Redis最实用的基础入门数据结构和常用指令使用教程
1.单线程redis操作为什么那么快?
一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。
Linux 中的 IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
2.redis基本数据结构
Redis 有 5 种基础数据结构,分别为:string (字符串)、list (列表)、set (集合)、hash (哈希) 和 zset (有序集合)。
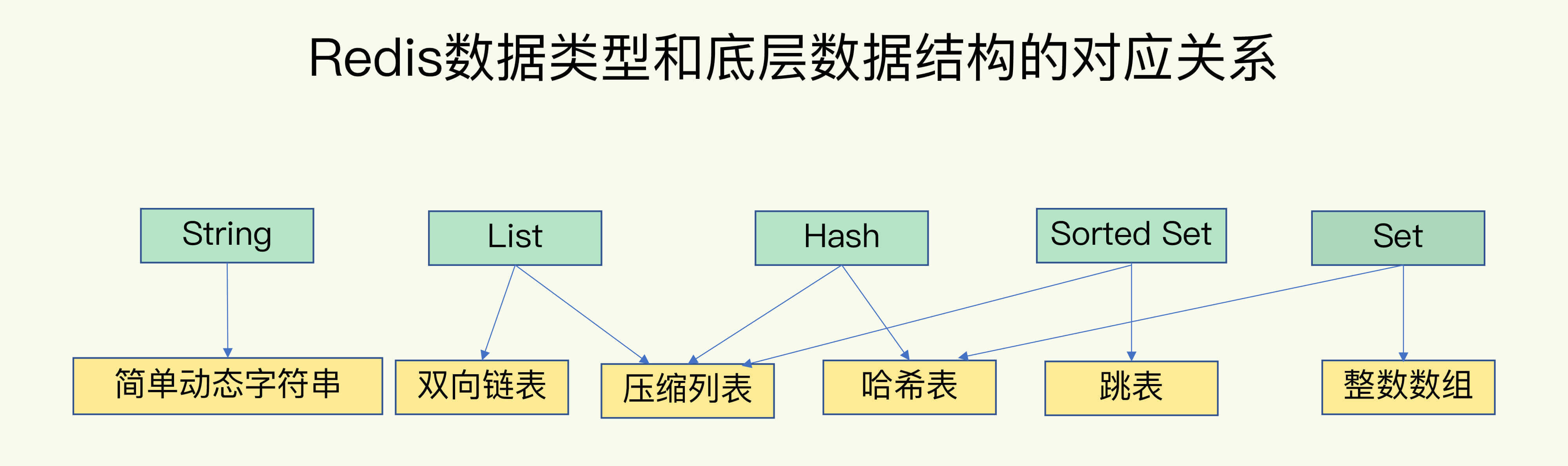
可以看到,String 类型的底层实现只有一种数据结构,也就是简单动态字符串。而 List、Hash、Set 和 Sorted Set 这四种数据类型,都有两种底层实现结构。通常情况下,我们会把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对,其实现原理和Java的HashMap一样,所以同样有哈希冲突,redis也是使用链表解决哈希冲突,随着键值对越来越多,哈希冲突频率越来越高,导致链表越来越长,最终结果就是redis的性能下降,所以redis同样需要rehash操作来解决。
Java 的 HashMap 在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面。如果 HashMap 中元素特别多,线程就会出现卡顿现象。Redis 为了解决这个问题,它采用渐进式 rehash。
它会同时保留旧数组和新数组,然后在定时任务中以及后续对 hash 的指令操作中渐渐地将旧数组中挂接的元素迁移到新数组上。Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。这意味着要操作处于 rehash 中的字典,需要同时访问新旧两个数组结构。如果在旧数组下面找不到元素,还需要去新数组下面去寻找。
2.1 String(字符串)
字符串 string 是 Redis 最简单的数据结构。
Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512M。
字符串是由多个字节组成,每个字节又是由 8 个 bit 组成,如此便可以将一个字符串看成很多 bit 的组合,这便是 **bitmap「位图」**数据结构,
String常用指令
127.0.0.1:6379> set key value [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|KEEPTTL] [NX|XX] [GET]
127.0.0.1:6379> set str helloworld
OK
127.0.0.1:6379> get str
"helloworld"
127.0.0.1:6379> exists str # 判断key是否存在
(integer) 1
127.0.0.1:6379> keys st* # 查找某些key,返回符合正则表达式的所有key,如果key很多导致redis卡主
1) "str"
127.0.0.1:6379> scan 0 match st* count 1000 # 也是查找key 从游标0开始,匹配正则, 这里的count 1000不是返回1000条,限定服务器单次遍历的字典槽位数?(约等于1000)
1) "0" # 返回结果游标为0代表查找遍历结束
2) 1) "str"
127.0.0.1:6379> strlen str
(integer) 10
127.0.0.1:6379> mset str1 v1 str2 v2 # 批量操作
OK
127.0.0.1:6379> mget str1 str2
1) "v1"
2) "v2"
127.0.0.1:6379> set number 0
OK
127.0.0.1:6379> incr number
(integer) 1
127.0.0.1:6379> get number
"1"
127.0.0.1:6379> incrby number 5 # 操作value为数字类型
(integer) 6
127.0.0.1:6379> setex str4 10 ab # 设置过期时间
OK
127.0.0.1:6379> ttl str4 # 查看剩余时间
(integer) 5
127.0.0.1:6379> exists str4
(integer) 0
127.0.0.1:6379> setnx lock uuid # setnx (set if not exist) # 不存在才能设置,常在分布式锁中使用??
(integer) 1
127.0.0.1:6379> setnx lock 123
(integer) 0
127.0.0.1:6379> set lock 123
OK
项目推荐:基于SpringBoot2.x、SpringCloud和SpringCloudAlibaba企业级系统架构底层框架封装,解决业务开发时常见的非功能性需求,防止重复造轮子,方便业务快速开发和企业技术栈框架统一管理。引入组件化的思想实现高内聚低耦合并且高度可配置化,做到可插拔。严格控制包依赖和统一版本管理,做到最少化依赖。注重代码规范和注释,非常适合个人学习和企业使用
Github地址:https://github.com/plasticene/plasticene-boot-starter-parent
Gitee地址:https://gitee.com/plasticene3/plasticene-boot-starter-parent
微信公众号:Shepherd进阶笔记
交流探讨qun:Shepherd_126
2.2 list(列表)
Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n),这点让人非常意外。
当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
Redis 的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。
Redis 底层存储的还不是一个简单的 linkedlist,而是称之为快速链表 quicklist 的一个结构。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间,而且会加重内存的碎片化。比如这个列表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next 。所以 Redis 将链表和 ziplist 结合起来组成了 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
list常用指令
127.0.0.1:6379> lpush books java # 左侧插入元素
(integer) 1
127.0.0.1:6379> lpush books python c++ # 左侧批量插入
(integer) 3
127.0.0.1:6379> lrange books 0 -1 # 查看list中元素,-1代表查看所有
1) "c++"
2) "python"
3) "java"
127.0.0.1:6379> rpush books golang # 右侧插入元素
(integer) 4
127.0.0.1:6379> lrange books 0 -1
1) "c++"
2) "python"
3) "java"
4) "golang"
127.0.0.1:6379> lpop books # 左侧删除元素
"c++"
127.0.0.1:6379> lpush books java
(integer) 4
127.0.0.1:6379> lrange books 0 -1
1) "java"
2) "python"
3) "java"
4) "golang"
127.0.0.1:6379> lrem books 1 java # 移除books集合中指定个数的value,精确匹配
(integer) 1
127.0.0.1:6379> lrange books 0 -1
1) "python"
2) "java"
3) "golang"
127.0.0.1:6379> rpush books c#
(integer) 4
127.0.0.1:6379> lrange books 0 -1
1) "python"
2) "java"
3) "golang"
4) "c#"
127.0.0.1:6379> lrange books 1 2 # 显示部分元素
1) "java"
2) "golang"
127.0.0.1:6379> llen books # 集合长度
(integer) 4
127.0.0.1:6379> ltrim books 1 2 # 截取子集合
OK
127.0.0.1:6379> lrange books 0 -1
1) "java"
2) "golang"
127.0.0.1:6379> lindex books 1 # 根据位置index获取元素
"golang"
127.0.0.1:6379> exists books # 判断key是否存在
(integer) 1
2.3 hash(字典)
Redis 的hash相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同 Java 的 HashMap 也是一致的,同样的数组 + 链表二维结结构。
当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。
hash 结构也可以用来存储用户信息,不同于字符串一次性需要全部序列化整个对象,hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话就只能一次性全部读取,这样就会比较浪费网络流量。
hash 也有缺点,hash 结构的存储消耗要高于单个字符。
hash常用指令如下:
127.0.0.1:6379> hset user:1 id 1 # 设置key为user:1的map
(integer) 1
127.0.0.1:6379> hset user:1 name xiaoming
(integer) 1
127.0.0.1:6379> hset user:1 age 20
(integer) 1
127.0.0.1:6379> hset user:1 address 杭州市余杭区
(integer) 1
127.0.0.1:6379> hmset user:1 email shepherd_zfj@163.com phone 12345678 # 批量设置
OK
127.0.0.1:6379> hget user:1 email # 获取key下面某个字段值
"shepherd_zfj@163.com"
127.0.0.1:6379> hgetall user:1 # 获取所以值,o(n),性能差
1) "id"
2) "1"
3) "name"
4) "xiaoming"
5) "age"
6) "20"
7) "address"
8) "\xe6\x9d\xad\xe5\xb7\x9e\xe5\xb8\x82\xe4\xbd\x99\xe6\x9d\xad\xe5\x8c\xba"
9) "email"
10) "shepherd_zfj@163.com"
11) "phone"
12) "12345678"
127.0.0.1:6379> hincrby user:1 age 5 # 操作某个字段
(integer) 25
127.0.0.1:6379> hexists user:1 name # 判断某个字段是否存
(integer) 1
127.0.0.1:6379> hlen user:1 # 获取长度
(integer) 6
127.0.0.1:6379> hsetnx user:1 age 0
(integer) 0
127.0.0.1:6379> hkeys user:1
1) "id"
2) "name"
3) "age"
4) "address"
5) "email"
6) "phone"
127.0.0.1:6379> hvals user:1
1) "1"
2) "xiaoming"
3) "25"
4) "\xe6\x9d\xad\xe5\xb7\x9e\xe5\xb8\x82\xe4\xbd\x99\xe6\x9d\xad\xe5\x8c\xba"
5) "shepherd_zfj@163.com"
6) "12345678"
127.0.0.1:6379>
2.4 set(集合)
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。
当集合中最后一个元素移除之后,数据结构自动删除,内存被回收。 set 结构可以用来存储活动中奖的用户 ID,因为有去重功能,可以保证同一个用户不会中奖两次。还有很有用场景就是集合交并集、差集等,可以给出共同好友,推荐好友啥的。。。
set的常用指令
127.0.0.1:6379> sadd set1 a b c d # 批量添加元素
(integer) 4
127.0.0.1:6379> smembers set1 # 遍历集合元素 o(n)
1) "d"
2) "c"
3) "a"
4) "b"
127.0.0.1:6379> sismember set1 b # 判断当前元素是否存在
(integer) 1
127.0.0.1:6379> scard set1 # 集合长度
(integer) 4
127.0.0.1:6379> srandmember set1 2 # 随机取2个元素
1) "c"
2) "d"
127.0.0.1:6379> srandmember set1 2
1) "c"
2) "b"
127.0.0.1:6379> sadd set2 b c e f
(integer) 4
127.0.0.1:6379> sdiff set1 set2 # 取差集
1) "d"
2) "a"
127.0.0.1:6379> sinter set1 set2 # 取交集
1) "c"
2) "b"
127.0.0.1:6379> sunion set1 set2 # 取并集
1) "f"
2) "b"
3) "d"
4) "c"
5) "e"
6) "a"
127.0.0.1:6379>
2.5 Zset(有序集合)
zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结构。它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫着「跳跃列表」的数据结构。
zset 中最后一个 value 被移除后,数据结构自动删除,内存被回收。 zset 可以用来存粉丝列表,value 值是粉丝的用户 ID,score 是关注时间。我们可以对粉丝列表按关注时间进行排序。
zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们可以对成绩按分数进行排序就可以得到他的名次
zset的常用指令
127.0.0.1:6379> zadd myzset 99 java # 添加权重和元素值
(integer) 1
127.0.0.1:6379> zadd myzset 90 python
(integer) 1
127.0.0.1:6379> zadd myzset 95 c++
(integer) 1
127.0.0.1:6379> zadd myzset 100 golang
(integer) 1
127.0.0.1:6379> zadd myzset 85 c#
(integer) 1
127.0.0.1:6379> zrange myzset 0 -1 # 遍历集合 权重正序
1) "c#"
2) "python"
3) "c++"
4) "java"
5) "golang"
127.0.0.1:6379> zrange myzset 0 2
1) "c#"
2) "python"
3) "c++"
127.0.0.1:6379> zrevrange myzset 0 -1 # 遍历集合 权重降序
1) "golang"
2) "java"
3) "c++"
4) "python"
5) "c#"
127.0.0.1:6379> zrangebyscore myzset 90 100 #根据分数查询元素区间
1) "python"
2) "c++"
3) "java"
4) "golang"
127.0.0.1:6379> zrangebyscore myzset 99 inf
1) "java"
2) "golang"
127.0.0.1:6379> zrank myzset java # 元素排名
(integer) 3
127.0.0.1:6379> zrank myzset golang
(integer) 4
127.0.0.1:6379> zcard myzset # 集合长度
(integer) 5
3.redis高级数据结构
3.1GeoHash
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着我们可以使用 Redis 来实现摩拜单车「附近的 Mobike」、美团和饿了么「附近的餐馆」这样的功能。
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用 Redis 的 Geo 数据结构,它们将全部放在一个 zset 集合中。在 Redis 的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成较大的影响,在集群环境中单个 key 对应的数据量不宜超过 1M,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。
所以,这里建议 Geo 的数据使用单独的 Redis 实例部署,不使用集群环境。
如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个 zset 集合的大小
geo的常用指令:
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing # geoadd添加位置数据
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqi 114.05 22.52 shengzhen
(integer) 2
127.0.0.1:6379> geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 2
127.0.0.1:6379> GEOPOS china:city beijing # 获取北京的经纬度
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> GEODIST china:city beijing shanghai km # 获取北京到上海的距离,单位km
"1067.3788"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord withdist withhash # 以(110,30)为中心500km一类的城市
1) 1) "chongqi"
2) "341.9374"
3) (integer) 4026042091628984
4) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) "483.8340"
3) (integer) 4040115445396757
4) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> georadiusbymember china:city shanghai 3000 km # 获取指定元素的周围元素
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379> georadiusbymember china:city shanghai 300 km
1) "hangzhou"
2) "shanghai"
127.0.0.1:6379> ZRANGE china:city 0 -1 # geohash底层是使用zset实现的,所以可以使用zset的指令操作
1) "chongqi"
2) "xian"
3) "shengzhen"
4) "hangzhou"
5) "shanghai"
6) "beijing"
127.0.0.1:6379>
3.2 Bitmap(位图)
在我们平时开发过程中,会有一些 bool 型数据需要存取,比如用户一年的签到记录,签了是 1,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365 个,当用户上亿的时候,需要的存储空间是惊人的。
为了解决这个问题,Redis 提供了位图数据结构,这样每天的签到记录只占据一个位,365 天就是 365 个位,46 个字节 (一个稍长一点的字符串) 就可以完全容纳下,这就大大节约了存储空间。
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit 等将 byte 数组看成「位数组」来处理。
bitmap常用指令:
127.0.0.1:6379> setbit s 1 1 # h的二进制:0b1101000 e的二进制:0b1100101
(integer) 0
127.0.0.1:6379> setbit s 2 1
(integer) 0
127.0.0.1:6379> setbit s 4 1
(integer) 0
127.0.0.1:6379> setbit s 9 1
(integer) 0
127.0.0.1:6379> setbit s 10 1
(integer) 0
127.0.0.1:6379> setbit s 13 1
(integer) 0
127.0.0.1:6379> setbit s 15 1
(integer) 0
127.0.0.1:6379> get s
"he"
127.0.0.1:6379> getbit s 4
(integer) 1
127.0.0.1:6379> getbit s 5
(integer) 0
127.0.0.1:6379> bitcount 1
(integer) 0
127.0.0.1:6379> bitcount s
(integer) 7
127.0.0.1:6379> bitcount s 0 3
(integer) 7
127.0.0.1:6379> bitpos s 1
(integer) 1
127.0.0.1:6379> bitpos s 1 4 10
(integer) -1
127.0.0.1:6379> bitpos s 1 4 8
(integer) -1
127.0.0.1:6379> set w hello
OK
127.0.0.1:6379> bitcount w
(integer) 21
127.0.0.1:6379> bitcount w 0 0
(integer) 3
127.0.0.1:6379> bitcount w 0 1
(integer) 7
127.0.0.1:6379> bitpos w 1
(integer) 1
127.0.0.1:6379> bitpos w 1 1 1
(integer) 9
127.0.0.1:6379>
3.3 Hyperloglog
统计网站每个网页每天的 UV 数据,你会如何实现?
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
你也许已经想到了一个简单的方案,那就是为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。没错,这是一个非常简单的方案。
但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值得么?其实老板需要的数据又不需要太精确,105w 和 106w 这两个数字对于老板们来说并没有多大区别,So,有没有更好的解决方案呢?
这就是本节要引入的一个解决方案,Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。
Hyperloglog常用指令:
127.0.0.1:6379> pfadd hylog 1 2 3 4 5 6 # 添加元素
(integer) 1
127.0.0.1:6379> pfcount hylog # 统计
(integer) 6
127.0.0.1:6379> pfadd hylog1 5 6 7 8 9 10
(integer) 1
127.0.0.1:6379> pfadd hylog1 9 10 # 添加重复元素,不成功
(integer) 0
127.0.0.1:6379> pfcount hylog1
(integer) 6
127.0.0.1:6379> pfmerge hylog2 hylog hylog1 # 合并
OK
127.0.0.1:6379> pfcount hylog2
(integer) 10
127.0.0.1:6379>
Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间,最大固定内存长度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!