【ELK 学习】ElasticSearch
发布时间:2024年01月12日
ELK:ElasticSearch存储,Logstash收集,Kibana展示
版本较多,使用时需要版本匹配,还需要和mysql版本匹配(elastic官网给了版本对应关系)
本次使用的版本es6.8.12
filebeat 轻量级的数据收集工具
ElasticSearch为文档搜索产生的
分布式文档搜索,lucene单线程搜索的组合
ElasticSearch也支持python
0.作用
大数据时代产生的应用:
1.分布式存储:hdfs
2.分布式计算:
离线计算:MapReduce、hive
实时计算:spark、Flink
3.分布式搜索引擎:ElasticSearch
海量数据、近实时处理
1. 核心概念
Index,Type,Document
对应到数据库:
数据库database=Index
表table=Type
一条记录row=Document
Index下面可以存储不同的type,但是大部分要相同,type是作为一个字段存储的(7.0之后不建议使用)
8.0之后一个index只能存储相同 type 的数据
shard,replica
hdfs的存储是物理切块(block)
primary shard 切片存储
replica shard 容错存储,每个切片都有一个容错副本
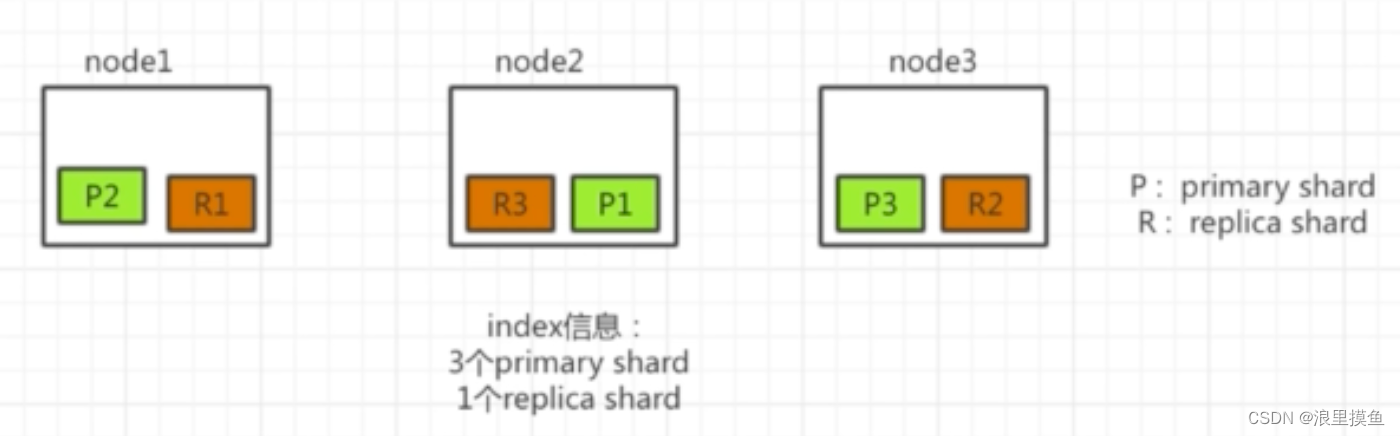
切片自己和容错存在不同的服务器(节点)上(部署集群)
2. 下载安装
windows版本
bin目录下,elasticsearch.bat点击启动
3. es的基本操作
Elasticsearch提供了基于JSON的DSL来定义查询
DSL语法
检查集群健康状况
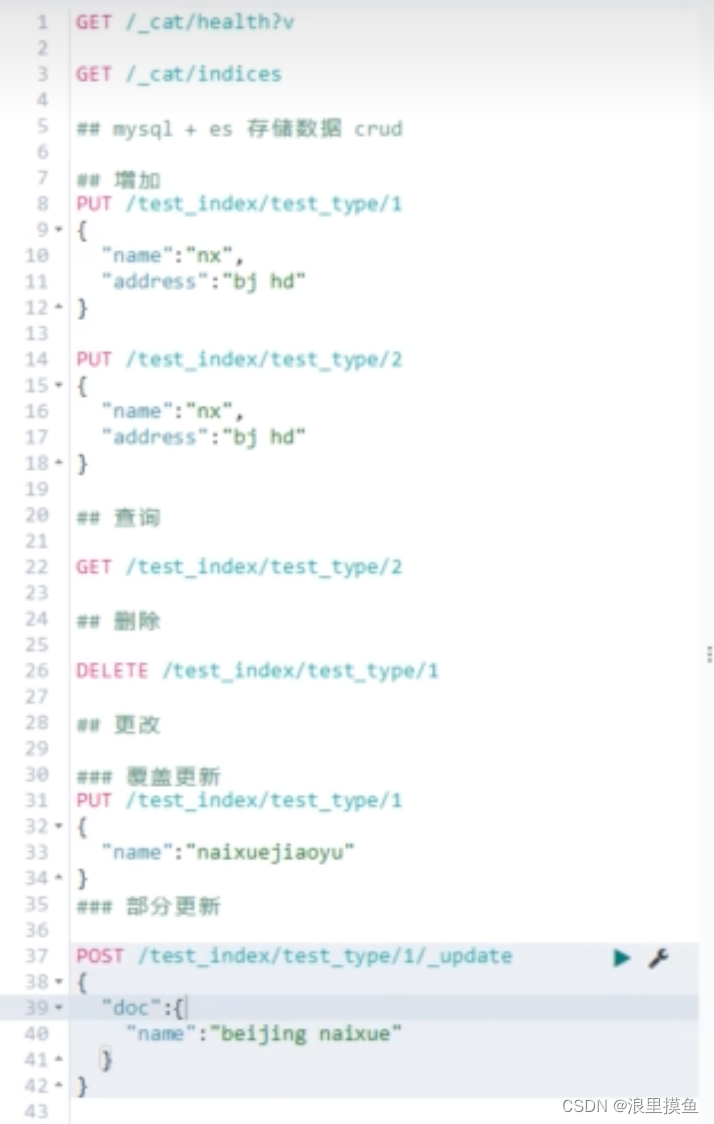
索引

增删改
聚合分析
分组 count
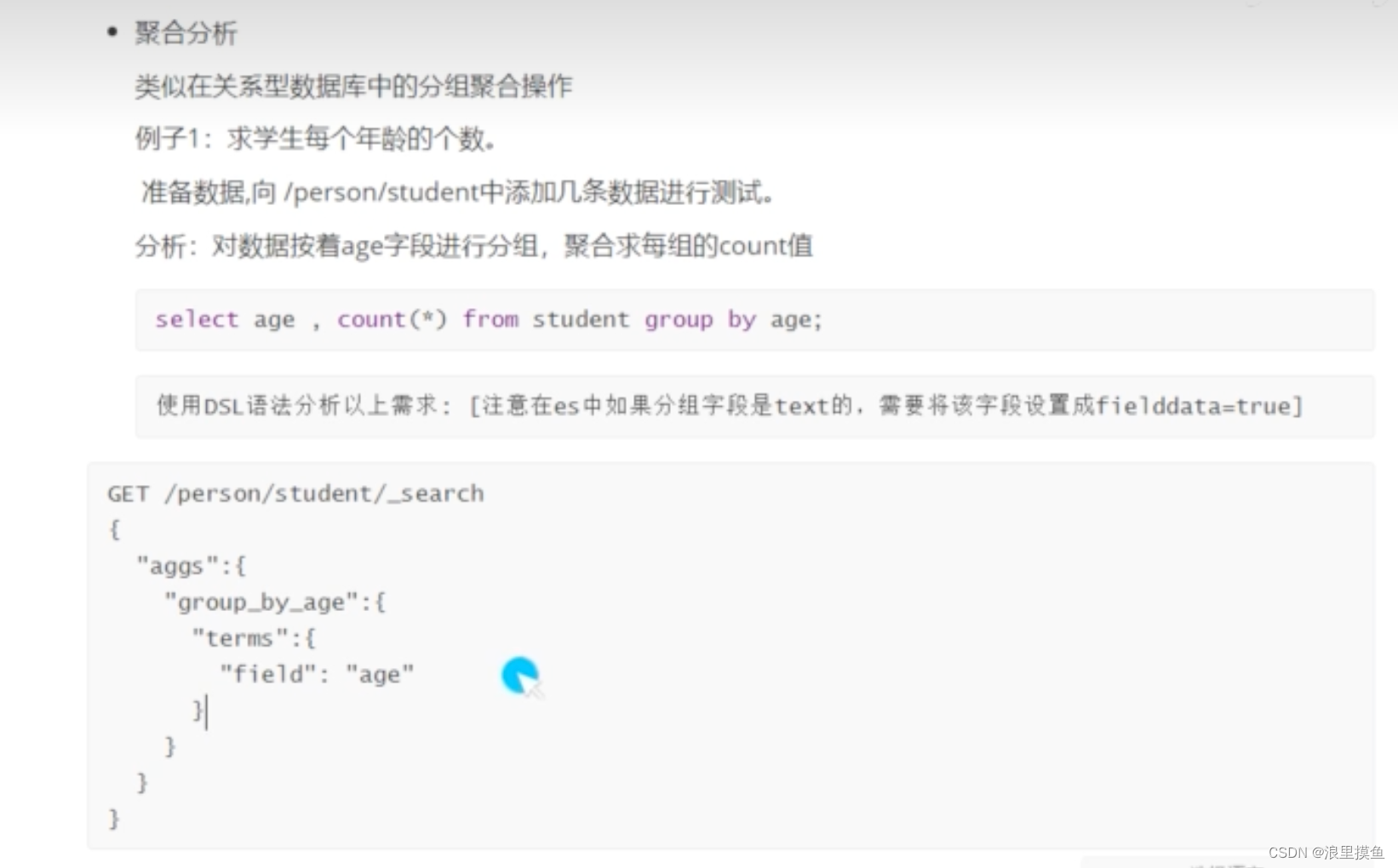
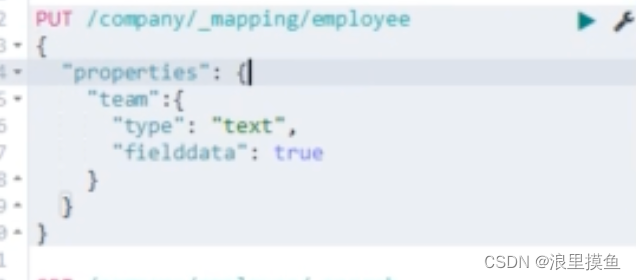
用字符串分组需要指定fileddate=true
条件判断
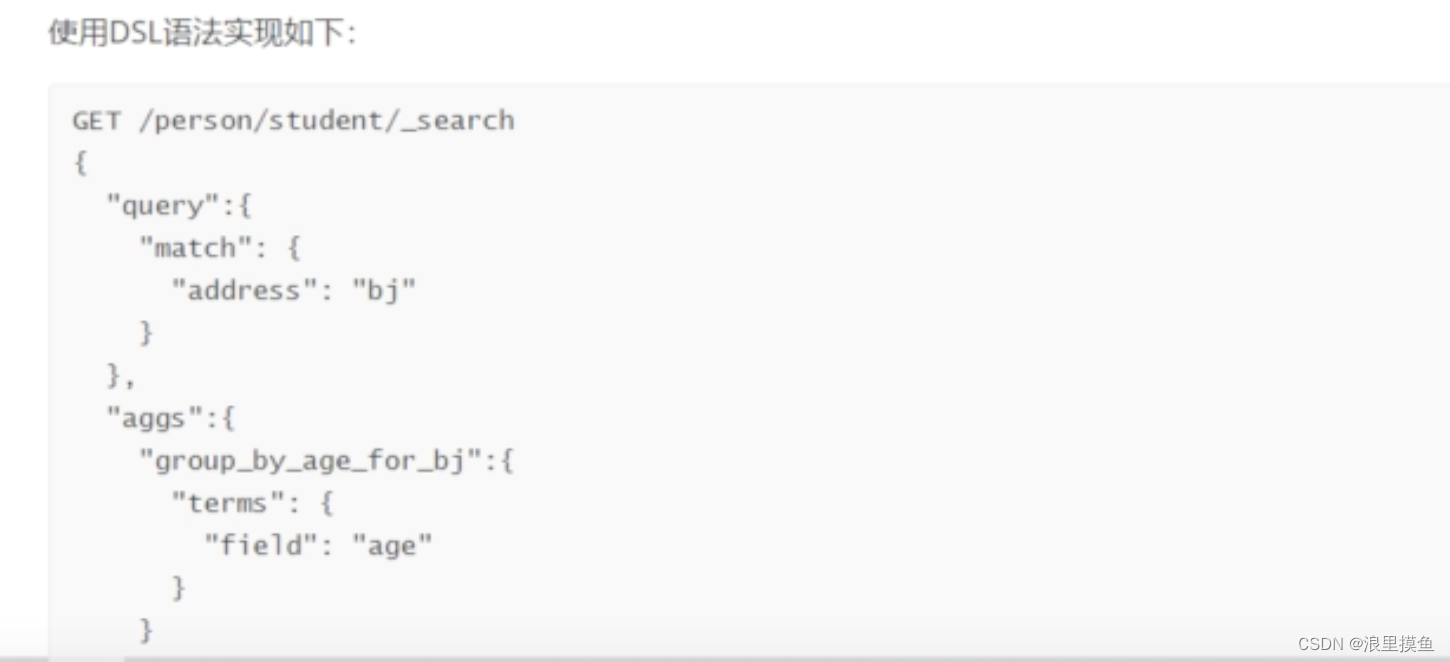
平均数,求和
4. es的扩容实现
垂直扩容:节点扩容
水平扩容:添加新节点
水平扩容用的比较多
文章来源:https://blog.csdn.net/weixin_42802447/article/details/135552491
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- android开发 apk瘦身的步骤
- 某粮油公司营销团队的管理改革项目纪实
- 外包做了1个月,技术退步一大半了。。。
- 童年的游戏
- 用js让用户输入一个数累加和
- 42道Java网络编程相关面试题含答案(很全)
- canvas绘制美国国旗(USA Flag)
- linux高级篇基础理论八(web调度器、LVS,heproxy、nginx,算法)
- 不开心的小朋友 - 华为OD统一考试
- TIDB的忘了root用户密码和数据库密码解决办法