千亿参数大模型再突破,数据质量为何是关键?
“模型诚可贵,算力价格高。”--百模大战的硝烟尚未散去,算力紧缺的呼声似犹在耳。
如今,哪怕强如OpenAI也会处于算力紧缺的状态。这也衍生出产业界共同的挑战:即当算力资源愈发宝贵时,如何在同等算力当量的情况下,更高效地训练模型,进而获得更好的模型精度和更好的智能涌现效果。
目前看,在“预训练+微调”成为大模型发展新范式的趋势下,数据层面的创新正变得愈发关键。事实上,OpenAI CEO Sam Altman去年就强调,增加大模型的参数量不再是提升大模型能力的最有效手段,大规模、高质量数据和数据高效处理工程化才是关键。
无独有偶,国内以源2.0为代表的大模型亦走在数据创新的最前沿,通过数据质量的提升,让算力、算法、数据三位一体产生更好的化学反应,从而驱动基础大模型的创新普惠。
数据质量:大模型的短板
数据质量正成为千亿参数大模型的巨大短板。
OpenAI 在《Scaling Laws for Neural Language Models》中提出 LLM 模型遵循“伸缩法则”(scaling law),即独立增加训练数据量、模型参数规模或者延长模型训练时间,预训练模型的效果会越来越好。
但从GPT4起,情况开始发生变化。OpenAI GPT3.5 从基于预训练的范式下开展转向“预训练+微调”的范式,微调的重要性愈发突出,在这种新的情况下,是否依旧还是我们投入的算力规模越大,模型的效果就越好?我们投入的数据规模越大,模型效果就越好?

答案显然是否定且值得需重新思考的。高质量、大规模、多样性的数据集对于提高模型精度、可解释性和减少训练时长大有裨益。正如著名人工智能专家吴恩达所言,AI发展正在从“以模型为中心”加速转向“以数据为中心”,高质量的训练数据集决定着模型的精度与表现。
因此,数据层面需要适应“预训练+微调”范式下不同阶段的需求,追求数据质量将会成为所有大模型接下来的重点。
但数据质量的提升绝非易事,尤其是高质量数据的匮乏可能成为一种常态。以GPT3为例,其开发文档显示,45TB纯文本数据经过质量过滤之后获得570GB文本,有效数据仅仅只有1.27%;同样,浪潮信息在源2.0的训练中,清洗了12PB规模的原始网页数据,最后提取跟数学相关的数据仅仅只有10GB不到。
众所周知,高质量数据可以带来更好的模型性能,包括推理能力,但高质量数据也将在未来一段时间消耗殆尽。根据《Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning》预测,语言数据将于 2030~2040 年耗尽,其中能训练出更好性能的高质量语言数据将于 2026 年耗尽。此外,视觉数据将于 2030~2060 年耗尽。
如何在数据层面弥补大模型发展的短板?此时此刻,增加数据来源,采用数据增强以及合成数据的新技术方法,逐渐成为牵引数据质量提升的关键所在。
提升数据质量:突破的钥匙
高质量数据是大模型能力跃迁的关键钥匙。
要想获得高质量数据,首先需要让多样性数据比例更加合理。过去,大模型的训练往往过于依赖互联网数据,书籍、科学论文等专业语言数据占比较少。但互联网公开数据集的数据质量往往低于书籍、科学论文等更专业的语言数据,增加专业数据占比就成为提升数据质量的一大关键路径。
事实上,国家也意识到增加专业数据集对于发展大模型的重要价值。最新的《“数据要素×”三年行动计划(2024—2026年)》就明确指出以科学数据支持大模型开发,深入挖掘各类科学数据和科技文献,建设高质量语料库和基础科学数据集,支持开展人工智能大模型开发和训练。
对于大模型厂商而言,增加百科、书籍、期刊等高质量数据的比重已是大势所趋。浪潮信息也是最早有意识增加高质量数据来源的厂商之一,其源 2.0大模型有意识地减少互联网公开数据集,增加百科、书籍、期刊等高质量数据,同时引入代码和数学数据,甚至针对120PB海量规模的社群数据也进行有针对性的清洗和提纯,从而达到广泛增加高质量数据的目的。
另外,考虑到中国人工智能领域数据供给产业生态不完善、获取成本高等真实情况,利用人工方式来获得高质量数据的的方式就像“刀耕火种”,成本高昂且效率低下,对于很多大模型犹如杯水车薪。因此,采用技术手段自动合成数据的方法成为弥补高质量数据不足的重要手段。
所谓生成数据,即通过大模型生成新的数据,补充模型训练中真实数据的不足。Gartner就预测,2024 年用于训练大模型的数据中有60%将是合成数据,到2030年大模型使用的绝大部分数据将由人工智能合成。
OpenAI GPT-4就非常看重合成数据,其技术文档中重点提到生成数据在训练中关键作用。目前,合成数据在自动驾驶、金融欺诈、医疗等场景有着巨大需求。
在国内,目前真正使用合成数据的大模型相对较少。其中,源2.0大模型是注重合成数据的代表,已通过丰富实践形成了一套数据构建的方法论,实现利用大模型的数据生产及过滤方法,在保证数据多样性的同时,在每一个类别上提升数据质量,从而获取高质量的训练数据。

综合来看,AGI绝不仅仅局限在语言与文字,发展多模态大模型已经成为大势所趋,无疑会进一步加大构建高质量数据集的难度,通过扩大真实数据来源、构建高质量的合成数据集在未来会越来越重要。
开源+共训:大模型高质量发展的关键
经历了2023年的百模大战,高质量发展已成为大模型产业界的共识。
事实上,在算力资源、高质量数据资源日趋宝贵的今天,我们再也不能陷入重复造轮子的商业陷阱了,大模型走向开源+共训符合未来的高质量发展需求。
以数据层面为例,IDC预测,到2025年中国有望成为全球最大的数据圈。但国内开源意识不足,数据开放程度依然较低,虽然已有不少企业与科研机构构建了开源数据集,但与我国整体数据庞大体量相比显得极为渺小。而通过开源开放的生态,有利于带动高质量数据集的利用效率,提升模型泛化应用能力。
当下,浪潮信息的源2.0是“开源+共训路线”的坚定实践者。去年11月,浪潮信息正式发布源2.0基础大模型,包括1026亿、518亿、21亿等三种参数规模的模型,在编程、推理、逻辑等方面展示出了先进的能力,并且宣布全面开源。据相关数据统计,源大模型的开放数据集目前已经被国内50家大模型所采用。
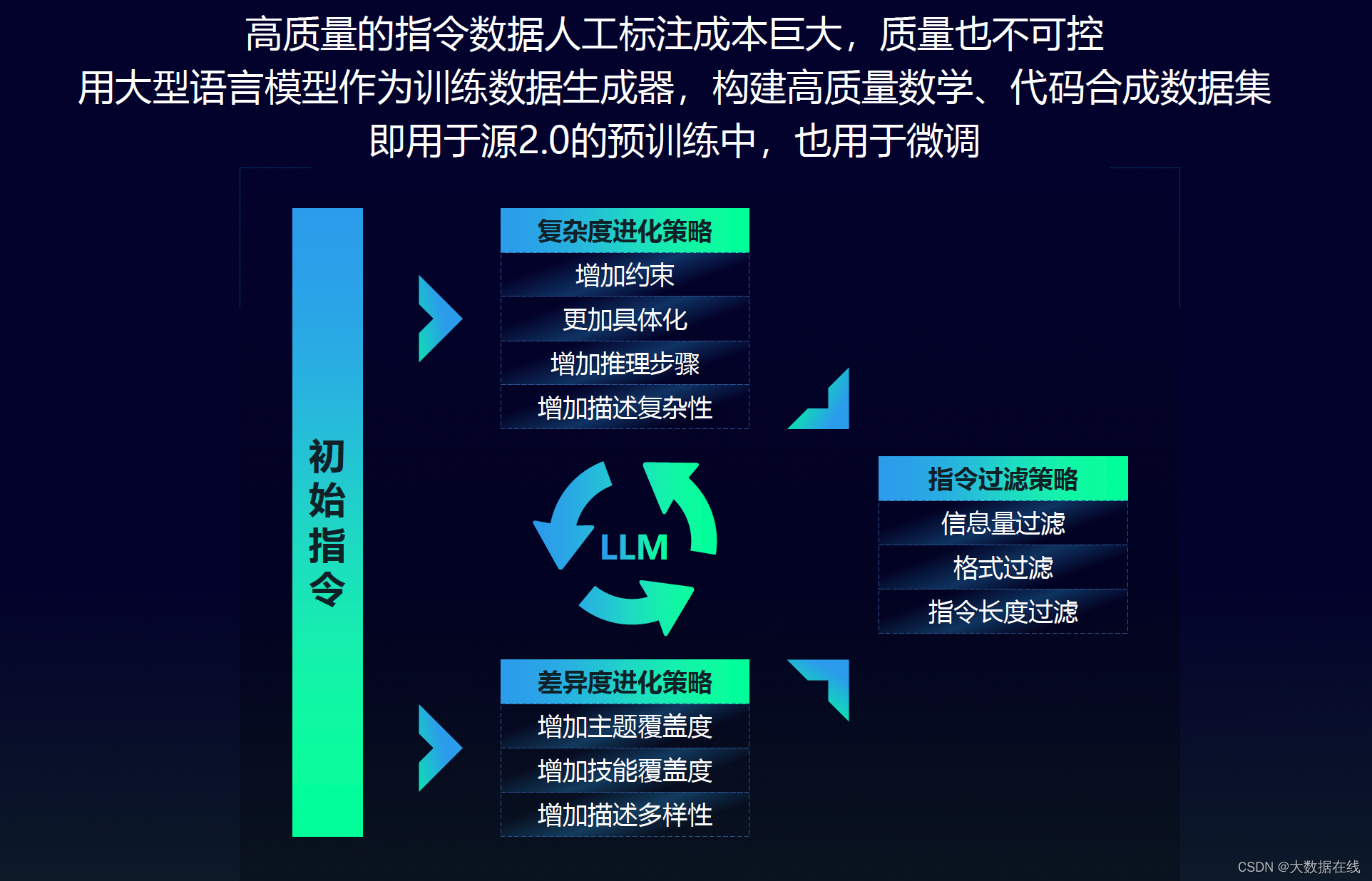
据悉,浪潮信息在“源2.0”的研发过程中,针对算法、数据和计算方面进行了创新,包括新型的注意力算法结构、数据合成方法、非均匀流水并行策略等,并采取开源+共训模式,将产业链各个环节有效串联起来,实现整个产业的快速协同发展,为国内大模型高质量发展开辟了一条有效路径。
例如,浪潮信息接下来会围绕开源社区,广泛收集开发者需求推动大模型能力与实际应用场景的适配,加速大模型在不同行业、场景中的商业化落地。
总体来看,AGI时代的奇点已经由大模型开启,但大模型“大力出奇迹”的时代已经结束。正如一句与数据相关的名言:Garbage in,Garbage out,数据质量的高低也是大模型高质量发展的关键所在。面向未来,开源+共训有利于大模型汇聚包括算法、数据等在内的技术创新力量,形成创新与成长的土壤,真正激发大模型无穷的能力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 硬件基础-LDO
- Apache OFBiz groovy 远程代码执行漏洞(CVE-2023-51467)复现
- Linux系统常用命令行指令
- 面试算法109:开密码锁
- JSON文件在Vue页面中怎么使用
- javascript 常见事件
- 【Linux】动静态库
- java连接redis,日志报错java.lang.IllegalStateException
- 5、Pandas分组和排序
- apt-mirror 制作kylin 内网源