3 pandas之dataframe
发布时间:2023年12月23日
定义
DataFrame是一个二维数据结构,即数据以行和列的方式以表格形式对齐。
DataFrame特点:
- 存在不同类型的列
- 大小可变
- 带有标签的轴
- 可对列和行进行算数运算
构造函数
pandas.DataFrame( data, index, columns, dtype, copy)
参数解释:
| 序号 | 参数和描述 |
|---|---|
| 1 | 数据(data) 数据可以是各种形式,如ndarray、series、map、lists、dict、constants和另一个DataFrame。 |
| 2 | 索引(index) 用于行标签的索引,如果没有传递索引,则默认为np.arange(n)。 |
| 3 | 列标签(columns) 用于列标签的可选默认语法是np.arange(n),仅当没有传递索引时才成立。 |
| 4 | 数据类型(dtype) 每列的数据类型。 |
| 5 | 复制(copy) 如果默认值为False,则用于复制数据的命令(或其他命令)。 |
创建DataFrame
创建空的DataFrame
#import the pandas library and aliasing as pd
import pandas as pd
df = pd.DataFrame()
print df

从list创建
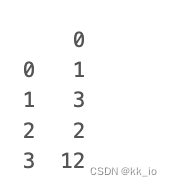
data =[1,3,2,12]
df = pd.DataFrame(data)
print(df)
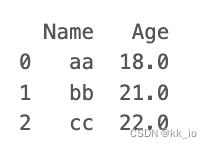
data = [['aa', 18], ['bb', 21], ['cc', 22.]]
df = pd.DataFrame(data,columns=['Name', 'Age'])
print(df)
从字典的 ndarrays/List创建
data = {'Name':['aa', 'bb', 'cc'], 'Age': [18, 21., 22]}
df = pd.DataFrame(data)
print(df)

data = {'Name':['aa', 'bb', 'cc'], 'Age': [18, 21., 22]}
df = pd.DataFrame(data, index=['rank1', 'rank2', 'rank3'])
print(df)

从字典列表创建
data = [{"aa":18,'bb':21.}, {'aa':11, 'bb':81, 'cc':71}]
df = pd.DataFrame(data)
print(df)

data = [{"aa":18,'bb':21.}, {'aa':11, 'bb':81, 'cc':71}]
df = pd.DataFrame(data, index=['first', 'second'])
print(df)
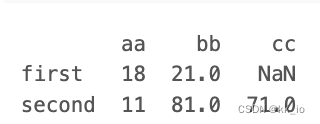
data = [{"aa":18,'bb':21.}, {'aa':11, 'bb':81, 'cc':71}]
# With 2 columns indices, values same as dictionary keys
df = pd.DataFrame(data, index=['first', 'second'], columns=['aa', 'bb'])
print(df)
# With 2 columns indices, columns values with different dictionary keys
df1 = pd.DataFrame(data, index=['first', 'second'], columns=['aa', 'bb1'])
print(df1)

从Series dict创建
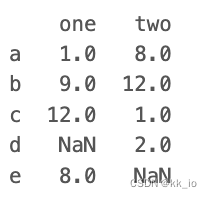
data = {
'one':pd.Series([1,9,12,8],index=['a','b','c','e']),
'two': pd.Series([8,12,1,2], index=['a','b','c','d'])
}
df = pd.DataFrame(data)
print(df)
获取对应位置的值
data = {
'one':pd.Series([1,9,12,8],index=['a','b','c','e']),
'two': pd.Series([8,12,1,2], index=['a','b','c','d'])
}
df = pd.DataFrame(data)
print(df['one'])

添加列
# Adding a new column to an existing DataFrame object with column label by passing new series
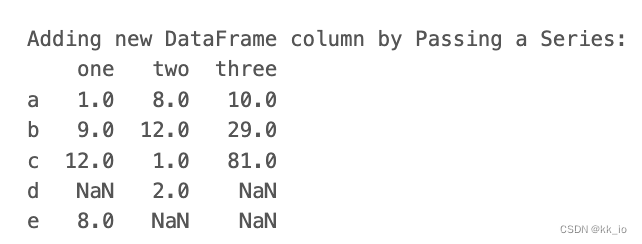
print("Adding new DataFrame column by Passing a Series:")
df['three'] = pd.Series([10,29,81], index=['a', 'b','c'])
print(df)
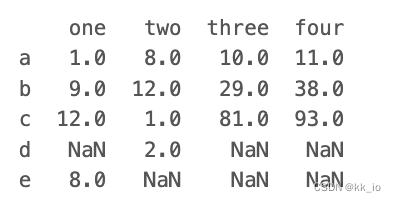
列相加
df['four']=df['one'] + df['three']
print(df)
删除列
del(df['four'])
print(df)

行的增删改查
查找
data = {
'one':pd.Series([1,9,12,8],index=['a','b','c','e']),
'two': pd.Series([8,12,1,2], index=['a','b','c','d'])
}
df = pd.DataFrame(data)
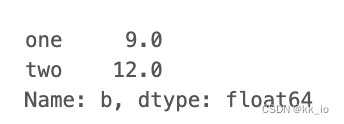
row = df.loc['b']
print(row)
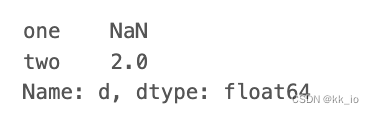
# index location from 0
row = df.iloc[3]
print(row)
# include start, exclude end
n_df = df[1:3]
print(n_df)

添加行
df = pd.DataFrame([[1,8]], columns=['a','b'])
df1 = pd.DataFrame([[2,9]], columns=['a', 'b'])
df = df.append(df1)
print(df)

删除行
···
df = pd.DataFrame([[1,8]], columns=[‘a’,‘b’])
df1 = pd.DataFrame([[2,9]], columns=[‘a’, ‘b’])
df = df.append(df1)
df = df.drop(0)
print(df)
···

文章来源:https://blog.csdn.net/qq_41758289/article/details/135120006
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!