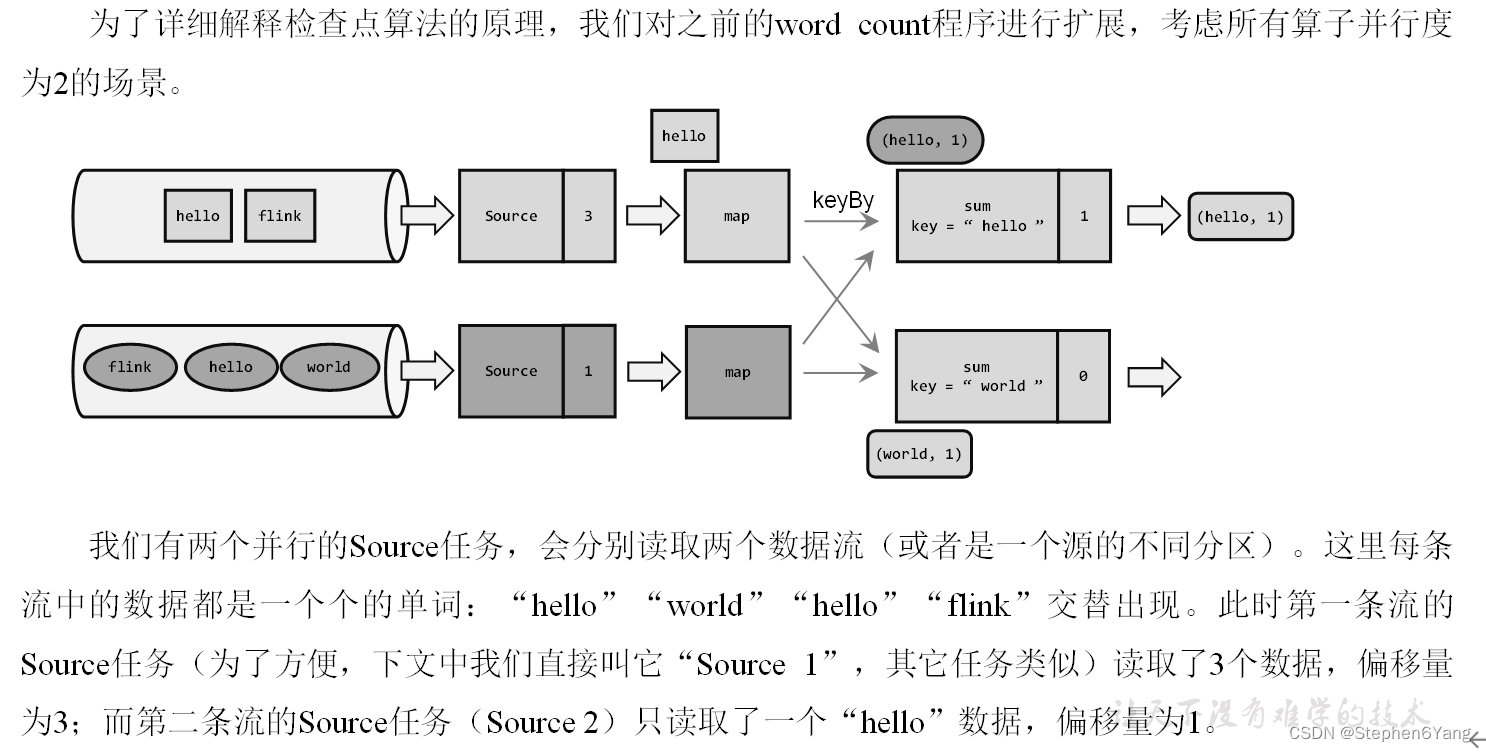
触发检查点保存
(1)触发检查点:JobManager向Source发送Barrier;
(2)Barrier发送:向下游广播发送;
(3)Barrier对齐:下游需要收到上游所有并行度传递过来的Barrier才做自身状态的保存;
(4)状态保存:有状态的算子将状态保存至持久化。
(5)先处理缓存数据,然后正常继续处理
完成检查点保存之后,任务就可以继续正常处理数据了。这时如果有等待分界线对齐时缓存的数据,需要先做处理;然后再按照顺序依次处理新到的数据。当JobManager收到所有任务成功保存状态的信息,就可以确认当前检查点成功保存。之后遇到故障就可以从这里恢复了。
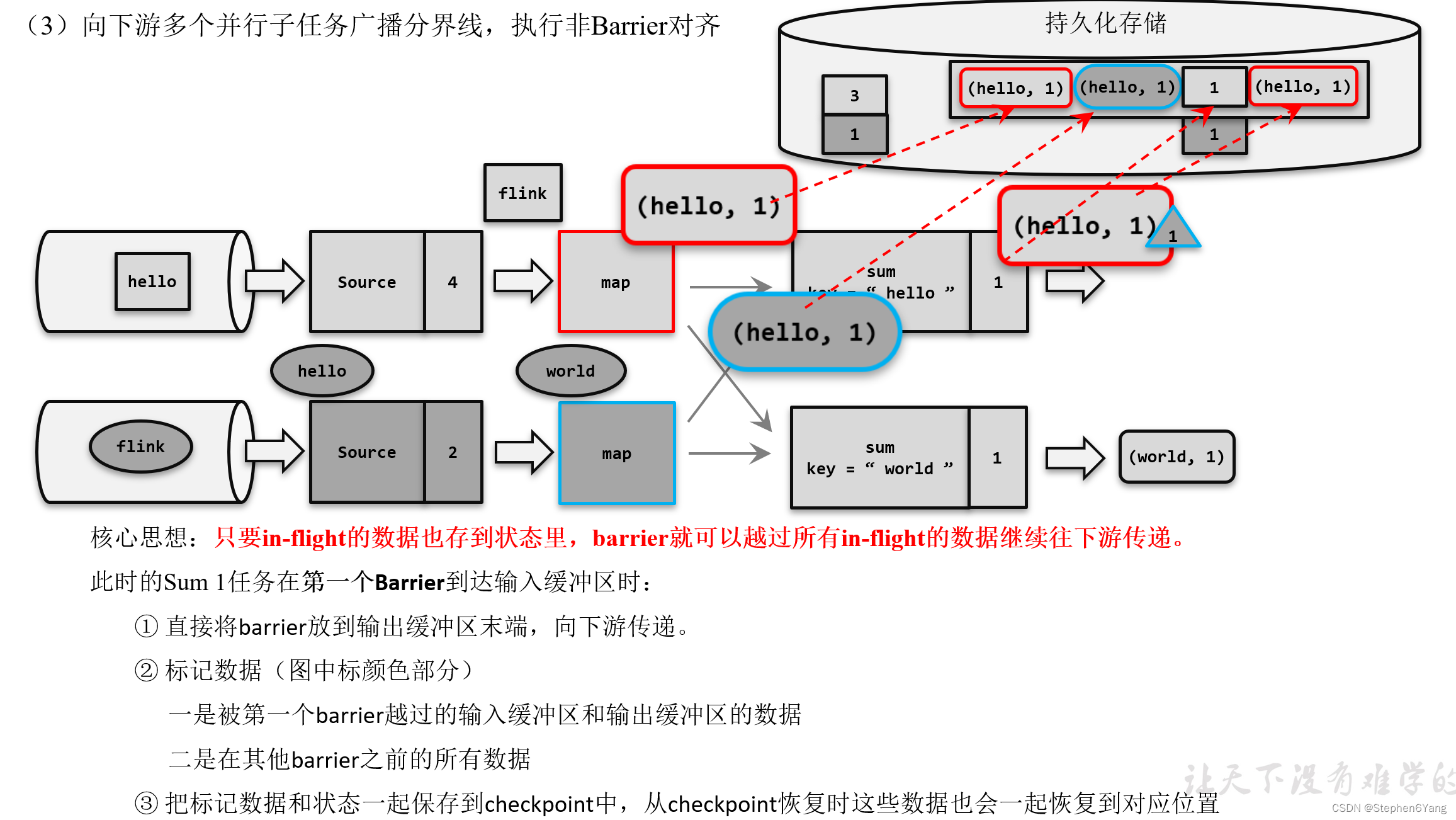
(补充)由于分界线对齐要求先到达的分区做缓存等待,一定程度上会影响处理的速度;当出现背压时,下游任务会堆积大量的缓冲数据,检查点可能需要很久才可以保存完毕。为了应对这种场景,Barrier对齐中提供了至少一次语义以及Flink 1.11之后提供了不对齐的检查点保存方式,可以将未处理的缓冲数据也保存进检查点。这样,当我们遇到一个分区barrier时就不需等待对齐,而是可以直接启动状态的保存了。
分布式快照算法(Barrier对齐的至少一次)
分布式快照算法(非Barrier对齐的精准一次)
文章来源:https://blog.csdn.net/qq_44675837/article/details/135088327
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 零基础学习鸿蒙开发,掌握这一点就够了!
- C++基础1
- 电影《艾里甫与赛乃姆》简介
- 鸿蒙列表,item组件封装传参问题?@ObjectLink 和@Observerd
- webstorm中直接运行ts(TypeScript)
- 【LeetCode】2619. 数组原型对象的最后一个元素
- 轻量化的yolov8部署到安卓Android手机端
- 怎么开启基于软件标签的kasan, CONFIG_KASAN_SW_TAGS=y
- Python:try的正确使用方法
- (windows2012共享文件夹和防火墙设置