阿里巴巴提出AnyText:首个解决多语言视觉文本生成的工作

基于扩散模型的文本到图像在最近取得了令人瞩目的成就。尽管当前的图像合成技术已经非常先进,能够以高保真度生成图像,但当关注生成图像中的文本区域时,往往可能会暴露问题,因为合成文本通常包含模糊、不可读或不正确的字符,使得视觉文本生成成为该领域最具挑战性的问题之一。为了解决这个问题,本文引入了AnyText,这是一个基于扩散的多语言视觉文本生成和编辑模型,专注于在图像中呈现准确而连贯的文本。AnyText包括一个具有两个主要元素的扩散pipeline:辅助潜在模块和文本embedding模块。前者使用文本字形、位置和mask图像等输入,生成用于文本生成或编辑的潜在特征。后者采用OCR模型将笔画数据编码为embedding,这些embedding与来自分词器的图像字幕embedding融合,生成与背景无缝集成的文本。使用文本控制扩散损失和文本感知损失进行训练,以进一步提高写作准确性。AnyText可以书写多种语言的字符,据我们所知,这是首个解决多语言视觉文本生成的工作。值得一提的是,AnyText可以插入社区中现有的扩散模型,以准确呈现或编辑文本。在进行了广泛的评估实验后,我们的方法在所有其他方法中表现出色。此外,我们贡献了第一个大规模的多语言文本图像数据集AnyWord-3M,包含300万个图像文本对,其中包含多种语言的OCR注释。基于AnyWord-3M数据集,我们提出了AnyText-benchmark,用于评估视觉文本生成的准确性和质量。
开源地址:https://github.com/tyxsspa/AnyText
主要贡献
a) 多行:AnyText可以在用户指定的位置生成多行文本。
b) 变形区域:它可以在水平、垂直甚至弯曲或不规则的区域进行书写。
c) 多语言:我们的方法可以生成中文、英文、日文、韩文等多种语言的文本。
d) 文本编辑:提供在所提供的图像中以一致的字体样式修改文本内容的能力。
e) 即插即用:AnyText可以与稳定的扩散模型无缝集成,并赋予它们生成文本的能力。
算法框架
对于文本生成,AnyText可以将指定的文本从提示渲染到指定的位置,并生成外观吸引人的图像。至于文本编辑,AnyText可以在输入图像中指定位置修改文本内容,同时保持与周围文本样式的一致性。如下图:对于提示中的非英语单词,提供括号中的翻译,蓝色框表示文本编辑的位置。

AnyText的框架,包括文本控制扩散pipeline、辅助潜在模块、文本embedding模块和文本感知损失:

效果展示
AnyText和竞争方法的定量比较。下表中?是在LAION-Glyph-10M上训练的,而?是在TextCaps-5k上进行了微调。所有竞争方法都使用官方发布的模型进行评估。

AnyText和英文文本生成的最新模型或API的定性比较。所有标题均从AnyText-benchmark的英文评估数据集中选择:

GlyphDraw、ControlNet和AnyText在中文文本生成方面的比较示例,所有示例均摘自原始的GlyphDraw论文:

一些无文本生成图像效果:

与 AnyText 集成的可以生成文本的模型示例

文本生成中AnyText的更多效果展示:
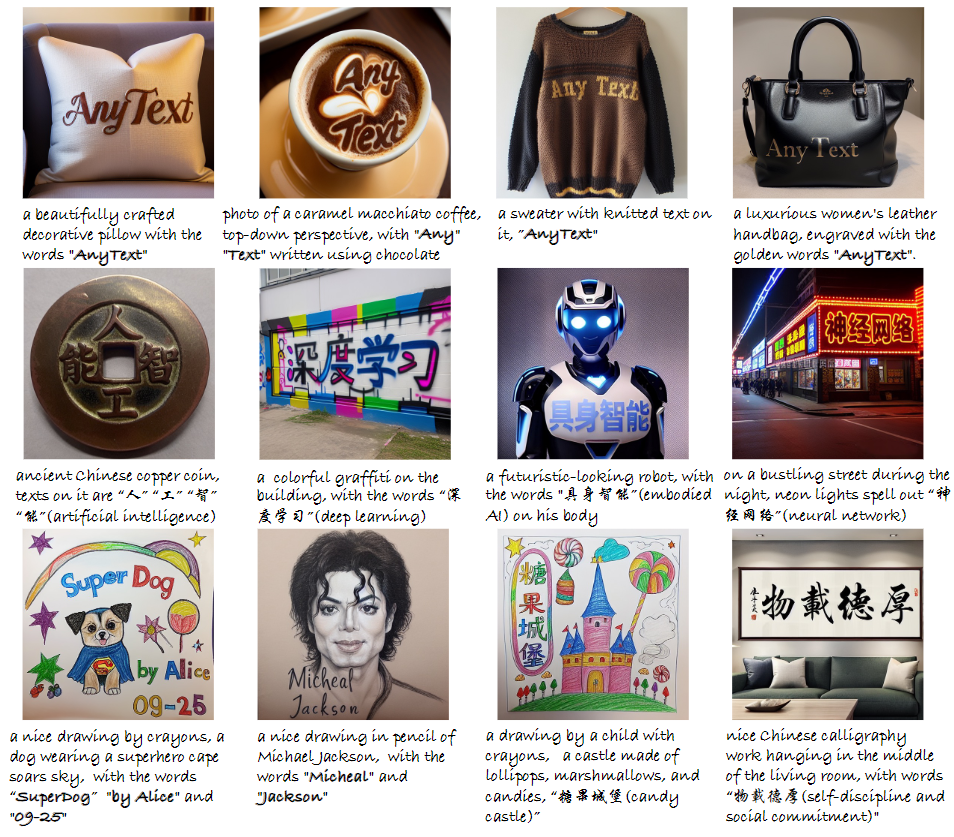
文本编辑中的AnyText 效果展示:

?
多精彩内容,请关注公众号:AI生成未来

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- nodejs微信小程序+python+PHP基于Android自习室管理系统的设计与实现-计算机毕业设计推荐
- 国产矩阵方案首选LT8644EX-4进4出,8进8出,16进16出数字交叉点开关,矩阵控制软件介绍
- 【JS面试题】Javascript内置的可迭代对象
- Ado.Net连接数据库
- 矩阵微分笔记(3)
- sql语句条件查询,模糊查询
- Nacos
- 【零基础入门Docker】如何构建Web服务Dockerfile?
- 基于Java Web的素材网站的设计与实现
- DDA 算法