《手把手教你》系列基础篇之4-python+ selenium自动化测试-xpath使用(详细教程)
1. 简介
俗话说:磨刀不误砍柴工,因此在我们要开始写自动化脚本之前,我们先来学习和了解几个基本概念,在完全掌握了这几个概念之后,有助于我们快速上手,如何去编写自动化测试脚本。
元素,在这个教程系列,我们说的元素之网页元素(web element)。在网页上面的文本输入框,按钮,多选,单选,标签,和文字都叫元素,总之,凡是能在页面显示的对象都可以作为页面元素对象。
元素定位,有时候也叫Locator,一个HTML页面元素,可以用很多方法去描述这个元素的位置。打个比方,生活中地址,一个大厦,正常的地址是 xx省xx市xx区xx街道xxx号,这个具体描述就是这个大厦的Locator。同样的道理,一个网页元素,也有位置,也可以通
过一些手段或者表达式去描述这个元素在页面对应的位置。
XPath,XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力,XPath 很快的被开发者采用来当作小型查询语言。
Selenium一共有八种元素定位方法,这个在上一篇文章中已经提到过,其中在实际开发自动化脚本过程中,XPath的使用是最多的、比较好用的一种方法,所以本文就着重来介绍如何通过XPath来元素定位。学习了XPath元素定位后,其他7中方法,很容易理解,甚至
已经学会了其中好几种方法。
1.1 XPath工具安装
????? 为了提高抓取元素XPath的,我推荐在Firefox上安装一个firepath的插件,这个插件,可以帮我们快速获取网页元素的XPath表达式。
1.???打开火狐浏览器,如果没有安装,下载默认安装
2.???点击右上角,菜单-附件组件-扩展
3.???在搜索所有附件组件文本输入框输入:firebug
4.???找到Firebug,点击 安装。重复步骤3和4,搜索和安装FirePath。
5.???安装好了之后,会在火狐浏览器右上角显示一个虫子的图标。
1.2 XPath工具简单使用
我们用定位百度首页的搜索输入框这个元素定位来演示。
1.???打开百度首页
2.???鼠标定位到搜索输入框
3.???右键鼠标,选Inspect in FirePath
4.???打开界面如下图
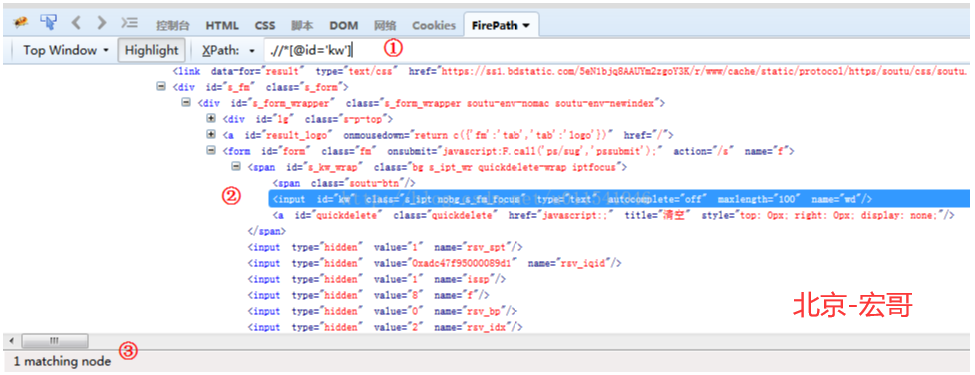
①FirePath自动推荐该元素的XPath表达式
②该元素节点的详细信息,XPath表达式选取重点区域
③找到一个匹配元素
?????? 一般来说,自动推荐的XPath表达式定位不够精确。我们大部分时候需要去步骤2中,找出能够识别这个唯一元素的节点信息。刚好上面通过id=kw只能找到一个匹配的元素,说明这个XPath可用,看起来也简洁。实际项目中,可能XPath表达式写得很长,或者附
近节点信息好多相同,不太好能够快速找到一个唯一的节点信息去定位这个目标元素。接下来,我介绍几种比较实用的XPath定位技巧,基本上能定位到所有的网页元素。
1.3 XPath定位技巧之text()方法
以百度首页右上角“新闻”定位举例
XPath如下图

1.4 XPath定位技巧之contains()方法
????? 有时候,我们不喜欢写很长的XPath表达式,而且节点信息里面,有些信息是动态的,每次都获取都不一样,这个时候contains()方法就很好用。
JD首页左侧电脑菜单举例
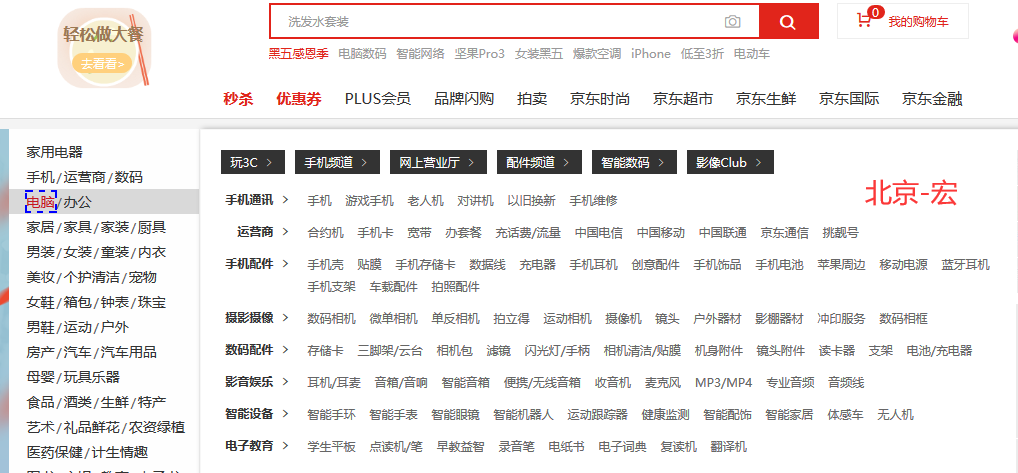
XPath写法推荐,这里用contains()方法来定位

这里href = //diannao.jd.com, 如果我觉得这个href太长,我只取关键字diannao,利用contains()方法来定位就方便多了,推荐电脑这个元素的XPath://*/a[contains(@href,'diannao')]
1.5 相对XPath路径写法
????? 有时候,我们遇到目标元素节点的信息很少,不足够用来精确定位到目标元素,这个时候,我们就需要考虑,利用目标元素上下附件节点,通过确定附件的节点从而确定目标元素,这种方式就叫相对路径。
这里用火狐浏览器百度首页的一个单选按钮来举例;

火狐浏览器上firepath给出的推荐表达式是:
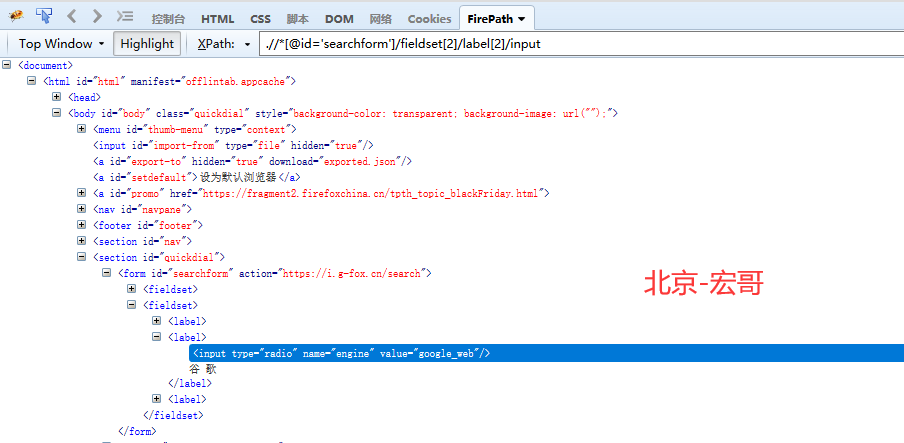
这里推荐的XPath是根据目标元素节点中id信息来定位的,这个通过id就能定位,当然好。有时候,如果这个id不能作为参考值,我们需要利用相对定位方法来定位这个新闻标题前面的单选按钮;
1)先根据value = google_web 或者text()=谷歌来定位“谷歌”这个标签。
2)根据相对定位来确定“谷歌”前面的这个radio按钮。
3)XPath的写法是:.//*/label[@value='google_web']/
此前使用webdriver对浏览器进行了一些基本操作,可以说是基本接触了这个工具了,接下来就应该做更多事情了。
打开了网页,接下来就需要对网页中的内容进行操作了,例如定位网页中的元素、读取网页元素中的内容、对内容进行操作。
2.小结
XPath 是一种在 XML 文档中定位元素的语言。因为 HTML 可以看做 XML 的一种实现,所以 selenium用户可是使用这种强大语言在 web 应用中定位元素。
2.1 绝对路径定位:
XPath 有多种定位策略,最简单和直观的就是写元素的绝对路径。如果仍然把一个元素看做一个人的话,那么现在有一个人,他没有任何属性特征,那么这个人一定会存在于某个地理位置,如:xx 省 xx 市xx 区 xx 路 xx 号。那么对于一个元素在一个页面当中也会有
这样的一个绝对地址。
参考 baidu.html 前端工具所展示的代码,我们可以用下面的方式来找到百度输入框和搜索按钮。
find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span/input")
find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span[2]/input")
find_element_by_xpath()方法用于 XPath 语言定位元素。XPath 的绝对路径主要用标签名的层级关系来
定位元素的绝对路径。最外层为 html 语言,body 文本内,一级一级往下查找,如果一个层级下有多个相同的标签名,那么就按上下顺序确定是第几个,div[2]表示第二个 div 标签。
2.2 利用元素属性定位:
除了使用绝对路径的以外,XPath 也可以使用使素的属性值来定位。同样以百度输入框和搜索按钮为例:
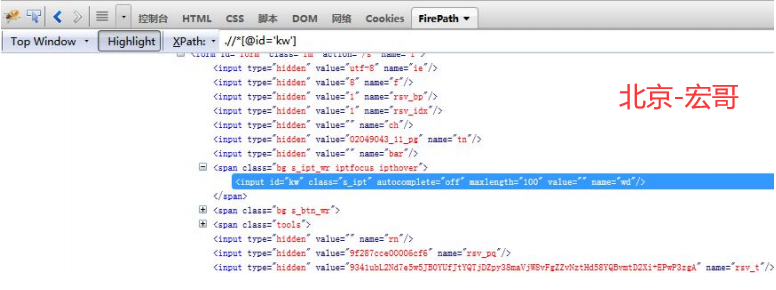
find_element_by_xpath("//input[@id='kw']")
find_element_by_xpath("//input[@id='su']")
//表示当前页面某个目录下,input 表示定位元素的标签名,[@id='kw'] 表示这个元素的 id 属性值等于kw。下面通过 name 和 class 属性值来定位。
find_element_by_xpath("//input[@id='wd']")
find_element_by_xpath("//input[@class='s_ipt']")
find_element_by_xpath("//*[@class='bg s_btn']")
如果不想指定标签名也可以用星号(*)代替。当然,使用 XPath 不仅仅只局限在 id、name 和 class 这三个属性值,元素的任意属性值都可以使用,只要它能唯一的标识一个元素。
find_element_by_xpath("//input[@maxlength='100']")
find_element_by_xpath("//input[@autocomplete='off']")
find_element_by_xpath("//input[@type='submit']")
2.3 层级与属性结合:
如果一个元素本身并没有可以唯一标识这个元素的属性值,我们可以找其上一级元素,如果它的上级
有可以唯一标识属性的值,也可以拿来使用。参考 baidu.html 文本。
…… <form id="form" class="fm" action="/s" name="f"> <input type="hidden" value="utf-8" name="ie"> <input type="hidden" value="8" name="f"> <input type="hidden" value="1" name="rsv_bp"> <input type="hidden" value="1" name="rsv_idx"> <input type="hidden" value="" name="ch"> <input type="hidden" value="02.." name="tn"> <input type="hidden" value="" name="bar"> <span class="bg s_ipt_wr"> <input id="kw" class="s_ipt" autocomplete="off" maxlength="100" value="" name="wd"> </span> <span class="bg s_btn_wr"> <input id="su" class="bg s_btn" type="submit" value="百度一下"> </span> ……
假如百度输入框本身没有可利用的属性值,我们可以查找它的上一级属性。比如,“小明”刚出生的时候没有名字,没上户口(没身份证号),那么亲朋好友来找“小明”可以先到小明的爸爸,因为他爸爸是有很多属性特征的,找到了小明的爸爸,抱在怀里的一定就是小
明了。通过 XPath 描述如下:
find_element_by_xpath("//span[@class='bg s_ipt_wr']/input")
find_element_by_xpath("//span[@class='bg s_btn_wr']/input")
span[@class='bg s_ipt_wr'] 通过 class 属性定位到是父元素,后面/input 也就表示父元素下面标签名为input 的子元素。如果父元素没有可利用的属性值,那么可以继续向上查找“爷爷”元素。
find_element_by_xpath("//form[@id='form']/span/input")
find_element_by_xpath("//form[@id='form']/span[2]/input")
我们可以通过这种方法一级一级的向上打找,直到找到最外层的<html>标签,那么就是一个绝对路径的写法了。
2.4 使用逻辑运算符
如果一个属性不能唯一的区分一个元素,我们还可以使用逻辑运算符连接多个属性来区别于其它属性。
…… <input id="kw" class="su" name="ie"> <input id="kw" class="aa" name="ie"> <input id="bb" class="su" name="ie"> ……
如上面的三行元素,假如我们现在要定位第一行元素,如果使用 id 将会与第二行元素重名,如果使用class 将会与第三行元素的重名。那么如果同时使用 id 和 class 就会唯一的标识这个元素。那么这个时候就可以通过逻辑运算符号连接。
find_element_by_xpath("//input[@id='kw' and @class='su']/span/input")
当然,我们也可以用 and 连接更多的属性来唯一的标识一个元素。
我们在本书的第一章中介绍的 Firebug 前端调试工具和 FirePath 插件可以方便的辅助 XPath 语法。
打开 FireFox 浏览器的 FireBug 插件,点击插件左上角的鼠标箭头,再点击页面上需要定位的元素,在元
素行上右键弹出快捷菜单,选择“复制 XPath”,将会获得当前元素的 XPath 语法,如图:

FirePath插件的使用就更加方便和快捷了,选中元素后,直接在XPath的输入框中生成当前元素的XPath语法,如图:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI论文范文:AIGC中的图像转视频技术研究
- henauOJ 1081: 超简单的归并
- C++2种方式方法实现题目:最大拓扑网络。
- 案例109:基于微信小程序的高校寻物平台
- C++实现单例模式
- 写在2023年末,软件测试面试题总结
- React 实现 Step组件
- 深入了解CSS
- openssl3.2/test/certs - 006 - trust variants: +anyEKU -anyEKU
- 基于alibaba druid的血缘解析工具