基于Python +Echarts+Mysql ,我搭建了一个招聘分析系统(附源码)
发布时间:2024年01月06日
大家好,今天给大家分享一个招聘分析系统,使用的技术有:Pycharm + Python3.7 + Requests库爬取 + Mysql + Echarts
首页有各类图表的综合分析,用户在打开招聘分析系统后在首页就能看到相应的图表分析。
通过后端的爬虫程序在各类在线平台或者招聘网站上获取的数据信息,保存到mysql数据库表,再经过可视化技术传回给前端界面,就能实现饼图、直方图、折线图、扇图等丰富的展示形式。同时利用机器学习算法对薪资进行预测,详情如下:
1、数据采集

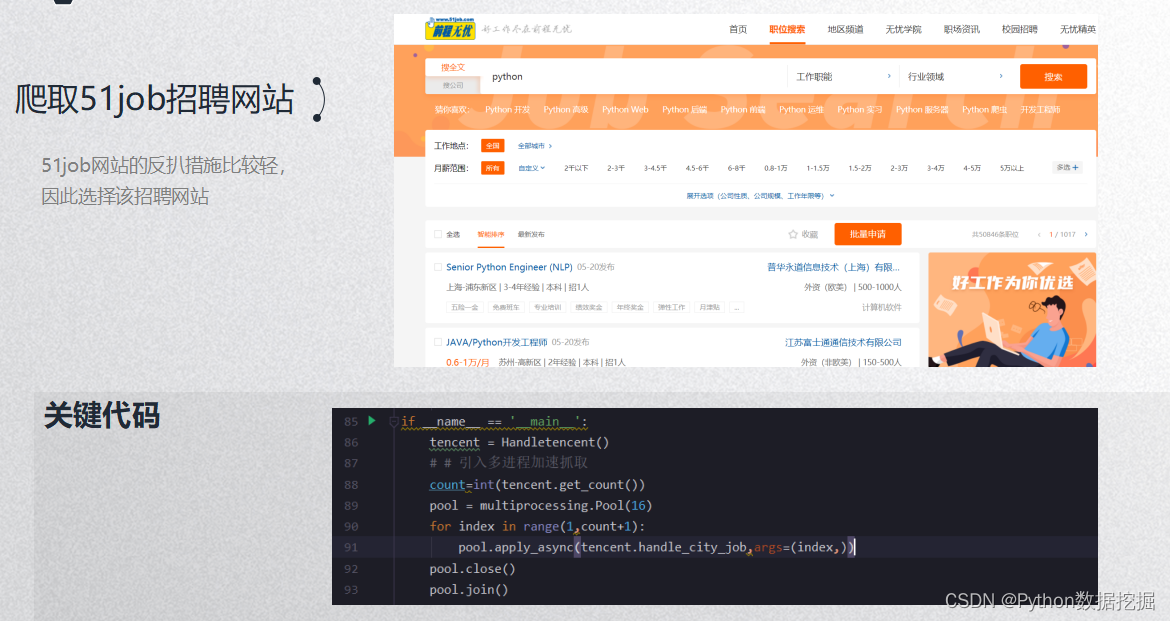
2、数据预处理

3、数据可视化


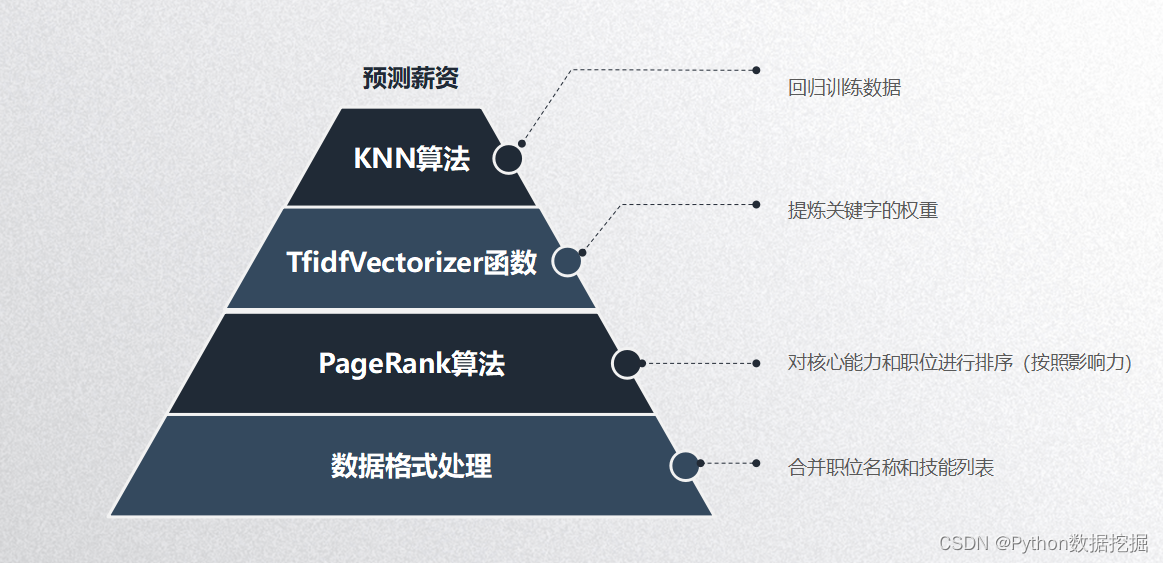
4、数据挖掘和薪资预测
技术交流
独学而无优则孤陋而寡闻,技术要学会交流、分享,不建议闭门造车。
技术交流与答疑、源码获取,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:Python学习与数据挖掘,后台回复:资料
方式②、添加微信号:dkl88194,备注:资料
部分代码展示
1、爬虫部分
import json
import re
import time
import requests
import random
import multiprocessing
from fake_useragent import UserAgent
import sys,os
sys.path.append(os.path.abspath(os.path.dirname(__file__) + '/' + '..'))
from tencent_spider.handle_insert_data import tencent_mysql
import json
class Handletencent(object):
cookies = {
'guid': 'f9afd04891c4871a0970652cc413e4ff',
'_ujz': 'MTg3MzgxOTcxMA%3D%3D',
'ps': 'needv%3D0',
'51job': 'cuid%3D187381971%26%7C%26cusername%3Dphone_16605924339_202103174904%26%7C%26cpassword%3D%26%7C%26cname%3D%26%7C%26cemail%3D%26%7C%26cemailstatus%3D0%26%7C%26cnickname%3D%26%7C%26ccry%3D.0XTya4Gjns9Y%26%7C%26cconfirmkey%3D%25241%2524MFfAaAGt%2524Kpf7biKttwh.Cn5noq0Nq.%26%7C%26cautologin%3D1%26%7C%26cenglish%3D0%26%7C%26sex%3D%26%7C%26cnamekey%3D%25241%2524apg60.Va%25242pY8PN26oaFo5o0fHOFUS.%26%7C%26to%3D0c90f570cf414295f2754e901b1ccd4360517dc5%26%7C%26',
'adv': 'adsnew%3D0%26%7C%26adsnum%3D6617760%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A%252F%252Fwww.baidu.com%252Fbaidu.php%253Fsc.Kf0000K5cNxA6dzipHgb8SMDhFjlNtbVcH1d68plK6h_2eJqZTGo7vVnpsK5YCeeLdlNPD54geiBcRB5RNi5EuUSqjCHFJNiXiYKUTkMKBPoLFElrV0mwVs2mzUizFXYdmqqowxQcvDdSDIoFO3XXqtH6rN6_uF0aJb71OOwkXWPziMr0MkY7ct-dC-B9w13qDc3bezOKj7yeRpYHrv0si29h71X.7Y_NR2Ar5Od66CHnsGtVdXNdlc2D1n2xx81IZ76Y_I5Hg3S5Huduz3vAxLOqIb5eOtHGOgCLYAX54tZ4xY5oeQtMLsxqWFECxo3Ol3EdtxzYUOkLOk5qMlePZtH4xx6O3Zj43AxLOqIaO4UqnrMxfOPSLOVNnOVOllOSkSLSIWov_gUS1GEu_ePqS8OGtUSM_dq-h1xYqnPq1572IlknyuQr1xuvTXguz3qis1f_urMIuyC.U1Yk0ZDq1PowVVgfkoWj8q5f8pHgqtHJ1qeiJ_x10ZKGm1Ys0Zfq1PowVVgfko60pyYqnWcd0ATqUvwlnfKdpHdBmy-bIykV0ZKGujYd0APGujYLn0KVIjYknjDLg1DsnH-xnH0vnNt1PW0k0AVG5H00TMfqnW0d0AFG5HDdPNtkPH9xnW0Yg1ckPdtdnjn0UynqnH63PHTdPW04Pdtknj0kg1Dsn-ts0Z7spyfqn0Kkmv-b5H00ThIYmyTqn0K9mWYsg100ugFM5H00TZ0qPHfzrjRsrjbd0A4vTjYsQW0snj0snj0s0AdYTjYs0AwbUL0qn0KzpWYk0Aw-IWdsmsKhIjYs0ZKC5H00ULnqn0KBI1Ykn0K8IjYs0ZPl5fK9TdqGuAnqTZnVuLGCXZb0pywW5R9rffKYmgFMugfqn17xn1Dkg160IZN15HfYn1nvnHc3njDsn1nLPWfLrjb0ThNkIjYkPWDdrHR1n104rjb10ZPGujdWrHD1mycsm10snjc3rj-W0AP1UHYsf1uaP19AnjbYfWbvPjc30A7W5HD0TA3qn0KkUgfqn0KkUgnqn0KbugwxmLK95H00XMfqn0KVmdqhThqV5HKxn7tsg100uA78IyF-gLK_my4GuZnqn7tsg1RznHmsPHIxn0Ksmgwxuhk9u1Ys0AwWpyfqn0K-IA-b5iYk0A71TAPW5H00IgKGUhPW5H00Tydh5H00uhPdIjYs0A-1mvsqn0KlTAkdT1Ys0A7buhk9u1Yk0Akhm1Ys0AwWmvfqwHRkwjT3PYmYPHRvfH0sPRnsPbcLnbm4wbNKnHRsrDPtn0KYTh7buHYs0AFbpyfqwjfLnRPKPWPaPHR4nbR1nWb3nHK7rjcvnWTsnYuKnRR0UvnqnfKBIjYs0Aq9IZTqn0KEIjYk0AqzTZfqnBnsc1nWnBnYnjTsnjn1rjRWPjRsnanYPH0sQW0snj0snankc1cWnanVc108njn1rH0dc1D8njDvnH0s0Z7xIWYsQWmvg108njKxna3sn7tsQW0zg108njFxna3zrNtknj08njKxnHc30AF1gLKzUvwGujYs0A-1gvPsmHYs0APs5H00ugPY5H00mLFW5HDdn10v%2526word%253D%2526ck%253D7187.15.81.366.147.315.182.242%2526shh%253Dwww.baidu.com%2526sht%253D02049043_8_pg%2526us%253D1.0.1.0.1.301.0%2526wd%253D%2526bc%253D110101%26%7C%26ad_logid_url%3D0%26%7C%26',
'slife': 'lowbrowser%3Dnot%26%7C%26lastlogindate%3D20210317%26%7C%26securetime%3DAT1VYAJlB2ZWPQA7DzcLYwYxCzU%253D',
'track': 'registertype%3D1',
'nsearch': 'jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D',
'search': 'jobarea%7E%60000000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60110300%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21',
}
headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Referer': 'https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('lang', 'c'),
('postchannel', '0000'),
('workyear', '99'),
('cotype', '99'),
('degreefrom', '99'),
('jobterm', '99'),
('companysize', '99'),
('ord_field', '0'),
('dibiaoid', '0'),
('line', ''),
('welfare', ''),
)
def __init__(self):
self.baseurl='https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{}.html'
self.city_list = []
#获取全国所有城市列表的方法
def handle_city(self):
#with open(r"D:\softwares\pythonProject\tencentflask\tencent_spider\citys.txt","r") as f:
with open(r"D:\项目系统调试区\Python爬虫招聘系统\tencentflask\tencent_spider\citys.txt", "r") as f:
f.readline()
datas=f.read().split("\n")
for data in datas:
self.city_list.append(data.split(',')[1])
# self.city_list=
def handle_city_job(self,index):
first_request_url = self.baseurl.format(index)
response = requests.get(first_request_url, headers=self.headers, params=self.params, cookies=self.cookies)
response=response.text
response=json.loads(response)
# print(response)
job_list=response['engine_jds']
for job in job_list:
tencent_mysql.insert_item(job)
def handle_request(self,method,url,data=None,info=None):
while True:
try:
if method == "GET":
# response = self.tencent_session.get(url=url,headers=self.header,proxies=proxy,timeout=6)
response = self.tencent_session.get(url=url,headers=self.header,timeout=6)
elif method == "POST":
# response = self.tencent_session.post(url=url,headers=self.header,data=data,proxies=proxy,timeout=6)
response = self.tencent_session.post(url=url,headers=self.header,data=data,timeout=6)
except:
# 需要先清除cookies信息
self.tencent_session.cookies.clear()
# 重新获取cookies信息
first_request_url = "https://www.tencent.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput=" % info
self.handle_request(method="GET", url=first_request_url)
time.sleep(20)
continue
response.encoding = 'utf-8'
if '频繁' in response.text:
print(response.text)
#需要先清除cookies信息
self.tencent_session.cookies.clear()
# 重新获取cookies信息
first_request_url = "https://www.tencent.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%info
self.handle_request(method="GET",url=first_request_url)
time.sleep(20)
continue
return response.text
def get_count(self):
start_urls = self.baseurl.format(1)
response = requests.get(start_urls, headers=self.headers, params=self.params, cookies=self.cookies)
response=response.text
response=json.loads(response)
count=response['total_page']
# count=data['Count']
return count
if __name__ == '__main__':
tencent = Handletencent()
count=tencent.get_count()
index=0
while index<int(count):
index+=1
tencent.handle_city_job(index)
# time.sleep(1)
2、flask 部分
from flask import Flask, render_template, jsonify
import sys,os
sys.path.append(os.path.abspath(os.path.dirname(__file__) + '/' + '..'))
import json
from tencent_spider.handle_insert_data import tencent_mysql
# 实例化flask
app = Flask(__name__)
# 注册路由
# @app.route("/")
# def index():
# return "Hello World"
@app.route("/get_echart_data",methods=["post","get"])
def get_echart_data():
info = {}
# 行业发布数量分析
info['echart_1'] = tencent_mysql.query_industryfield_result()
# print(info['echart_1'] )
# 薪资发布数量分析
info['echart_2'] = tencent_mysql.query_salary_result()
# 岗位数量分析,折线图
info['echart_4'] = tencent_mysql.query_job_result()
#工作年限分析
info['echart_5'] = tencent_mysql.query_workyear_result()
#学历情况分析
info['echart_6'] = tencent_mysql.query_education_result()
#融资情况
info['echart_31'] = tencent_mysql.query_financestage_result()
#公司规模
info['echart_32'] = tencent_mysql.query_companysize_result()
#岗位要求
info['echart_33'] = tencent_mysql.query_jobNature_result()
#各地区发布岗位数
info['map'] = tencent_mysql.query_city_result()
return jsonify(info)
@app.route("/",methods=['GET','POST'])
def tencent():
# 库内数据总量,今日抓取量
result = tencent_mysql.count_result()
return render_template('index.html',result=result)
@app.route("/hello")
def hellod():
# 库内数据总量,今日抓取量
return "Hello World"
if __name__ == '__main__':
# 启动flask
# app.debug=True
app.run()
文章来源:https://blog.csdn.net/qq_34160248/article/details/135422786
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Openjudge 2989:糖果题解(附带一维数组优化【貌似还没有人发过这种方法】)
- python安装cv2
- springsecurity集成kaptcha功能
- Android Framework | Linux 基础知识:入门指南
- 手把手教你,Selenium 遇见伪元素该如何处理?
- 怎样通过交换机封锁MAC地址
- ARM1.2作业
- 2023年总结(2023年1月1日至2023年12月31日)
- 绝对干货-讲讲设计模式之结构型设计模式
- 【Java面试题】ArrayList和LinkedList有什么区别