AI扩展手写数字识别应用(一)
简介
本文将介绍一例支持识别手写数学表达式并对其进行计算的人工智能应用的开发案例。本文的应用是基于前文“手写数字识别应用”中的基础应用进行扩展实现的。本文将通过这一案例,展示基本的数据整理和扩展人工智能模型的过程,以及介绍如何利用手写输入的特性来简化字符分割的过程。并且本文将演示如何利用Visual Studio Tools for AI进行批量推理,以便利用底层人工智能框架的并行计算,实现推理加速。此外,本文还将对该应用的主要代码逻辑进行分析、讲解,并介绍现实场景中识别手写数学表达式的一些潜在问题。 ?
背景
在手写数字识别课程中,我们介绍了能识别单个手写字母、基于MNIST数据集的人工智能应用,并且在我们的几次试验中,该应用表现良好,能比较准确地将手写的数字图形识别成对应的数字。那么,该应用能不能识别更多种类的手写字符,甚至是同时的出现多个字符呢?这样的情形有很多,比如生活中常见的数学表达式(形如1+2x3)。这样的复合情形更为常见,也更具现实意义。相比之下,如果一次识别仅能一个手写数字,应用就会有比较大的局限性。
首先,我们可以尝试一下多个字符同时出现这类情形中最基本的特例,即一次出现两个数字的情况。请启动手写数字识别课程中构建的应用,并在现有的应用里一次写下两个数字,看看识别效果(为了更方便书写及展示效果,我们将前一课程示例中笔画的宽度由40调整为20。可以体验出这一改动对单个数字的识别并无大的影响):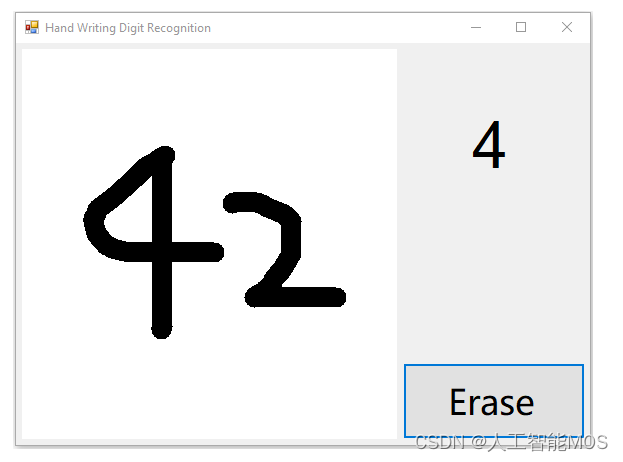
上图是一次试验的结果。进行多次试验,我们看到现有应用对两个数字的识别效果不尽人意。
如上图所示,应用窗口右上角展示的结果准确地反应了模型对我们手写输入的推理结果(即result.First().First().ToString()),然而这一结果并不像期望的那样,是我们在左侧绘图区写下的“42”。
其实对这个现象的解释已经蕴含在我们之前的课程中了。在手写数字识别课程的模型介绍章节中,我们对用于训练模型的MNIST数据集做了大致的介绍。归根结底,上述现象的症结在于:作为我们人工智能应用核心的模型,本身并不具备识别多个数字的能力——作为模型的源头,也即是训练数据的MNIST数据集只覆盖了单个的手写数字。并且,在应用的输入处理部分,我们并未对笔迹图形作额外的处理。
这两点的综合结果就是,在写下多个数字的情况下,我们实际上在“强行”让AI模型做超出其适应性范围的推理。这属于AI模型的误用。其结果自然难以令人满意。
那么,为了增强应用的可用性,我们能不能改善这款应用,让其能处理常见的数学表达式呢?这要求我们的应用既能识别数字和符号,又能识别同时出现的多个字符:首先对于多个数字这种情况,我们很自然地想到,既然MNIST模型已经能很好地识别单个数字,那我们只需要把多个数字分开,一个一个地让MNIST模型进行识别就好了;对于识别其他数学符号,我们可以尝试通过扩展MNIST模型的识别范围,也即扩展MNIST数据集来实现。两者合二为一,就是一种非常可行的解决方案。这样,我们就引入了两个新的子问题,即“扩充MNIST数据集”和“多个手写字符的分割”。
结合上文陈述的问题和潜在的解决方案,本文将以“识别并计算简单的数学表达式”这一问题为导向,对现有的手写数字识别应用进行扩展。
我们的目标是对克服现存的只能对单个数字进行识别这一局限,让新应用可以识别数字、加减乘除和括号这些能构成简单数学表达式的元素,并对识别出的数学表达式进行计算。本文希望通过这些,能最终获得一款更具现实意义的人工智能应用。
最终的应用效果如下图:
注意
“识别可能出现的多种字符”和“识别同时出现的多个字符”是完全不同的,请注意区别。
子问题:扩展MNIST数据集
准备数据
数据格式
为了让我们的新模型能支持除了数字以外的字符,一个简单的做法是扩展MNIST数据集并尝试复用已有的模型训练算法(卷积神经网络)。在手写数字识别课程的数据预处理章节中,我们部分了解了MNIST数据集所采用的数据格式和规范。为了尽可能地复用已有的资源,我们有必要让扩展的那部分数据贴近原始的MNIST数据。
Samples-for-ai样例库中使用的MNIST示例,在初运行时会从MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges下载MNIST数据集并作为训练数据。当我们顺利运行mnist.py脚本并完成训练后,我们可以在samples-for-ai\examples\tensorflow\MNIST\input目录中看到四个扩展名为.gz的文件,这四个文件就是从网上下载下来的MNIST数据集,即手写数字的位图和标记。不过这些文件是经过压缩的数据,我们使用的训练程序在下载完成后还会对这些压缩文件进行解压。训练程序只将解压后的数据储存在内存中,并没有回写到硬盘上,所以我们在input目录下找不到储存了原始位图数据的文件。
小提示
我们仍可以使用支持这种压缩格式的工具将其解压。并使用二进制工具查看其内容。
从MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges页面上,我们可以了解到MNIST数据集的位图文件和标签文件的文件格式。其中最主要的,是用于训练的位图都是28x28尺寸的、单通道的灰度图,前景色(笔画)对应值为255,背景色对应值0。一般作为像素值考虑时,255是白色,而0是黑色。从上一课中我们已经了解到,MNIST数据集是取反保存位图像素的,如果将其直接显示为位图,则和我们在界面上所见的白底黑字相反。
注意
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges页面提到
0 means background (white), 255 means foreground (black),其对颜色的解释和一般的色值解释相反。请注意厘清这两种颜色的解释方法。但是无论视觉上的颜色是什么,我们真正要遵守的规则是将前景的值转换到255,背景的值转换到0(在输入模型时,分别表现为0.5和-0.5)。
结合页面上的描述和mnist.py中数据预处理部分的相关逻辑,我们了解到目前使用的卷积神经网络要求的最终的输入数据格式如下:
| 图像数据 | 标记数据 |
|---|---|
| 四维数组 | 一维数组 |
| 第一维大小为输入的图片总数; 第二维、第三维大小为输入位图的宽高,此处皆为28; 第四维大小为输入位图的颜色通道数,MNIST只使用灰度图片,故为1。 | 大小为输入的图片总数。 |
| 每个元素(在第四维)都是32位浮点数。取值大于等于-0.5,小于等于0.5。其中0.5表示前景像素的最大值,-0.5表示背景像素的最大值。 | 每个元素都是64位整数。取值0-9,分别代表对应的手写0-9的数字。 |
根据上述的输入格式,我们已经可以确定我们扩展训练数据的方向了。这里我们需要注意,这些格式是最终输入到卷积神经网络的数据必须满足的,而非我们即将搜集、准备的新数据。虽然这表明了我们新搜集的数据不一定要精确地满足这些条件,这些输入格式仍然对我们的数据搜集起到重要的指导作用。
下图是按照一般的像素值-视觉颜色对应关系,将MNIST中的数据、UI上绘制的数据、作为模型输入的数据三者可视化之后的示意图。图上还标记了像素值到输入数据格式中32位浮点数的映射方式(上方的橙色箭头),以便形象地展示这一转换过程(F表示?Foreground 即前景,B表示?Background 即背景):
UI上绘制的数据的格式,同时也是我们下文中要准备的新数据的格式。之所以使用和MNIST内部数据相反的形式,是为了在界面和其他地方进行可视化展示时,更符合一般的书写习惯。之后我们可以在进行训练之前,再进行反色操作,如同我们上一课处理从界面上来的位图数据一样。
收集并格式化数据
搜集数据的方式多种多样。就本文的需要来说,我们可以在网络上搜索已有的数据集,可以自行开发小型应用以在触摸屏甚至手机上搜集手写图形,或者扫描手写文档并通过图像分割的方式提取运算符。并且,在搜集完原始数据之后,我们还可以通过缩放、扭曲、添加噪点等方式来扩展、增强我们的数据集,以获得更广泛的适应性。
在我们搜集足够多的新图片后(考虑到原始MNIST数据集共70000张图片,我们搜集40000张左右比较合适,虽然数量不是绝对的),我们还需要对其进行一定的格式化,以方便我们最终将其作为神经网络的输入。
位图部分所需的处理非常直观。我们可以参考前一篇手写数字识别课程中对应用图形界面上捕获的手写图形的处理方式,将搜集的图片(可能具有RGB通道)转换成28x28像素的、单通道的灰度图片,并且前景色(即笔画)色值为0(黑色),背景色色值为255(白色)。符合要求的位图样例如下:

此处更需要注意的是对图片标记的处理。在原始MNIST数据集中我们看到整数0-9被用来标记对应的图形,这是非常自然的做法。因为我们此处要解决的是多分类问题,解决这类问题的一个先决条件就是我们必须为每个分类提供一一对应的标记。我们很容易就想到用诸如10、11、12来标记加号、减号、乘号等图形类别。这是可行的。
此处我们不由得思考,延续已被占用的自然数取标记新类别,虽然可行,但让对应关系变得混乱了。10和加号、11和减号之间,并不像0-9的整数和图形之间有那么自然的联系。作为开发者的我们不禁想到,能否用ASCII表里加减乘除的字符对应的数值来做标记呢(如加号对应53,减号对应55)?这种标记的设定方法实际上是很难使用的,特别是本文中出现的MNIST训练程序基于的是TensorFlow框架,框架本身要求了标记占用的整数值必须小于类别总数。在保证标记和类别一一对应的前提条件下,我们接着已有0-9标记,再为我们新搜集的图形类别增加标记。此时我们需要清楚的定义标记到类别的对应关系,以便我们正确处理模型的输入和输出。
我们用10-15分别表示加号、减号、乘号、除号、正括号、反括号。并且,为了便于训练,我们要求这六种数学符号对应的位图,分别放置于add、minus、mul、div、lp、rp这六个文件夹中,并且这六个文件夹需要在同一个目录下。如下图所示:

训练模型
为了支持我们新增的六种数学符号,我们需要修改原始的MNIST模型训练脚本(即上一课中的mnist.py)。
这一仓库包含两部分内容:
- 在./tensorflow_model/路径下,是支持扩展的MNIST数据集的训练脚本
mnist_extension.py。这一脚本要求额外的命令行参数--extension_dir,用于指定我们扩展的六种数学符号的位图所在; - 在./extended_mnist_calculator/MNIST.App目录下,是本文这款应用的主体代码。我们会在下文中用到。 上文中,我们要求新搜集的数据最后需要被格式化为以色值0(黑色)为前景色,以色值255(白色)为前景色的单通道位图。我们修改后的训练脚本会读取这些位图并其反色,以到达和原始MNIST数据同样的效果(也和我们应用中输入处理的部分一致)。 假设我们存放
add、minus等六个文件夹的目录是D:\extension_images,我们就可以在克隆好了的仓库的/training目录下,通过命令行执行:
python mnist_extension.py --extension_dir D:\extension_images
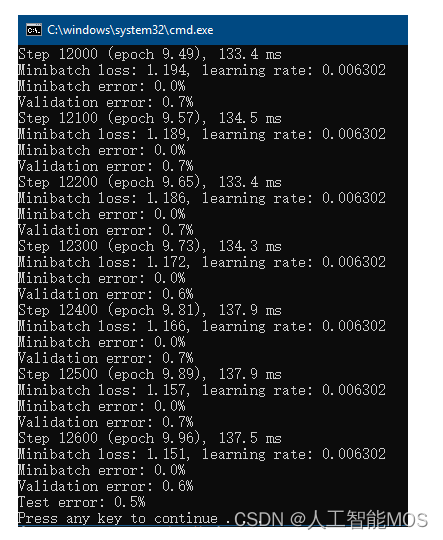
来启动针对包含了六种数学符号的扩展数据集的训练。该训练脚本在导入原始MNIST数据之后,还会从D:\extension_images目录分别读取六种新类别的数据。再混合新旧数据之后进行训练。可能的训练结果如下图:
小提示
混合新旧数据在这里非常有用。因为训练过程中,目前的脚本是一次仅将一部分数据用于迭代优化和模型参数更新。如果不进行混合,就会发生新数据迟迟不被利用的情况,影响模型的训练结果。
我们对MNIST模型的训练是基于卷积神经网络的。并且上本中的脚本在处理扩展的符号位图之外,并没有对用于训练原始MNIST模型的卷积神经网络的结构进行修改。我们知道系统的结构决定其功能,那么我们针对原始MNIST数据设计的网络结构能否支撑扩展后的数据集呢?对这一问题最简单的回答就是进行一次训练并观察模型性能。
用这种方法进行试验后,我们通过错误率(主要是Validation error,即每100次小批量训练之后,模型当前在整个验证集上的错误率;和Test error,即训练结束后模型在整个测试集上的错误率)发现新模型的性能还是不错的。足以支持我们接下来的应用。
子问题:分割多个手写字符
如上文所述,我们为了对多个同时出现的字符进行识别,还必须解决一个子问题,那就是要对这些同时出现的字符进行分割。
我们注意到本文介绍的应用有一个特点,那就是最终用作输入的图形,是用户当场写下的,而非通过图片文件导入的静态图片。也就是说,我们拥有笔画产生过程中的全部动态信息,比如笔画的先后顺序,笔画的重叠关系等等。而且我们期望这些笔画基本都是横向书写的。考虑到这些信息,我们可以设计一种基本的分割规则:在水平面上的投影相重叠的笔画,我们就认为它们同属于一个数字。
笔画和水平方向上投影的关系示意如下图:
因此书写时,就要求不同的数字之间尽量隔开。当然为了尽可能处理不经意的重叠,我们还可以为重叠部分相对每一笔画的位置设定一个阈值,如至少进入笔画一端的10%以内。
加入对重叠的容忍阈值后,对笔画的分割的结果可以参看下图。在分割后被认为是属于同一字符的笔画我们使用了相同的颜色绘制,并且用不同的颜色区分了不属于同一字符的笔画。在字符的上方,我们用一系列水平方向的半透明色块表现了每一笔画在水平方向上的的有效重叠区域和字符之间的重叠关系。
应用这样的规则后,我们就能简便而又有效地对多个笔画进行分割,并能利用Visual Studio Tools for AI提供的批量推理功能,一次性对所有分割出的图形做推理。
应用的构建和理解
完成应用
同手写数字识别课程类似,我们还是先于GitHub克隆主体的应用代码,再加以引用模型来完成本文中这款应用。
注意
由于本教程使用的工具对中文路径的支持不好,请务必将?
extended_mnist_calculator?文件夹复制到?没有中文字符的路径?下,再从那里打开解决方案。
按照训练模型一节中所述,成功获取代码后,我们可以通过Visual Studio打开?extended_mnist_calculator\MnistDemo.sln?解决方案,并和上一课一样,在解决方案里添加AI Tools – Inference模型项目。不过与上一课程稍有不同的是,为了对我们扩展的新模型加以区分,我们需要将新模型项目命名为ExtendedModel(同时也是默认的命名空间名字),并将新的模型包装类命名为MnistExtension。并且这一次,在模型项目创建向导中,我们需要选择上文中训练出的新模型。
新的Inference模型项目和模型包装类配置如下图:


推理类库创建成功后,我们还需要调整一个依赖项的版本,否则会出现不兼容的错误。要调整依赖项版本,请在解决方案管理器中,于?ExtendedModel?项目下的?引用?上右键,选择?管理NuGet包,如下图所示。

然后在弹出的NuGet包管理页面里,找到 Microsoft.ML.Scoring 项(已经被自动安装了,比如下图中显示的 1.2.0 版),我们需要将它换成其他版本。请在下图所示的高亮区里,选择?1.0.3?版本并安装。之后等待安装完备。这样就设置好可以运行本教程的软件环境了。
完成NuGet包的版本替换之后,请不要忘记在主体界面的项目上,引用我们的模型推理类库。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- webrtc报文记录
- 2024年1月9日
- 【JS笔记】JavaScript语法 《基础+重点》 知识内容,快速上手(三)
- swift基础语法
- 电极箔,预计到2025年市场规模将达到35亿美元
- 计算机毕业设计-----ssm情缘图书馆管理系统
- JMS消息发送
- vue+springboot+mybatis-plus实现新生报到管理系统
- Python ASCCI及colorama文本颜色输出
- # Jenkins:一键部署与备份的终极解决方案