【Animatable 3D Gaussian】3D高斯最新工作,25s重建十人, 炸裂

1. 资料
2. 论文
2.1 摘要
神经辐射场能够重建高质量的可驱动人类化身,但训练和渲染成本很高。为减少消耗,本文提出可动画化的3D高斯,从输入图像和姿势中学习人类化身。我们通过在正则空间中建模一组蒙皮的3D高斯模型和相应的骨架,并根据输入姿态将3D高斯模型变形到姿态空间,将3D高斯[1]扩展到动态人类场景。本文引入哈希编码的形状和外观来加快训练,并提出与时间相关的环境光遮蔽,以在包含复杂运动和动态阴影的场景中实现高质量重建。在新视图合成和新姿态合成任务中,所提出方法在训练时间、渲染速度和重建质量方面都优于现有方法。所提出方法可以很容易地扩展到多人类场景,并在25秒训练时间内实现十人场景的高质量的新视图合成结果。
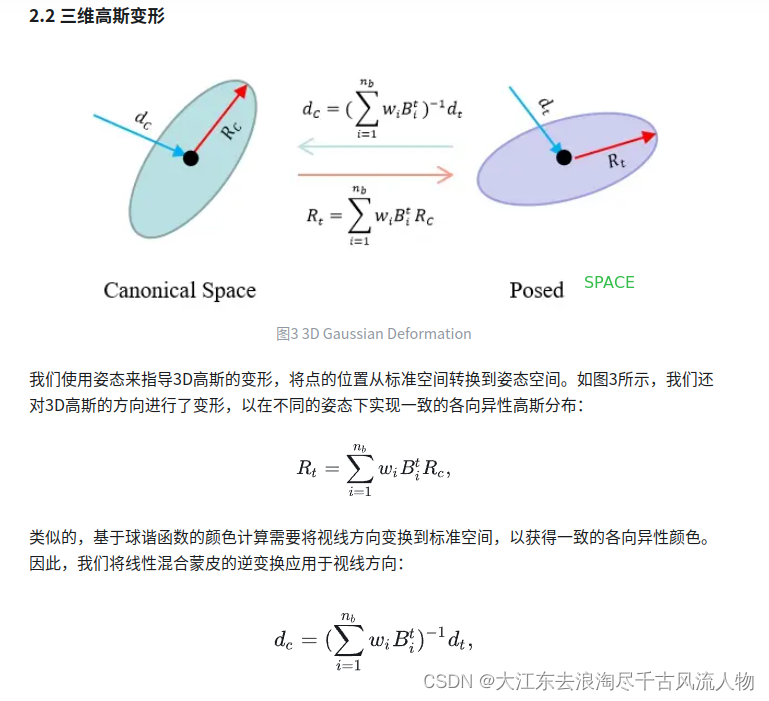
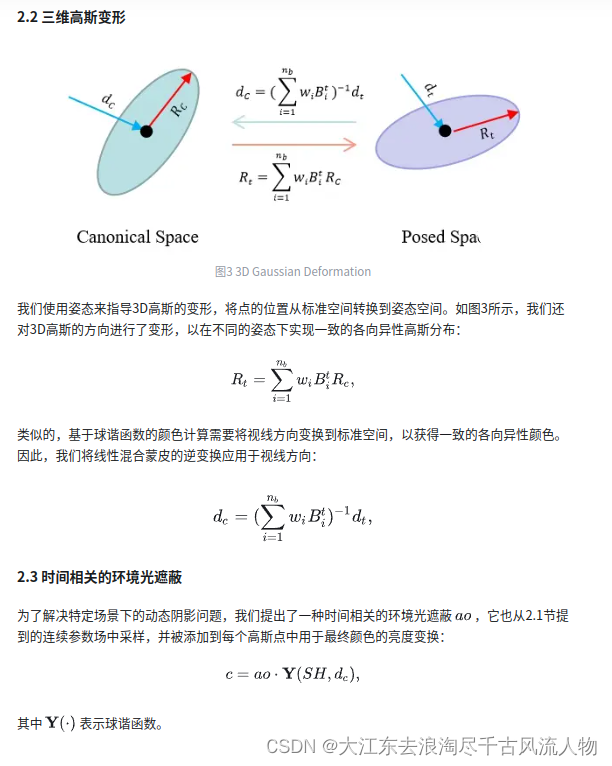
2.2 Method
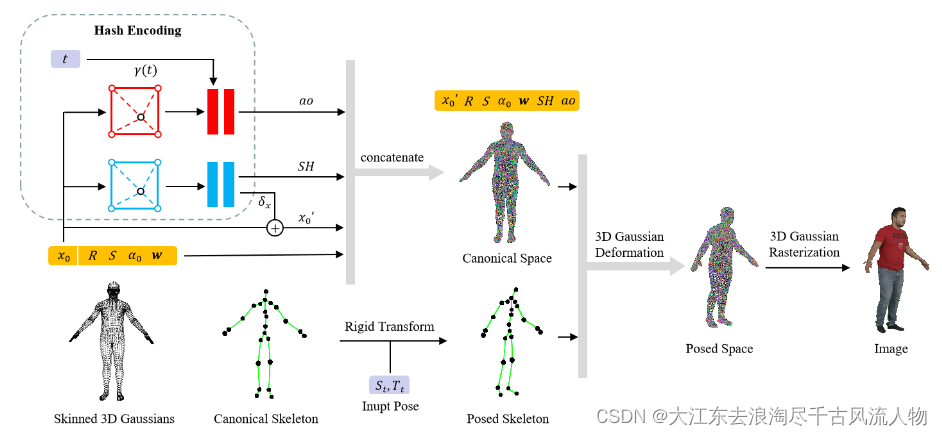
The proposed animatable 3D Gaussian consists of a set of skinned 3D Gaussians and a corresponding canonical skeleton. Each skinned 3D Gaussian contains center x0, rotation R, scale S, opacity α0, and skinning weights w. First, we sample spherical harmonic coefficients SH, vertex displacement δx, and ambient occlusion ao from the hash-encoded parameter field according to the center x0, where the multilayer perceptron for ao requires an additional frequency encoded time γ(t) as input. Next, we concatenate the sampled parameters, the original parameters, and a shifted center x0’ in canonical space. Finally, we deform 3D Gaussians to the posed space according to the input pose St,Tt and render them to the image using 3D Gaussian rasterization.


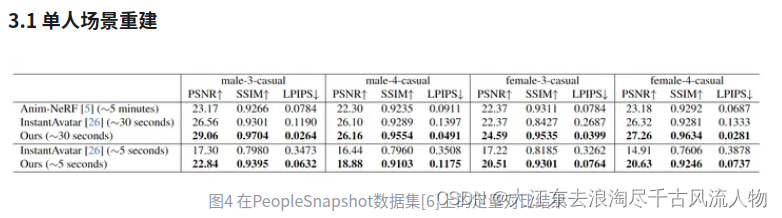
3 Result (Training)
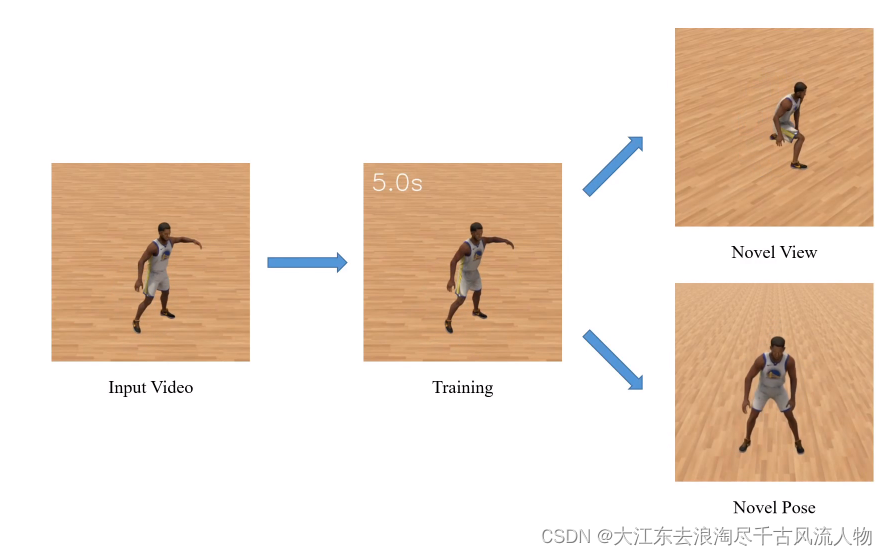
3.2 Multi-Human Scene

4. 小结
我们提出了一种新的人体重建方法,能够在数秒内重建高质量可驱动人体。与最新的方法比较,我们的方法能够在更短的时间内实现更高的重建质量。并且我们的方法能够扩展到多人场景,实现复杂场景下的快速自由视角视频合成。
5. 参考文献
[1] Kerbl, B., Kopanas, G., Leimkühler, T., & Drettakis, G. (2023). 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (ToG),42(4), 1-14.
[2] Müller, T., Evans, A., Schied, C., & Keller, A. (2022). Instant neural graphics primitives with a multiresolution hash encoding.ACM Transactions on Graphics (ToG),41(4), 1-15.
[3] Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., & Black, M. J. (2023). SMPL: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2(pp. 851-866).
[4] Jiang, T., Chen, X., Song, J., & Hilliges, O. (2023). Instantavatar: Learning avatars from monocular video in 60 seconds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 16922-16932).
[5] Chen, J., Zhang, Y., Kang, D., Zhe, X., Bao, L., Jia, X., & Lu, H. (2021). Animatable neural radiance fields from monocular rgb videos.arXiv preprint arXiv:2106.13629.
[6] Alldieck, T., Magnor, M., Xu, W., Theobalt, C., & Pons-Moll, G. (2018, September). Detailed human avatars from monocular video. In2018 International Conference on 3D Vision (3DV)(pp. 98-109). IEEE.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- UG阵列-数字递增
- Java项目:165SpringBoot的手机商城系统
- FlinkSQL
- C++中,左值引用和右值引用的区别
- 数模学习day01-层次分析法模型
- 2.4G水墨屏电子标签|RFID电子纸基站CK-RTLS0501G_VT硬件功能与联机方法
- jmeter+ant+jenkins接口自动化测试框架
- C程序训练:两个数组按规则结合形成一个集合
- SpringBoot测试类提示没有发现测试(JUnit4和JUnit5注解)
- 在vue中使用高德地图点击打点,搜索打点,高德地图组件封装