web前端算法简介之栈
栈
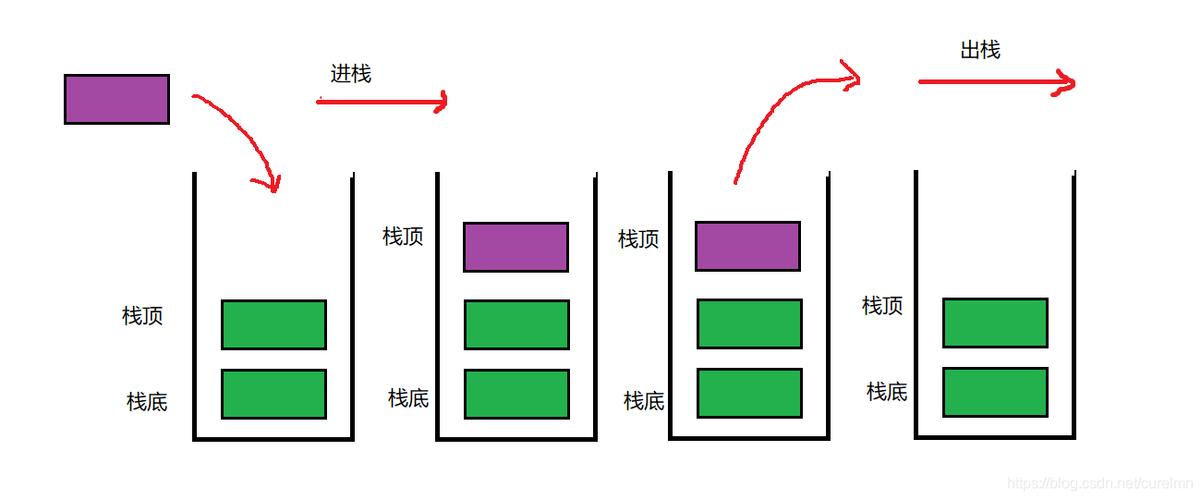
栈是一种数据结构,它是一种特殊的线性表。
栈具有 先进后出(LIFO)的特性 ,也就是最后进入栈的元素最先出栈,而最先进入栈的元素最后出栈。
栈通常有两个基本操作:压栈(push)和出栈(pop)。
压栈是将元素加入栈顶,而出栈是将栈顶元素移除。
栈可以用来进行函数调用的处理、表达式求值、以及其他需要后进先出特性的算法和数据结构。
栈通常用于实现递归算法、表达式求值、以及其他需要临时存储临时数据的场景。
举个例子:
假设我们有一个整数栈,我们可以使用栈来模拟浏览器的“后退”功能。
每当用户访问一个新的网页时,我们将该网页的信息入栈。
当用户想要返回上一页时,我们可以从栈中弹出最近访问的网页信息,实现类似后退功能的效果。
栈的基本操作包括:
栈(Stack)是一种线性数据结构,只允许在一端进行插入和删除操作。栈的典型应用场景是函数调用栈、表达式求值、括号匹配等。
栈的操作主要包括以下几种:
初始化栈(InitStack):
- 这是创建一个空栈的过程,通常包括分配一定的存储空间。
判断栈是否为空(IsStackEmpty):
- 检查栈中是否没有元素,如果栈顶指针指向NULL或者栈的大小为0,那么栈为空。
入栈(Push):
- 将一个元素添加到栈顶。例如,如果我们有一个栈S,我们想要将元素e推入栈中,我们可以这样做:
这将使得e成为新的栈顶元素。Push(S, e)
出栈(Pop):
- 删除栈顶元素并返回其值。例如,从栈S中弹出栈顶元素:
这将删除栈顶元素,并将它的值赋给变量value = Pop(S)value。剩余的元素会向上移动,新的栈顶元素变为原来栈顶元素的下一个元素。
获取栈顶元素(GetTop):
- 返回栈顶元素的值但不删除它。例如:
top_element = GetTop(S)
获取栈的大小(StackSize):
- 返回栈中元素的数量。
销毁栈(DestroyStack):
- 释放栈占用的内存资源。
这些操作都是基于栈的后进先出(LIFO)原则进行的,即最后进入栈的元素最先被移出。
以下是一个简单的栈的实现示例,使用JavaScript语言实现:
class Stack {
constructor() {
this.items = [];
}
push(item) {
this.items.push(item);
}
pop() {
return this.items.pop();
}
top() {
return this.items[this.items.length - 1];
}
isEmpty() {
return this.items.length === 0;
}
}
// 使用示例:
const stack = new Stack();
stack.push(1);
stack.push(2);
stack.push(3);
console.log(stack.pop()); // 输出3
console.log(stack.top()); // 输出2
console.log(stack.isEmpty()); // 输出false
在上面的示例中,我们定义了一个Stack类,包含了常用的栈操作方法:
- push、
- pop、
- top
- isEmpty。
我们可以通过创建一个Stack的实例来使用这些方法,对栈进行添加、删除、获取栈顶元素和判断是否为空等操作。
更多详细内容,请微信搜索“前端爱好者“, 戳我 查看 。
关于栈的前端算法题
有效的括号
leetcode地址:https://leetcode.cn/problems/valid-parentheses/
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true
示例 2:
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
提示:
1 <= s.length <= 104
s 仅由括号 '()[]{}' 组成
实现代码
/**
* @param {string} s
* @return {boolean}
*/
var isValid = function (s) {
// 新建一个数组(创建一个栈)
var stack = []
// 循环数组
for (let i = 0; i < s.length; i++) {
// 记录当前字符
const start = s[i]
// 如果当前字符等于小括号或者大括号或者中括号的左半边,则入栈
if (s[i] == '(' || s[i] == '{' || s[i] == '[') {
stack.push(s[i])
} else {
// 取出栈内最后一个元素
const end = stack[stack.length - 1]
// 如果当前字符等于小括号或者大括号或者中括号的有半边,则出栈
if (start == ')' && end == '(' || start == '}' && end == '{' || start == ']' && end == '[') {
stack.pop();
} else {
return false
}
}
}
return stack.length == 0
};

删除字符串中的所有相邻重复项
leetcode地址:https://leetcode.cn/problems/remove-all-adjacent-duplicates-in-string/
给出由小写字母组成的字符串 ‘S’,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
输入:"abbaca"
输出:"ca"
解释:
例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。
提示:
1 <= S.length <= 20000
S 仅由小写英文字母组成。
实现代码
/**
* @param {string} s
* @return {string}
*/
var removeDuplicates = function (s) {
// 新建一个栈,空栈
let stack = []
//循环字符串
for (value of s) {
let prev = stack.pop() // 删掉头部元素
// 当前删除元素不等于当前循环元素,则入栈,并且当前循环元素也入栈
// 如果二者相等,则没有入栈,直接抛弃掉了
if (prev != value) {
stack.push(prev)
stack.push(value)
}
}
return stack.join('')
};
简化路径
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 ‘/’ 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (…) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,‘//’)都被视为单个斜杠 ‘/’ 。 对于此问题,任何其他格式的点(例如,‘…’)均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
- 始终以斜杠 ‘/’ 开头。
- 两个目录名之间必须只有一个斜杠 ‘/’ 。
- 最后一个目录名(如果存在)不能 以 ‘/’ 结尾。
- 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含 ‘.’ 或 ‘…’)。
返回简化后得到的 规范路径 。
示例 1:
输入:path = "/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:path = "/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
示例 3:
输入:path = "/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:path = "/a/./b/../../c/"
输出:"/c"
提示:
1 <= path.length <= 3000
path 由英文字母,数字,'.','/' 或 '_' 组成。
path 是一个有效的 Unix 风格绝对路径。
实现源码
/**
* @param {string} path
* @return {string}
*/
var simplifyPath = function (path) {
// 新建一个栈,空栈
let stack = []
let str = ''; // 返回的字符
// 拆分数组
let arr = path.split('/')
// 循环拆分的数组
arr.forEach(item => {
// item存在并且等于'..',则出栈
if (item && item == '..') {
stack.pop()
} else if (item && item != '.') {
// item存在并且不等于'.',则进栈
stack.push(item)
}
})
// 判断数组、栈是否有值,如果有值,则需要join一下,最后前面拼接字符串'//
arr.length ? str = '/' + stack.join('/') : str = '/'
// 返回字符串
return str
};
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!