书生·浦语大模型实战营-学习笔记5
发布时间:2024年01月23日
LMDeploy 大模型量化部署实践


大模型部署背景


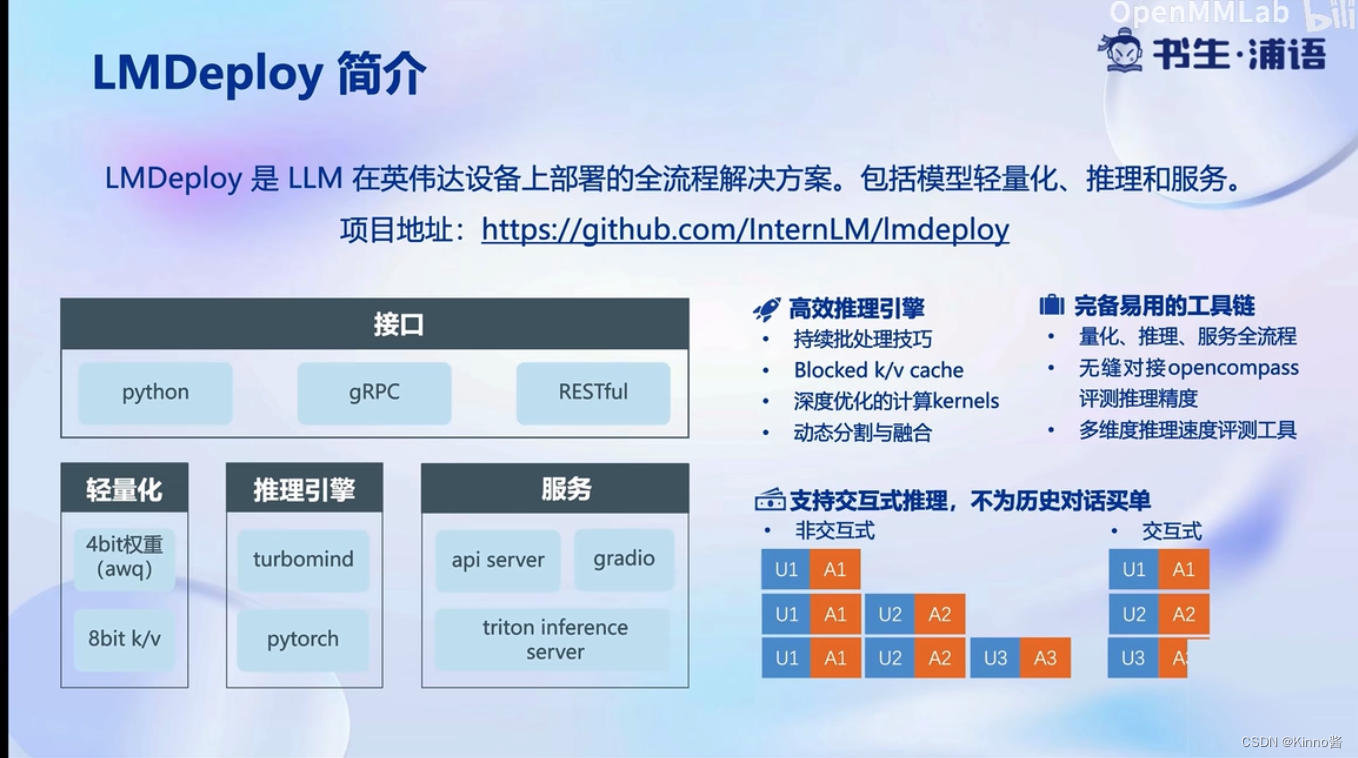
LMDeploy简介
轻量化、推理引擎、服务
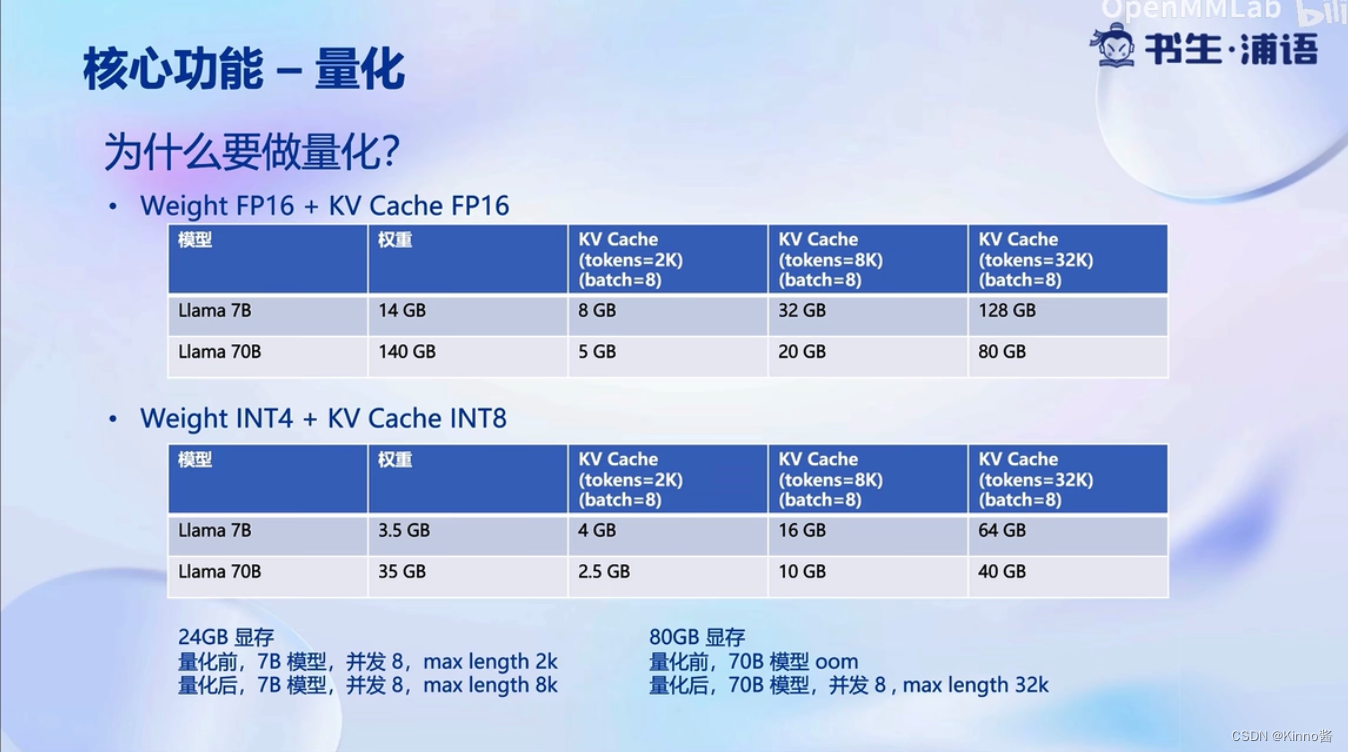
核心功能-量化
显存消耗变少了

大语言模型是典型的访存密集型任务,因为它是decoder-by-decoder
先把数据量化为INT4存起来,算的时候会反量化为FP16
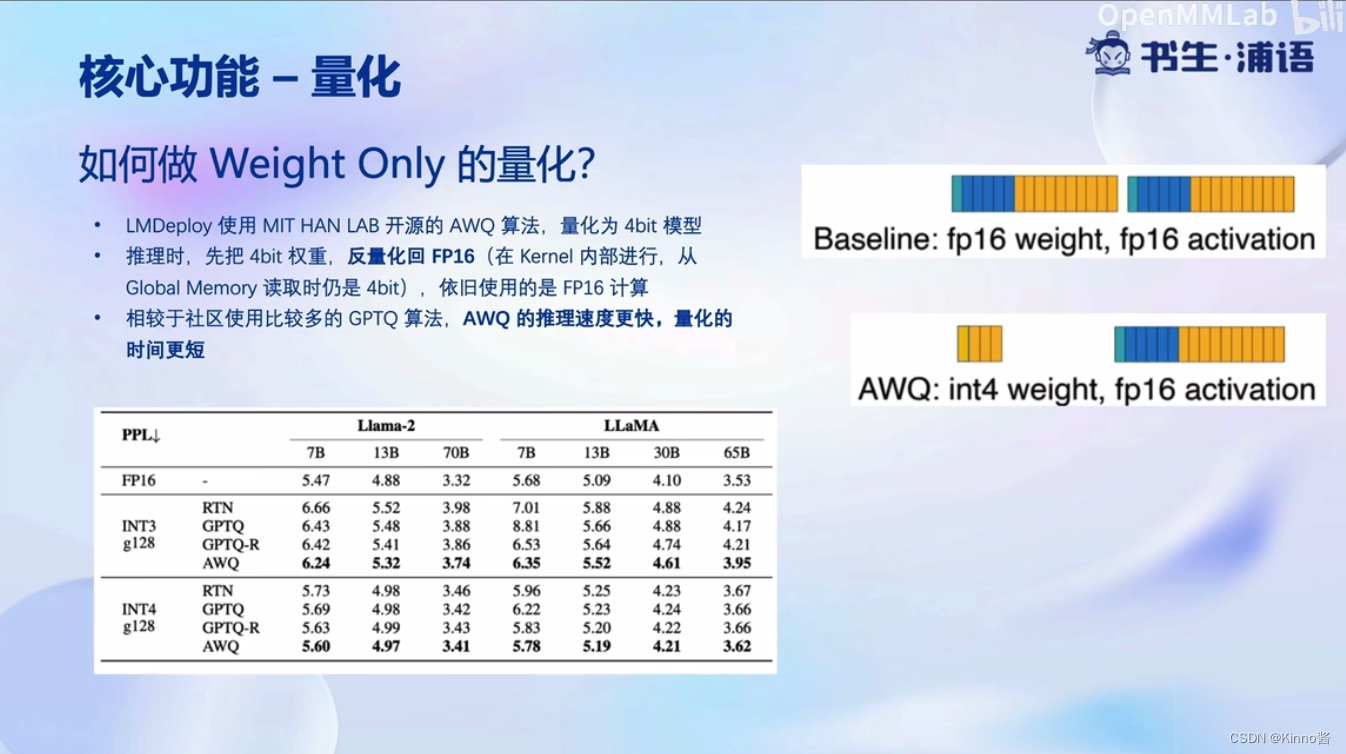
AWQ算法:观察到模型在推理过程中,只有一小部分参数是重要的参数,这部分参数不量化,其他的参数量化,这样保留了显存,性能也不会下降多少
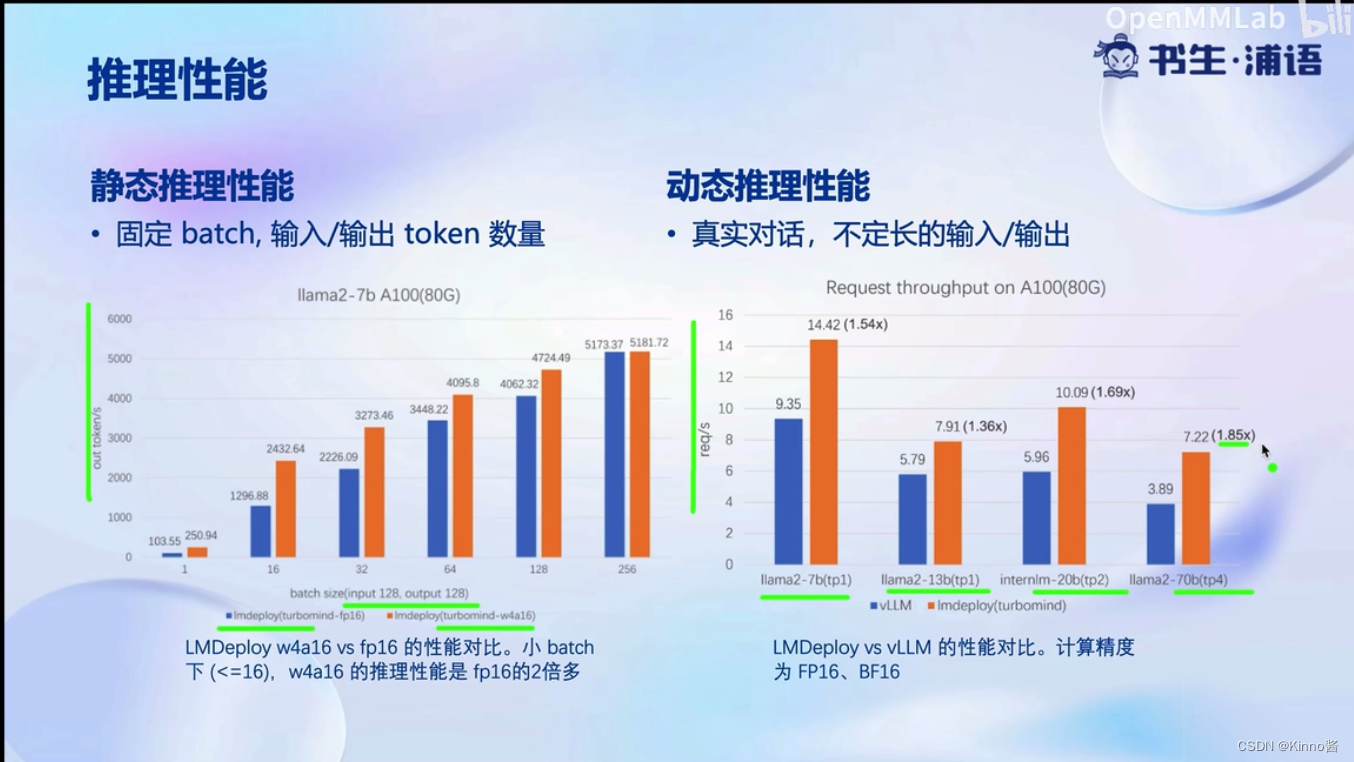
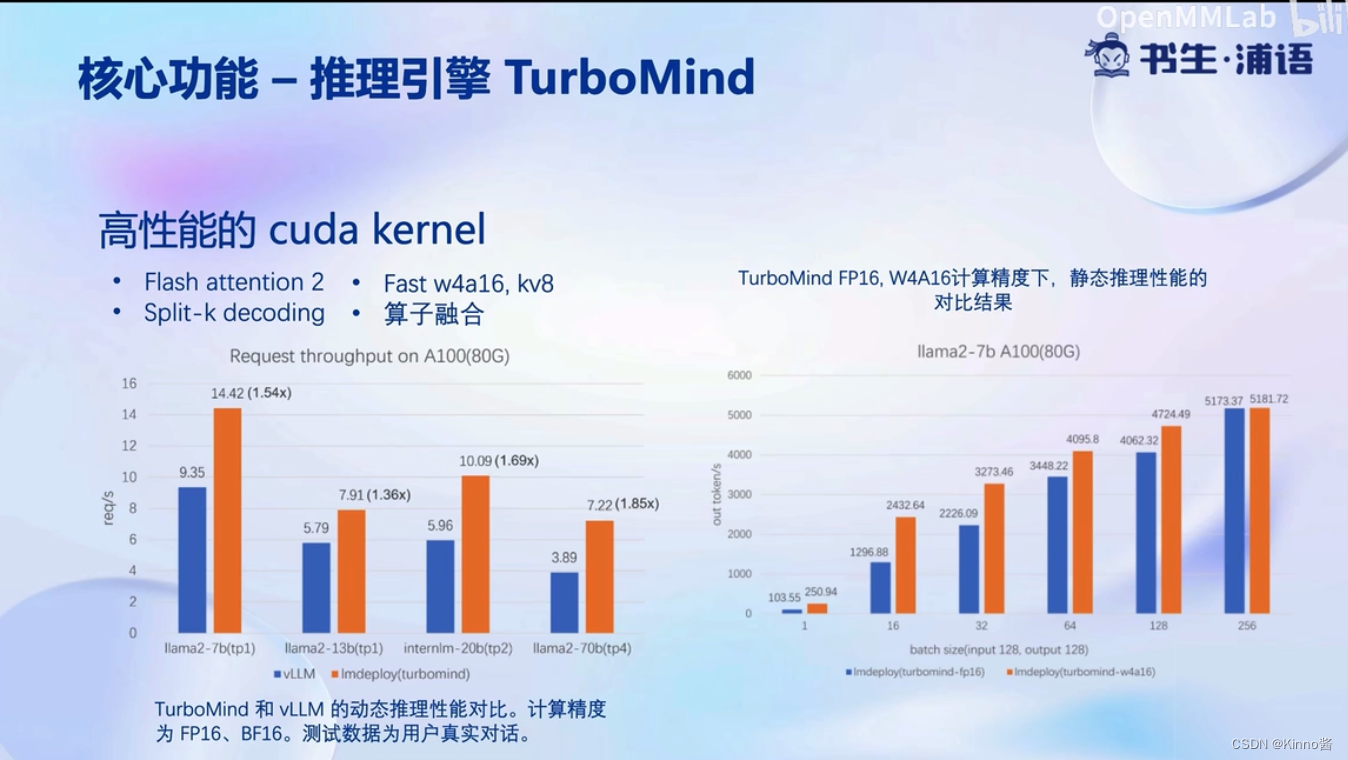
核心功能-推理引擎
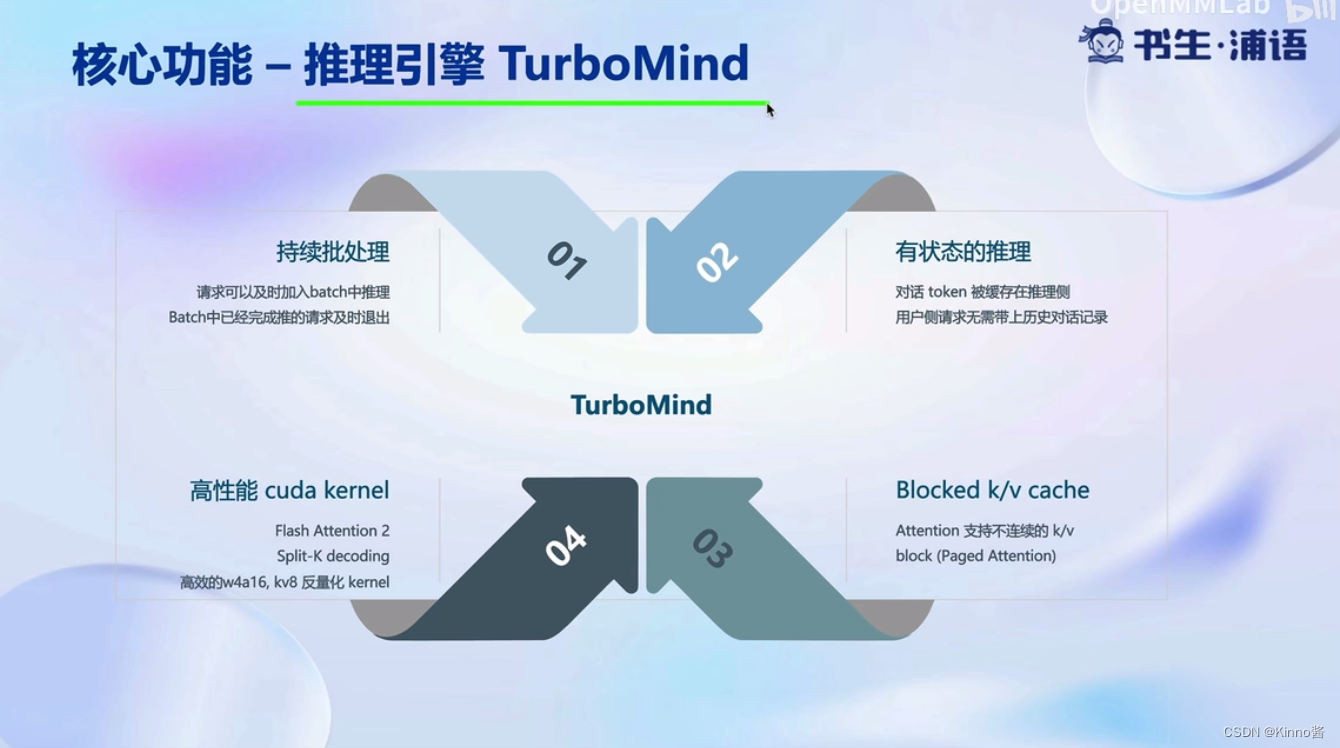
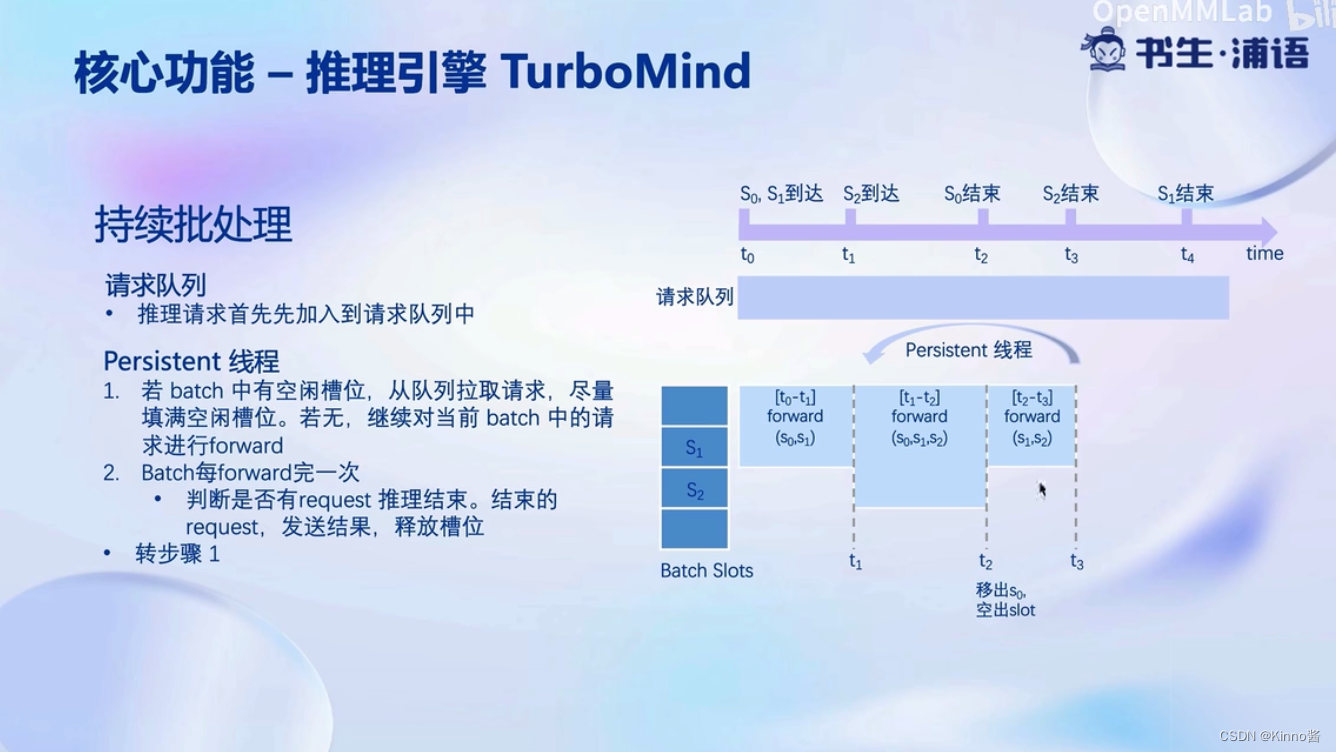
不用等到整个batch结束


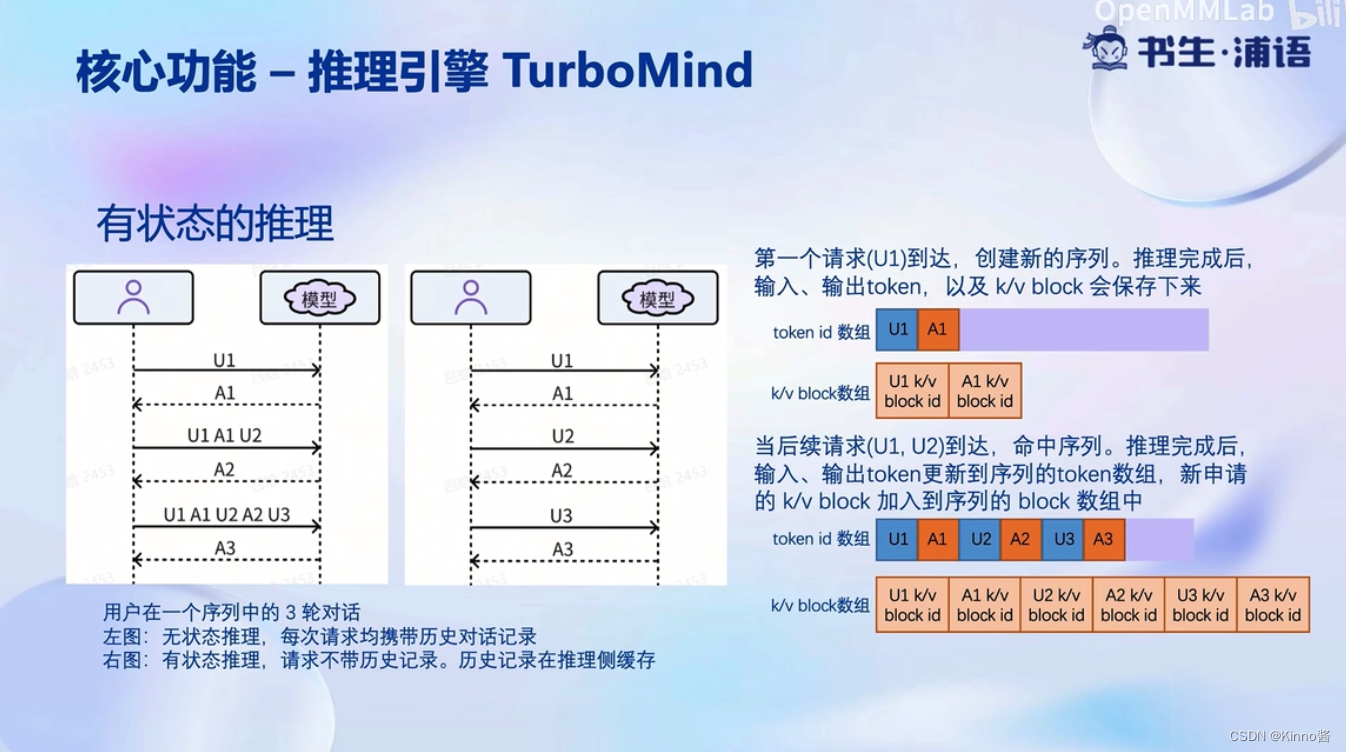
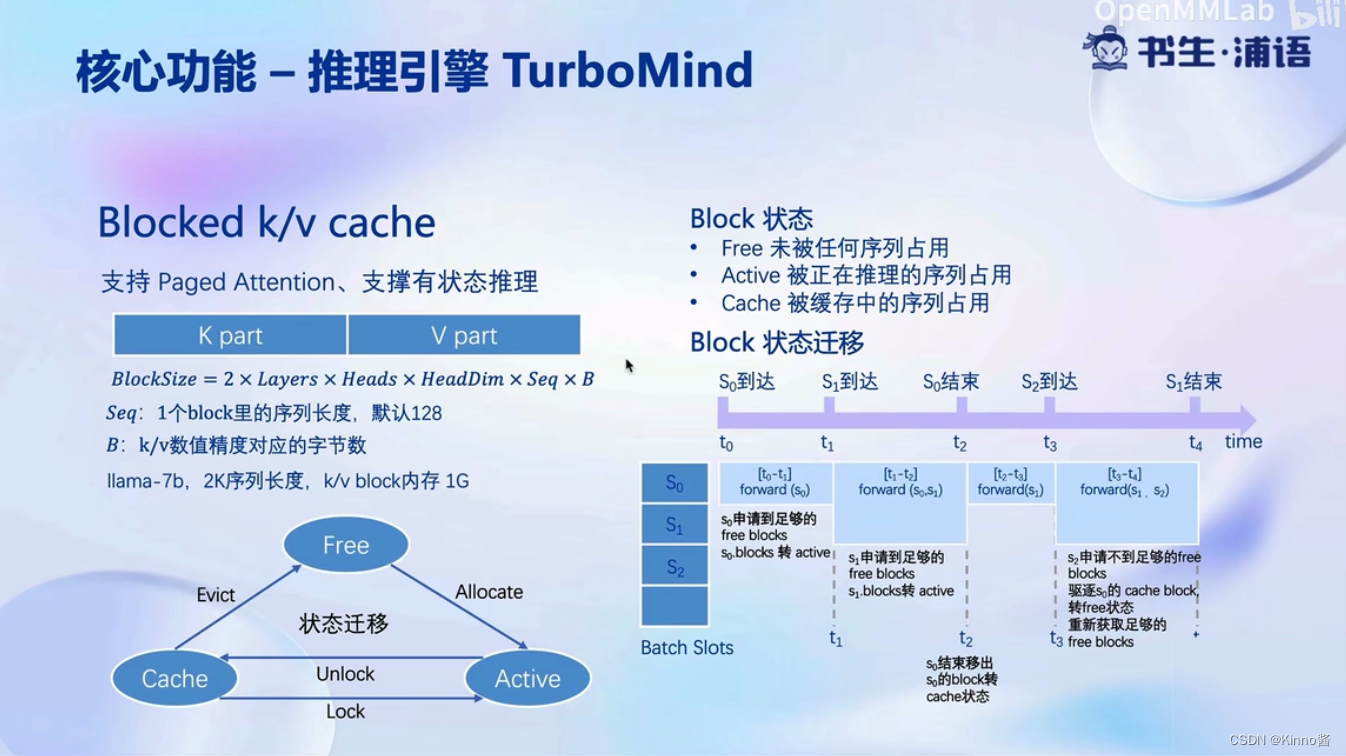
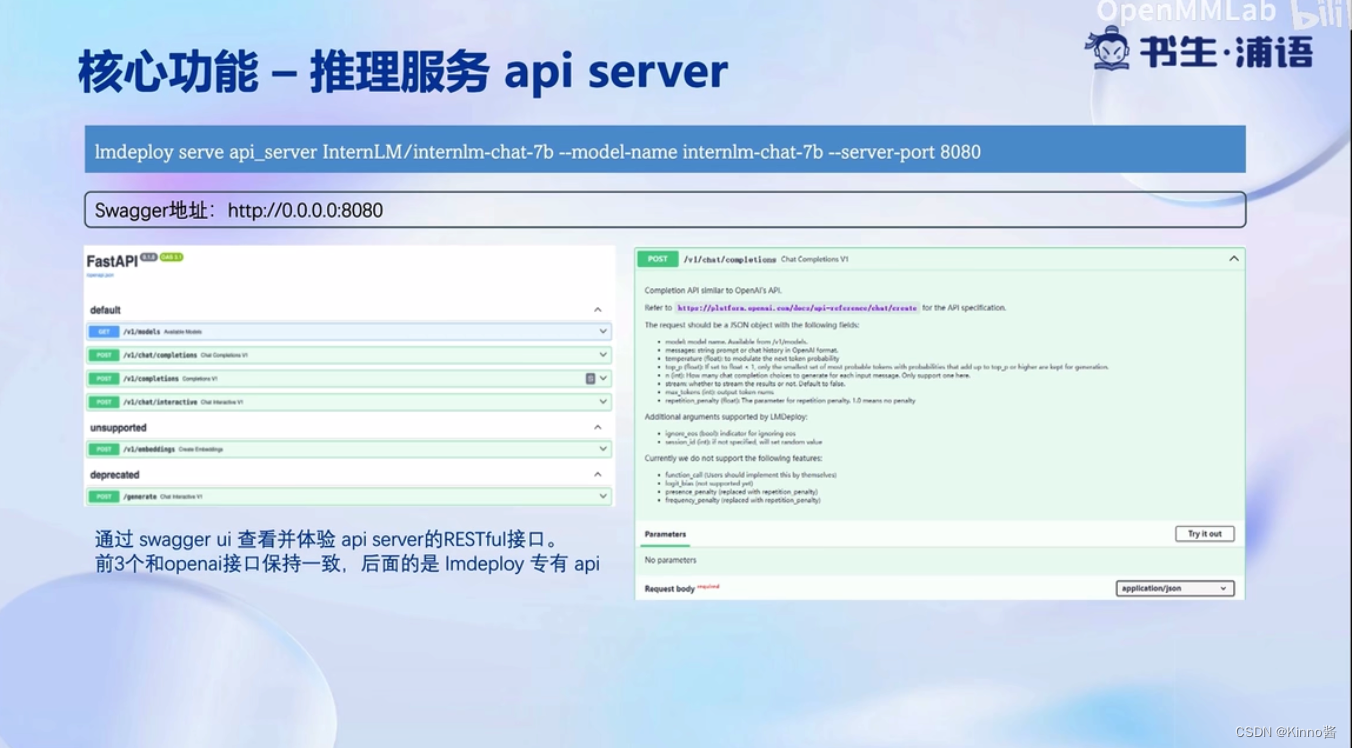
核心功能-推理服务api server
动手实践环节
https://github.com/InternLM/tutorial/blob/main/lmdeploy/lmdeploy.md
文章来源:https://blog.csdn.net/qq_37397652/article/details/135778297
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!