推荐算法常见的评估指标
推荐算法评估指标比较复杂,可以分为离线和在线两部分。召回、粗排、精排和重排由于定位区别,其评估指标也会有一定区别,下面详细讲解。
1 召回评价体系
召回结果并不是最终推荐结果,其本质是为后续排序层服务的,故核心在于覆盖率,而不需要追求绝对的准确率。因此精排中常用的AUC等指标,不能用来衡量召回效果。常用的召回评价指标有Hit Rate、差异率、Top-K召回率和平均点击位置等。
Hit Rate在召回中使用十分广泛。它可以衡量用户点击的物品,被包含在召回前N条结果中的概率。计算过程如公式所示,其中Dtest表示测试集,I为指示函数(Indicator function)。

差异率则用来衡量某一通路与其他通路的差异。特别是新增一路召回时,通常需要能带来一些之前没有被召回的新物品,从而提升整体覆盖率。差异率可以表达为,新增物品数量与该通路召回总数的比值。
Top-K召回率可以衡量召回结果对真实候选的覆盖率。其定义为召回前K个结果中目标物品个数,与目标物品总数的比值。计算过程如公式所示,其中di表示第i个召回结果,T为目标物品集合,N为其总数。

还可以通过用户点击的物品,在召回结果中的平均位置,来评估其效果。其他指标还有NDCG、MRR和MAP等。另外不可忽视的是,人工体验和评估召回结果,仍然是一个推荐工程师必备的素养。最后,离线评估完成后,还需要在线AB测试,从而确认最终效果。\
2 粗排评价体系
粗排评价体系主要分为三部分:召回能力、排序能力和效率指标。召回能力可以衡量粗排和精排的一致性,防止粗排排名靠前的物品无法在精排阶段透出。可以通过如下方法计算:选取一个物品候选集,同时给粗排和精排打分并排序,二者Top-K物品重合个数,除以总物品个数,即为召回率。
排序能力的评估可以采用AUC和GAUC等指标,与精排基本一致,此处不再赘述。效率指标主要包括QPS( Queries Per Seconds)和RT(Return Time)等。其中QPS通过计算每秒可以承受的请求数,来衡量模型吞吐率。RT通过计算系统返回结果的平均时间,来衡量模型耗时。
3 精排评价体系
精排相对比较纯粹,主要围绕排序能力和效率指标。其中排序能力尤为关键,是整个推荐系统个性化能力和分发精准性的核心。离线评估主要以AUC和GAUC等指标为准。在线评估则通过AB测试来实现。
AUC是衡量二分类模型优劣的一种评价指标,表示预测的正例排在负例前面的概率。AUC的详细讲解,可以参见文章?所向披靡的张大刀:万字长文深入浅出AUC。
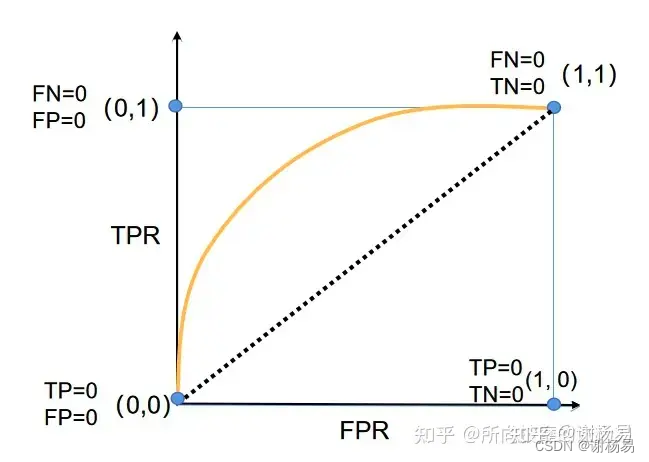
AUC表示模型将正样本排在负样本前面的概率,取值范围在0.5到1之间,是衡量模型排序能力的核心指标。但在推荐场景有一定不足。离线评估时,对不同用户的不同样本一起计算 。但在线上预测时,模型只需要保证对同一用户,正样本尽量排在负样本前面,而不用关心不同用户之间的样本顺序关系。基于此经常出现离线 上涨,但上线后业务指标并没有上涨的情况。
基于这一问题,GAUC被引入来解决上述问题。其计算过程如下公式所示。
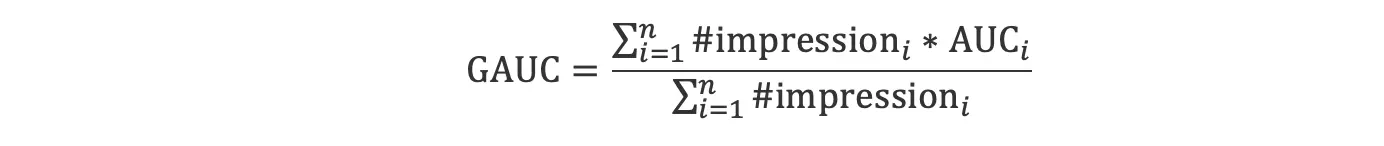
其中i表示第i个用户,n为用户总数。#imperssioni表示第i个用户的曝光数,也就是正负样本总数。AUCi表示该用户的AUC。总结下来,GAUC计算过程为,先对各用户分别计算他们的AUC,然后利用其样本数进行加权平均。GAUC的计算是用户粒度的,可以保证离在线的一致性。
4 重排评价体系
重排是推荐系统最后一层,除了要考虑算法效率外,还需要兼顾用户体验问题。其中多样性是用户体验十分重要的组成部分。其评估包括客观指标和主观体验,可以从如下角度出发:
(1)?业务指标:例如用户次日留存、用户点击率和人均订单等。通过A/B测试一般可以观测它们。
(2)?多样性指标:可以从用户和物品两个角度评估,例如平均每个用户的曝光类目数,或曝光物品同属一个类目的概率等。通常可以从类目、作者和其他标签等多个维度进行数据分析。
(3)?人工体验:抽样进行人工体验,评估多样性。这是最贴近用户的做法,但主观性偏强,不同人的评估标准不容易统一。人工体验评估,千万不可忽略。算法工程师要经常去体验自己的实际业务场景。
(4)?ILS指标:用来评估单个用户的多样性程度。在物品展现列表中,任意两个物品属于同一个类目的概率,值越低代表多样性越好。
系列文章,欢迎关注。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 软件测试基础
- apache poi_5.2.5 实现对表格单元格的自定义变量名进行图片替换
- javascript和HTML手机端实现多条件筛选的实战记录(筛选层的展示与隐藏、AJAX传输数组)
- Python列表的介绍与操作 增改查,连接,赋值,复制,清空
- Vue——计算属性
- MSPM0L1306例程学习-UART部分(2)
- Java Web项目中 JSP 访问问题
- 哪种猫粮比较好?怎样囤性价比高的主食冻干品牌 ?
- 圆中点算法
- Nuxt如何将服务测数据存储到Vuex中