User-Agent(用户代理)是什么?
User-Agent(用户代理)是什么?
User-Agent 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用的操作系统版本、CPU 类型、浏览器版本等信息。而网站服务器则通过判断 UA 来给客户端发送不同的页面。
网络爬虫使用程序代码来访问网站,而非人类亲自点击访问,因此爬虫程序也被称为“网络机器人”。绝大多数网站都具备一定的反爬能力,禁止网爬虫大量地访问网站,以免给网站服务器带来压力。这里要学习的 User-Agent 就是反爬策略的第一步。
网站通过识别请求头中 User-Agent 信息来判断是否是爬虫访问网站。如果是,网站首先对该 IP 进行预警,对其进行重点监控,当发现该 IP 超过规定时间内的访问次数, 将在一段时间内禁止其再次访问网站。
服务器只想给浏览器提供服务,而不想给爬虫程序提供服务,使用 UA 就是要伪装成浏览器向服务器发送请求并获取相应
获取User-Agent 请求头
想要知道自己的浏览器的User-Agent 请求头是什么,可以通过以下方式获得:
- 打开 edge
- 随便一个页面,按
F12,打开开发者工具 - 点击“网络”或“network”
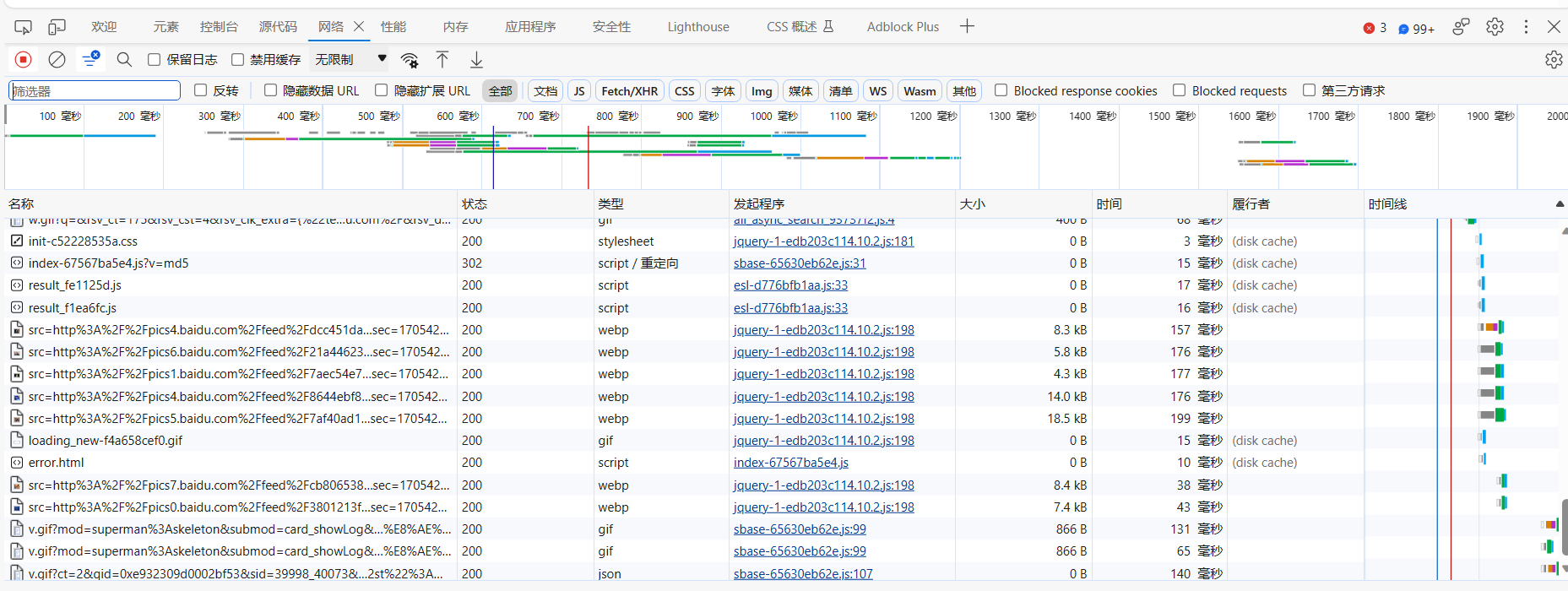
- 按
F5刷新页面,可以看到浏览器向服务器发送的全部请求 - 随便找到一个请求,点击,找到User-Agent 后面的内容,如果需要使用,复制即可
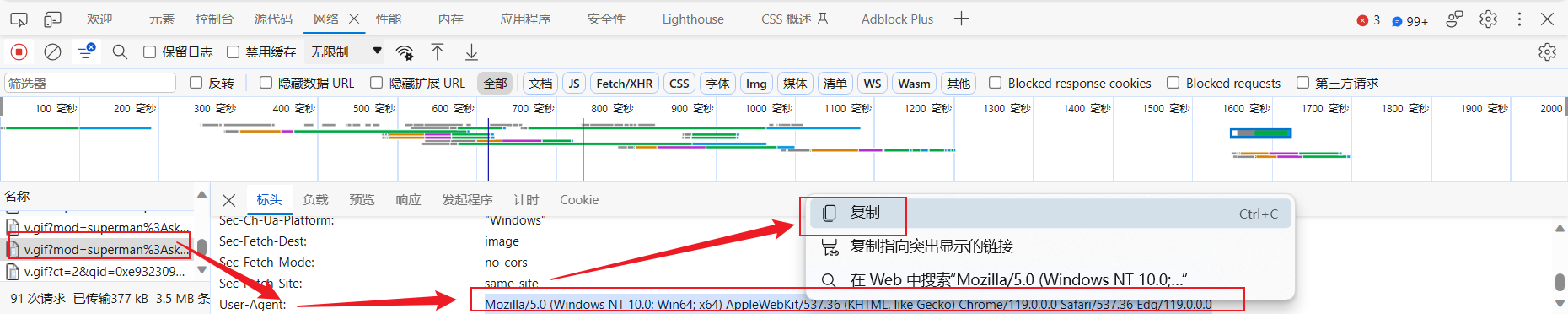
爬虫程序的 UA信息
通过向 HTTP 测试网站(http://httpbin.org/)发送 GET 请求来查看请求头信息,从而获取爬虫程序的 UA。代码如下所示:
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get')
html = response.read().decode('utf-8')
print(html)
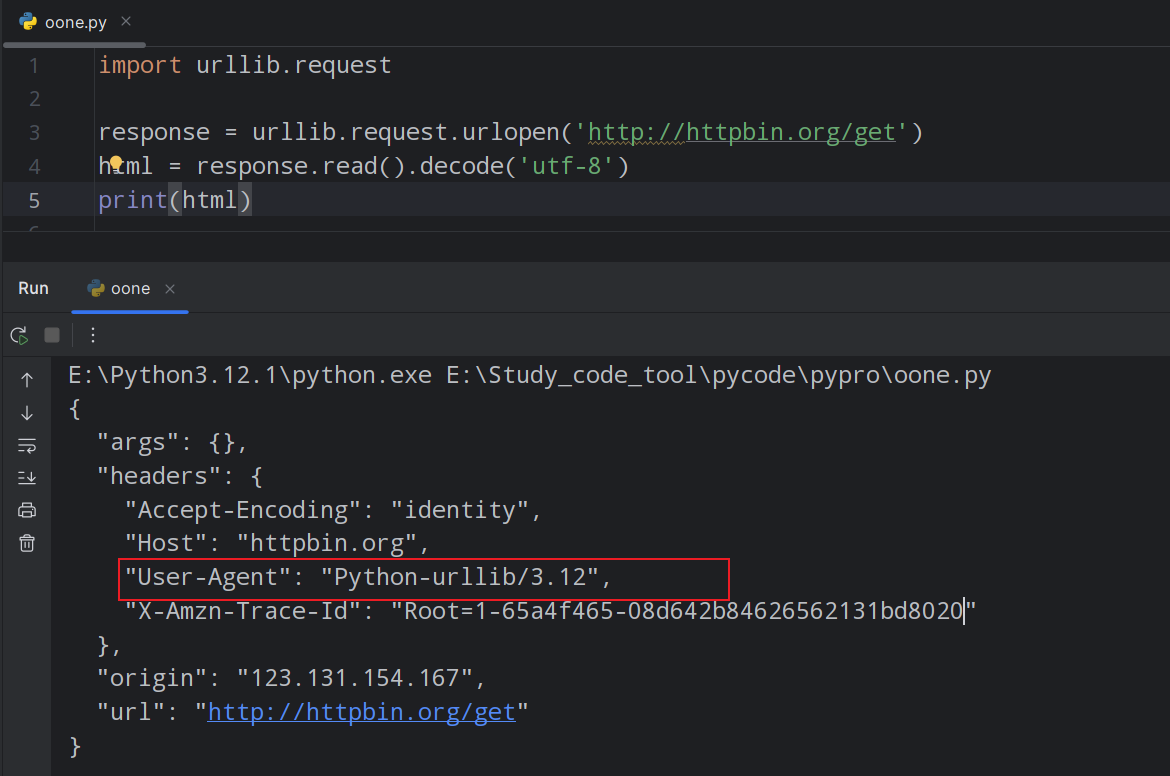
从输出结果可以看出,User-Agent 竟然是 Python-urllib/3.12,这显然是爬虫程序访问网站。因此就需要重构 User-Agent,将其伪装成“浏览器”访问网站。
注意:httpbin.org这个网站能测试 HTTP 请求和响应的各种信息,比如 cookie、IP、headers 和登录验证等,且支持 GET、POST 等多种方法,对 Web 开发和测试很有帮助。
重构爬虫UA信息
使用urllib.request.Request()方法重构 User-Agent 信息,代码如下所示:
from urllib import request
# 定义变量:URL 与 headers
url = 'http://httpbin.org/get' # 向测试网站发送请求
# 重构请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'}
# 1、创建请求对象,包装ua信息
req = request.Request(url=url, headers=headers)
# 2、发送请求,获取响应对象
res = request.urlopen(req)
# 3、提取响应内容
html = res.read().decode('utf-8')
print(html)
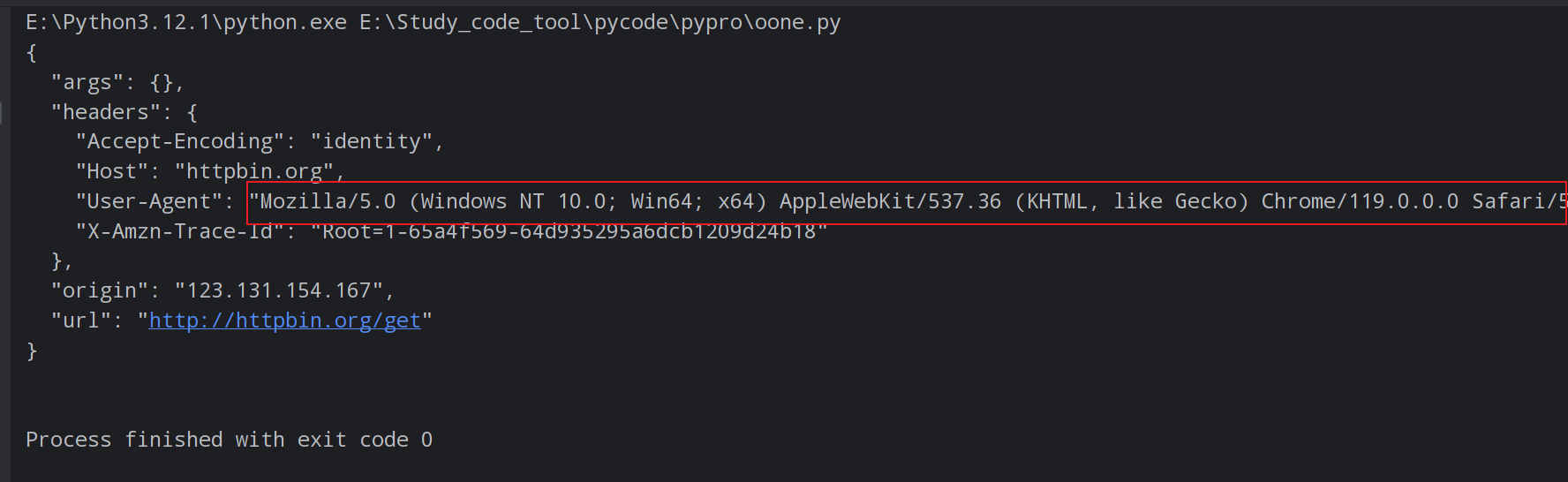
上述代码重构了 User-Agent 字符串信息,这样就解决了网站通过识别 User-Agent 来封杀爬虫程序的问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Shell命令】常用命令使用合集(由AI助力,持续更新)
- 电源模块测试之充电桩电源测试项目
- 【SSH】Linux常用命令
- vue中 ref 和 $refs的使用
- 产品电子画册用什么工具可以轻松制作
- xtu oj 1329 连分式
- 【C++杂货铺】三分钟彻底搞懂如何使用C++中max函数
- CentOS7 修改主机名
- window11后台服务优化记录
- Spring Cloud + Vue前后端分离-第10章 基于阿里云OSS的文件上传