超分之ESRGAN
- Esrgan:增强型超分辨率生成对抗网络。
- Esrgan: Enhanced super-resolution generative adversarial networks.
- In: ECCVW. (2018)
- Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu,Chao Dong, Yu Qiao, and Chen Change Loy.
文章目录
摘要
- 首先介绍了SRGAN的缺点:
- SRGAN生成的SR图像的细节经常伴随着令人不愉快的伪影。(unpleasant artifacts)
- 然后针对SRGAN三个关键组成部分,进一步研究并改进:
- 网络结构:
- 引入了没有BN层的Residual-in-Residual Dense Block(RRDB)作为基本网络构建单元。
- 对抗损失
- 借用了relativistic GAN的思想,让辨别器预测相对真实值(ralative realness)而不是绝对真实值(absolute value)。
- 感知损失
- 使用激活前的特征来计算感知损失,这可以为亮度一致性和纹理回复提供更强的监督。
- 网络结构:
一、引言
详细介绍了针对SRGAN的三个改进:
- 网络结构(network architecture):
- 通过==引入Residual-in-Residual Dense Block(RDDB)==来改进网络结构:
- RDDB结合了多级残差网络和密集连接,
而密集块中的密集连接正是为了避免正反向传递过程中的信息丢失问题(图像信息、梯度),从而使网络具有更高的容量并且更容易训练。 - 更多的层和连接总是可以提高性能。
- RDDB结合了多级残差网络和密集连接,
- 移除Batch Normalization(BN)层:
- 移除BN层实现了稳定的训练和一致的性能。
- 有助于提高泛化能力。
- 减少计算复杂度和内存的使用。
- `在训练期间,BN层是通过使用每个batch的均值和方差对特征进行归一化;而在测试时, BN则使用整个训练数据的均值和方差完成对测试数据的归一化。这便出现了一个问题:用训练数据的均值和方差来估计测试数据的均值和方差是否合理?
答案往往是否定的,当训练和测试数据集的统计数据差距很大时,BN层往往会引入一些令人不快的伪影,并限制其泛化能力。通过实验发现,当再GAN框架下训练更深的网络时,BN层更有可能会带来伪影,这也违反了训练过程中对稳定性能的需求。
- 使用残差缩放(residual scaling)和较小的初始化(smaller initialization):
- 能够促进训练非常深的网络
这主要是借用了EDSR、Inception-v4的网络思想。redisual scaling:通过学习到的残差乘上一个0~1的常数,然后再和主通路上的特征信息做加法,有利于增强网络的稳定性。smaller initialization: 初始查参数方差越小,残差结构的网络越容易训练。
- 通过==引入Residual-in-Residual Dense Block(RDDB)==来改进网络结构:
- 对抗损失(adversarial loss):
- ==使用相对平均GAN(Relativistic average GAN)(RaGAN)==来改进辨别器:
- 它学习判断“一张图像是否比另一张更真实”,而不是“一张图像是真还是假”。
- 实验表明,这种改进有助于学习更清晰的边缘和更详细的纹理。
- `SRGAN的对抗损失目的是:让真实图像的判决概率更接近1,让生成图像的判决概率更接近与0。而改进的ESRGAN的目标是:让生成图像和真实图像之间的距离保持尽可能大。
这是引入了真实图像和生成图像见的相对距离(Relativbistic average GAN,RaGAN),而不是SRGAN中的衡量0和1之间的绝对距离。具体来说,ESRGAN的目的是:让真实图像的判决分布减去生成图像的平均分布,在对上述结果做sigmoid,使得结果更接近于1;让生成图像的判决分布减去真实图像的平均分布,在对上述结果做sigmoid,使得结果更接近于0。
- ==使用相对平均GAN(Relativistic average GAN)(RaGAN)==来改进辨别器:
- 感知损失(perceptual loss):
- (基于特征空间计算,而非像素空间)
- 通过==在激活前使用VGG features ==(而不是像SRGAN中在激活后使用VGG特征)来改进感知损失:
- 凭经验发现,这中调整后的感知损失提供了更清晰的边缘和令人视觉愉悦的结果。
- `激活层后的特征图有更稀疏的特征,越深的网络越明显。稀疏的特征会导致更弱的监督,从而网络性能变得更差。
使用激活后得特征图计算感知损失会使得重建图像得亮度和ground-truth图像不一致。
大量实验表明,增强型 SRGAN(称为 ESRGAN)在清晰度和细节方面始终优于最先进的方法。
- 关于PIRM-SR Challenge 中的感知损失设计:
-
文章中提到了新的图像质量评估标准(无参照评估):Ma’s score 和NIQE,计算公式为:perceptual index(即PI) = 1/2 ((10 ? Ma) + NIQE), PI值越小,感知质量越好。
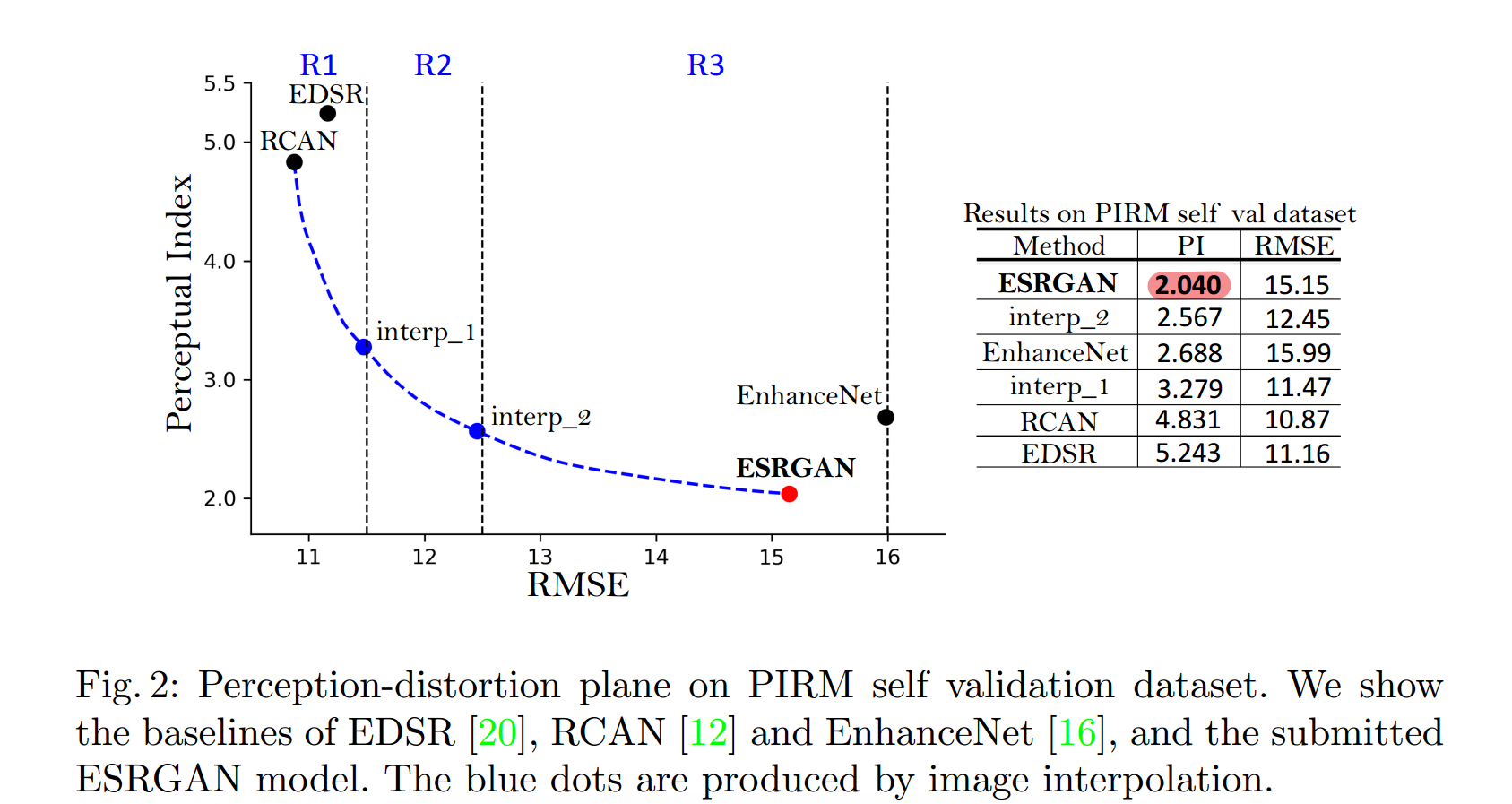
-
上图中,对于不同的评价标准而言,PSNR and SSIM越高越好,而RMSE and PI越低越好。可以看出,虽然EDSR and RCAN的RMSE很低,但PI却很高,说明感知质量并不好,ESRGAN则相反。
-
最后,为了平衡感知质量和PSNR指标,作者提出了网络插值。这能够调整重建风格和光滑度。同时,作者将在3.4节对比网络插值和基于像素空间的图像插值的关系。
-
二、相关工作
该部分主要列出了当年的一些trick
- 整体网络结构:
- 深度卷积神经网络:SRCNN、
- 深度残差神经网络:VDSR、
- 拉普拉斯金字塔结构:LapSRN、
- 残差块:SRGAN、
- 递归学习:DRCN、DRRN、
- 稠密连接网络:MemNet、
- 深的反向投影:DBPN、
- 残差稠密网络:RDN、
- 移除BN层的残差块:EDSR、
- 带有通道注意力的深度网络:RCAN、
- SR中的强化学习:
- Crafting a toolchain for image restoration by deep reinforcement learning
- SR中的无监督学习:
- Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks
- 深度网络的稳定训练方法:
- 残差通道:
- 残差缩放:
- 移除BN层的网络参数初始化方法
- residual-in-residual dense block替换残差块
- 基于感知损失的方法
- 目标是最小化特征空间的误差而不是像素空间的误差。
- 判别损失
- 相关性判别器作为优化目标,不仅增加了生成数据为真的概率,也减小了真实数据为真的概率。
- 评价指标
- 否定了PSNR 和SSIM。肯定了基于人类感知的无线照评价方法Ma’s score和NIQE,从而根据这种评价标准创建了perceptual index(PI)评价方法。
三、Methods
网络络目标为提升图片的整体感知质量,主要涉及四个方面:
- 网络结构;
- 判别器;
- 感知损失;
- 网络插值(平衡感知质量和PSNR).
3.1 网络结构(Network Architecture)
主要对生成器G的结构进行改进:
- 移除BN层;
- 移除BN层的原因:
- 删除 BN 层可以在不同的面向 PSNR 的任务(包括 SR 和去模糊 )中提高性能并降低计算复杂性。
- BN层的原理:
- BN 层在训练期间使用批次中的均值和方差对特征进行归一化,
- 并在测试期间使用整个训练数据集的估计均值和方差。
- 当训练和测试数据集的统计数据差异很大时,BN 层往往会引入令人不快的伪影并限制泛化能力。
- BN层对于GAN网络的缺点:
- 当网络更深并在 GAN 框架下训练时,使用BN层更有可能出现伪影(伪影偶尔会出现在迭代和不同设置中,违反了训练过程中稳定性能的需求)。
- 移除BN层的优势:
- 删除了 BN 层以实现稳定的训练和一致的性能。
- 去除 BN 层有助于提高泛化能力并减少计算量。
- 移除BN层的原因:
- 将原始的residual block(RB)替换为Residual-in-Residual Dense Block (RRDB)。这样的RRDB既融合了多级残差网络的思想,也融合了密集连接的思想。
- RRDB块的网络结构如下:
- RRDB采用了两层残差结构,RRDB结构由一个大的残差结构构成,主干部分由3个 RDB(Residual Dense Block)密集残差块构成,将主干网络的输出与残差边叠加。
- 在程序中,每个RDB块都有5个卷积,然后通过torch.cat函数,将卷积的通道数相叠加,所以卷积的通道数由num_feat,叠加变成num_feat + 4 * num_grow_ch,利用最后一个卷积将通道数调整为num_feat ,通过x5 * 0.2 + x构建残差边。
- (RDB)Residual Dense Block结构相当于将Residual block (ResBlock)与Dense block密集块相结合,通过密集连通卷积层提取丰富的局部特征,从先前RDB的状态直接连接到当前RDB的所有层,然后利用RDB的局部特征融合自适应地从先前和当前的局部特征中学习更有效的特征,使训练更加稳定。
- RRDB块的网络结构如下:
- 改进trick(用于促进训练非常深的网络):
- 残差缩放(residual scaling):
- 在将残差添加到主网络之前,通过乘以0到1之间的常数来缩小残差防止不稳定的途径。
- 较小的初始化(smaller initialization):
- 当初始参数方差变小时,残差架构更容易训练。
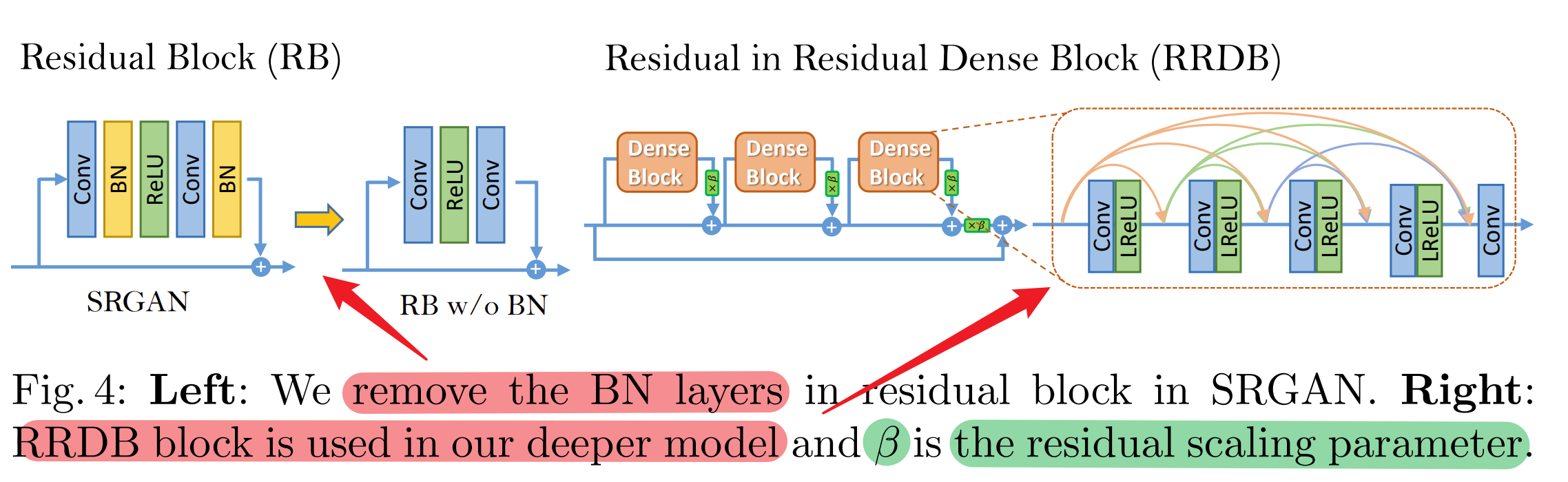
- 当初始参数方差变小时,残差架构更容易训练。
- 残差缩放(residual scaling):
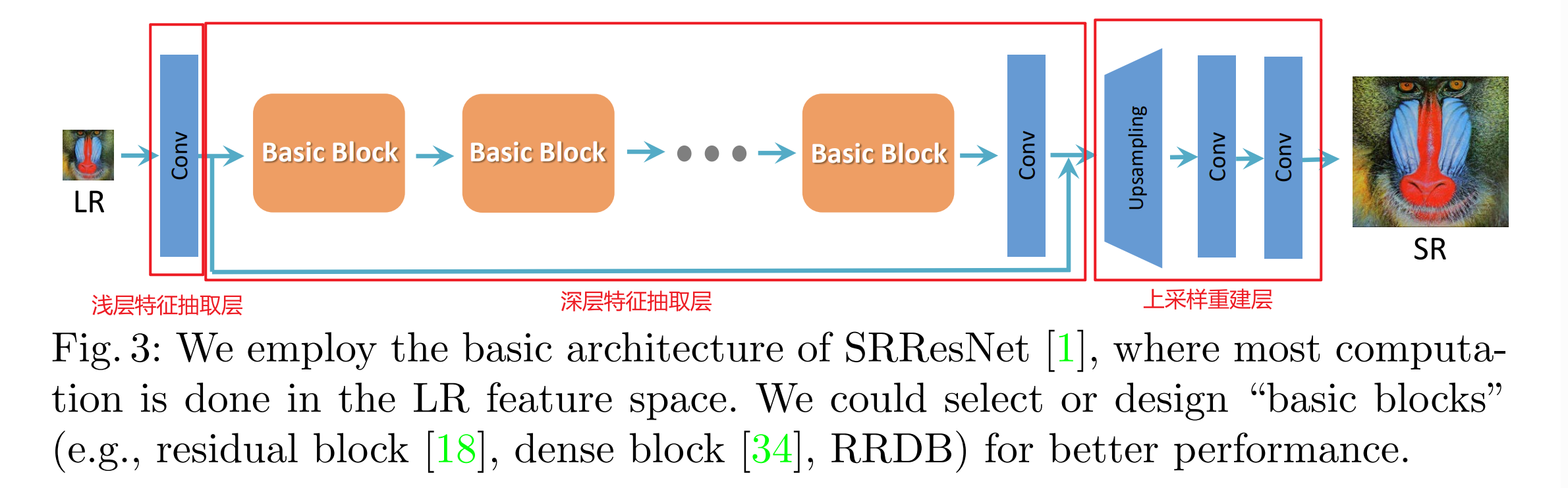
ESRGAN仍然使用SRGAN网络的高层架构设计,网络共由3部分组成:
- 浅层特征抽取层,提取浅层特征。低分辨率图像进入后会经过一个卷积+RELU函数,将输入通道数调整为64。
- 深层特征抽取层:包含然N个RDB(Residual Dense Block)密集残差块和一个残差边,每个RDB都包含5个卷积+RELU。
- 上采样重建层,然后进入上采样部分,在经过两次上采样后,原图的高宽变为原来的4倍,并且实现分辨率的提升。
3.2 相对辨别器(Relativistic Discriminator)
基于相对 GAN 增强了判别器:
- SRGAN中标准的辨别器D:为了让真实图像的判别结果的概率更趋近于1(真),让生成图像的判别结果的概率更趋近于0(假)。
- ESRGAN中的相对平均辨别器D(RaD):让生成图像和真实图像之间的距离保持尽可能大。
![![[Pasted image 20230915215014.png]]](https://img-blog.csdnimg.cn/direct/53af0a77361d471c819efe050c9fa78a.png)
参数解释:
-
x
r
x_r
xr?:真实数据,即
x
i
:
L
R
图像
x_i: LR图像
xi?:LR图像
-
x
f
x_f
xf?:假数据,
x
f
=
G
(
x
i
)
:
S
R
图像
x_f = G(x_i): SR图像
xf?=G(xi?):SR图像
-
σ
\sigma
σ:sigmoid函数:x–> -∞时,
σ
\sigma
σ(x)–>0,x–> +∞时,
σ
\sigma
σ(x)–>1。
- C(x):未变换的鉴别器输出
-
E
x
i
E_{x_i}
Exi??:对小批量中所有 真数据/假数据 取平均值的操作。
-
D
R
a
D_{Ra}
DRa?:相对平均鉴别器RaD
- 辨别器RaD原理:
- 首先需要明确的是:判别器对真实数据判决的原始值大于对虚假数据判决的原始值。
- 因此考虑第一个等式左侧: [ C ( R e a l ) ? E x f [ C ( F a k e ) ] > 0 [C(Real) - E_{x_f}[C(Fake)] >0 [C(Real)?Exf??[C(Fake)]>0, 且差值越大,表明二者距离越远,也就是该差值经过sigmoid后的值就越接近于1,这就将真实图片和生成图片很好的区分开;
- 考虑第二个等式左侧: [ C ( F a k e ) ? E x r [ C ( R e a l ) ] < 0 [C(Fake) - E_{x_r}[C(Real)] <0 [C(Fake)?Exr??[C(Real)]<0,且差值越大(负的越多),表明二者距离越远,也就是改差值经过sigmoid后的值越接近于0,这就将真实图片和生成图片很好的区分开。
- 辨别器RaD的数学表达式:
- L D R a = ? E x r [ l o g ( D R a ( x r , x f ) ) ] ? E x f [ l o g ( 1 ? D R a ( x f , x r ) ) ] ( 1 ) L^{Ra}_{D} = - \mathbb E_{x_r}[log(D_{Ra}(x_r,x_f))] - \mathbb E_{x_f}[log(1-D_{R_a}(x_f,x_r))]\quad\quad (1) LDRa?=?Exr??[log(DRa?(xr?,xf?))]?Exf??[log(1?DRa??(xf?,xr?))](1)
- 生成器的目标损失函数(正好与辨别器相反):
- L G R a = ? E x r [ 1 ? l o g ( D R a ( x r , x f ) ) ] ? E x f [ l o g ( D R a ( x f , x r ) ) ] ( 2 ) L^{Ra}_{G} = - \mathbb E_{x_r}[1 - log(D_{Ra}(x_r,x_f))] - \mathbb E_{x_f}[log(D_{R_a}(x_f,x_r))]\quad\quad (2) LGRa?=?Exr??[1?log(DRa?(xr?,xf?))]?Exf??[log(DRa??(xf?,xr?))](2)
- 直观的角度上解释:
- 因为辨别器是为了更好的区分真实图像和生成图像,而生成器是为了更难区分真实图像和生成图像。
- 由于生成器的优化函数中同时涉及生成数据 x f x_f xf?和真实数据 x r x_r xr?,所以生成器在对抗训练中受益于生成数据和真实数据的梯度,更有利于梯度的生成,可以更有利于生成图像中的边缘和细节信息。(而在 SRGAN 中只有生成的部分生效)
- 相对鉴别器有助于学习更清晰的边缘和更详细的纹理。
3.3 感知损失(Perceptual loss)
-
两大缺点(使用VGG激活层后的特征计算感知损失)
- 激活后的特征非常稀疏,尤其是在非常深的网络之后;而稀疏激活提供了弱监督,从而导致性能较差。
- 与真实图像相比,使用激活后的特征也会导致重建亮度不一致。
![![[Pasted image 20240124151555.png|500]]](https://img-blog.csdnimg.cn/direct/5f82f83cc6f54cb18359af1fe9d88f78.png)
-
改进:
- 在VGG激活层前获取的感知损失 L p e r c e p L_{percep} Lpercep?(通过计算抽象出来的SR和HR的特征图间的距离),而非传统的SRGAN在激活层后计算感知损失。
-
生成器的优化函数表达式: L G = L p e r c e p + λ L G R a + η L 1 ( 3 ) L_G = L_{percep}+λL^{Ra}_{G} + \eta L_1\quad\quad\quad (3) LG?=Lpercep?+λLGRa?+ηL1?(3)
-
符号含义:
-
L p e r c e p L_{percep} Lpercep?:在激活之前的感知损失
-
L 1 = E x i ∣ ∣ G ( x i ) ? y ∣ ∣ 1 L_1 = \mathbb E_{x_i}||G(x_i) - y||_1 L1?=Exi??∣∣G(xi?)?y∣∣1?:( L 1 范数 L_1范数 L1?范数)评估生成图像 G ( x i ) G(x_i) G(xi?)和真实图像y之间的距离。
-
λ 、 η \lambda、\eta λ、η:平衡不同损失项的系数。
3.4 网络插值(Network Interpolation)
目的:
- 消除基于GAN方法中的令人不快的噪声,同时保持良好的感知质量。
原理:
- 首先训练一个基于PSNR的网络
G
P
S
N
R
G_{PSNR}
GPSNR?,
- 然后通过微调获得一个基于GAN的网络
G
G
A
N
G_{GAN}
GGAN?,
- 然后对这两个网络的所有相应参数进行插值,得到插值模型
G
I
N
T
E
R
P
G_{INTERP}
GINTERP?。
公式如下:
θ
G
I
N
T
E
R
P
=
(
1
?
α
)
θ
G
P
S
N
R
+
α
θ
G
G
A
N
(
4
)
\theta^{INTERP}_{G} = (1 - \alpha)\theta^{PSNR}_{G} +\alpha\theta^{GAN}_{G}\quad\quad\quad(4)
θGINTERP?=(1?α)θGPSNR?+αθGGAN?(4)符号含义:
- θ G I N T E R P 、 θ G P S N R 、 θ G G A N \theta^{INTERP}_{G}、\theta^{PSNR}_{G}、\theta^{GAN}_{G} θGINTERP?、θGPSNR?、θGGAN?:分别是 G I N T E R P 、 G P S N R 、 G G A N G_{INTERP}、G_{PSNR}、G_{GAN} GINTERP?、GPSNR?、GGAN?的参数。
- α ∈ [ 0 , 1 ] \alpha \in [0,1] α∈[0,1]:插值参数。
网络插值的优点:
1. 插值模型能够为任何可行的 α 生成有意义的结果,而不会引入伪影。
2. 可以持续平衡感知质量和保真度,而无需重新训练模型。
是否还有其他平衡方法?
1. 对输出图像(pixel by pixel)逐元素进行插值,但是无法在噪声和模糊之间实现良好的平衡:
- 因为,插值后的图像,要么太模糊,要么带有伪影的噪声。
2. 调整内容损失和对抗损失的权重参数(公式3中的
λ
、
η
\lambda、\eta
λ、η):
- 这种方法需要调整损失权重和微调网络,因此实现图像风格的持续控制的成本太高。
四、实验
4.1 实验细节
- 缩放因子: 4×
- LR获取方式:
- matlab 双三次插值下采样
- mini-batch size: 16
- HR patch: 128×128
- 网络的深度与patch的大小成正比:
- 训练更深的网络受益于更大的 patch ,因为扩大的感受野有助于捕获更多语义信息。
- 但是会花费更多的训练时间, 并消耗更多的计算资源。
- 训练分为两个过程:
- 首先,训练具有 L1 损失的 PSNR 导向模型;
- 学习率: 2 × 1 0 ? 4 2 ×10^{-4} 2×10?4,每 2 × 1 0 5 2×10^{5} 2×105学习率衰退2倍
- 然后,使用经过训练的 PSNR 导向模型作为生成器的初始化。
- 学习率: 1 × 1 0 ? 4 1×10^{-4} 1×10?4,分别在50K, 100K,200K,300K时减半
- 公式三中, λ = 5 × 1 0 ? 3 , β = 1 × 10 ? 2 \lambda=5×10^{-3}, \beta=1×10{-2} λ=5×10?3,β=1×10?2
- 具有逐像素损失的预训练有助于基于 GAN 的方法获得更美观的结果
- 原因如下:
(1)它可以避免生成器出现不期望的局部最优;
(2)预训练后,判别器一开始就收到了相对较好的超分辨率图像,而不是极端的假图像(黑色或噪声图像),这有助于它更专注于纹理判别
- 原因如下:
- 首先,训练具有 L1 损失的 PSNR 导向模型;
- 优化器:Adam,
β
1
=
0.9
,
β
2
=
0.999
\beta_1 = 0.9,\beta_2 = 0.999
β1?=0.9,β2?=0.999
- 交替优化生成器和判别器直至模型收敛。
- 两种生成器结构:
- 含有16个Residual Block,与SRGAN类似。
- 使用23个RRDB,更深的模型。
4.2 数据集
- 训练集:
- DIV2K:800张2K分辨率的图像
- Flickr2K :2650 张 2K 高分辨率图像
- OutdoorSceneTraining (OST)
- 测试集:
- set5、Set14 、BSD100 、Urban100 以及 PIRM-SR 挑战赛中提供的 PIRM 自验证数据集。
4.3 定性分析
![![[Pasted image 20240124201125.png|500]]](https://img-blog.csdnimg.cn/direct/789202d759264c4e88a2c5e24eeb70d3.png)
4.4 消融实验
- 删除BN层
- 首先删除所有 BN 层,以获得稳定一致的性能,且不会出现伪影。它不会降低性能,而是节省计算资源和内存使用。
- 当网络更深、更复杂时,具有 BN 层的模型更有可能引入令人不快的伪影。
- 使用激活之前的特征作为感知损失
- 使用激活之前的特征会导致更准确的亮度分布,更接近真实情况。
- 在激活之前使用特征有助于产生更锐利的边缘和更丰富的纹理,因为激活前的密集特征提供了更强的纹理。监督比稀疏激活所能提供的监督要多。
- 使用相对判别器
R
a
G
A
N
R_aGAN
Ra?GAN
- 有利于学习更清晰的边缘和更详细的纹理
- 使用RRDB作为生成器的基本块。
- 使用所提出的 RRDB 的更深模型可以进一步改善恢复的纹理, 因为深层模型具有捕获语义信息的强大表示能力, 同时更深的模型可以减少令人不快的噪声。
4.5 网络插值
- 纯基于 GAN 的方法:
- 产生清晰的边缘和更丰富的纹理,但存在一些令人不快的伪影。
- 纯基于 PSNR 的方法:
- 输出卡通风格的模糊图像。
- 通过采用网络插值:
- 可以减少令人不快的伪影,同时保留纹理。
- 同时,网络插值策略提供了平衡感知质量和保真度的平滑控制。
- 图像插值无法有效消除这些伪影。
五、结论
- 首先,强调ESRGAN实现了SOTA,并且在PIRM-SR挑战赛中获得感知指数第一名。
- 然后,说明了本论文的创新点:
- ESRGAN包含多个没有 BN 层的 RDDB 块。
- 采用了包括残差缩放和较小初始化在内的有用技术来促进所提出的深度模型的训练。
- 使用相对论 GAN 作为判别器,它学习判断一幅图像是否比另一幅图像更真实,指导生成器恢复更详细的纹理。
- 使用激活前的特征来增强感知损失,这提供了更强的监督,从而恢复更准确的亮度和真实的纹理。****
六、支撑材料
- 重点实验了BN层带来的伪影。
- 重点实验了较小的初始化和残差缩放这两种有用的技术,来简化非常深的网络的训练,
- 针对不同的数据集,测试了RSRGAN的泛化性。
- 重点实现了HR图像的patch size对模型性能的影响。
- 更多地可视化了其他测试集的定性实验结果,
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JVM
- 联想,用PC抢AI船票
- RT-DETR优化:轻量化卷积设计 | DualConv双卷积魔改RT-DETR结构
- 序列模型(4)—— Scaling Laws
- Python 自动化测试框架unittest与pytest的区别
- Mybatis-plus动态条件查询QueryWrapper的函数用法
- Linux DISK赛题配置
- 18位身份证编码校验——我国第二代居民身份证
- uniapp打包配置 (安卓+ios)
- 【无标题】