dpdk原理概述及核心源码剖析
dpdk原理
1、操作系统、计算机网络诞生已经几十年了,部分功能不再能满足现在的业务需求。如果对操作系统做更改,成本非常高,所以部分问题是在应用层想办法解决的,比如前面介绍的协程、quic等,都是在应用层重新开发的框架,简单回顾如下:
-
协程:server多线程通信时,如果每连接一个客户端就要生成一个线程去处理,对server硬件资源消耗极大!为了解决多线程以及互相切换带来的性能损耗,应用层发明了协程框架:单线程人为控制跳转到不同的代码块执行,避免了cpu浪费、线程锁/切换等一系列耗时的问题!
-
quic协议:tcp协议已经深度嵌入了操作系统,更改起来难度很大,所以同样也是在应用层基于udp协议实现了tls、拥塞控制等,彻底让协议和操作系统松耦合!
除了上述问题,操作还有另一个比较严重的问题:基于os内核的网络数据IO!传统做网络开发时,接收和发送数据用的是操作系统提供的receive和send函数,用户配置一下网络参数、传入应用层的数据即可!操作系统由于集成了协议栈,会在用户传输的应用层数据前面加上协议不同层级的包头,然后通过网卡发送数据;接收到的数据处理方式类似,按照协议类型一层一层拨开,直到获取到应用层的数据!整个流程大致如下:
网卡接受数据----->发出硬件中断通知cpu来取数据----->os把数据复制到内存并启动内核线程 --->软件中断--->内核线程在协议栈中处理包--->处理完毕通知用户层
大家有没有觉得这个链条忒长啊?这么长的处理流程带来的问题:
-
“中间商”多,整个流程耗时;数据进入下一个环节时容易cache miss
-
同一份数据在内存不同的地方存储(缓存内存、内核内存、用户空间的内存),浪费内存
-
网卡通过中断通知cpu,每次硬中断大约消耗100微秒,这还不算因为终止上下文所带来的Cache Miss(L1、L2、TLB等cpu的cache可能都会更新)
-
用户到内核态的上下文切换耗时
-
数据在内核态用户态之间切换拷贝带来大量CPU消耗,全局锁竞争
-
内核工作在多核上,为保障全局一致,即使采用Lock Free,也避免不了锁总线、内存屏障带来的性能损耗
这一系列的问题都是内核处理网卡接收到的数据导致的。大胆一点想象:如果不让内核处理网卡数据了?能不能避免上述各个环节的损耗了?能不能让3环的应用直接控制网卡收发数据了?
2、如果真的通过3环应用层直接读写网卡,面临的问题:
-
用户空间的内存要映射到网卡,才能直接读写网卡
-
驱动要运行在用户空间
(1)这两个问题是怎么解决的了?这一切都得益于linux提供的UIO机制! UIO 能够拦截中断,并重设中断回调行为(相当于hook了,这个功能还是要在内核实现的,因为硬件中断只能在内核处理),从而绕过内核协议栈后续的处理流程。这里借用别人的一张图:

UIO 设备的实现机制其实是对用户空间暴露文件接口,比如当注册一个 UIO 设备 uioX,就会出现文件 /dev/uioX(用于读取中断,底层还是要在内核处理,因为硬件中断只能发生在内核),对该文件的读写就是对设备内存的读写(通过mmap实现)。除此之外,对设备的控制还可以通过 /sys/class/uio 下的各个文件的读写来完成。所以UIO的本质:
-
让用户空间的程序拦截内核的中断,更改中断的handler处理函数,让用户空间的程序第一时间拿到刚从网卡接收到的“一手、热乎”数据,减少内核的数据处理流程!由于应用程序拿到的是网络链路层(也就是第二层)的数据,这就需要应用程序自己按照协议解析数据了!说个额外的:这个功能可以用来抓包!
简化后的示意图如下:原本网卡是由操作系统内核接管的,现在直接由3环的dpdk应用控制了!

这就是dpdk的第一个优点;除了这个,还有以下几个:
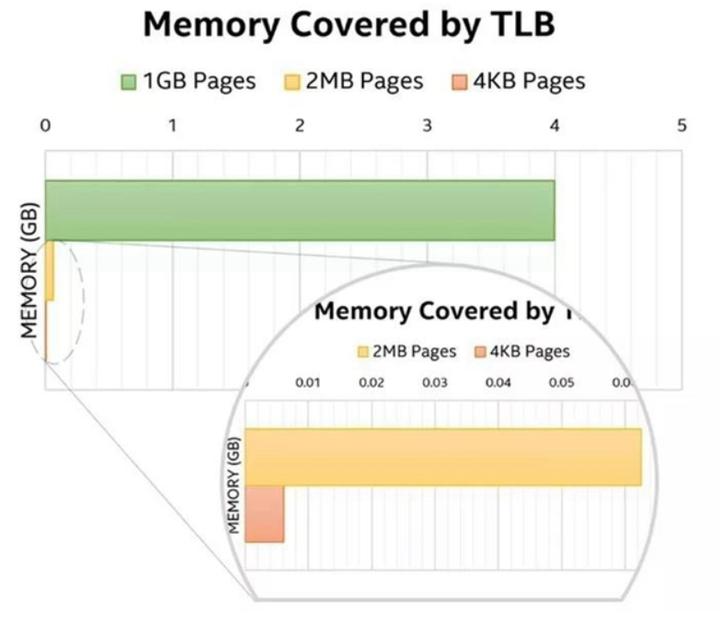
(2)Huge Page 大页:传统页面大小是4Kb,如果进程要使用64G内存,则64G/4KB=16000000(一千六百万)页,所有在页表项中占用16000000 * 4B=62MB;但是TLB缓存的空间是有限的,不可能存储这么多页面的地址映射关系,所以可能导致TLB miss;如果改成2MB的huge Page,所需页面减少到64G/2MB=2000个。在TLB容量有限的情况下尽可能地多在TLB存放地址映射,极大减少了TLB miss!下图是采用不同大小页面时TLB能覆盖的内存对比!
(3)mempool 内存池:任何网络协议都要处理报文,这些报文肯定是存放在内存的!申请和释放内存就需要调用malloc和free函数了!这两个是系统调用,涉及到上下文切换;同时还要用buddy或slab算法查找空闲内存块,效率较低!dpdk 在用户空间实现了一套精巧的内存池技术,内核空间和用户空间的内存交互不进行拷贝,只做控制权转移。当收发数据包时,就减少了内存拷贝的开销!
(4)Ring 无锁环:多线程/多进程之间互斥,传统的方式就是上锁!但是dpdk基于 Linux 内核的无锁环形缓冲 kfifo 实现了自己的一套无锁机制,支持多消费者或单消费者出队、多生产者或单生产者入队;
(5)PMD poll-mode网卡驱动:网络IO监听有两种方式,分别是
-
事件驱动,比如epoll:这种方式进程让出cpu后等数据;一旦有了数据,网卡通过中断通知操作系统,然后唤醒进程继续执行!这种方式适合于接收的数据量不大,但实时性要求高的场景;
-
轮询,比如poll:本质就是用死循环不停的检查内存有没有数据到来!这种方式适合于接收大块数据,实时性要求不高的场景;
总的来说说:中断是外界强加给的信号,必须被动应对,而轮询则是应用程序主动地处理事情。前者最大的影响就是打断系统当前工作的连续性,而后者则不会,事务的安排自在掌握!
dpdk采用第二种轮询方式:直接用死循环不停的地检查网卡内存,带来了零拷贝、无系统调用的好处,同时避免了网卡硬件中断带来的上下文切换(理论上会消耗300个时钟周期)、cache miss、硬中断执行等损耗!
(6)NUMA:dpdk 内存分配上通过 proc 提供的内存信息,使 CPU 核心尽量使用靠近其所在节点的内存,避免了跨 NUMA 节点远程访问内存的性能问题;其软件架构去中心化,尽量避免全局共享,带来全局竞争,失去横向扩展的能力
(7)CPU 亲和性: dpdk 利用 CPU 的亲和性将一个线程或多个线程绑定到一个或多个 CPU 上,这样在线程执行过程中,就不会被随意调度,一方面减少了线程间的频繁切换带来的开销,另一方面避免了 CPU L1、L2、TLB等缓存的局部失效性,增加了 CPU cache的命中率。
dpdk学习视频推荐
dpdk专题讲解,dpdk/网络协议栈/vpp/OvS/DDos/SDN/NFV/虚拟化/高性能网络专家之路![]() https://www.bilibili.com/video/BV1fY411z7Y8/
https://www.bilibili.com/video/BV1fY411z7Y8/
Linux C/C++开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

dpdk核心源码
dpdk是intel主导开发的网络编程框架, 有这么多的优点,都是怎么实现的了?
1、UIO原理:dpdk绕过了操作系统内核,直接接管网卡,用户程序可以直接在3环读写网卡的数据,这就涉及到两个关键技术点了:
-
地址映射:3环的程序是怎么定位到网卡数据存放在哪的了?
-
拦截硬件中断:传统数据处理流程是网卡收到数据后通过硬件中断通知cpu来取数据,3环的程序肯定要拦截这个中断,然后通过轮询方式取数据,这个又是怎么实现的了?
(1)地址映射:3环程序最常使用的就是内存地址了,一共32或64bit;C/C++层面可以通过指针直接读写地址的值;除了内存,还有很多设备也需要和cpu交互数据,比如显示器:要在屏幕显示的内容肯定是需要用户指定的,用户程序可以把显示的内容发送到显示器指定的地方,然后再屏幕打印出来。为了方便用户程序发送数据,硬件层面会把显示器的部分存储空间映射到内存地址,做到了和内存条硬件的寻址方式一样,用户也可以直接通过指针往这里写数据(汇编层面直接通过mov指令操作即可)!网卡也类似:网卡是插在pci插槽的,网卡(或者说pci插槽)的存储空间也会映射到内存地址,应用程序读写这块物理地址就等同于读写网卡的存储空间!实际写代码时,由于要深入驱动,pci网卡预留物理的内存与io空间会保存到uio设备上,相当于将这些物理空间与io空间暴露给uio设备,应用程序访问这些uio设备即可!几个关键的函数如下:
将pci网卡的物理内存空间以及io空间保存在uio设备结构struct uio_info中的mem成员以及port成员中,uio设备就知道了网卡的物理以及io空间。应用层访问这个uio设备的物理空间以及io空间,就相当于访问pci设备的物理以及io空间;本质上就是将pci网卡的空间暴露给uio设备。
int igbuio_pci_probe(struct pci_dev *dev, const struct pci_device_id *id)
{
//将pci内存,端口映射给uio设备
struct rte_uio_pci_dev *udev;
err = igbuio_setup_bars(dev, &udev->info);
}
static int igbuio_setup_bars(struct pci_dev *dev, struct uio_info *info)
{
//pci内存,端口映射给uio设备
for (i = 0; i != sizeof(bar_names) / sizeof(bar_names[0]); i++)
{
if (pci_resource_len(dev, i) != 0 && pci_resource_start(dev, i) != 0)
{
flags = pci_resource_flags(dev, i);
if (flags & IORESOURCE_MEM)
{
//暴露pci的内存空间给uio设备
ret = igbuio_pci_setup_iomem(dev, info, iom, i, bar_names[i]);
}
else if (flags & IORESOURCE_IO)
{
//暴露pci的io空间给uio设备
ret = igbuio_pci_setup_ioport(dev, info, iop, i, bar_names[i]);
}
}
}
}(2)拦截硬件中断:为了减掉内核中冗余的数据处理流程,应用程序要hook网卡的中断,从源头开始拦截网卡数据!当硬件中断触发时,才不会一直触发内核去执行中断回调。也就是通过这种方式,才能在应用层实现硬件中断处理过程。注意:这里说的中断仅是控制中断,而不是报文收发的数据中断,数据中断是不会走到这里来的,因为在pmd开启中断时,没有设置收发报文的中断掩码,只注册了网卡状态改变的中断掩码;hook中断的代码如下:
int igbuio_pci_probe(struct pci_dev *dev, const struct pci_device_id *id)
{
//填充uio信息
udev->info.name = "igb_uio";
udev->info.version = "0.1";
udev->info.handler = igbuio_pci_irqhandler; //硬件控制中断的入口,劫持原来的硬件中断
udev->info.irqcontrol = igbuio_pci_irqcontrol; //应用层开关中断时被调用,用于是否开始中断
}
static irqreturn_t igbuio_pci_irqhandler(int irq, struct uio_info *info)
{
if (udev->mode == RTE_INTR_MODE_LEGACY && !pci_check_and_mask_intx(udev->pdev))
{
return IRQ_NONE;
}
//返回IRQ_HANDLED时,linux uio框架会唤醒等待uio中断的进程。注册到epoll的uio中断事件就会被调度
/* Message signal mode, no share IRQ and automasked */
return IRQ_HANDLED;
}
static int igbuio_pci_irqcontrol(struct uio_info *info, s32 irq_state)
{
//调用内核的api来开关中断
if (udev->mode == RTE_INTR_MODE_LEGACY)
{
pci_intx(pdev, !!irq_state);
}
else if (udev->mode == RTE_INTR_MODE_MSIX)\
{
list_for_each_entry(desc, &pdev->msi_list, list)
igbuio_msix_mask_irq(desc, irq_state);
}
}2、内存池:传统应用要使用内存时,一般都是调用malloc让操作系统在堆上分配。这样做有两点弊端:
-
进入内核要切换上下文
-
操作系统通过buddy&slab算法找合适的空闲内存
所以频繁调用malloc会严重拉低效率!如果不频繁调用malloc,怎么处理频繁收到和需要发送的报文数据了?dpdk采用的是内存池的技术:即在huge page内存中开辟一个连续的大缓冲区当做内存池!同时提供rte_mempool_get从内存池中获取内存空间。也可调用rte_mempool_put将不再使用的内存空间放回到内存池中。从这里就能看出:dpdk自己从huge page处维护了一大块内存供应用程序使用,应用程序不再需要通过系统调用从操作系统申请内存了!
(1)内存池的创建,在rte_mempool_create接口中完成。这个接口主要是在大页内存中开辟一个连续的大缓冲区当做内存池,然后将这个内存池进行分割,头部为struct rte_mempool内存池结构; 紧接着是内存池的私有结构大小,这个由应用层自己设置,每个创建内存池的应用进程都可以指定不同的私有结构; 最后是多个连续的对象元素,这些对象元素都是处于同一个内存池中。每个对象元素又有对象的头部,对象的真实数据区域,对象的尾部组成。这里所说的对象元素,其实就是应用层要开辟的真实数据空间,例如应用层自己定义的结构体变量等;本质上是dpdk自己实现了一套内存的管理办法,其作用和linux的buddy&slab是一样的,没本质区别!整个内存池图示如下:
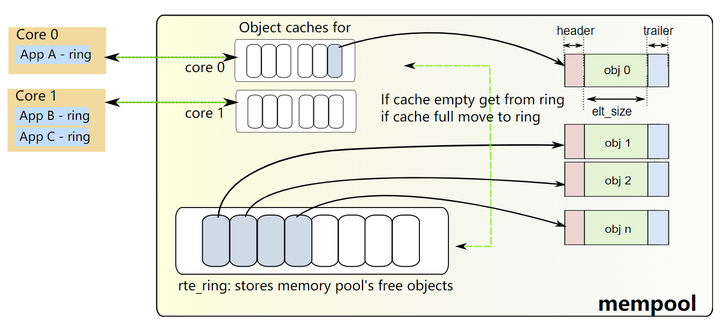
每创建一个内存池,都会创建一个链表节点,然后插入到链表中,因此这个链表记录着当前系统创建了多少内存池。核心代码如下:
//创建内存池链表节点
te = rte_zmalloc("MEMPOOL_TAILQ_ENTRY", sizeof(*te), 0);
//内存池链表节点插入到内存池链表中
te->data = (void *) mp;
RTE_EAL_TAILQ_INSERT_TAIL(RTE_TAILQ_MEMPOOL, rte_mempool_list, te);所以说内存池可能不止1个,会有多个!在内存池中,内存被划分成了N多的对象。应用程序要申请内存时,怎么知道哪些对象空闲可以用,哪些对象已经被占用了?当对象元素初始化完成后,会把对象指针放入ring队列,所以说ring队列的所有对象指针都是可以使用的!应用程序要申请内存时,可以调用rte_mempool_get接口从ring队列中获取,也就是出队; 使用完毕后调用rte_mempool_put将内存释放回收时,也是将要回收的内存空间对应的对象指针放到这个ring队列中,也就是入队!
(2)具体分配内存时的步骤:
-
现代cpu基本都是多核的,多个cpu同时在内存池申请内存时无法避免涉及到互斥,会在一定程度上影响分配的效率,所以每个cpu自己都有自己的“自留地”,会优先在自己的“自留地”申请内存;
-
如果“自留地”的内存已耗尽,才会继续去内存池申请内存!核心代码如下:
int rte_mempool_get(struct rte_mempool *mp, void **obj_table, unsigned n)
{
#if RTE_MEMPOOL_CACHE_MAX_SIZE > 0
//从当前cpu应用层缓冲区中获取
cache = &mp->local_cache[lcore_id];
cache_objs = cache->objs;
for (index = 0, len = cache->len - 1; index < n; ++index, len--, obj_table++)
{
*obj_table = cache_objs[len];
}
return 0;
#endif
/* get remaining objects from ring */
//直接从ring队列中获取
ret = rte_ring_sc_dequeue_bulk(mp->ring, obj_table, n);
}释放内存的步骤和申请类似:
-
先查看cpu的“自留地”是否还有空间。如果有,就先把释放的对象指针放在“自留地”;
-
如果“自留地”没空间了,再把释放的对象指针放在内存池!核心代码如下:
int rte_mempool_put(struct rte_mempool *mp, void **obj_table, unsigned n)
{
#if RTE_MEMPOOL_CACHE_MAX_SIZE > 0
//在当前cpu本地缓存有空间的场景下, 先放回到本地缓存。
cache = &mp->local_cache[lcore_id];
cache_objs = &cache->objs[cache->len];
for (index = 0; index < n; ++index, obj_table++)
{
cache_objs[index] = *obj_table;
}
//缓冲达到阈值,刷到队列中
if (cache->len >= flushthresh)
{
rte_ring_mp_enqueue_bulk(mp->ring, &cache->objs[cache_size], cache->len - cache_size);
cache->len = cache_size;
}
return 0
#endif
//直接放回到ring队列
rte_ring_sp_enqueue_bulk(mp->ring, obj_table, n);
}注意:这里的ring是环形无锁队列!
3、Poll mode driver: 不论何总形式的io,接收方获取数据的方式有两种:
-
被动接收中断的唤醒:典型如网卡收到数据,通过硬件中断通知操作系统去处理;操作系统收到数据后会唤醒休眠的进程继续处理数据
-
轮询 poll:写个死循环不停的检查内存地址是否有新数据到了!
在 x86 体系结构中,一次中断处理需要将 CPU 的状态寄存器保存到堆栈,并运行中断handler,最后再将保存的状态寄存器信息从堆栈中恢复,整个过程需要至少 300 个处理器时钟周期!所以dpdk果断抛弃了中断,转而使用轮询方式!整个流程大致是这样的:内核态的UIO Driver hook了网卡发出的中断信号,然后由用户态的 PMD Driver 采用主动轮询的方式。除了链路状态通知仍必须采用中断方式以外(因为网卡发出硬件中断才能触发执行hook代码的嘛,这个容易理解吧?),均使用无中断方式直接操作网卡设备的接收和发送队列。整体流程大致如下:UIO hook了网卡的中断,网卡收到数据后“被迫”执行hook代码!先是通过UIO把网卡的存储地址映射到/dev/uio文件,而后应用程序通过PMD轮询检查文件是否有新数据到来!期间也使用mmap把应用的虚拟地址映射到网卡的物理地址,减少数据的拷贝转移!

总的来说:UIO+PMD,前者旁路了内核,后者主动轮询避免了硬中断,DPDK 从而可以在用户态进行收发包的处理。带来了零拷贝(Zero Copy)、无系统调用(System call)的优化。同时,还避免了软中断的异步处理,也减少了上下文切换带来的 Cache Miss!轮询收报核心代码如下:
/*PMD轮询接收数据包*/
uint16_t
eth_em_recv_pkts(void *rx_queue, struct rte_mbuf **rx_pkts,
uint16_t nb_pkts)
{
/* volatile防止编译器优化,每次使用必须又一次从memory中取而不是用寄存器的值 */
volatile struct e1000_rx_desc *rx_ring;
volatile struct e1000_rx_desc *rxdp;//指向rx ring中某个e1000_rx_desc描述符
struct em_rx_queue *rxq;//整个接收队列
struct em_rx_entry *sw_ring;//指向描述符队列的头部,根据rx tail来偏移
struct em_rx_entry *rxe;//指向sw ring中具体的entry
struct rte_mbuf *rxm;//entry里的rte mbuf
/*是new mbuf,新申请的mbuf,当rxm从ring中取出后,需要用nmb再挂上去,
更新对应rx ring和sw ring中的值,为下一次收包做准备*/
struct rte_mbuf *nmb;
struct e1000_rx_desc rxd;//具体的非指针描述符
uint64_t dma_addr;
uint16_t pkt_len;
uint16_t rx_id;
uint16_t nb_rx;
uint16_t nb_hold;
uint8_t status;
rxq = rx_queue;
nb_rx = 0;
nb_hold = 0;
//初始化临时变量,要开始遍历队列了
rx_id = rxq->rx_tail;
rx_ring = rxq->rx_ring;
sw_ring = rxq->sw_ring;
/* 一次性收32个报文 */
while (nb_rx < nb_pkts) {
/*
* The order of operations here is important as the DD status
* bit must not be read after any other descriptor fields.
* rx_ring and rxdp are pointing to volatile data so the order
* of accesses cannot be reordered by the compiler. If they were
* not volatile, they could be reordered which could lead to
* using invalid descriptor fields when read from rxd.
*/
/* 当前报文的descriptor */
rxdp = &rx_ring[rx_id];
status = rxdp->status; /* 结束标记,必须首先读取 */
/*检查状态是否为dd, 不是则说明驱动还没有把报文放到接收队列,直接退出*/
if (! (status & E1000_RXD_STAT_DD))
break;
rxd = *rxdp; /* 复制一份 */
/*
* End of packet.
*
* If the E1000_RXD_STAT_EOP flag is not set, the RX packet is
* likely to be invalid and to be dropped by the various
* validation checks performed by the network stack.
*
* Allocate a new mbuf to replenish the RX ring descriptor.
* If the allocation fails:
* - arrange for that RX descriptor to be the first one
* being parsed the next time the receive function is
* invoked [on the same queue].
*
* - Stop parsing the RX ring and return immediately.
*
* This policy do not drop the packet received in the RX
* descriptor for which the allocation of a new mbuf failed.
* Thus, it allows that packet to be later retrieved if
* mbuf have been freed in the mean time.
* As a side effect, holding RX descriptors instead of
* systematically giving them back to the NIC may lead to
* RX ring exhaustion situations.
* However, the NIC can gracefully prevent such situations
* to happen by sending specific "back-pressure" flow control
* frames to its peer(s).
*/
PMD_RX_LOG(DEBUG, "port_id=%u queue_id=%u rx_id=%u "
"status=0x%x pkt_len=%u",
(unsigned) rxq->port_id, (unsigned) rxq->queue_id,
(unsigned) rx_id, (unsigned) status,
(unsigned) rte_le_to_cpu_16(rxd.length));
nmb = rte_mbuf_raw_alloc(rxq->mb_pool);
if (nmb == NULL) {
PMD_RX_LOG(DEBUG, "RX mbuf alloc failed port_id=%u "
"queue_id=%u",
(unsigned) rxq->port_id,
(unsigned) rxq->queue_id);
rte_eth_devices[rxq->port_id].data->rx_mbuf_alloc_failed++;
break;
}
/* 表示当前descriptor被上层软件占用 */
nb_hold++;
/* 当前收到的mbuf */
rxe = &sw_ring[rx_id];
/* 收包位置,假设超过环状数组则回滚 */
rx_id++;
if (rx_id == rxq->nb_rx_desc)
rx_id = 0;
/* mbuf加载cache下次循环使用 */
/* Prefetch next mbuf while processing current one. */
rte_em_prefetch(sw_ring[rx_id].mbuf);
/*
* When next RX descriptor is on a cache-line boundary,
* prefetch the next 4 RX descriptors and the next 8 pointers
* to mbufs.
*/
/* 取下一个descriptor,以及mbuf指针下次循环使用 */
/* 一个cache line是4个descriptor大小(64字节) */
if ((rx_id & 0x3) == 0) {
rte_em_prefetch(&rx_ring[rx_id]);
rte_em_prefetch(&sw_ring[rx_id]);
}
/* Rearm RXD: attach new mbuf and reset status to zero. */
rxm = rxe->mbuf;
rxe->mbuf = nmb;
dma_addr =
rte_cpu_to_le_64(rte_mbuf_data_iova_default(nmb));
rxdp->buffer_addr = dma_addr;
rxdp->status = 0;/* 重置当前descriptor的status */
/*
* Initialize the returned mbuf.
* 1) setup generic mbuf fields:
* - number of segments,
* - next segment,
* - packet length,
* - RX port identifier.
* 2) integrate hardware offload data, if any:
* - RSS flag & hash,
* - IP checksum flag,
* - VLAN TCI, if any,
* - error flags.
*/
pkt_len = (uint16_t) (rte_le_to_cpu_16(rxd.length) -
rxq->crc_len);
rxm->data_off = RTE_PKTMBUF_HEADROOM;
rte_packet_prefetch((char *)rxm->buf_addr + rxm->data_off);
rxm->nb_segs = 1;
rxm->next = NULL;
rxm->pkt_len = pkt_len;
rxm->data_len = pkt_len;
rxm->port = rxq->port_id;
rxm->ol_flags = rx_desc_status_to_pkt_flags(status);
rxm->ol_flags = rxm->ol_flags |
rx_desc_error_to_pkt_flags(rxd.errors);
/* Only valid if PKT_RX_VLAN set in pkt_flags */
rxm->vlan_tci = rte_le_to_cpu_16(rxd.special);
/*
* Store the mbuf address into the next entry of the array
* of returned packets.
*/
/* 把收到的mbuf返回给用户 */
rx_pkts[nb_rx++] = rxm;
}
/* 收包位置更新 */
rxq->rx_tail = rx_id;
/*
* If the number of free RX descriptors is greater than the RX free
* threshold of the queue, advance the Receive Descriptor Tail (RDT)
* register.
* Update the RDT with the value of the last processed RX descriptor
* minus 1, to guarantee that the RDT register is never equal to the
* RDH register, which creates a "full" ring situtation from the
* hardware point of view...
*/
nb_hold = (uint16_t) (nb_hold + rxq->nb_rx_hold);
if (nb_hold > rxq->rx_free_thresh) {
PMD_RX_LOG(DEBUG, "port_id=%u queue_id=%u rx_tail=%u "
"nb_hold=%u nb_rx=%u",
(unsigned) rxq->port_id, (unsigned) rxq->queue_id,
(unsigned) rx_id, (unsigned) nb_hold,
(unsigned) nb_rx);
rx_id = (uint16_t) ((rx_id == 0) ?
(rxq->nb_rx_desc - 1) : (rx_id - 1));
E1000_PCI_REG_WRITE(rxq->rdt_reg_addr, rx_id);
nb_hold = 0;
}
rxq->nb_rx_hold = nb_hold;
return nb_rx;
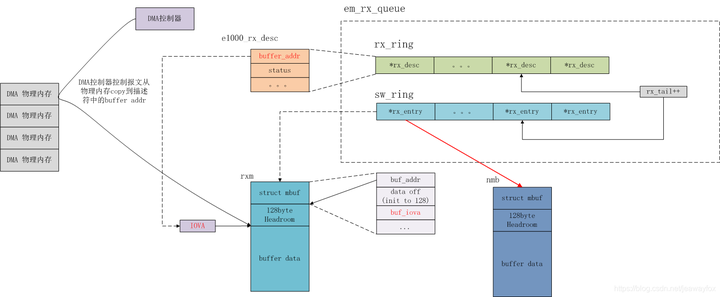
}接收报文的整理流程梳理如下图所示:
-
DMA控制器控制报文一个个写到rx ring中接收描述符指定的IO虚拟内存中,对应的实际内存应该就是mbuf;
-
接收函数用rx tail变量控制不停地读取rx ring中的描述符和sw ring中的mbuf,并申请新的mbuf放入sw ring中,更新rx ring中的buffer addr
-
最后把读取的mbuf返回给应用程序。
4、线程亲和性
一个cpu上可以运行多个线程, 由linux内核来调度各个线程的执行。内核在调度线程时,会进行上下文切换,保存线程的堆栈等信息, 以便这个线程下次再被调度执行时,继续从指定的位置开始执行。然而上下文切换是需要耗费cpu资源的的。多核体系的CPU,物理核上的线程来回切换,会导致L1/L2 cache命中率的下降。同时NUMA架构下,如果操作系统调度线程的时候,跨越了NUMA节点,将会导致大量的L3 cache的丢失。Linux对线程的亲和性是有支持的, 如果将线程和cpu进行绑定的话,线程会一直在指定的cpu上运行,不会被操作系统调度到别的cpu上,线程之间互相独立工作而不会互相扰完,节省了操作系统来回调度的时间。目前DPDK通过把线程绑定到cpu的方法来避免跨核任务中的切换开销。
线程绑定cpu物理核的函数如下:
/* set affinity for current EAL thread */
static int
eal_thread_set_affinity(void)
{
unsigned lcore_id = rte_lcore_id();
/* acquire system unique id */
rte_gettid();
/* update EAL thread core affinity */
return rte_thread_set_affinity(&lcore_config[lcore_id].cpuset);
}继续往下走:
/*
根据前面的rte_cpuset_t ,设置tid的绑定关系
存储thread local socket_id
存储thread local rte_cpuset_t
*/
int
rte_thread_set_affinity(rte_cpuset_t *cpusetp)
{
int s;
unsigned lcore_id;
pthread_t tid;
tid = pthread_self();//得到当前线程id
//绑定cpu和线程
s = pthread_setaffinity_np(tid, sizeof(rte_cpuset_t), cpusetp);
if (s != 0) {
RTE_LOG(ERR, EAL, "pthread_setaffinity_np failed\n");
return -1;
}
/* store socket_id in TLS for quick access */
//socketid存放到线程本地空间,便于快速读取
RTE_PER_LCORE(_socket_id) =
eal_cpuset_socket_id(cpusetp);
/* store cpuset in TLS for quick access */
//cpu信息存放到cpu本地空间,便于快速读取
memmove(&RTE_PER_LCORE(_cpuset), cpusetp,
sizeof(rte_cpuset_t));
lcore_id = rte_lcore_id();//获取线程绑定的CPU
if (lcore_id != (unsigned)LCORE_ID_ANY) {//如果不相等,就更新lcore配置
/* EAL thread will update lcore_config */
lcore_config[lcore_id].socket_id = RTE_PER_LCORE(_socket_id);
memmove(&lcore_config[lcore_id].cpuset, cpusetp,
sizeof(rte_cpuset_t));
}
return 0;
}继续往下走:
int
pthread_setaffinity_np(pthread_t thread, size_t cpusetsize,
const rte_cpuset_t *cpuset)
{
if (override) {
/* we only allow affinity with a single CPU */
if (CPU_COUNT(cpuset) != 1)
return POSIX_ERRNO(EINVAL);
/* we only allow the current thread to sets its own affinity */
struct lthread *lt = (struct lthread *)thread;
if (lthread_current() != lt)
return POSIX_ERRNO(EINVAL);
/* determine the CPU being requested */
int i;
for (i = 0; i < LTHREAD_MAX_LCORES; i++) {
if (!CPU_ISSET(i, cpuset))
continue;
break;
}
/* check requested core is allowed */
if (i == LTHREAD_MAX_LCORES)
return POSIX_ERRNO(EINVAL);
/* finally we can set affinity to the requested lcore
前面做了大量的检查和容错,这里终于开始绑定cpu了
*/
lthread_set_affinity(i);
return 0;
}
return _sys_pthread_funcs.f_pthread_setaffinity_np(thread, cpusetsize,
cpuset);
}绑定cpu的方法也简单:本质就是个上下文切换
/*
* migrate the current thread to another scheduler running
* on the specified lcore.
*/
int lthread_set_affinity(unsigned lcoreid)
{
struct lthread *lt = THIS_LTHREAD;
struct lthread_sched *dest_sched;
if (unlikely(lcoreid >= LTHREAD_MAX_LCORES))
return POSIX_ERRNO(EINVAL);
DIAG_EVENT(lt, LT_DIAG_LTHREAD_AFFINITY, lcoreid, 0);
dest_sched = schedcore[lcoreid];
if (unlikely(dest_sched == NULL))
return POSIX_ERRNO(EINVAL);
if (likely(dest_sched != THIS_SCHED)) {
lt->sched = dest_sched;
lt->pending_wr_queue = dest_sched->pready;
//真正切换线程到指定cpu运行的代码
_affinitize();
return 0;
}
return 0;
}
tatic __rte_always_inline void
_affinitize(void);
static inline void
_affinitize(void)
{
struct lthread *lt = THIS_LTHREAD;
DIAG_EVENT(lt, LT_DIAG_LTHREAD_SUSPENDED, 0, 0);
ctx_switch(&(THIS_SCHED)->ctx, <->ctx);
}
void
ctx_switch(struct ctx *new_ctx __rte_unused, struct ctx *curr_ctx __rte_unused)
{
/* SAVE CURRENT CONTEXT */
asm volatile (
/* Save SP */
"mov x3, sp\n"
"str x3, [x1, #0]\n"
/* Save FP and LR */
"stp x29, x30, [x1, #8]\n"
/* Save Callee Saved Regs x19 - x28 */
"stp x19, x20, [x1, #24]\n"
"stp x21, x22, [x1, #40]\n"
"stp x23, x24, [x1, #56]\n"
"stp x25, x26, [x1, #72]\n"
"stp x27, x28, [x1, #88]\n"
/*
* Save bottom 64-bits of Callee Saved
* SIMD Regs v8 - v15
*/
"stp d8, d9, [x1, #104]\n"
"stp d10, d11, [x1, #120]\n"
"stp d12, d13, [x1, #136]\n"
"stp d14, d15, [x1, #152]\n"
);
/* RESTORE NEW CONTEXT */
asm volatile (
/* Restore SP */
"ldr x3, [x0, #0]\n"
"mov sp, x3\n"
/* Restore FP and LR */
"ldp x29, x30, [x0, #8]\n"
/* Restore Callee Saved Regs x19 - x28 */
"ldp x19, x20, [x0, #24]\n"
"ldp x21, x22, [x0, #40]\n"
"ldp x23, x24, [x0, #56]\n"
"ldp x25, x26, [x0, #72]\n"
"ldp x27, x28, [x0, #88]\n"
/*
* Restore bottom 64-bits of Callee Saved
* SIMD Regs v8 - v15
*/
"ldp d8, d9, [x0, #104]\n"
"ldp d10, d11, [x0, #120]\n"
"ldp d12, d13, [x0, #136]\n"
"ldp d14, d15, [x0, #152]\n"
);
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AR眼镜光学方案_AR眼镜整机硬件定制
- 快速了解——逻辑回归及模型评估方法
- 【C++进阶06】红黑树图文详解及C++模拟实现红黑树
- Leetcode—445.两数相加II【中等】
- GD32E230C8T6《调试篇》之 (软件) IIC通信(主机接收从机) + GN1650驱动芯片 + 按键 + 4位8段数码管显示 (成功)
- MySQL5.7服务器系统变量(一)
- 云原生性能测试通用中的基本参数
- 大一C语言作业题目2
- swing快速入门(三十四)输入对话框
- 解决 BeanUtil.copyProperties 不同属性直接的复制