【MySQL】Sql优化之索引的使用方式(145)
索引分类
1.单值索引
单的意思就是单列的值,比如说有一张数据库表,表内有三个字段,分别是 id name numberNo,我给name 这个字段加一个索引,这就是单值索引,因为只有name 这一列是索引;
一个表可以有多个单值索引,我不光可以设置name ,我也可以把numberNo设置成索引,或许更多;
2.唯一索引
顾名思义,就是不能重复,比如age就不能被设置为唯一索引,因为年龄肯定是不唯一的,小明18岁,有可能小李也是18岁,这就重复了,所以age这一列不能被设置成唯一索引;
一般唯一索引就是Id;
3.复合索引
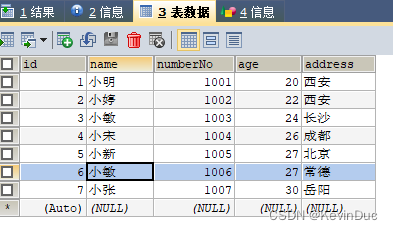
由多个列构成,相当于书的二级目录,比如我找“小敏”,它就先去X里面找,然后再去xiao里面去找,找两次;
这个时候我把name跟numberNo它两个共同组成一个复合索引,意思就是,我先根据name找人,如果名字重复了,我再根据numberNo去找;
复合索引不一定必须两个列在一起使用,比如找小婷,这个表里面就一个小婷,就没有必要再去找numberNo进行筛选;
如图:表:student_data
创建索引的方式一:
语法:careate 索引类型 索引名 on 表 (字段)
1.创建单值索引:单值索引索引类型就是index;
CREATE INDEX name_index ON student_data(NAME)
1.1查看索引:
SHOW INDEX FROM student_data

2.创建唯一索引:创建的该字段值必须唯一
CREATE UNIQUE INDEX numberNo_index ON student_data(numberNo)
讲解:unique 与 index 都是索引类型,这里我们就假设name是唯一的,创建方法跟上面一样,无非就多加了一个unique,去掉unique就是单值索引;
3.创建复合索引
CREATE INDEX name_numberNo_index ON student_data(NAME,numberNo)
//程序会自动检测,如果你后面参数只有一个,那就判定你为单值,如果是一个以上,就判定你是复合!
3.1 查看索引:
SHOW INDEX FROM student_data
3.2查看索引执行计划:EXPLAIN 
4.删除索引:
DROP INDEX name_index ON student_data
5.查看索引:
SHOW INDEX FROM student_data

SQL性能问题
1.分析SQSL的执行计划:EXPLAIN
通过explain,可以模拟SQL优化器执行SQL语句,从而让开发人员知道自己编写的状况;
查询执行计划:explain+SQL语句;
EXPLAIN SELECT * FROM student_data

id:顾名思义就是查询编号
select_type:查询类型
table:你在操作哪一张表
type:类型
key:实际使用的索引,你到底用了哪些索引
possible_keys:预测你用到了哪些索引,假设你用了八个索引,它这里就会显示八个,但是实际有效的只有五个,所以在key显示就是五个!
key_len:实际使用索引的长度;
ref:表和表之间的引用关系;
rows:通过索引查询到的数据量;
Extra:额外的优化信息
创建索引的方式二:
语法:alter table 表名 索引类型 索引名(字段)
1.创建单值索引
ALTER TABLE student_data ADD INDEX name_index(NAME);
查看索引
SHOW INDEX FROM student_data

2.创建唯一索引
ALTER TABLE student_data ADD UNIQUE INDEX numberNo_index(numberNo)
讲解:照猫画虎,跟上放基本一致,假设numberNo字段是唯一不可重复
3.创建复合索引
ALTER TABLE student_data ADD INDEX name_numberNo_index(NAME,numberNo)
讲解:先NAME就是先根据NAME查,再去根据numberNo查,这个顺序是有意义的!
值得注意的是,两个创建方式的效果是一样的,任选其一,均不需要事物的提交(commit),因为两者都是DDL语句,程序遇到DDL会自动提交,但是你写了也不报错,就是什么也没提交而已;
事物只对DML语句进行操作,也就是增删改操作,这个需要理解!
注意:
如果一个字段是primary key(主键),则该字段默认就是主键索引,即便你没有给他加索引,他也是主键索引!
主键索引与唯一索引基本相似,区别就是,值不能为Null,而唯一索引可以!
主键索引:值不能重复 值不能为null
唯一索引:值不能重复 值可以为null
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 对接钉钉机器人发送钉钉通知
- 【开源软件】2022年最佳开源软件-排名第一:AlmaLinux
- uml超市进销存管理系统 实验报告.doc
- 在 Windows 环境下使用 Python 编写程序、打包 Docker 并部署
- Java实现限流算法
- ssm基于JSP的游戏虚拟道具交易网站的设计论文
- 《Qt开发》MDI应用程序
- 小型洗衣机什么牌子好又便宜?实用的小型洗衣机测评
- vue 中 watch 、computed、 watchEffect 区别
- sessionStorage可以在多个Tab之间共享数据吗?