【MySQL·8.0·源码】MySQL 的查询处理
发布时间:2024年01月03日
Query processing
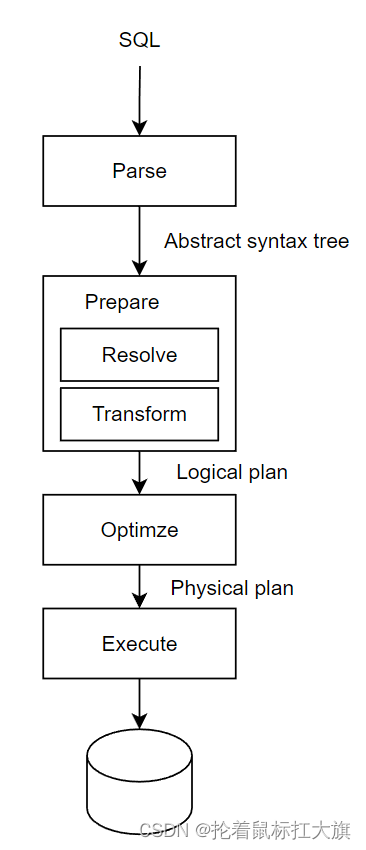
MySQL 的 Query 处理可以分为 Parse、Prepare(Resolve/Transform)、Optimize 和 Execute 几个阶段
-
Parse
词法扫描器将 SQL 语句字符串分解为 tokens,语法分析器将 tokens 组装成语法树的子树结构,并 Reduce 为基本查询结构,最终生成 SQL 语法解析数MySQL 语法解析树结构如【MySQL·8.0·源码】MySQL 语法树结构
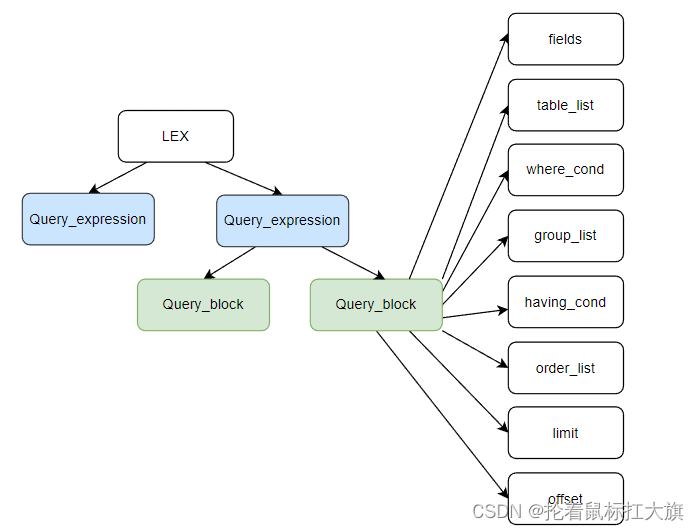
-
Prepare
- Resolve
语义检查
对象解析(schema名称、表名称、view 对象,将其解析为实际存储对象,并检查是否存在)
对子查询进行初步解析,尝试是否可以合并到外层 - Transform
逻辑改写转换(IN 转换为 semi-join,IN 转换为 EXISTS,ANY/ALL 改写)
Outer JOIN 到 Inner JOIN 的转换
条件谓词的 Transform
子查询的 Transform
- Resolve
-
Optimize
代价评估,table access method 选择,最优 join order 选择MySQL table access method 部分可以阅读 【MySQL·8.0·源码】MySQL 表的扫描方式
-
Execute
查询执行处理- MySQL 采用的执行模型为 Volcano 迭代模型
- MySQL 每个迭代器都有一个通用的迭代器接口,init()->read()
unique_ptr<RowIterator> iterator(new ...); if (iterator->Init()) return true; while (iterator->Read() == 0) { ... } - JOIN 连接也是一个迭代器
- Nested Loop Join
- BKA Join
- Hash Join
主要函数
先通过一个简单的单表索引查询所经过的重要函数,对各个阶段可能走过的重要函数有个大概印象,后序
会再通过不同的例子来说明各个函数的作用
Sql_cmd_dml::execute()
Sql_cmd_dml::prepare // Prepare
check_table_access ^
open_tables_for_query |
open_tables |
open_and_process_table |
open_table |
Query_block::prepare | /* resolve 阶段 */
Query_block::setup_tables | ^
setup_natural_join_row_types | |
Query_block::setup_wild | |
setup_fields | |
Query_block::setup_conds | |
Query_block::setup_join_cond | v
Query_block::apply_local_transforms | /* transform 阶段 */
Query_block::simplify_joins | ^
lock_tables | |
v v
Query_expression::optimize // optimize 阶段
Query_block::optimize ^
JOIN::optimize() |
JOIN::make_join_plan |
Optimize_table_order::choose_table_order|
Optimize_table_order::greedy_search |
make_join_query_block |
JOIN::optimize_distinct_group_order |
JOIN::test_skip_sort |
reduce_cond_for_table |
make_join_readinfo |
setup_semijoin_dups_elimination |
JOIN::make_tmp_tables_info |
JOIN::push_to_engines v
Query_expression::execute // excute 阶段
THD::send_result_metadata ^
handler::ha_rnd_init |
int ha_innobase::rnd_init |
handler::ha_rnd_next |
int ha_innobase::rnd_next |
int ha_innobase::index_first |
int ha_innobase::index_read ...
...
文章来源:https://blog.csdn.net/u010502974/article/details/135368606
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!