全志V853 NPU开发之Demo使用说明
上一章节中配置 NPU 扩展包后可以在?menuconfig?里看到两个 Demo 测试应用程序。这里我们来介绍一下怎么使用这两个 Demo。
YOLOV3
在 NPU Package 中我们提供了一个较为完整的 YOLOV3 Demo 作为测试,程序源码位于:
openwrt/package/npu/yolov3/src
这个 Demo 相较于 Lenet 的 Demo 增加了图片前处理、数据处理、后处理与图片打框的功能。可以将上传的图片物体打框标记并输出打框后的图片。
首先我们在?menuconfig?里选中?YOLOV3?的相关选项

可以看到这里选择了?yolov3?会出现?yolov3-model?这个选项,这个选项是提供一个测试使用的模型到系统中,文件较大,如果编译打包出现错误请参阅【FAQ 常见问题 - V853】查看或参考以下解决方法。
报错时的错误提示:

解决方法:修改板级目录下面的 sys_partition.fex 的 rootfs.fex 节点?45360 ==> 95744?。
测试 YOLOV3
首先我们准备一张图片,并把图片转换为?416*416?分辨率的图片。
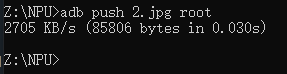
使用?ADB?将图片下载到?root?目录
adb push 2.jpg root
在开发板上,切换文件夹到?root?文件夹,使用?ls?列出看看有没有?2.jpg?这个图片文件
cd /root
ls

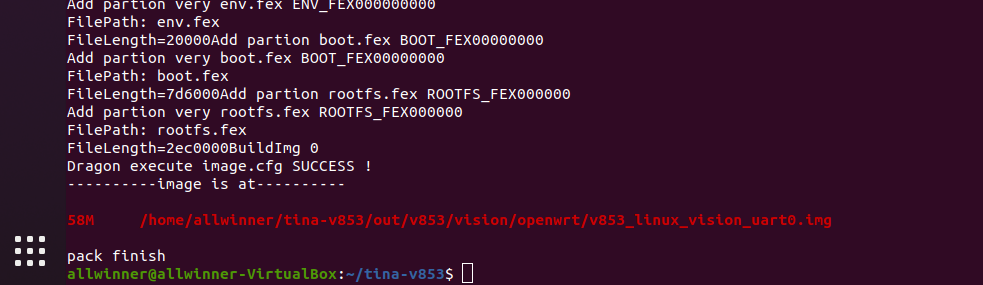
可以看到,这里已经下载成功了,接下来运行?yolov3,格式是:
yolov3 <模型文件> <图片文件>
之前我们选中了?yolov3-model?模型包,模型已经安装到/etc/models/yolov3_model.nb了,所以在这里我们直接可以使用这个模型,执行
yolov3 /etc/models/yolov3_model.nb 2.jpg
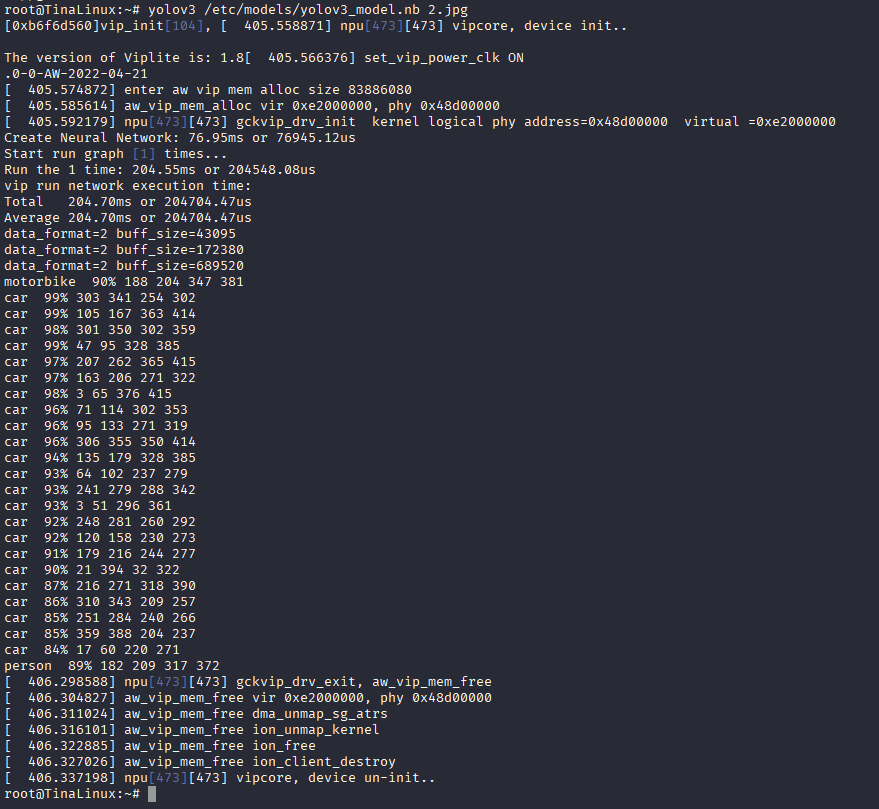
可以看到识别到了?car和motorbike?,此时?ls?可以看到打标完成的图片?yolo_v3_output.bmp
可以使用?adb?上传图片到主机查看。
adb pull /root/yolo_v3_output.bmp
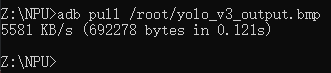
打开图片即可查看标注情况

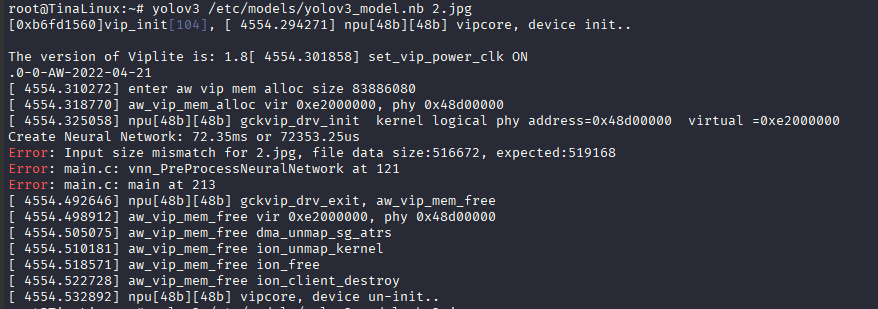
如果运行出现错误,请确认图片格式是否为jpg,图片分辨率是否为?416x416
Error: Input size mismatch for 2.jpg, file data size:516672, expected:519168
Lenet
如果说深度学习有什么 HelloWorld,那一定是 Lenet。
在 NPU 扩展包中提供了一个 Lenet 的 Demo 程序。
这个 Demo 较为基础,演示了模型转换生成的模板代码如何集成到 Tina Linux 里。由于没有前处理与后处理,所以输入数据与输出数据均为二进制?tensor?文件。也正因为如此,所以可以将输出的?tensor?与仿真输出的?tensor?进行对比,验证是否有错误。
如果想要更完善的包括前处理与后处理的 Demo 可以查看?yolov3?Demo。
我们先?make menuconfig?找到 Lenet 选项,这里提供?lenet?主程序与?lenet-model?模型两个包,可以只选中主程序使用自己转换的模型测试。

在这里我们就使用扩展包提供的模型进行验证。先去 扩展包里找到测试数据?lenet_input_0.dat?并上传到开发板。
使用?ls?列出上传的数据

使用?lenet?命令运行测试模型
lenet <模型文件> <数据文件>
lenet /etc/models/lenet_model.nb lenet_input_0.dat

可以看到这里输出了?tensor?output0_10_1.dat?文件

如果需要实现图片的输入与输出,需要基于这个模板增加图片前处理与数据后处理部分的代码。前处理将图片转为?tensor?输入,后处理解析?tensor?输出数据。
vpm_run
vpm_run 软件包是用于在开发板上测试运行的工具,一般用于开发板测试推理。而且可以通过参考 vpm_run 的流程,用户可以开发自己的 AI 应用程序,所以它可以看成是一套基于 AI 应用开发模板,只不过,它有自己的一些特点,
-
vpm_run 是可以作为一个通用模型运行环境,程序不需要修改,可以运行任何部署正确的NBG 模型文件.
-
vpm_run 基于 viplite 网络层 API,程序短小精悍。
-
vpm_run 具备默认的后处理程序 TOP5, 如果不满足你的算法要求,可以自行扩展。
我们先?make menuconfig?找到 vpm_run 选项,勾选,打包编译。这里我们同样勾选 lenet 选项,待会测试 vpm_run 使用,提供模型。
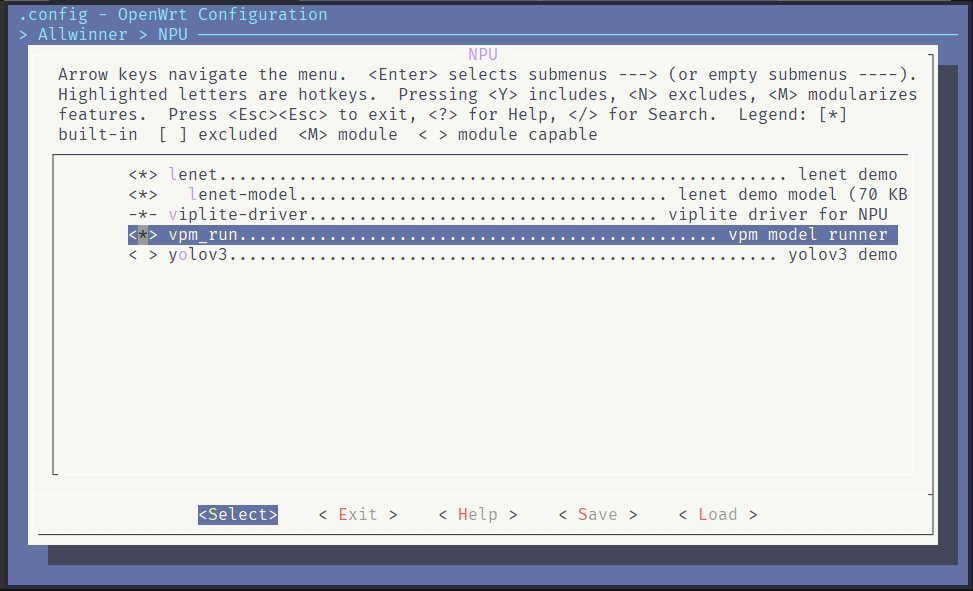
在开发板中,可以运行?vpm_run?查看支持的操作
vpm_run

可以看到,他需要一个?sample.txt?文件,定义如下
[network] # 模型的名称
./lenet_model.nb
[input] # 输入数据
./lenet_input_0.dat
[golden] # 标准输出数据,会与输出数据比对检查是否有偏差(可选)
./lenet_input_golden.dat
[output] # 输出数据
./lenet_output_data.dat
其中的?golden?标签代表的是标准输入,可以看作一个满分的输出,这个输出可以用预推理阶段生成的输出文件,也可以用仿真输出的文件。vpm_run 会比对这两个文件查看是否有错误产生。
vpm_run sample.txt
有些模型需要的内存较大,需要修改更大的内存,可以打开?openwrt/package/npu/vpm_run/src/vpm_run.c?修改分配的内存大小(viip_init(内存大小))。
多输入/多网络配置
多输入sample.txt文件配置,当只有一个nb模型但需要有两个输入时:
``` [network] ./network_binary.nb [input] ./iter_0_images_262_out0_1_3_640_640.tensor ./input_0.dat
多网络sample.txt文件配置,当需要一次运行多个nb模型时,不同nb以标签为界限:
```
[network]
./network_binary.nb
[input]
./iter_0_images_262_out0_1_3_640_640.tensor
[network]
./network_binary.nb
[input]
./input_0.dat
常见问题
① 按照官网上的教程在V853上部署?lenet?模型,使用?vpm_run sample.txt?的时候出现segmentation fault?,如下图所示
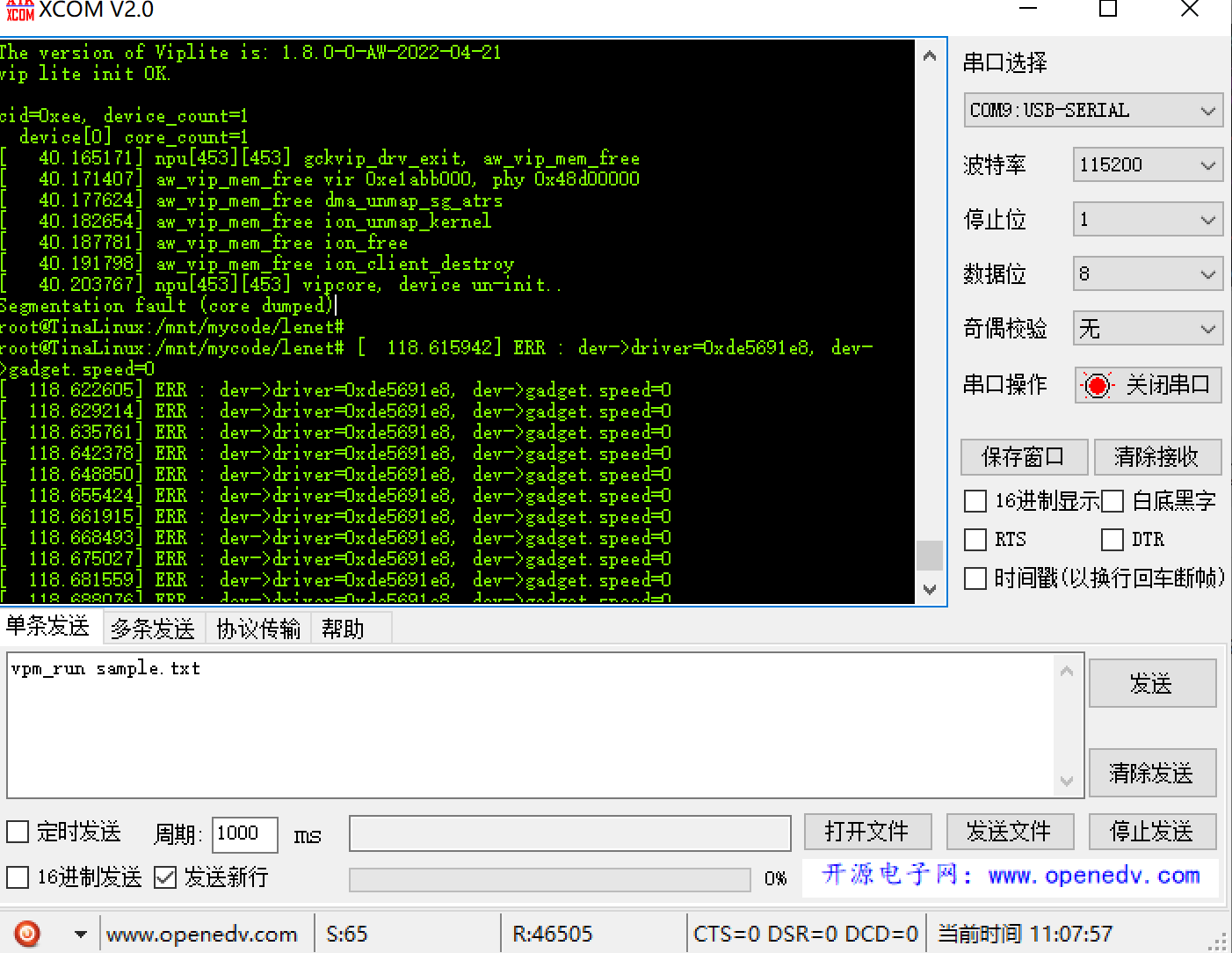
读取sample.txt失败,检查一下vpm_run.c源码,查看获取文件名的换行符类型。
尝试将把sample.txt文件中的空格去掉,这是导致segmentation fault错误的原因之一。
windows操作系统的换行为:CR/LF或\r\n,而Linux的换行符为LF或\n。
② NPU模块vpm_run例程运行时sample.txt读取错误
编写sample.txt文件:
``` [network] ./network_binary.nb [input] ./iter_0_images_262_out0_1_3_640_640.tensor
将模型、输入文件、vpm_run例程传入板端
运行vpm_run例程:
./vpm_run -s sample.txt
报错LOG如下:
unsupported input file type=tenso. error input file type segmentation fault ```
报错为读取sample.txt失败,检查一下vpm_run.c源码,查看获取文件名的换行符类型,多是由于空格字符问题引起。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux下MySQL的安装部署
- 在 iPhone 手机上恢复数据的 7 个有效应用程序
- 【CmakeLists】规范编写CmakeLits文件,以查找链接ZMQ与OpenCV库为例
- Docker(十二)安全
- C++笔记(二)
- 53.最大子数组和(前缀和、动态规划,C解法)
- elasticsearch 中热词使用遇到的坑
- 设计模式-责任链模式
- Typescript面向对象
- 环境搭建及源码运行_java环境搭建_mysql安装