Python中使用Matplotlib、Seaborn和Plotly进行散点图绘制
在数据探索与呈现的旅程中,我们踏上了折线图的绘制之路。本文将继续我们的探索,聚焦于Python中三个主要绘图模块——Matplotlib、Seaborn和Plotly,探讨如何使用它们绘制生动而有力的散点图。与折线图一样,散点图是数据可视化中的重要工具,能够帮助我们观察变量之间的关系,发现规律和趋势。
在接下来的篇章中,我们将分为三个主要部分,依次介绍如何使用这三个库绘制单一散点图、对比多组数据的多散点图,以及通过实际案例展示散点图在数据解读中的应用。通过学习这些内容,我们将更全面地掌握Matplotlib、Seaborn和Plotly的散点图绘制技能,为更深入的数据分析和可视化奠定基础。
matplotlib绘制散点图
单图示例代码
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
# 示例数据
x_values = [1, 2, 3, 4, 5]
y_values = [2, 4, 6, 8, 10]
# 创建散点图
plt.scatter(x_values, y_values, label='散点图', color='blue', marker='o')
# 添加标题和标签
plt.title('简单散点图')
plt.xlabel('X轴标签')
plt.ylabel('Y轴标签')
# 添加图例
plt.legend()
# 显示图形
plt.show()
多图示例代码
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
# 生成示例数据
x = np.linspace(0, 10, 30)
y1 = np.sin(x) + np.random.normal(0, 0.2, len(x))
y2 = np.cos(x) + np.random.normal(0, 0.2, len(x))
# 创建一个包含两个子图的图形,一行两列
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
# 第一个子图(散点图)
ax1.scatter(x, y1, label='数据点', color='blue', marker='o')
ax1.set_title('散点图 1')
ax1.set_xlabel('X轴')
ax1.set_ylabel('Y轴')
ax1.legend()
# 第二个子图(散点图)
ax2.scatter(x, y2, label='数据点', color='red', marker='x')
ax2.set_title('散点图 2')
ax2.set_xlabel('X轴')
ax2.set_ylabel('Y轴')
ax2.legend()
# 显示图形
plt.show()
案例
案例概述:通过这个散点图,我们主要想了解不同种类的鸢尾花在花萼长度和花萼宽度上的分布情况,以及是否存在某些特征上的明显差异。
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
data = iris.data
target = iris.target
# 提取特征
sepal_length = data[:, 0]
sepal_width = data[:, 1]
petal_length = data[:, 2]
# 绘制散点图
plt.scatter(sepal_length, sepal_width, c=target, cmap='viridis', alpha=0.7, edgecolors='w', linewidth=0.5)
# 添加标签和标题
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.title('Scatter Plot of Iris Sepal Features')
# 显示颜色条
plt.colorbar(label='Iris Species')
# 显示图形
plt.show()
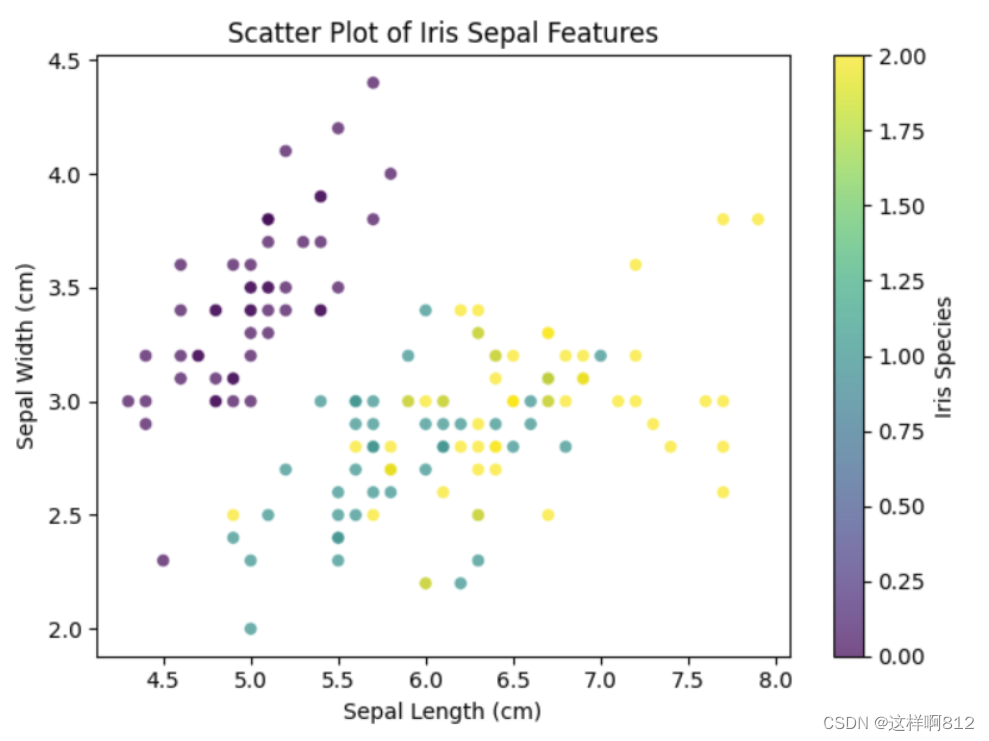
当我们使用鸢尾花数据集进行散点图可视化时,我们关注的是该数据集的花萼长度(sepal length)和花萼宽度(sepal width)两个特征。这个数据集包含了三个不同种类的鸢尾花:setosa、versicolor和virginica。
- 花萼长度和宽度: 这两个特征分别表示鸢尾花的花萼的长度和宽度。在图中,横轴表示花萼长度,纵轴表示花萼宽度。
- 颜色编码: 每个数据点的颜色代表了鸢尾花的类别。不同的颜色对应于不同的鸢尾花种类,例如setosa、versicolor和virginica。
通过观察散点图,我们可以看到不同种类的鸢尾花在花萼长度和宽度上的分布情况。这种可视化有助于我们理解不同鸢尾花种类之间的特征差异,可能在实际问题中有助于分类和分析。
结论:通过散点图可以看到三个不同种类的鸢尾花花萼长度和宽度存在较为明显的差异:
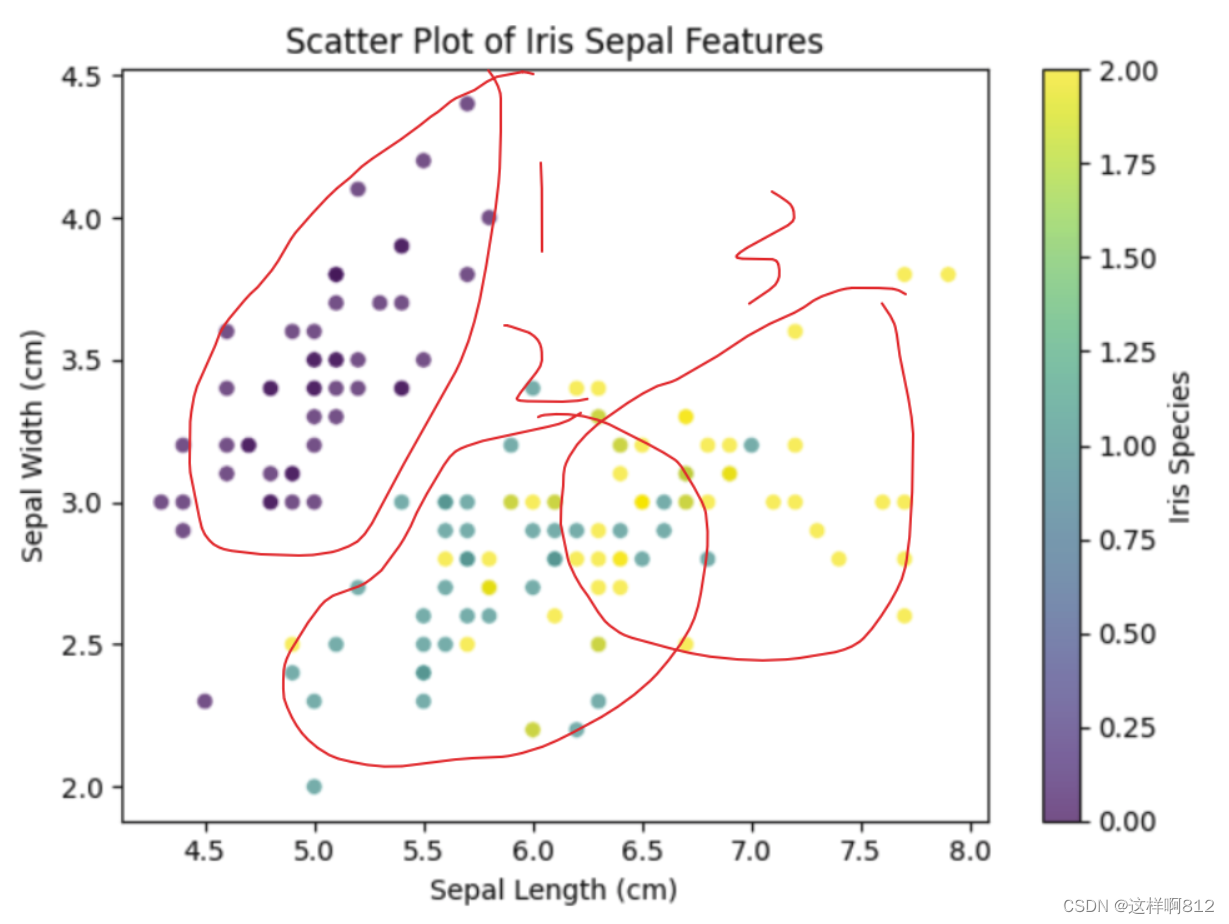
- 种类1:花萼长度集中在4.5-5.5,花萼宽度集中在3.0-4.0
- 种类2:花萼长度集中在5.5-6.5,花萼宽度集中在2.4-3.0
- 种类3:花萼长度集中在6.0-7.5,花萼宽度集中在2.6-3.4
seaborn绘制散点图
单图示例代码
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(rc={ 'font.sans-serif': ['simhei', 'Arial']}) # 处理图形显示中文乱码问题
# 生成示例数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 创建散点图
sns.scatterplot(x=x, y=y, label='散点图')
# 添加标题和标签
plt.title('Seaborn散点图')
plt.xlabel('X轴标签')
plt.ylabel('Y轴标签')
# 显示图形
plt.show()
多图示例代码
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(rc={'font.sans-serif': ['simhei', 'Arial']}) # 处理图形显示中文乱码问题
# 生成示例数据
x = [1, 2, 3, 4, 5]
y1 = [2, 4, 6, 8, 10]
y2 = [1, 3, 5, 7, 9]
# 创建一个包含两个子图的图形
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
# 在第一个子图上绘制散点图
sns.scatterplot(x=x, y=y1, ax=axes[0], label='散点图 1')
axes[0].set_title('子图 1')
axes[0].set_xlabel('X轴标签')
axes[0].set_ylabel('Y轴标签')
axes[0].legend()
# 在第二个子图上绘制散点图
sns.scatterplot(x=x, y=y2, ax=axes[1], label='散点图 2')
axes[1].set_title('子图 2')
axes[1].set_xlabel('X轴标签')
axes[1].set_ylabel('Y轴标签')
axes[1].legend()
# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()
案例
案例概述:找出4个聚类(群体)的特征。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(rc={"axes.facecolor":"#FFF9ED","figure.facecolor":"#FFF9ED"}) # 设置背景
# 准备数据 -->用pandas模块获取csv文件中的数据并进行聚类操作,此处省略
# 绘制散点图
pl = sns.scatterplot(data = data,x=data["Spent"], y=data["Income"],hue=data["clusters"])
# 显示图例
plt.legend()
# 显示图形
plt.show()
注意:scatterplot的hue参数指定分类变量为散点图中的点着色,即这里数据集中我有4个不同的聚类(4个聚类可视作4个不同类型的群体,群体内部存在共同点,因此而聚在一起,成为一个群体,而不同群体之间存在较大的差别),同一个聚类的样本采用同一种颜色标记

由上图表明各个聚类(群体)的特征:
- group 0: low spending & low income(低消费、低收入)
- group 1: low spending & low income(低消费、低收入)
- group 2: average spending & high income(中消费、高收入)
- group 3: high spending & high income(高消费、高收入)
Plotly绘制散点图
单图示例代码
import plotly.express as px
# 示例数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 创建散点图
fig = px.scatter(x=x, y=y, labels={'x': 'X轴标签', 'y': 'Y轴标签'}, title='Plotly散点图')
# 显示图形
fig.show()
多图示例代码
在plotly中,每个子图的图例是共享的,这意味着我们不能为每个子图单独设置图例位置。所以如果一定要图例分开显示,那么用matplotlib、sns库实现即可。
Plotly Express(px)方法
import plotly.express as px
from plotly.subplots import make_subplots
# 示例数据
x_data = [1, 2, 3, 4, 5]
y1_data = [2, 4, 6, 8, 10]
y2_data = [1, 3, 5, 7, 9]
# 创建子图
fig = make_subplots(rows=1, cols=2, subplot_titles=("子图 1", "子图 2"))
# 添加第一个子图
trace1 = px.scatter(x=x_data, y=y1_data)
fig.add_trace(trace1.data[0], row=1, col=1)
# 添加第二个子图
trace2 = px.scatter(x=x_data, y=y2_data)
fig.add_trace(trace2.data[0], row=1, col=2)
# 更新图表布局
fig.update_layout(
title="两个坐标系示例(px方法)",
xaxis=dict(title="X轴标签"),
yaxis=dict(title="Y轴标签"),
xaxis2=dict(title="X轴标签"),
yaxis2=dict(title="Y轴标签"),
)
# 显示图形
fig.show()
Plotly Graph Objects(go)方法
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# 示例数据
x_data = [1, 2, 3, 4, 5]
y1_data = [2, 4, 6, 8, 10]
y2_data = [1, 3, 5, 7, 9]
# 创建子图
fig = make_subplots(rows=1, cols=2, subplot_titles=("子图 1", "子图 2"))
# 添加第一个子图
trace1 = go.Scatter(x=x_data, y=y1_data, mode='markers', name="线条1")
fig.add_trace(trace1, row=1, col=1)
# 添加第二个子图
trace2 = go.Scatter(x=x_data, y=y2_data, mode='markers', name="线条2")
fig.add_trace(trace2, row=1, col=2)
# 更新图表布局
fig.update_layout(
title="两个坐标系示例(go方法)",
xaxis=dict(title="X轴标签"),
yaxis=dict(title="Y轴标签"),
xaxis2=dict(title="X轴标签"),
yaxis2=dict(title="Y轴标签"),
)
# 显示图形
fig.show()
案例
案例概述:以下散点图可以帮助观察Youtuber在不同类别下的订阅人数与视频观看次数之间的关系,并可以比较不同Youtuber之间的差异。
import plotly.express as px
# 准备数据 并完成数据预处理操作。
# 绘制散点图
fig = px.scatter(
data_new, # 存储包含散点图数据的数据集 DataFrame类型
x='subscribers', # 订阅人数
y='video views', # 视频观看次数
size='video_views_for_the_last_30_days', # 散点图中每个数据点的大小
color='category', # 散点图中每个数据点的颜色
hover_name='Youtuber', # 当鼠标悬停在散点上时显示的标签
hover_data='Country', # 鼠标悬停在散点上时显示的附加数据
size_max=40, # 散点图中单个数据点的最大大小
labels={'subscribers': 'Subscribers (in billions)', 'video views': 'Video Views (in billions)'},
color_discrete_sequence=px.colors.qualitative.Set2 # 指定散点图中离散型变量(在这里是'category'列)的颜色序列
)
# 更新布局时使用新行,便于阅读
fig.update_layout(
title_text='Subscribers vs. Video Views by Category',
xaxis_type='log', # 采用对数尺度
yaxis_type='log'
)
# 显示图形
fig.show()
size='video_views_for_the_last_30_days具体来说,每个散点代表一个Youtuber,而这个Youtuber的点的大小与其在过去30天内的视频观看次数有关。更大的点表示观看次数更多的Youtuber,而较小的点表示观看次数较少的Youtuber;
color='category'每个 Youtuber 的散点被分配一个颜色,这个颜色表示该 Youtuber 所属的类别;
hover_name='Youtuber'每个散点都与数据集中的Youtuber列相关联,这就意味着在鼠标悬停在某个点上时,将显示相应 Youtuber 的名称;
hover_data='Country'每个散点都与数据集中的Country列相关联,这就意味着当你将鼠标悬停在图中的某个点上时,除了显示 Youtuber 的名称之外,还会显示该 Youtuber 所属的国家信息;
color_discrete_sequence=px.colors.qualitative.Set2将颜色序列设置为 Plotly Express 提供的 Set2 调色板中的一组离散颜色;采用对数尺度,我们使图表更具可读性,特别是在处理订阅人数和视频观看次数这样的广泛数值范围时。
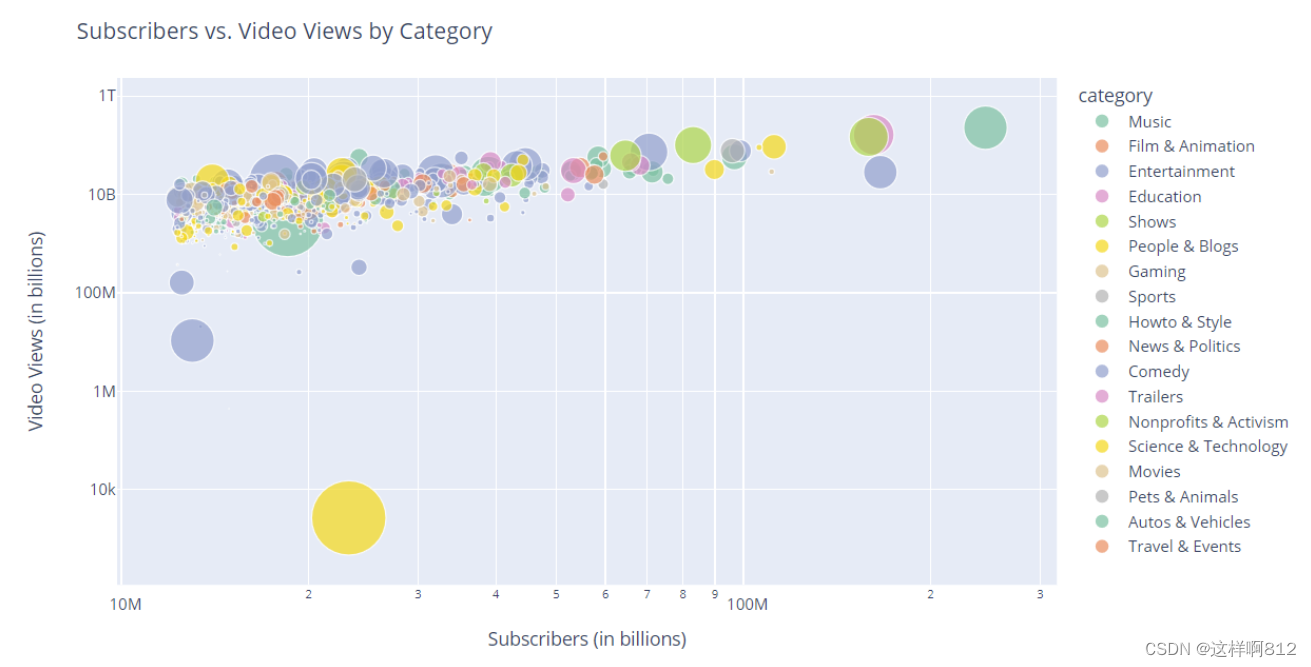
*** 以上散点图可以帮助观察Youtuber在不同类别下的订阅人数与视频观看次数之间的关系,并可以比较不同Youtuber之间的差异。***这句话怎么理解呢?我们可以这样,将散点图右侧的图例除第一个music以外都取消选中,得到下面的散点图
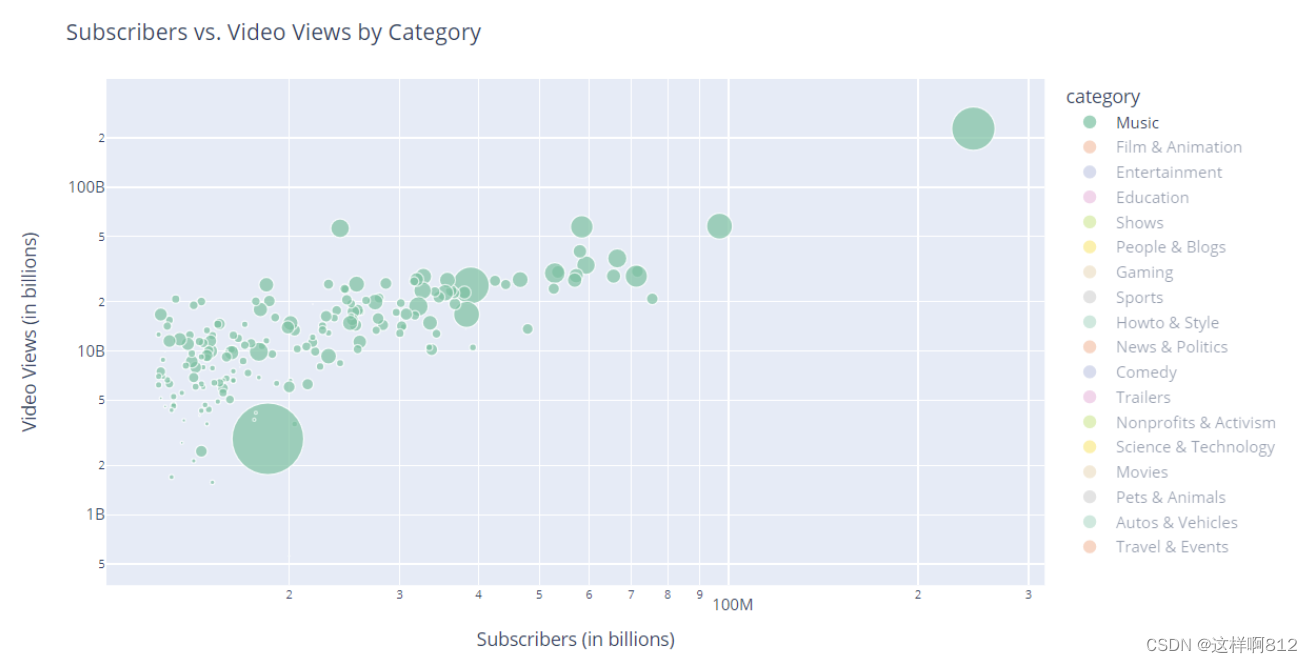
通过该散点图,我们可以看到所有YouTuber的订阅人数和视频观看次数信息,同时我们也可以看到其在过去30天内的视频观看次数。通过上图,我们可以得出在类别Music下,哪些YouTuber是最受欢迎的,哪些是近期视频播放量激增的。
然后回到原来的显示所有类别的散点图,从该图我们可以得出各个类别下的最受欢迎的YouTuber及近期视频播放量激增的YouTuber。
结语
本文深入研究了使用Matplotlib、Seaborn和Plotly绘制散点图的技术和方法。从单一图表到多图对比,再到实际案例的运用,我们通过这三个强大的绘图库展示了创建生动散点图的全过程。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 「Kafka」入门篇
- 【docker】docker-compose.yml 语法详解
- 印刷企业如何提高数字工厂管理系统的使用效率
- HTTP详解
- Linux 配置 swap 区
- ElasticSearch使用Grafana监控服务状态-Docker版
- seatunnel部署遇到的一些问题及总结
- 校园-智慧门禁(卡码脸)解决方案
- C#,入门教程(19)——循环语句(for,while,foreach)的基础知识
- 第二证券:旅游股大涨 “预热”春节黄金周