U-MixFormer:用于高效语义分割的类unet结构的混合注意力Transformer
论文:
代码:GitHub - RecklessRonan/MuSE
感觉这篇比较优雅无痛涨点欸.....最近要期末了没时间看文章和做实验了(摊
摘要
语义分割在Transformer架构的适应下取得了显著的进步。与Transformer的进步并行的是基于CNN的U-Net在高质量医学影像和遥感领域的重大进展。这两种双赢激发了作者将它们的优势结合起来,从而诞生了一种专为高效语义编码的U-Net基础视觉Transformer解码器。在这里,作者提出了一种新的Transformer解码器U-MixFormer,它基于U-Net结构,用于高效的语义分割。作者的方法通过利用编码器和解码器阶段之间的横向连接作为注意力模块的特征 Query ,除了依赖跳接的传统方式。此外,作者还创新地将来自不同编码器和解码器阶段的层次特征图混合,形成一个统一的表示形式,用于Key和Value,从而产生作者独特的_mix-attention_模块。
作者的方法在各种配置下都展示了最先进的性能。大量实验表明,U-MixFormer在SegFormer、FeedFormer和SegNet之上取得了巨大的优势。例如,U-MixFormer-B0在mIoU方面分别比SegFormer-B0和FeedFormer-B0提高了3.8%和2.0%,且计算量减少了27.3%,同时比SegNext提高了3.3%的mIoU,在MSCAN-T编码器在ADE20K上的表现。
背景
主要贡献
1. 基于U-Net的新型解码器结构
我们提出了一种新的强大的转换-解码器架构,该架构由U-Net驱动,用于高效的语义分割。利用U-Net在捕获和传播层次特征方面的熟练程度,我们的设计独特地使用了Transformer编码器的横向连接作为查询特征。这种方法确保了高级语义和低级结构的和谐融合。
2. 优化特征合成,增强上下文理解
类似unet的转换器架构,我们混合和更新多个编码器和解码器输出作为键和值的集成功能,从而产生我们提出的混合注意机制。丰富每个解码器阶段的特征表示,但也提高了上下文理解
3.?兼容不同的编码器
我们演示了U-MixFormer与基于变压器(MiT和LVT)和基于cnn (MSCAN)编码器的现有流行编码器的兼容性。
4.?基准测试经验
如图1所示,在语义分割方法中,UMixFormer在计算成本和准确性方面都达到了新的水平。它始终优于轻量级、中型甚至重型编码器。ADE20K和cityscape数据集证明了这种优势,在具有挑战性的Cityscape-C数据集上表现显著。
相关工作
Encoder Architectures
SETR是第一个将ViT作为语义分割的编码器架构。由于ViT仅将输入图像划分为 Patch ,SETR产生了单 Scale 编码器特征。PVT和Swin Transformer在编码器阶段之间重复将特征图分组到新的非重叠 Patch 中,从而分级生成多 Scale 编码器特征。这两种方法也通过减少Key和Value的空间维度(PVT)或使用位移窗口组(Swin Transformer)来增强自注意力模块的效率。SegFormer重用了PVT的效率策略,同时删除了位置编码和嵌入特征图到重叠 Patch 中。与上述方法不同,SegNeXt和LVT的编码器采用了卷积注意力机制。
Decoder Architectures
DETR是第一个将Transformer解码器用于语义分割的方法。随后的作品改编了DETR,但仍然依赖于可学习的 Query ,这在计算上是昂贵的,特别是与多尺度编码器特征相结合时。相比之下,FeedFormer直接使用编码器阶段的特征作为特征 Query ,从而提高了效率。FeedFormer解码使用最低级别的编码器特征(作为 Query 特征)和最高级别的编码器特征。然而,这种设置处理特征图逐个,没有在解码器阶段之间逐步传播特征图,因此错过了改进目标边界检测的机会。此外,其他最近的MLP或CNN基解码器也缺乏解码器特征的逐步传播。
UNet-like Transformer
人们已经尝试将UNet架构从基于卷积神经网络(CNN)的框架转变为基于Transformer的框架。TransUNet是首次成功将Transformer引入医学图像分割的方法,它使用ViT与他们的CNN编码器相结合。Swin-UNet,这是第一个完全基于Transformer的UNet类似架构。该设计具有用于编码器和解码器的重型Swin Transformer阶段,保留了它们之间的横向连接作为跳接连接。与Swin-UNet相比,我们采用轻量级解码器阶段,使其适合更广泛的下游任务。此外,我们将横向连接解释为 Query 特征而不是跳接连接,并融入了一种独特的注意力机制。
方法
模型结构
一般来说,我们的解码器由多个阶段i∈{1,…,N},因为有编码器阶段。为了清晰起见,图2提供了该体系结构的可视化概述,并举例说明了一个四阶段(N = 4)分层编码器,如MiT、LVT或MSCAN。

首先,编码器处理输入H×W×3(channel)的图像. 四个阶段i∈{1,…, 4}生成分层、多分辨率特征Ei 其次,我们的解码器阶段依次生成精细的特征D4-i+1通过执行混合注意,其中的特征用于查询Xq i 等于各自的横向编码器特征图。键和值的特性Xkv i?由编码器和解码器阶段混合给出。值得注意的是,我们的解码器反映了编码器级输出的尺寸。第三,使用双线性插值对解码器特征进行上采样,以匹配D1的高度和宽度。最后,对拼接后的特征进行MLP处理,以H/4 ×W/4 × 3预测分割图。
其次,我们的解码器阶段依次生成精细的特征D4-i+1通过执行混合注意,其中的特征用于查询Xq i 等于各自的横向编码器特征图。键和值的特性Xkv i?由编码器和解码器阶段混合给出。值得注意的是,我们的解码器反映了编码器级输出的尺寸。第三,使用双线性插值对解码器特征进行上采样,以匹配D1的高度和宽度。最后,对拼接后的特征进行MLP处理,以H/4 ×W/4 × 3预测分割图。
Mix-Attention混合注意力
Transformer 块中使用的注意力模块计算查询Q,键K和值V的缩放点积注意力,如下所示:

其中dk为键的嵌入维数,Q、K、V由所选特征的线性投影得到。我们方法的核心是选择要投射到键和值上的特征,这导致了我们提出的混合注意机制。传统的自注意力、交叉注意和新型混合注意之间的比较从左到右如图3所示。

在自注意力中,用于生成查询、键和值的特征是相同的(Xqkv),并且来自相同的来源,即相同的编码器/解码器阶段。交叉注意采用两个不同的特征,Xq和Xkv,每一个都来自一个独特的来源。相比之下,我们的混合注意机制利用了来自多个多尺度阶段的Xkv的混合特征。这个概念允许查询在所有不同的阶段找到匹配,即上下文粒度的程度,从而促进增强的功能细化。我们在消融研究部分的实验验证了这种方法的有效性。
对解码器阶段i的特征集Fi的选择分段形式化如下↓ 其中,对于第一解码器阶段(i = 1),选择所有编码器特征。对于后续阶段,先前计算的解码器阶段输出通过替换Fi中的横向编码器对等体来传播。

为了对齐Fi中特征的空间维度,我们采用了Wang等人(2021)引入的空间约简程序:式中,Fi j为特征集Fi的第j个元素,prj 为特征映射 FiN的大小与最小特征映射FiN对齐的池化比率。AvgPool操作配置为AvgPool(kernelSize, stride)(·),Linear(Cin, Cout)(·)

空间对齐的特征沿着通道维度连接,形成键和值的混合特征。

Decoder Stage?
我们通过抛弃自注意模块来调整传统的Transformer解码器块。此外,我们将交叉注意模块替换为我们提出的混合注意模块。得到的结构如图4所示。
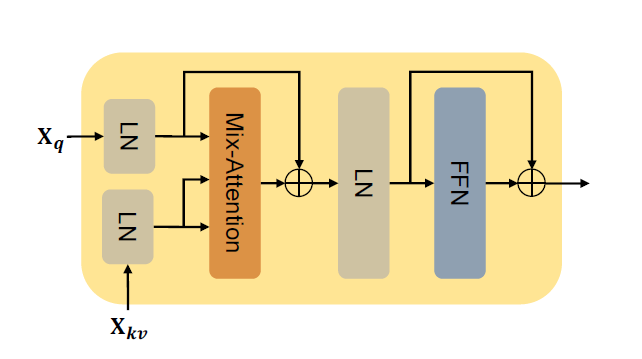
采用层归一化(LN)和前馈网络 (FFN), DecoderStage i的输出计算如下↓ MixAtt的地方。表示我们提出的的混合注意

Relationship to U-Net Architectures
我们的方法和其他类似unet的变体之间的主要区别:
?因为我们将横向连接视为查询的特征,我们的解码器特征映射隐式地增加了空间分辨率,而不需要在解码器阶段之间显式上采样。
?我们的方法使用所有解码器阶段来预测分割图,而不仅仅是最后一个。
?最后一个解码器阶段的特征图产生H/4, W/4的分辨率,而其他的恢复原来的空间分辨率H, W。(其实我之前读过有篇文章有刻意去琢磨恢复方法,至少在医学图像这种对于分辨率要求很高的任务我个人认为还是要恢复哦)
实验
数据集
ADE20K(2017)
Cityscapes(2016)
实现细节
encoder backbone
为了评估UMixFormer在各种编码器复杂性中的多功能性,我们合并了三个不同的编码器骨干:
Mix Transformer(MiT) (Xie et al. 2021),
Light Vision Transformer? (LVT) (Yang et al. 2022)
multi-scale convolutional attention-based encoder (MSCAN) (Guo et al. 2022). (这个结构出自于segnext,我以前也记过笔记SegNeXt:重新思考语义分割中卷积注意力设计-CSDN博客)
详细地说,我们将MiT-B0、LVT和MSCAN-T用于我们的轻量级变体,将MiT-B1/2和MSCAN-S用于中型架构,而较重的变体包括MiT-B3/4/5。
embedding
在最后的MLP阶段,轻量级模型的嵌入维度为128,其他模型的嵌入维度为768。补充材料第A.1节提供了关于培训和评价环境的额外信息。
实验结果
state of art对比
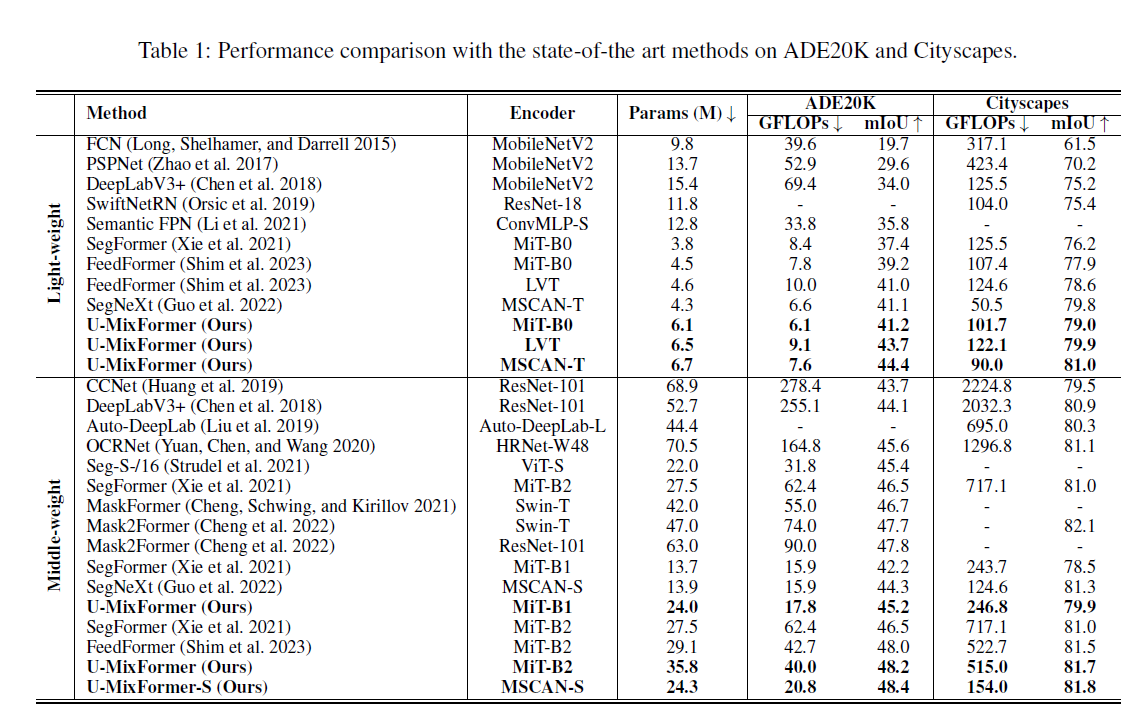
ADE20K表现

?
?定性结果
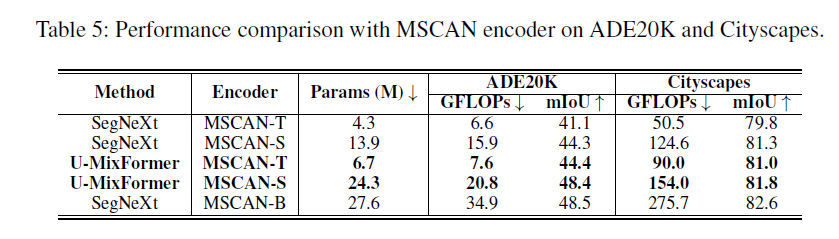
消融实验
重量级encoder性能对比

如表2所示,当与相同的重型编码器配对时,UMixFormer优于SegFormer,特别是MiT-B3/4/5。例如,在ADE20K上,U-MixFormer-B3的mIoU收益率为49.8%,GFLOPs仅为56.8。这表明与SegFormer-B3相比,mIoU提高了0.4%,计算减少了28.1%。我们还假设,扩大模型大小(从MiT-B0改为MiT-B5)将允许从编码器阶段提取更丰富的上下文信息,从而潜在地提高性能。出于这个原因,我们训练和评估了重权重模型变体,MiT-B4和MiT-B5,引入了一种方法,从编码器的第三阶段中点提取额外的键和值,其中堆叠了大量的注意力块。我们将这种增强的变体称为U-MixFormer+。对于MiT-B4和MiT-B5配置,我们分别提取了5个和6个键和值,以方便混合注意。因此,我们观察到,当集成来自编码器的更多上下文数据时,MiT-B4的性能提高了0.8%,MiT-B5的性能提高了0.1%,而计算需求仅略有增加。
混合注意力和U-Net结构的有效性
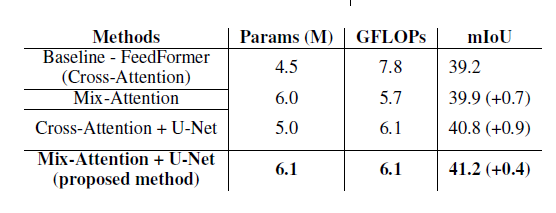
鲁棒性
对于三种使用相同编码器(MiT)的语义分割方法,计算了cityscape验证集的干净和损坏变体的平均mIoU值。mIoU是所有适用的严重级别的平均值,除了噪声损坏类别,该类别考虑了五个严重级别中的前三个。哇,鲁棒性居然也提高了

相同encoder下decoder的有效性
表1表2所示
总结与未来展望
总结
在本文中,我们提出了U-MixFormer,建立在为语义分割而设计的U-Net结构之上。UMixFormer开始与最上下文编码器的特征图,并逐步纳入更精细的细节,建立在U-Net的能力,以捕获和传播分层特征。我们的混合注意设计强调合并特征图的组件,将它们与越来越细粒度的横向编码器特征对齐。这确保了高级上下文信息与复杂的低级细节的和谐融合,这是精确分割的关键。我们在流行的基准数据集上展示了我们的U-MixFormer在不同编码器上的优势。
展望
尽管我们的U-MixFormer在计算成本和mIoU方面具有竞争力,但仍需要解决某些限制。在mmsegmentation基准设置下,我们使用单个A100 GPU测试了单个2048 × 1024图像的推理时间。如表6所示,U-MixFormer的推断时间往往比其他轻量级模型要慢。延迟可归因于U-Net的固有结构,它需要通过横向(或残余)连接来保存信息。虽然这些连接对于捕获分层特征至关重要,但在推理阶段会带来开销。为了解决这一限制,我们的目标是在未来的工作中探索模型压缩技术,如修剪和知识蒸馏。这些方法有望在保留UMixFormer的准确性优势的同时潜在地提高推理速度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 学习就要从简单的开始嘛,开始学一个个人博客吧
- Hotspot源码解析-第二十章-系统类及其方法以符号形式存储在符号表(三)
- 跨境卖家做独立站有哪些独特优势?
- CHS_01.1.1.1+1.1.3+操作系统的概念、功能
- 达梦兼容MySQL问题
- 数据结构与算法教程,数据结构C语言版教程!(第三部分、栈(Stack)和队列(Queue)详解)六
- 【基于B/S结构的博览图书管理系统的设计与实现】(论文)
- 【亚马逊云科技】使用Helm 3为Amazon EKS部署Prometheus+Grafana监控平台
- Docker jenkins 镜像制作
- java?志体系