图像分类】【深度学习】【轻量级网络】【Pytorch版本】EfficientNet_V2模型算法详解
【图像分类】【深度学习】【轻量级网络】【Pytorch版本】EfficientNet_V2模型算法详解
文章目录
前言
EfficientNet_V2是由谷歌公司的Tan, Mingxing等人《EfficientNetV2: Smaller Models and Faster Training【 ICML-2021】》【论文地址】一文中提出的改进模型,在EfficientNet_V1的基础上,引入渐进式学习策略、自适应正则强度调整机制使得训练更快,进一步关注模型的推理速度与训练速度。
EfficientNet_V2讲解
随着模型规模和训练数据规模越来越大,训练效率对于深度学习非常重要。NFNets旨在通过去除昂贵的批量归一化来提高训练效率;Lambda Networks和BotNet侧重于通过在卷积网络上使用注意层来提高训练速度;ResNet-RS优化尺度超参数提高训练效率;Vision Transformers通过使用Transformer块提高大规模数据集的训练效率。
原论文中给出了各网络模型与EfficientNet_V2在参数、性能等领域的对比示意图。EfficientNetV2网络不仅精度达到了当前的最优水平,而且训练速度更快以及参数数量更少。

EfficientNet_V1关注的是准确率,参数数量以及FLOPs,但是理论计算量小不代表推理速度快,因此EfficientNet_V2进一步关注模型的训练速度。
简单回顾一下EfficientNet_V1【参考】,它是一系列针对FLOPs和参数效率进行优化的模型,首先利用NAS搜索基线EfficientNet-B0,该基线在准确性和FLOPs方面具有更好的权衡,然后使用复合缩放策略扩展基线模型,以获得模型B1-B7族。
论文系统性的研究了EfficientNet_V1的训练过程,并总结EfficientNet_V1中存在的三个问题:
-
训练图像的尺寸很大时,训练速度非常慢: EfficientNet_V1在大图像尺寸训练时导致了大量的内存占用,由于GPU/TPU上的总内存是固定的,必须用较小的batch来训练这些模型,这大大降低了训练速度。论文给出的下表数据显示,较小的图像尺寸会导致较少的计算,并能实现大批量的计算,从而提高训练速度。因此提供了一种更先进的训练方法(自适应正则化的渐进学习),在训练中逐步调整图像大小和正则化。

“imgs/sec/core” 表示每秒每个处理核心能够处理的图像数量。
-
深度卷积在早期阶段较慢,但在后期阶段有效: 深度卷积相比于普通卷积有参数更少、FLOPs更低,但深度卷积往往不能充分利用现代加速器。为了更好地利用移动或服务器加速器,EfficientNet_V2在Fused-MBConv中用一个普通的3x3卷积取代了EfficientNet_V1在MBConv中的1×1膨胀卷积和3×3深度卷积。

为了系统地比较这两个构件,论文逐步用FusedMBConv替换的原始MBConv。当应用于早期1-3阶段时,FusedMBConv可以提高训练速度,但对参数和FLOPs的开销很小,但在第1-7阶段用Fused-MBConv取代所有的模块,那么就会大大增加参数和FLOPs,同时也降低了训练速度。
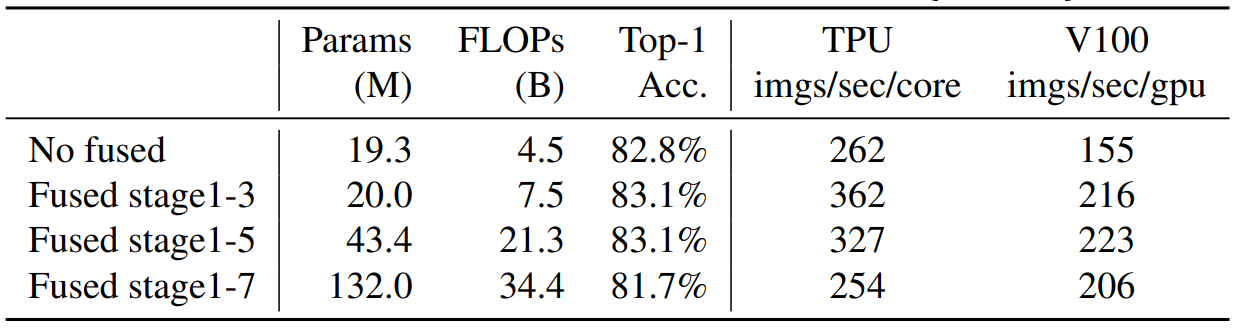
找到MBConv和Fused-MBConv这两个构件的正确组合是不容易的,论文利用神经结构搜索来自动搜索最佳组合。
-
使用一个简单的复合缩放规则对所有阶段进行平均缩放: 在 EfficientNet_V1中每个阶段(stage )的深度和宽度都是同等放大的,只需要直接简单粗暴的乘上宽度和深度缩放因子,但是每个阶段对于网络的训练速度,参数量等贡献并不相同;EfficientNet_V1采用大尺寸图像导致大计算量、训练速度降低问题。在论文中将使用非均匀缩放策略对后面阶段逐步增加更多的网络层,对缩放规则进行了略微调整将最大图像尺寸限制在一个较小的数值。
神经网络架构搜索的技术路线参考:

自适应正则化的渐进学习(Progressive Learning with adaptive Regularization)
图像大小对训练效率起着重要的作用,因此许多模型在训练期间动态改变图像大小,但通常导致准确性下降。论文中假设准确率的下降来自于不平衡的正则化: 当用不同的图像尺寸进行训练时应该相应地调整正则化强度,而不是像以前那样使用固定的正则化。事实上,大模型需要更强的正则化来对抗过拟合。论文提出,即使对于相同的网络,较小的图像大小也会导致较小的网络容量,因此需要较弱的正则化;反之亦然,图像尺寸越大,计算量越大,越容易过度拟合。
深度学习网络容量是指一个深度学习模型所能够表示或学习的函数的复杂度或丰富程度。它反映了模型在处理和学习复杂问题时的表达能力。
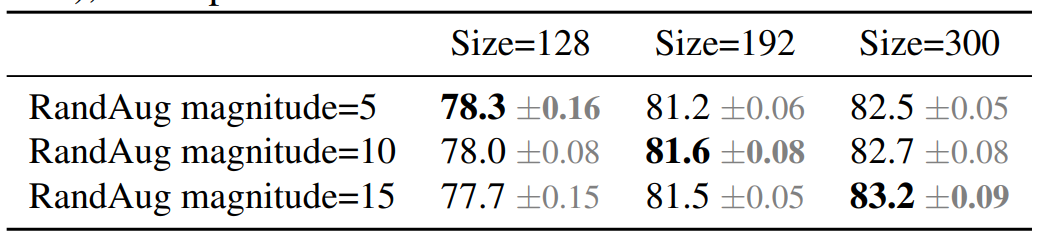
为了验证论文中的假设,如下表所示,从搜索空间取样训练了一个模型,用不同的图像大小和数据增强。当图像尺寸较小时,它在使用弱数据增强时具有最好的准确性;但对于较大的图像,它在使用较强数据增强时表现更好。这一实验结果促使作者在训练过程中随着图像大小自适应地调整正则化,从而引导作者改进的渐进式学习方法。
下图展示了论文中改进渐进学习的训练过程:在训练早期使用较小的图像和弱正则化来训练网络,使网络快速学习简单的表示,然后逐渐增加图像的大小,同时增强的正则化,以增加学习难度。

正则化的目标是在保持模型对训练数据的拟合能力的同时,降低模型的复杂度,使其更具有泛化能力,即在未见过的数据上表现良好。
数据增强(Data Augmentation)也是常见的正则化方法:数据增强是通过对训练数据进行随机变换来扩充数据集的方法。这样可以引入一定的随机性和多样性,使模型能够更好地适应不同的变化和噪声,从而减少过拟合的风险。
论文将渐进式学习策略抽象成了一个公式来设置不同训练阶段使用的训练尺寸以及正则化强度。

注:上表中 N N N表示总训练次数, M M M表示图片尺寸以及正则化强度变化的几个阶段, N M \frac{N}{M} MN?表示每个阶段的训练次数;
S 0 S_0 S0?表示初始阶段的图片的大小, S e S_e Se?表示最终阶段的图片大小, S i S_i Si?表示第 i i i阶段的图片大小;
Φ i = { ? i k } {\Phi _i} = \left\{ {\phi _i^k} \right\} Φi?={?ik?}表示第 i i i阶段的正则化强度, k k k表示正则化的类型, Φ 0 {\Phi _0} Φ0?表示初始阶段的正则化强度, Φ e {\Phi _e} Φe?表示最终阶段的正则化强度。
i M ? 1 \frac{i}{{M - 1}} M?1i?表示图片尺寸以及正则化强度变化是等差增长的。
论文中改进的渐进式学习与现有的正则化普遍兼容,主要研究以下三种类型的正则化:
- Dropout(dropout rate γ γ γ): 一种常用的正则化技术,在前向传播过程中,每个神经元都有一定的概率被丢弃,通过随机丢弃(置零)网络中的一些神经元的输出来实现,用于减少深度神经网络的过拟合。
- RandAugment(magnitude ? ? ?): 核心思想是对一组预定义的图像在一定范围内随机选择和组合一些变换操作,包括旋转、缩放、裁剪、翻转、变亮、变暗、变色等,可以生成多样化的图像,从而扩展原始数据集来增强输入图像。
- Mixup(mixup ratio λ λ λ): 一种广泛应用的数据增强技术,通过线性插值的方式将不同样本的特征和标签进行混合,生成新的训练样本,旨在改善深度学习模型的泛化能力和鲁棒性。给定两张具有标签的图像 ( x i , y i ) \left( {{{\rm{x}}_i},{y_i}}\right) (xi?,yi?)和 ( x j , y j ) \left( {{{\rm{x}}_j},{y_j}}\right) (xj?,yj?)的图像,以混合比例将它们结合起来 ( x ~ , y ~ ) \left( {\mathop x\limits^ \sim ,\mathop y\limits^ \sim } \right) (x~,y~?): x ~ = λ x j + ( 1 ? λ ) x i \mathop x\limits^ \sim = \lambda {{\rm{x}}_j} + \left( {1 - \lambda } \right){{\rm{x}}_i} x~=λxj?+(1?λ)xi?, y ~ = λ y j + ( 1 ? λ ) y i \mathop y\limits^ \sim = \lambda {{\rm{y}}_j} + \left( {1 - \lambda } \right){{\rm{y}}_i} y~?=λyj?+(1?λ)yi?。
EfficientNet_V2的模型结构
下表展示了原论文中使用NAS搜索得到的EfficientNet_V2-S模型框架。
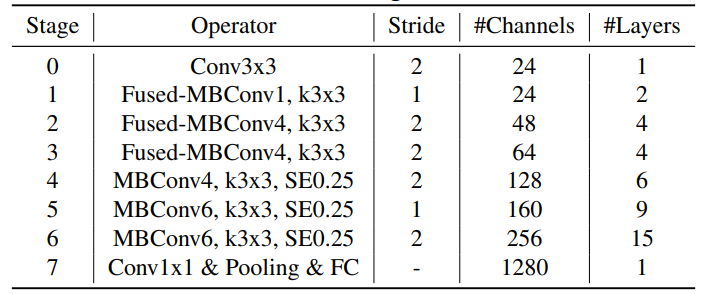
相比与EfficientNet_V1,主要有以下四点不同:
- 除了使用 MBConv之外,在网络浅层使用了Fused-MBConv模块,加快训练速度与提升性能;
- 使用较小的expansion ratio(从V1版本的6减小到4),从而减少内存的访问量;
- 偏向使用更小的3×3卷积核(V1版本存在很多5×5),并堆叠更多的层结构以增加感受野;
- 移除步长为1的最后一个阶段(V1版本中stage8),因为它的参数数量过多,需要减少部分参数和内存访问。
以下内容是原论文中没有的补充内容,关于EfficientNet_V2结构的更细节描述。
SE模块(Squeeze Excitation)
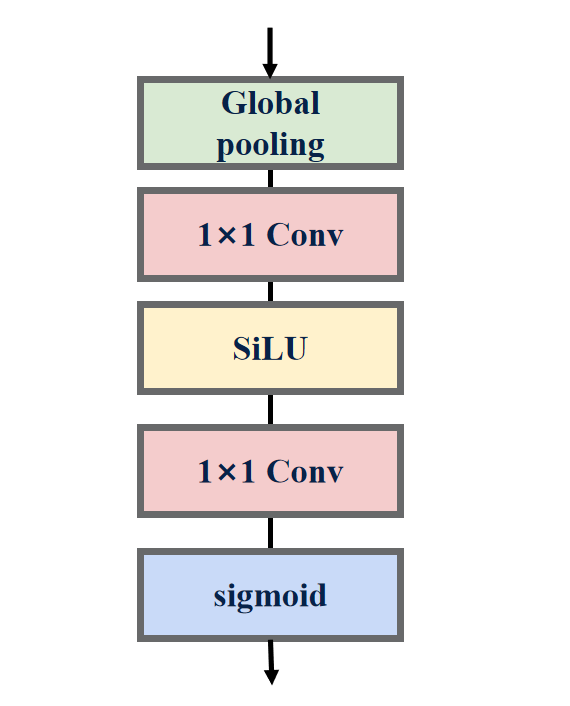
对所通道输出的特征图进行加权: SE模块显式地建立特征通道之间的相互依赖关系,通过学习能够计算出每个通道的重要程度,然后依照重要程度对各个通道上的特征进行加权,从而突出重要特征,抑制不重要的特征。

- 压缩(squeeze): 由于卷积只是在局部空间内进行操作,很难获得全局的信息发现通道之间的关系特征,因此采用全局平局池化将每个通道上的空间特征编码压缩为一个全局特征完成特征信息的进行融合。
- 激励(excitation): 接收每个通道的全局特征后,采用俩个全连接层预测每个通道的重要性(激励)。为了降低计算量,第一个全连接层带有缩放超参数起到减少通道、降低维度的作用;第二个全连接层则恢复原始维度,以保证通道的重要性与通道的特征图数量完全匹配。
- 加权(scale): 计算出通道的重要性后,下一步对通道的原始特征图进行加权操作,各通道权重分别和对应通道的原始特征图相乘获得新的加权特征图。
EfficientNet_V2中的SE模块:
反向残差结构 MBConv
ResNet【参考】中证明残差结构(Residuals) 有助于构建更深的网络从而提高精度,MobileNets_V2【参考】中以ResNet的残差结构为基础进行优化,提出了反向残差(Inverted Residuals) 的概念。
反向残差结构MBConv的过程: 低维输入->1x1膨胀卷积(升维)-> bn层+swish激活->3x3深度卷积(低维)->bn层+swish激活->1x1点卷积(降维)->bn层->与残差相加。
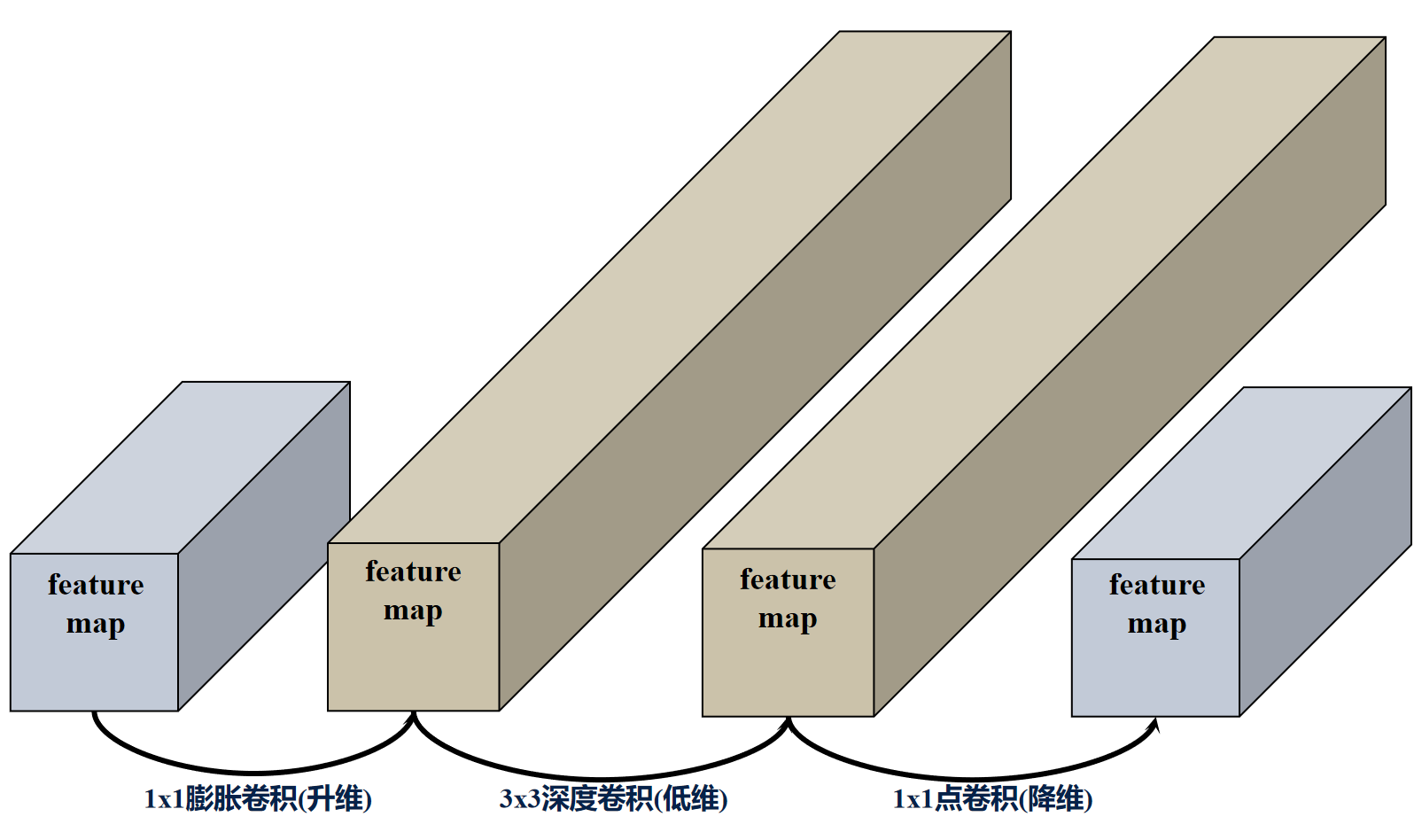
EfficientNet_V2的反向残差结构MBConv分为俩种,当stride=2时,反向残差结构取消了shortcut连接和drop_connect。
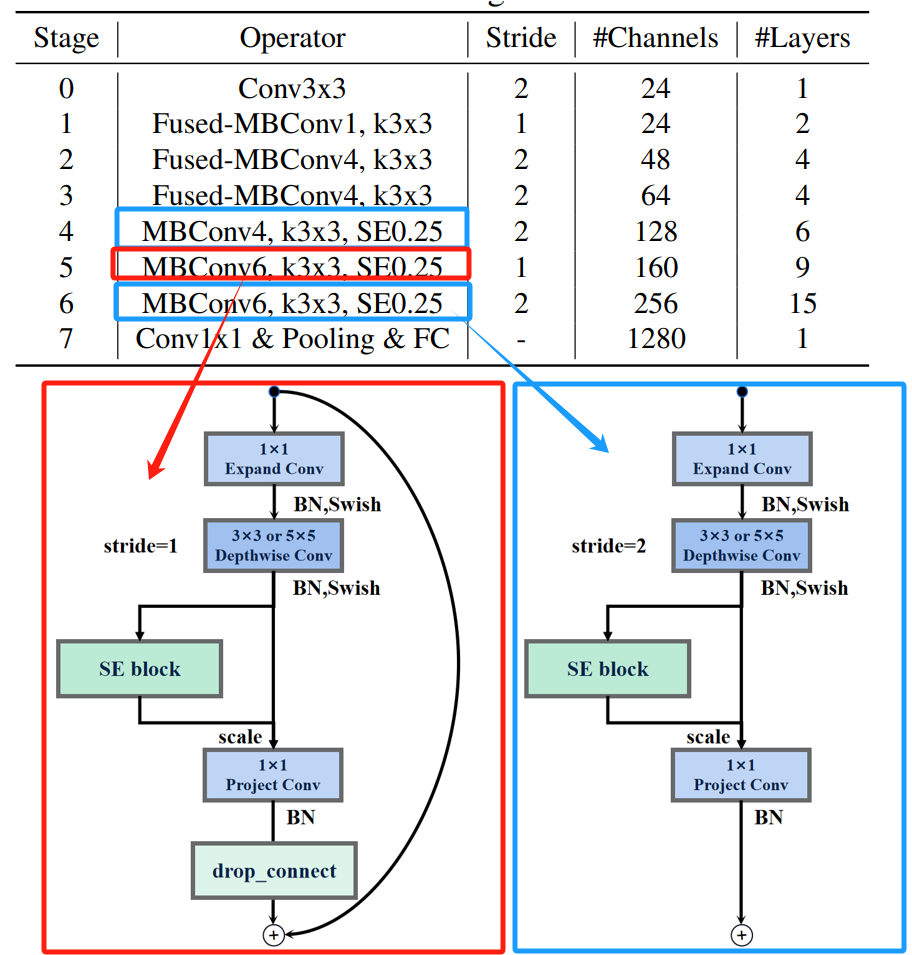
这里的stride=2只是当前stage的首个MBConv,而不是整个stage的所有MBConv
不同于EfficientNet_V1【参考】,EfficientNet_V2没有特殊的反向残差结构MBConv。
EfficientNet_V2沿用EfficientNet_V1使用的swish激活函数,即x乘上sigmoid激活函数:
s
w
i
s
h
(
x
)
=
x
σ
(
x
)
{\rm{swish}}(x) = x\sigma (x)
swish(x)=xσ(x)
其中sigmoid激活函数:
σ
(
x
)
=
1
1
+
e
?
x
\sigma (x) = \frac{1}{{1 + {e^{ - x}}}}
σ(x)=1+e?x1?
反向残差结构 FusedMBConv
反向残差结构FusedMBConv的过程: 低维输入->3x3膨胀卷积(升维)-> bn层+swish激活->1x1点卷积->bn层+swish激活->与残差相加。
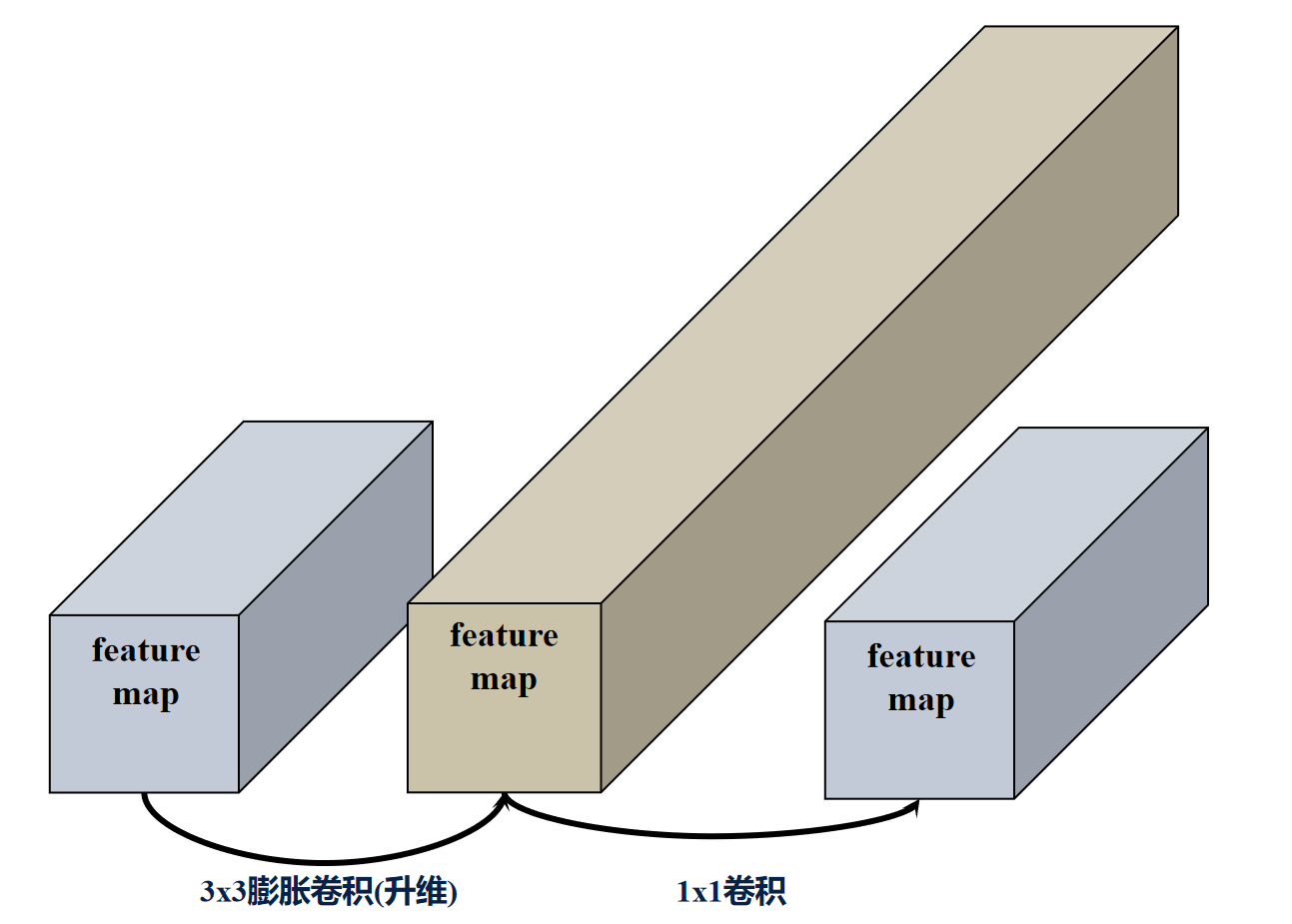
EfficientNet_V2的反向残差结构FusedMBConv也分为俩种,当stride=2时,反向残差结构取消了shortcut连接和drop_connect。
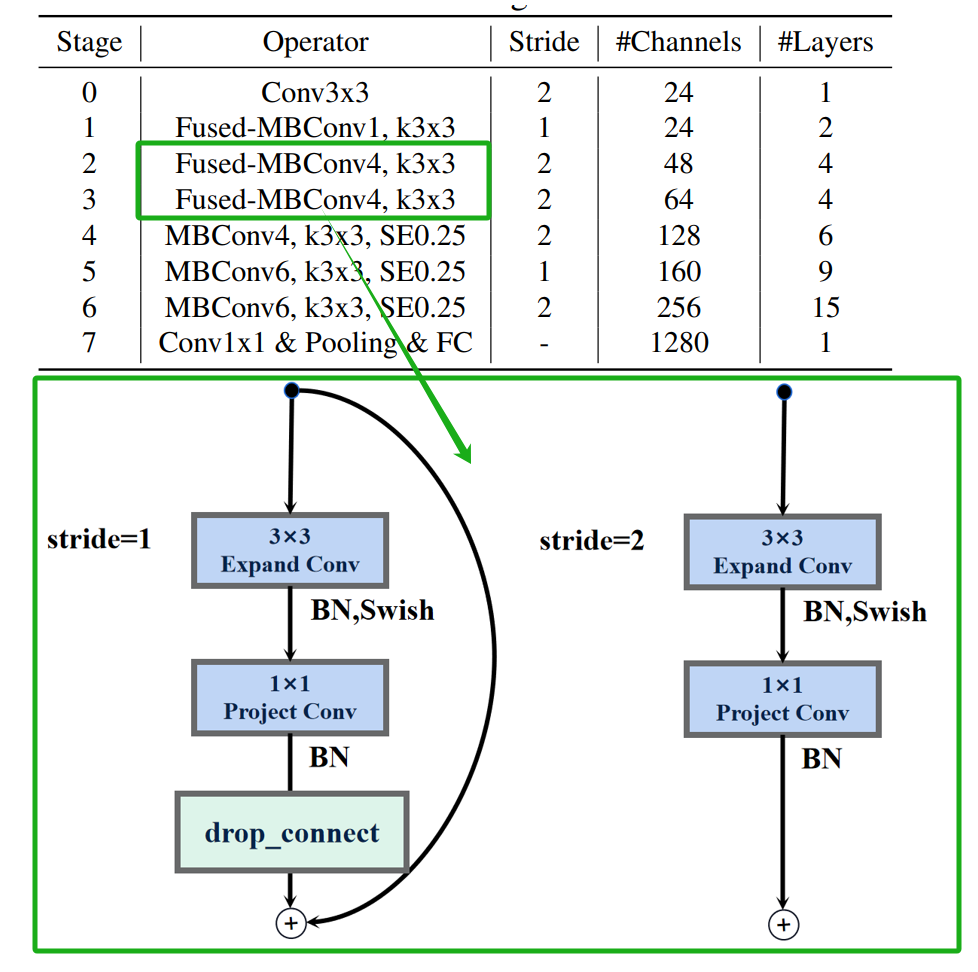
EfficientNet_V2还有一个特殊的反向残差结构,它没有用于升维的膨胀卷积。
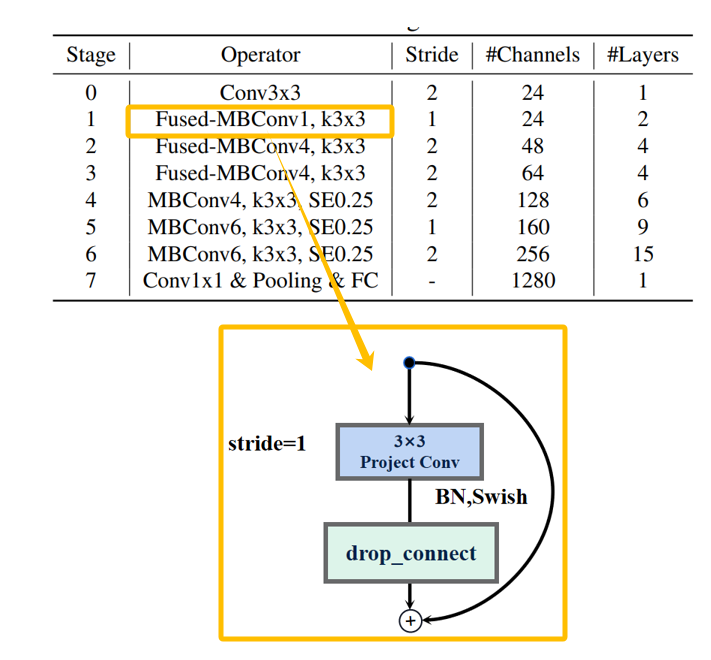
反向残差结构组 Stage
EfficientNet_V2由多个反向残差结构组构成,除了stride的细微差异,每个反向残差结构组具有相同的网络结构,以下是EfficientNet_V2-S模型参数以及对应的网络结构图。

EfficientNet_V2 Pytorch代码
卷积块: 3×3/5×5卷积层+BN层+Swish激活函数(可选)
# 卷积块:3×3/5×5卷积层+BN层+Swish激活函数(可选)
class ConvBNAct(nn.Sequential):
def __init__(self,
in_planes, # 输入通道
out_planes, # 输出通道
kernel_size=3, # 卷积核大小
stride=1, # 卷积核步长
groups=1, # 卷积层组数
norm_layer=None, # 归一化层
activation_layer=None): # 激活层
super(ConvBNAct, self).__init__()
# 计算padding
padding = (kernel_size - 1) // 2
# BN层
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# Swish激活函数
if activation_layer is None:
# nn.SiLU 等价于 x * torch.sigmoid(x)
activation_layer = nn.SiLU
super(ConvBNAct, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())
SE注意力模块:: 全局平均池化+1×1卷积+Swish激活函数+1×1卷积+sigmoid激活函数
# SE注意力模块:对各通道的特征分别强化
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c, # 1×1卷积输出通道数(降维)
expand_c, # se模块整体输入输出通道
se_ratio=0.25): # 降维系数
super(SqueezeExcitation, self).__init__()
# 降维通道数=降维卷积输出通道数*降维系数
squeeze_c = int(input_c * se_ratio)
# 1×1卷积(降维)
self.fc1 = nn.Conv2d(expand_c, squeeze_c, 1)
# Swish激活函数
self.ac1 = nn.SiLU()
# 1×1卷积(特征提取)
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1)
# Sigmoid激活函数(0~1重要性加权)
self.ac2 = nn.Sigmoid()
def forward(self, x):
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
# 特征按通道分别进行加权
return scale * x
反向残差结构MBConv: 1×1膨胀卷积层+BN层+Swish激活函数+3×3深度卷积层+BN层+Swish激活函数+1×1点卷积层+BN层
# 反残差结构:1×1膨胀卷积层+BN层+Swish激活函数+3×3深度卷积层+BN层+Swish激活函数+1×1点卷积层+BN层
class MBConvBlock(nn.Module):
def __init__(self,
kernel, # 卷积核大小 3
input_c, # 输入通道数
out_c, # 输出通道数
expand_ratio, # 膨胀系数 4 or 6
stride, # 卷积核步长
se_ratio, # 启用se注意力模块
drop_rate, # 通道随机失活率
norm_layer): # 归一化层
super(MBConvBlock, self).__init__()
# 膨胀通道数 = 输入通道数*膨胀系数
expanded_c = input_c * expand_ratio
# 步长必须是1或者2
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
# 深度卷积步长为2则没有shortcut连接
self.use_res_connect = (stride == 1 and input_c == out_c)
layers = OrderedDict()
# Swish激活函数
activation_layer = nn.SiLU # alias Swish
# 在EfficientNetV2中,MBConvBlock中不存在expansion=1的情况
assert expand_ratio != 1
# 1×1膨胀卷积(膨胀系数>1) 升维
layers.update({"expand_conv": ConvBNAct(input_c,
expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 3×3深度卷积
layers.update({"dwconv": ConvBNAct(expanded_c,
expanded_c,
kernel_size=kernel,
stride=stride,
groups=expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 启用se注意力模块
if se_ratio > 0:
layers.update({"se": SqueezeExcitation(input_c,
expanded_c,
se_ratio)})
# 1×1点卷积
layers.update({"project_conv": ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)})
self.block = nn.Sequential(layers)
# 只有在使用shortcut连接时才使用drop_connect层
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
else:
self.drop_connect = nn.Identity()
def forward(self, x):
result = self.block(x)
result = self.drop_connect(result)
# 反残差结构随机失活
if self.use_res_connect:
result += x
return result
反向残差结构FusedMBConv: 3×3膨胀积层+BN层+Swish激活函数+1×1点卷积层+BN层
# 反残差结构FusedMBConv:3×3膨胀卷积层+BN层+Swish激活函数+1×1点卷积层+BN层
class FusedMBConvBlock(nn.Module):
def __init__(self,
kernel, # 卷积核大小
input_c, # 输入通道数
out_c, # 输出通道数
expand_ratio, # 膨胀系数 1 or 4
stride, # 卷积核步长
se_ratio, # 启用se注意力模块
drop_rate, # 通道随机失活率
norm_layer): # 归一化层
super(FusedMBConvBlock, self).__init__()
# 膨胀通道数 = 输入通道数*膨胀系数
expanded_c = input_c * expand_ratio
# 步长必须是1或者2
assert stride in [1, 2]
# 没有se注意力模块
assert se_ratio == 0
# 深度卷积步长为2则没有shortcut连接
self.use_res_connect = stride == 1 and input_c == out_c
self.drop_rate = drop_rate
self.has_expansion = expand_ratio != 1
layers = OrderedDict()
# Swish激活函数
activation_layer = nn.SiLU
# 只有当expand ratio不等于1时才有膨胀卷积
if self.has_expansion:
# 3×3膨胀卷积(膨胀系数>1) 升维
layers.update({"expand_conv": ConvBNAct(input_c,
expanded_c,
kernel_size=kernel,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 1×1点卷积
layers.update({"project_conv": ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)}) # 注意没有激活函数
else:
# 当没有膨胀卷积时,3×3点卷积
layers.update({"project_conv": ConvBNAct(input_c,
out_c,
kernel_size=kernel,
norm_layer=norm_layer,
activation_layer=activation_layer)}) # 注意有激活函数
self.block = nn.Sequential(layers)
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
# 只有在使用shortcut连接时才使用drop_connect层
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
else:
self.drop_connect = nn.Identity()
def forward(self, x):
result = self.block(x)
result = self.drop_connect(result)
# 反残差结构随机失活
if self.use_res_connect:
result += x
return result
反残差结构随机失活
# 反残差结构随机失活:batchsize个样本随机失活,应用于反残差结构的主路径
class DropConnect(nn.Module):
def __init__(self, drop_prob=0.5):
super(DropConnect, self).__init__()
self.keep_prob = None
self.set_rate(drop_prob)
# 反残差结构的保留率
def set_rate(self, drop_prob):
if not 0 <= drop_prob < 1:
raise ValueError("rate must be 0<=rate<1, got {} instead".format(drop_prob))
self.keep_prob = 1 - drop_prob
def forward(self, x):
# 训练阶段随机丢失特征
if self.training:
# 是否保留取决于固定保留概率+随机概率
random_tensor = self.keep_prob + torch.rand([x.size(0), 1, 1, 1],
dtype=x.dtype,
device=x.device)
# 0表示丢失 1表示保留
binary_tensor = torch.floor(random_tensor)
# self.keep_prob个人理解对保留特征进行强化,概率越低强化越明显
return torch.mul(torch.div(x, self.keep_prob), binary_tensor)
else:
return x
完整代码
from collections import OrderedDict
from functools import partial
from typing import Callable
import torch
import torch.nn as nn
from torch import Tensor
from torch.nn import functional as F
from torchsummary import summary
def _make_divisible(ch, divisor=8, min_ch=None):
'''
int(ch + divisor / 2) // divisor * divisor)
目的是为了让new_ch是divisor的整数倍
类似于四舍五入:ch超过divisor的一半则加1保留;不满一半则归零舍弃
'''
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
# 反残差结构随机失活:batchsize个样本随机失活,应用于反残差结构的主路径
class DropConnect(nn.Module):
def __init__(self, drop_prob=0.5):
super(DropConnect, self).__init__()
self.keep_prob = None
self.set_rate(drop_prob)
# 反残差结构的保留率
def set_rate(self, drop_prob):
if not 0 <= drop_prob < 1:
raise ValueError("rate must be 0<=rate<1, got {} instead".format(drop_prob))
self.keep_prob = 1 - drop_prob
def forward(self, x):
# 训练阶段随机丢失特征
if self.training:
# 是否保留取决于固定保留概率+随机概率
random_tensor = self.keep_prob + torch.rand([x.size(0), 1, 1, 1],
dtype=x.dtype,
device=x.device)
# 0表示丢失 1表示保留
binary_tensor = torch.floor(random_tensor)
# self.keep_prob个人理解对保留特征进行强化,概率越低强化越明显
return torch.mul(torch.div(x, self.keep_prob), binary_tensor)
else:
return x
# 卷积块:3×3/5×5卷积层+BN层+Swish激活函数(可选)
class ConvBNAct(nn.Sequential):
def __init__(self,
in_planes, # 输入通道
out_planes, # 输出通道
kernel_size=3, # 卷积核大小
stride=1, # 卷积核步长
groups=1, # 卷积层组数
norm_layer=None, # 归一化层
activation_layer=None): # 激活层
super(ConvBNAct, self).__init__()
# 计算padding
padding = (kernel_size - 1) // 2
# BN层
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# Swish激活函数
if activation_layer is None:
# nn.SiLU 等价于 x * torch.sigmoid(x)
activation_layer = nn.SiLU
super(ConvBNAct, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())
# SE注意力模块:对各通道的特征分别强化
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c, # 1×1卷积输出通道数(降维)
expand_c, # se模块整体输入输出通道
se_ratio=0.25): # 降维系数
super(SqueezeExcitation, self).__init__()
# 降维通道数=降维卷积输出通道数*降维系数
squeeze_c = int(input_c * se_ratio)
# 1×1卷积(降维)
self.fc1 = nn.Conv2d(expand_c, squeeze_c, 1)
# Swish激活函数
self.ac1 = nn.SiLU()
# 1×1卷积(特征提取)
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1)
# Sigmoid激活函数(0~1重要性加权)
self.ac2 = nn.Sigmoid()
def forward(self, x):
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
# 特征按通道分别进行加权
return scale * x
# 反残差结构MBConv:1×1膨胀卷积层+BN层+Swish激活函数+3×3深度卷积层+BN层+Swish激活函数+1×1点卷积层+BN层
class MBConvBlock(nn.Module):
def __init__(self,
kernel, # 卷积核大小 3
input_c, # 输入通道数
out_c, # 输出通道数
expand_ratio, # 膨胀系数 4 or 6
stride, # 卷积核步长
se_ratio, # 启用se注意力模块
drop_rate, # 通道随机失活率
norm_layer): # 归一化层
super(MBConvBlock, self).__init__()
# 膨胀通道数 = 输入通道数*膨胀系数
expanded_c = input_c * expand_ratio
# 步长必须是1或者2
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
# 深度卷积步长为2则没有shortcut连接
self.use_res_connect = (stride == 1 and input_c == out_c)
layers = OrderedDict()
# Swish激活函数
activation_layer = nn.SiLU # alias Swish
# 在EfficientNetV2中,MBConvBlock中不存在expansion=1的情况
assert expand_ratio != 1
# 1×1膨胀卷积(膨胀系数>1) 升维
layers.update({"expand_conv": ConvBNAct(input_c,
expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 3×3深度卷积
layers.update({"dwconv": ConvBNAct(expanded_c,
expanded_c,
kernel_size=kernel,
stride=stride,
groups=expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 启用se注意力模块
if se_ratio > 0:
layers.update({"se": SqueezeExcitation(input_c,
expanded_c,
se_ratio)})
# 1×1点卷积
layers.update({"project_conv": ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)})
self.block = nn.Sequential(layers)
# 只有在使用shortcut连接时才使用drop_connect层
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
else:
self.drop_connect = nn.Identity()
def forward(self, x):
result = self.block(x)
result = self.drop_connect(result)
# 反残差结构随机失活
if self.use_res_connect:
result += x
return result
# 反残差结构FusedMBConv:3×3膨胀卷积层+BN层+Swish激活函数+1×1点卷积层+BN层
class FusedMBConvBlock(nn.Module):
def __init__(self,
kernel, # 卷积核大小
input_c, # 输入通道数
out_c, # 输出通道数
expand_ratio, # 膨胀系数 1 or 4
stride, # 卷积核步长
se_ratio, # 启用se注意力模块
drop_rate, # 通道随机失活率
norm_layer): # 归一化层
super(FusedMBConvBlock, self).__init__()
# 膨胀通道数 = 输入通道数*膨胀系数
expanded_c = input_c * expand_ratio
# 步长必须是1或者2
assert stride in [1, 2]
# 没有se注意力模块
assert se_ratio == 0
# 深度卷积步长为2则没有shortcut连接
self.use_res_connect = stride == 1 and input_c == out_c
self.drop_rate = drop_rate
self.has_expansion = expand_ratio != 1
layers = OrderedDict()
# Swish激活函数
activation_layer = nn.SiLU
# 只有当expand ratio不等于1时才有膨胀卷积
if self.has_expansion:
# 3×3膨胀卷积(膨胀系数>1) 升维
layers.update({"expand_conv": ConvBNAct(input_c,
expanded_c,
kernel_size=kernel,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# 1×1点卷积
layers.update({"project_conv": ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)}) # 注意没有激活函数
else:
# 当没有膨胀卷积时,3×3点卷积
layers.update({"project_conv": ConvBNAct(input_c,
out_c,
kernel_size=kernel,
norm_layer=norm_layer,
activation_layer=activation_layer)}) # 注意有激活函数
self.block = nn.Sequential(layers)
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
# 只有在使用shortcut连接时才使用drop_connect层
if self.use_res_connect and drop_rate > 0:
self.drop_connect = DropConnect(drop_rate)
else:
self.drop_connect = nn.Identity()
def forward(self, x):
result = self.block(x)
result = self.drop_connect(result)
# 反残差结构随机失活
if self.use_res_connect:
result += x
return result
class EfficientNetV2(nn.Module):
def __init__(self,
model_cnf, # 配置参数
num_classes=1000, # 输出类别
num_features=1280,
dropout_rate=0.2, # 通道随机失活率
drop_connect_rate=0.2): # 反残差结构随机失活概率
super(EfficientNetV2, self).__init__()
# 配置参数无误
for cnf in model_cnf:
assert len(cnf) == 8
# 配置bn层参数
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
self.stem = ConvBNAct(in_planes=3,
out_planes=_make_divisible(model_cnf[0][4]),
kernel_size=3,
stride=2,
norm_layer=norm_layer) # 激活函数默认是SiLU
# 当前反残差结构序号
block_id = 0
# 反残差结构总数
total_blocks = sum([i[0] for i in model_cnf])
blocks = []
for cnf in model_cnf:
# 选择反残差结构 0是MBConvBlock 1是FusedMBConvBlock
op = FusedMBConvBlock if cnf[-2] == 0 else MBConvBlock
# 每个stage的反残差结构数数
repeats = cnf[0]
for i in range(repeats):
# 反残差结构随机失活概率随着网络深度等差递增,公差为drop_connect_rate/total_blocks,范围在[0,drop_connect_rate)
blocks.append(op(kernel=cnf[1],
input_c=_make_divisible(cnf[4] if i == 0 else cnf[5]),
out_c=_make_divisible(cnf[5]),
expand_ratio=cnf[3],
stride=cnf[2] if i == 0 else 1,
se_ratio=cnf[-1],
drop_rate=drop_connect_rate * block_id / total_blocks,
norm_layer=norm_layer))
block_id += 1
head_input_c = _make_divisible(model_cnf[-1][-3])
# 主干网络
self.blocks = nn.Sequential(*blocks)
head = OrderedDict()
head.update({"project_conv": ConvBNAct(head_input_c,
_make_divisible(num_features),
kernel_size=1,
norm_layer=norm_layer)}) # 激活函数默认是SiLU
head.update({"avgpool": nn.AdaptiveAvgPool2d(1)})
head.update({"flatten": nn.Flatten()})
if dropout_rate > 0:
head.update({"dropout": nn.Dropout(p=dropout_rate, inplace=True)})
head.update({"classifier": nn.Linear(_make_divisible(num_features), num_classes)})
# 分类器
self.head = nn.Sequential(head)
# 初始化权重
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
# 主干网络
x = self.stem(x)
x = self.blocks(x)
x = self.head(x)
return x
# 不同的网络模型对应不同的分辨率
def efficientnetv2_s(num_classes = 1000):
# train_size: 300, eval_size: 384
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[2, 3, 1, 1, 24, 24, 0, 0],
[4, 3, 2, 4, 24, 48, 0, 0],
[4, 3, 2, 4, 48, 64, 0, 0],
[6, 3, 2, 4, 64, 128, 1, 0.25],
[9, 3, 1, 6, 128, 160, 1, 0.25],
[15, 3, 2, 6, 160, 256, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.2)
return model
def efficientnetv2_m(num_classes = 1000):
# train_size: 384, eval_size: 480
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[3, 3, 1, 1, 24, 24, 0, 0],
[5, 3, 2, 4, 24, 48, 0, 0],
[5, 3, 2, 4, 48, 80, 0, 0],
[7, 3, 2, 4, 80, 160, 1, 0.25],
[14, 3, 1, 6, 160, 176, 1, 0.25],
[18, 3, 2, 6, 176, 304, 1, 0.25],
[5, 3, 1, 6, 304, 512, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.3)
return model
def efficientnetv2_l(num_classes = 1000):
# train_size: 384, eval_size: 480
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[4, 3, 1, 1, 32, 32, 0, 0],
[7, 3, 2, 4, 32, 64, 0, 0],
[7, 3, 2, 4, 64, 96, 0, 0],
[10, 3, 2, 4, 96, 192, 1, 0.25],
[19, 3, 1, 6, 192, 224, 1, 0.25],
[25, 3, 2, 6, 224, 384, 1, 0.25],
[7, 3, 1, 6, 384, 640, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.4)
return model
def efficientnetv2_xl(num_classes = 1000):
# train_size: 384, eval_size: 512
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[4, 3, 1, 1, 32, 32, 0, 0],
[8, 3, 2, 4, 32, 64, 0, 0],
[8, 3, 2, 4, 64, 96, 0, 0],
[16, 3, 2, 4, 96, 192, 1, 0.25],
[24, 3, 1, 6, 192, 256, 1, 0.25],
[32, 3, 2, 6, 256, 512, 1, 0.25],
[8, 3, 1, 6, 512, 640, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.4)
return model
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = efficientnetv2_s().to(device)
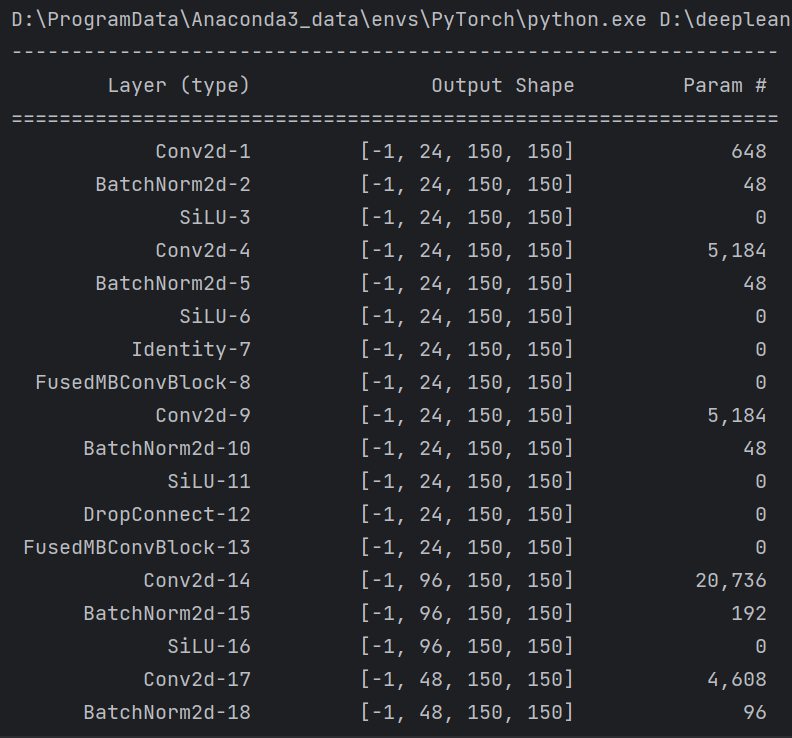
summary(model, input_size=(3, 300, 300))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了EfficientNet_V2改进过程和效果,讲解了EfficientNet_V2模型的结构和pytorch代码。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- STM32 TIM定时中断设计
- ansible从入门到精通(完整篇)
- 【IDEA】瑞_IDEA模版注释设置_IDEA自动生成注释模版(详细图文步骤)
- 数据库:园林题库软件(《城市绿地系统规划》答题卷一)
- go 源码解读 sync.RWMutex
- 共享代理IP是什么?有什么特点?
- 高校站群内容管理系统开发语言各有优势
- 017集:strip( )函数详解—python基础入门实例
- 【Linux】进程信号
- Blazor 的基本原理探索