《ORANGE’S:一个操作系统的实现》读书笔记(三十三)内存管理(一)
在之前学习保护模式的时候已经初窥过内存管理的门径。不管是分段还是分页,都是内存管理的基本概念。那么接下来要记录的内容就是内存管理,我们并不把事情搞得太复杂。而是以系统调用为驱动,逐步实现一种很简单的内存管理模式。本篇文章记录fork的创建。
目录
fork
上一篇文章我们最后实现了一个很“傻”的shell,那个shell当然没有什么用处。那么在操作系统重实现一个真正的shell,那这将是非常棒的,但是我们得先搞清楚shell做事情的原理。它的原理说来也简单,其实就是用一个子进程来执行一个命令。子进程对我们来说是个陌生的概念,目前我们的系统中所有的进程都是编译时确定好的,每个进程的入口地址、堆栈等都是在global.c中指定的,而且除了权限不同,所有进程是并列的,没有层次关系。根据之前文章对添加任务步骤的总结,我们可以想像得到,一个新的进程需要的要素有:
- 自己的代码,数据和堆栈;
- 在proc_table[]中占用一个位置;
- 在GDT中占用一个位置,用以存放进程对应的LDT描述符。
后两项工作比较容易完成,那第一项呢,代码、数据和堆栈从哪里来呢?传统上,生成一个新的进程时,这些都是直接从某个已有的进程那里继承或者复制。这也正解释了子进程这一概念:如果新的进程C的代码、数据和堆栈是从已有的进程P而来,那么P被称为父进程(parent),C被称为子进程(child)。
认识fork
生成一个子进程的系统调用被称为fork(),操作系统接到一个fork请求后,会将调用者复制一份,这时就会有两个一模一样的进程同时运行。我们现在就来实现这一过程。
第一个问题是拿谁作为父进程来执行fork()。你可能知道,在Linux中,所有进程都有同一个祖先,那就是int进程。那么我们也来模仿一下,写个Init进程,代码如下所示。
代码 kernel/main.c,Init。
void Init()
{
int fd_stdin = open("/dev_tty0", O_RDWR);
assert(fd_stdin == 0);
int fd_stdout = open("/dev_tty0", O_RDWR);
assert(fd_stdout == 1);
printf("Init() is running ...\n");
int pid = fork();
if (pid != 0) { /* parent process */
printf("parent is running, child pid:%d\n", pid);
spin("parent");
} else { /* child process */
printf("child is running, pid:%d\n", getpid());
spin("child");
}
}Init()中调用了我们即将实现的fork(),而且判断了返回值。在这里,对于父进程P和子进程C而言,判断操作系统返回给进程的fork()函数返回值,可以让进程知道自己是父进程还是子进程。
其实还有一个方法,可以让进程得知自己是父进程还是子进程,那就是通过调用getpid()。每个进程有唯一的pid,如果调用fork()前后pid一致,说明进程为父进程,反之则为子进程。获取进程pid的代码如下所示。
代码 lib/getpid.c,获取进程PID,这是新建的文件。
/**
* Get the PID.
*
* @return The PID.
*/
PUBLIC int getpid()
{
MESSAGE msg;
msg.type = GET_PID;
send_recv(BOTH, TASK_SYS, &msg);
assert(msg.type == SYSCALL_RET);
return msg.PID;
}代码 kernel/systask.c,添加对GET_PID消息的处理。
/**
* <Ring 1> The main loop of TASK SYS.
*/
PUBLIC void task_sys()
{
...
case GET_PID:
msg.type = SYSCALL_RET;
msg.PID = src;
send_recv(SEND, src, &msg);
break;
...
}现在我们来接着说fork()的返回值。fork()的返回值有两种:零或非零。如果返回零,表明自己是个子进程;如果返回非零,不仅表明自己是父进程,而且返回值即子进程的pid。
在这里我们不光要增加一个Init进程,还要增加一个MM进程——内存管理,这个进程无疑是最重要的。MM将负责从用户进程接收消息,完成fork()等操作。增加进程的方法这里就不再赘述。
不过事情还不仅如此,增加了一个Init,同时还意味着增加了Init的子子孙孙。我们来看下图(图10.1),它分成三部分,分别是GDT、进程表和进程体。GDT和进程表之间有两种联系,一是进程表的ldt_sel指向GDT中的某一项(②),而这一项反过来指向进程表内的两个LDT描述符(①)。两个LDT描述符所描述的内存范围,即为进程在内存中所占的空间,这用③来表示。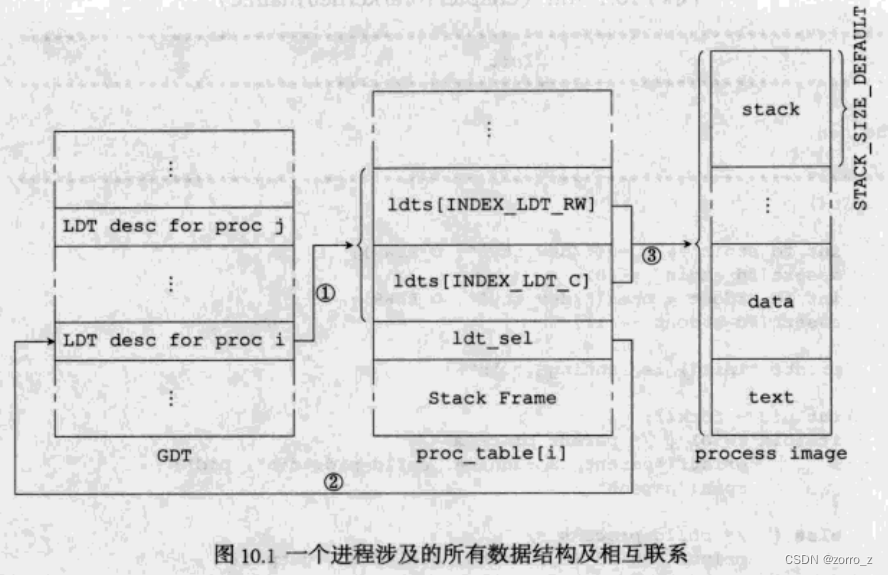
之前所有的进程都是我们“手工”添加的,进程的入口地址和堆栈长度等信息首先是记在global.c中,然后关系①在init_port()中确定,关系②和关系③在kernel_main()中确定。将来我们肯定没办法把由Init进程fork出来的子进程的入口地址放在global.c中,也不可能事先分配好某个未知进程的内存,所以有些内容肯定是要动态决定的。不过也不是所有工作都需要fork时才做,有些工作仍然是可以提前做好的。总结一下的话,以下工作我可以提前做好:
- 在proc_table[]中预留出一些空项,供新进程使用;
- 将proc_table[]中的每一个进程表项中的ldt_sel项都设定好(关系②);
- 将进程所需的GDT表项都初始化好(关系①)。
而新进程需要的内存空间,以及关系③,则都需要MM来完成,这是过会儿我们要重点关注的代码。
了解了图中各个元素之间的关系,我们就可以写代码了,首先是可以提前做好的工作,然后是需要MM来动态完成的工作。
fork前要做的工作(为fork所做的准备)
首先在proc_table[]中预留出一些空项,这需要通过改变NR_PROCS来实现:
代码 include/proc.h,NR_PROCS。
/* 最大允许任务数 */
#define NR_TASKS 5
/* 最大允许用户进程数 */
#define NR_PROCS 32
#define NR_NATIVE_PROCS 4这里我们不仅改变了NR_PROCS,还增加了一个宏:NR_NATIVE_PROCS,它表示系统初启时共有多少个用户进程。因为我们有TestA、TestB、TestC和Init,所以它应该是4。在表示进程数目的宏发生改变后,我们还应该修改kernel_main(),代如下所示。
代码 kernel/main.c,kernel_main()。
PUBLIC int kernel_main()
{
disp_str("\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n");
int i, j, eflags, prio;
u8 rpl;
u8 priv; /* privilege */
TASK * t;
PROCESS * p = proc_table;
char * stk = task_stack + STACK_SIZE_TOTAL;
for (i = 0; i < NR_TASKS + NR_PROCS; i++,p++,t++) {
if (i >= NR_TASKS + NR_NATIVE_PROCS) {
p->p_flags = FREE_SLOT;
continue;
}
if (i < NR_TASKS) { /* TASK */
t = task_table + i;
priv = PRIVILEGE_TASK;
rpl = RPL_TASK;
eflags = 0x1202; /* IF=1, IOPL=1, bit 2 is always 1 */
prio = 15;
} else { /* USER PROC */
t = user_proc_table + (i - NR_TASKS);
priv = PRIVILEGE_USER;
rpl = RPL_USER;
eflags = 0x202; /* IF=1, bit 2 is always 1 */
prio = 5;
}
strcpy(p->p_name, t->name); /* name of the process */
p->p_parent = NO_TASK;
if (strcmp(t->name, "INIT") != 0) {
p->ldts[INDEX_LDT_C] = gdt[SELECTOR_KERNEL_CS >> 3];
p->ldts[INDEX_LDT_RW] = gdt[SELECTOR_KERNEL_DS >> 3];
/* change the DPLs */
p->ldts[INDEX_LDT_C].attr1 = DA_C | priv << 5;
p->ldts[INDEX_LDT_RW].attr1 = DA_DRW | priv << 5;
} else { /* INIT process */
unsigned int k_base;
unsigned int k_limit;
int ret = get_kernel_map(&k_base, &k_limit);
assert(ret == 0);
init_descriptor(&p->ldts[INDEX_LDT_C],
0, /* bytes before the entry point are useless (wasted) for the INIT process, dosen't matter */
(k_base + k_limit) >> LIMIT_4K_SHIFT,
DA_32 | DA_LIMIT_4K | DA_C | priv << 5);
init_descriptor(&p->ldts[INDEX_LDT_RW],
0, /* bytes before the entry point are useless (wasted) for the INIT process, dosen't matter */
(k_base + k_limit) >> LIMIT_4K_SHIFT,
DA_32 | DA_LIMIT_4K | DA_DRW | priv << 5);
}
p->regs.cs = INDEX_LDT_C << 3 | SA_TIL | rpl;
p->regs.ds =
p->regs.es =
p->regs.fs =
p->regs.ss = INDEX_LDT_RW << 3 | SA_TIL | rpl;
p->regs.gs = (SELECTOR_KERNEL_GS & SA_RPL_MASK) | rpl;
p->regs.eip = (u32)t->initial_eip;
p->regs.esp = (u32)stk;
p->regs.eflags = eflags;
p->ticks = p->priority = prio;
p->p_flags = 0;
p->p_msg = 0;
p->p_recvfrom = NO_TASK;
p->p_sendto = NO_TASK;
p->has_int_msg = 0;
p->q_sending = 0;
p->next_sending = 0;
for (j = 0; j < NR_FILES; j++) {
p->filp[j] = 0;
}
stk -= t->stacksize;
}
k_reenter = 0;
ticks = 0;
p_proc_ready = proc_table;
init_clock();
init_keyboard();
restart();
while(1) {}
}跟之前相比,代码做了一些调整,主要是两点。一是将暂时没有用到的proc_table[]表项的p_flags成员赋值为FREE_SLOT,将来MM会根据此项值来判断一个表项是否为空;二是将Init进程单独区分开来,其LDT单独赋值。这样做的原因很简单,Init将来会fork出子进程,那么Init的所有内存范围都将被复制到新的位置,并在那里运行。如果Init用与其它进程相同的处理方法,使用0~4GB的扁平空间作为LDT描述符,那么我们在内存中将找不到另一块空间来存放它——在32位系统中,4GB是全部内存空间。
那么Init进程的内存应该被限制在怎样的范围之内呢?最简单的思路就是,内核有多大,Init进程的内存空间就有多大,这样不但大大缩小了进程占用的内存,而且可以保证对read()、write()等所有库函数调用都是合法的。
下面的问题就是如何得到内核的内存范围,由于内核是由LOADER加载的,所以需要问LOADER。具体方法是在LOADER中将内核中需要的数据写到内存的某个位置,然后在内核中读出来。内存500h~FFFh之间的区域都是空闲的,我们可以随意使用。
loader.asm中增加的内容如下代码所示。
代码 boot/loader.asm。
; fill in BootParam[]
mov dword [BOOT_PARAM_ADDR], BOOT_PARAM_MAGIC ; Magic Number
mov eax, [dwMemSize]
mov [BOOT_PARAM_ADDR + 4], eax ; memory size
mov eax, BaseOfKernelFile
shl eax, 4
add eax, OffsetOfKernelFile
mov [BOOT_PARAM_ADDR + 8], eax ; phy-addr of kernel.bin我们在地址BOOT_PARAM_ADDR(在load.inc中定义)处写入三个数字。第一个数字是个魔数,用作简单的标识。第二个数字是内存的大小。第三个数字是kernel.bin在内存中的物理地址。这样在内存中,我们只需要简单地读取就可以了。
代码 boot/include/load.inc。
; ATTENTION:
; Macros below should corresponding with C source.
BOOT_PARAM_ADDR equ 0x900
BOOT_PARAM_MAGIC equ 0xB007现在我们来编写在内核中读取LOADER保存参数的代码。
代码 lib/klib.c,获取LOADER预先保存的参数。
/**
* <Ring 0~1> The boot parameters have been saved by LOADER.
* We just read them out.
*
* @param pbp Ptr to the boot params structure
*/
PUBLIC void get_boot_params(struct boot_params * pbp)
{
/* Boot params should have been saved at BOOT_PARAM_ADDR. */
int * p = (int*)BOOT_PARAM_ADDR;
assert(p[BI_MAG] == BOOT_PARAM_MAGIC);
pbp->mem_size = p[BI_MEM_SIZE];
pbp->kernel_file = (unsigned char *)(p[BI_KERNEL_FILE]);
/* the kernel file should be a ELF executable, check it's magic number */
unsigned int temp = ELFMAG;
assert(memcmp(pbp->kernel_file, (void*)&temp, SELFMAG) == 0);
}
/**
* <Ring 0~1> Parse the kernel file, get the memory range of the kernel image.
*
* - The meaning of 'base': base => first_valid_byte
* - The meaning of 'limit': base + limit => last_valid_byte
*
* @param b Memory base of kernel.
* @param l Memory limit of kernel.
*/
PUBLIC int get_kernel_map(unsigned int * b, unsigned int * l)
{
struct boot_params bp;
get_boot_params(&bp);
Elf32_Ehdr * elf_header = (Elf32_Ehdr*)(bp.kernel_file);
unsigned int temp = ELFMAG;
/* the kernel file should be in ELF format */
if (memcmp(elf_header->e_ident, (void*)&temp, SELFMAG) != 0) {
return -1;
}
*b = ~0;
unsigned int t = 0;
int i;
for (i = 0; i < elf_header->e_shnum; i++) {
Elf32_Shdr * section_header = (Elf32_Shdr*)(bp.kernel_file + elf_header->e_shoff + i * elf_header->e_shentsize);
if (section_header->sh_flags & SHF_ALLOC) {
int bottom = section_header->sh_addr;
int top = section_header->sh_addr + section_header->sh_size;
if (*b > bottom) {
*b = bottom;
}
if (t < top) {
t = top;
}
}
}
assert(*b < t);
*l = t - *b - 1;
return 0;
}结构体boot_params定义在type.h中,具体定义如下所示。
代码 include/type.h,boot_params结构体定义。
/* i have no idea of where to put this struct, so i put it here */
struct boot_params {
int mem_size; /* memory size */
unsigned char * kernel_file; /* addr of kernel file */
};说了这么多,都是为了代码中使用函数get_kernel_map()来获得内核用到的内存范围。
接下来我们处理图10.1中的三个关系,首先是①和②。原先它们在两个地方处理,现在我们把它们合在一处,代码如下所示。
代码 kernel/protect.c,关系①和②。
PUBLIC void init_prot()
{
...
/* Fill the LDT descriptors of each proc in GDT */
int i;
for (i = 0; i < NR_TASKS + NR_PROCS; i++) {
memset(&proc_table[i], 0, sizeof(PROCESS));
proc_table[i].ldt_sel = SELECTOR_LDT_FIRST + (i << 3);
assert(INDEX_LDT_FIRST + i < GDT_SIZE);
init_descriptor(&gdt[INDEX_LDT_FIRST + i],
makelinear(SELECTOR_KERNEL_DS, proc_table[i].ldts),
LDT_SIZE * sizeof(DESCRIPTOR) - 1,
DA_LDT);
}
}代码中使用的makelinear宏定义在protect.h中,定义如下所示:
/* seg:off -> linear addr */
#define makelinear(seg, off) (u32)(((u32)(seg2phys(seg))) + (u32)(off))到这里,看上去图10.1我们已经用代码实现大半了,剩下的内容需要MM上场了。由于MM将接收用户的消息,所以我们不妨先完成用户进程和MM的桥梁部分,即fork()函数的界面。
fork()库函数
根据代码中fork()的用法,我们很容易写一个函数,代码如下所示。
代码 lib/fork.c,fork(),这是新建的文件。
/**
* Create a child process, which is actually a copy of the caller.
*
* @return On success, the PID of the child process is returned in the
* parent's thread of execution, and a 0 is returned in the child's
* thread of execution.
* On failure, a -1 will be returned in the parent's context, no
* child process will be created.
*/
PUBLIC int fork()
{
MESSAGE msg;
msg.type = FORK;
send_recv(BOTH, TASK_MM, &msg);
assert(msg.type == SYSCALL_RET);
assert(msg.RETVAL == 0);
return msg.PID;
}也就是说,我们调用fork()时,MM将收到一个FORK消息,这跟FS处理各种消息是类似的。
MM
跟FS一样,MM要有一个主消息循环,代码如下所示。
代码 mm/main.c,MM主消息循环,这是新建的文件。
/* <Ring 1> The main loop of TASK MM. */
PUBLIC void task_mm()
{
init_mm();
while (1) {
send_recv(RECEIVE, ANY, &mm_msg);
int src = mm_msg.source;
int reply = 1;
int msgtype = mm_msg.type;
switch (msgtype) {
case FORK:
mm_msg.RETVAL = do_fork();
break;
default:
dump_msg("MM::unknown msg", &mm_msg);
assert(0);
break;
}
if (reply) {
mm_msg.type = SYSCALL_RET;
send_recv(SEND, src, &mm_msg);
}
}
}
/* Do some initialization work. */
PRIVATE void init_mm()
{
struct boot_params bp;
get_boot_params(&bp);
memory_size = bp.mem_size;
/* print memory size */
printl("{MM} memsize:%dMB\n", memory_size / (1024 * 1024));
}当MM接到FORK消息后,调用do_fork()来处理,代码如下所示。
代码 mm/forkexit.c,do_fork(),这是新建的文件。
/**
* Perform the fork() syscall.
*
* @return Zero if success, otherwise -1.
*/
PUBLIC int do_fork()
{
/* find a free slot in proc_table */
PROCESS* p = proc_table;
int i;
for (i = 0; i < NR_TASKS + NR_PROCS; i++,p++) {
if (p->p_flags == FREE_SLOT) {
break;
}
}
int child_pid = i;
assert(p == &proc_table[child_pid]);
assert(child_pid >= NR_TASKS + NR_NATIVE_PROCS);
if (i == NR_TASKS + NR_PROCS) { /* no free slot */
return -1;
}
assert(i < NR_TASKS + NR_PROCS);
/* duplicate the process table */
int pid = mm_msg.source;
u16 child_ldt_sel = p->ldt_sel;
*p = proc_table[pid];
p->ldt_sel = child_ldt_sel;
p->p_parent = pid;
sprintf(p->p_name, "%s_%d", proc_table[pid].p_name, child_pid);
/* duplicate the process: T, D & S */
DESCRIPTOR* ppd;
/* Text segment */
ppd = &proc_table[pid].ldts[INDEX_LDT_C];
/* base of T-seg, in bytes */
int caller_T_base = reassembly(ppd->base_high, 24,
ppd->base_mid, 16,
ppd->base_low);
/* limit of T-seg, in 1 or 4096 bytes, depending on the G bit of descriptor */
int caller_T_limit = reassembly(0, 0,
(ppd->limit_high_attr2 & 0xF), 16,
ppd->limit_low);
/* size of T-seg, in bytes */
int caller_T_size = ((caller_T_limit + 1) *
((ppd->limit_high_attr2 & (DA_LIMIT_4K >> 8)) ?
4096 : 1));
/* Data & Stack segments */
ppd = &proc_table[pid].ldts[INDEX_LDT_RW];
/* base of D&G-seg, in bytes */
int caller_D_S_base = reassembly(ppd->base_high, 24,
ppd->base_mid, 16,
ppd->base_low);
/* limit of D&S-seg, in 1 or 4096 bytes, depending on the G bit of descriptor */
int caller_D_S_limit = reassembly((ppd->limit_high_attr2 & 0xF), 16,
0, 0,
ppd->limit_low);
/* size of D&S-seg, in bytes */
int caller_D_S_size = ((caller_T_limit + 1) *
((ppd->limit_high_attr2 & (DA_LIMIT_4K >> 8)) ?
4096 : 1));
/* we don't separate T, D & S segments, so we have: */
assert((caller_T_base == caller_D_S_base ) &&
(caller_T_limit == caller_D_S_limit) &&
(caller_T_size == caller_D_S_size ));
/* base of child proc, T, D & S segments share the same space, so we allocate memory just once */
int child_base = alloc_mem(child_pid, caller_T_size);
printl("{MM} 0x%x <- 0x%x (0x%x bytes)\n", child_base, caller_T_base, caller_T_size);
/* child is a copy of the parent */
phys_copy((void*)child_base, (void*)caller_T_base, caller_T_size);
/* child's LDT */
init_descriptor(&p->ldts[INDEX_LDT_C],
child_base,
(PROC_IMAGE_SIZE_DEFAULT - 1) >> LIMIT_4K_SHIFT,
DA_LIMIT_4K | DA_32 | DA_C | PRIVILEGE_USER << 5);
init_descriptor(&p->ldts[INDEX_LDT_RW],
child_base,
(PROC_IMAGE_SIZE_DEFAULT - 1) >> LIMIT_4K_SHIFT,
DA_LIMIT_4K | DA_32 | DA_DRW | PRIVILEGE_USER << 5);
/* tell FS, see fs_fork() */
MESSAGE msg2fs;
msg2fs.type = FORK;
msg2fs.PID = child_pid;
send_recv(BOTH, TASK_FS, &msg2fs);
/* child PID will be returned to the parent proc */
mm_msg.PID = child_pid;
/* birth of the child */
MESSAGE m;
m.type = SYSCALL_RET;
m.RETVAL = 0;
m.PID = 0;
send_recv(SEND, child_pid, &m);
return 0;
}代码中使用的reassembly宏定义在protect.h中,定义如下所示:
#define reassembly(high, high_shift, mid, mid_shift, low) \
(((high) << (high_shift)) + \
((mid) << (mid_shift)) + \
(low))代码总体上分为五个部分,第一部分是分配进程表。第8行到第23行从数组proc_table[]中寻找一个空项,用于存放子进程的进程表。接下来的第25行到第31行将父进程的进程表原原本本地赋给子进程。
第二部分是分配内存。由于子进程是父进程的副本,所以首先要得到父进程的内存占用情况,这由读取LDT来完成。注意其中以“_limit”结尾的变量表示的是段的“界限”,它可能是以字节为单位,也可能是以4096字节为单位,这取决于描述符的粒度位。经过计算,段的以字节为单位的实际大小放在以“_size”结尾的变量中。我们不仔细区分代码、数据和堆栈,也就是说,三个段指向相同的地址空间,在第67行我们用了个assert来保证这一点。
有了父进程的内存占用情况,下面就可以分配内存了。分配内存的函数为alloc_mem(),我们过会儿在介绍它。接下来的第75行将父进程的内存空间完整地复制了一份给新分配的空间。由于内存空间不同,所以子进程的LDT需要更新一下,这是第78行到85行所做的工作。
事情到这里并没有结束,而是生出枝节。我们知道,进程生出子进程的时候,可能已经打开了文件,我们需要在父进程和子进程之间共享文件,所以我们需要通知FS,由它来完成相应的工作(第87到91行)。
所有这些工作做完之后,函数就可以返回了(第93行到第101行)。返回之前别忘了,子进程由于使用了跟父进程几乎一样的进程表,所以目前也是挂起状态,我们需要给它也发一个消息,这样不但解除其阻塞,而且将零作为返回值传递给子进程,以便让它知道自己的身份。对于父进程,do_fork()正常返回后会由MM的主消息循环发送消息给它,我们只需要在do_fork()中给mm_msg.PID赋值就好了。
do_fork()的整体过程就是这样了,我们接下来看一看其中的两个旁支。
内存分配
一个成熟的内存分配机制是比较复杂的,但这并不意味着简单的机制就完全行不通。在这里我们就使用了一种十分老土的方案,那就是划定格子,每个格子大小固定。有新的进程需要内存,就给它一个格子,而且这个进程在整个生命周期中,只能使用这个格子的内存。
我们把格子的大小定为1MB,这个数字在一定程度内可随意选取,但至少应该大于内核的大小,这样才能盛得下Init。
与此同时,并不是所有的内存空间都能被Init的子进程使用。0~1MB的空间被内核使用,显然不能用。另外别忘了,FS等进程还使用了一些内存作为缓冲区,我们也要避开。
综合各种因素,我们定义了下面这几个宏:
代码 include/proc.h,内存分配相关的宏。
/**
* All forked proc will use memory above PROCS_BASE.
*
* @attention make sure PROCS_BASE is higher than any buffers, such as
* fsbuf, mmbuf, etc
* @see global.c
* @see global.h
*/
#define PROCS_BASE 0xA00000 /* 10 MB */
#define PROC_IMAGE_SIZE_DEFAULT 0x100000 /* 1 MB */
#define PROC_ORIGIN_STACK 0x400 /* 1 KB */我们将PROCS_BASE定义成0xA00000,也就是说,将10MB以上的空间给用户进程使用。由于我们总共有32MB的内存,所以同时最多可以有12个用户进程同时运行。在一个装有1GB内存的真实机器中,用户进程数最多可达近一千个,这听起来还不错。
PROC_ORIGIN_STACK的用途以后再说。
好了,分配方案一经确定,alloc_mem()也就容易写了,代码如下所示。
代码 mm/main.c,alloc_mem()。
/**
* Allocate a memory block for a proc.
*
* @param pid Which proc the memory is for.
* @param memsize How many bytes is needed.
*
* @return The base of the memory just allocated.
*/
PUBLIC int alloc_mem(int pid, int memsize)
{
assert(pid >= (NR_TASKS + NR_NATIVE_PROCS));
if (memsize > PROC_IMAGE_SIZE_DEFAULT) {
panic("unsupported memory request: %d. (should be less than %d)", memsize, PROC_IMAGE_SIZE_DEFAULT);
}
int base = PROCS_BASE + (pid - (NR_TASKS + NR_NATIVE_PROCS)) * PROC_IMAGE_SIZE_DEFAULT;
if (base + memsize >= memory_size) {
panic("memory allocation failed. pid:%d", pid);
}
return base;
}我们这种分配方案,其实就是建立了PID和进程内存空间之间的映射关系,或者说,内存空间是PID的一个函数。这一方案的缺点非常明显,对于小一点的程序,1MB的内存太浪费,而对于大一点的程序,1MB又可能会不够。不过我们先不管这么多,毕竟内核写了这么久,在内存中占用也还不到1MB,可见1MB也没有那么小;至于浪费嘛,那是属于优化的范畴,以后再说。总之,跟设计一个简单的FS思路相同,我们先不求好,只求先有个能用的版本。
对文件描述符的处理
上面我们说到,fork一个子进程还需要FS来协助,其实FS主要是增加两个计数器,代码如下所示。
代码 fs/main.c,fs_fork()。
/**
* Perform the aspects of fork() that relate to files.
*
* @return Zero if success, otherwise a negative integer.
*/
PRIVATE int fs_fork()
{
int i;
PROCESS* child = &proc_table[fs_msg.PID];
for (i = 0; i < NR_FILES; i++) {
if (child->filp[i]) {
child->filp[i]->fd_cnt++;
child->filp[i]->fd_inode->i_cnt++;
}
}
return 0;
}隶属于inode结构的i_cnt这个计数器我们已经很熟悉了,只要有进程使用这个inode,其i_cnt就应该加1。属于file_desc结构的fd_cnt是我们新增加的成员,它的道理很类似。假设进程P生成了进程C,那么P和C共享使用f_desc_table[]中的同一个file_desc结构,这是fd_cnt为2,表明有两个进程在使用这一结构。等进程P或C退出时,fd_cnt自减。若P和C都已退出,fd_cnt自减为零,这时系统应将fd_inode赋值为零,这样这个f_desc_table[]条目就又可被使用了。
接下来,我们在task_fs中添加对FORK消息的处理,代码如下所示。
代码 fs/main.c。
/**
* <Ring 1> The main loop of TASK FS.
*/
PUBLIC void task_fs()
{
...
case FORK:
fs_msg.RETVAL = fs_fork();
break;
...
}运行
好了,fork()系统调用的前后因果我们已经全都了解了,现在编译运行一下看看,由于新增加了C文件,所以不要忘记更改Makefile。运行效果如下图所示。
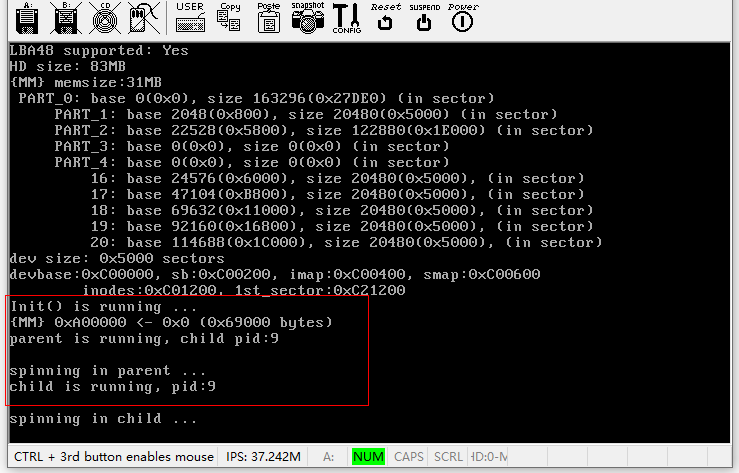
我们看到了父进程打印出的“parent is running”和子进程打印出的“child is running”,这说明我们的fork()成功了!
欢迎关注我的公众号

?
公众号中对应文章附有当前文章代码下载说明。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!