大数据处理与分析-Spark
导论
(基于Hadoop的MapReduce的优缺点)
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架
MapReduce是一种用于处理大规模数据集的编程模型和计算框架。它将数据处理过程分为两个主要阶段:Map阶段和Reduce阶段。在Map阶段,数据被分割为多个小块,并由多个并行运行的Mapper进行处理。在Reduce阶段,Mapper的输出被合并和排序,并由多个并行运行的Reducer进行最终的聚合和计算。MapReduce的优缺点如下:
优点:
??? 可伸缩性:MapReduce可以处理大规模的数据集,通过将数据分割为多个小块并进行并行处理,可以有效地利用集群的计算资源。它可以在需要处理更大数据集时进行水平扩展,而不需要对现有的代码进行修改。
??? 容错性:MapReduce具有高度的容错性。当某个节点发生故障时,作业可以自动重新分配给其他可用的节点进行处理,从而保证作业的完成。
??? 灵活性:MapReduce允许开发人员使用自定义的Mapper和Reducer来处理各种类型的数据和计算任务。它提供了灵活的编程模型,可以根据具体需求进行定制和扩展。
??? 易于使用:MapReduce提供了高级抽象,隐藏了底层的并行和分布式处理细节。开发人员只需要关注数据的转换和计算逻辑,而不需要关心并发和分布式算法的实现细节。
缺点:
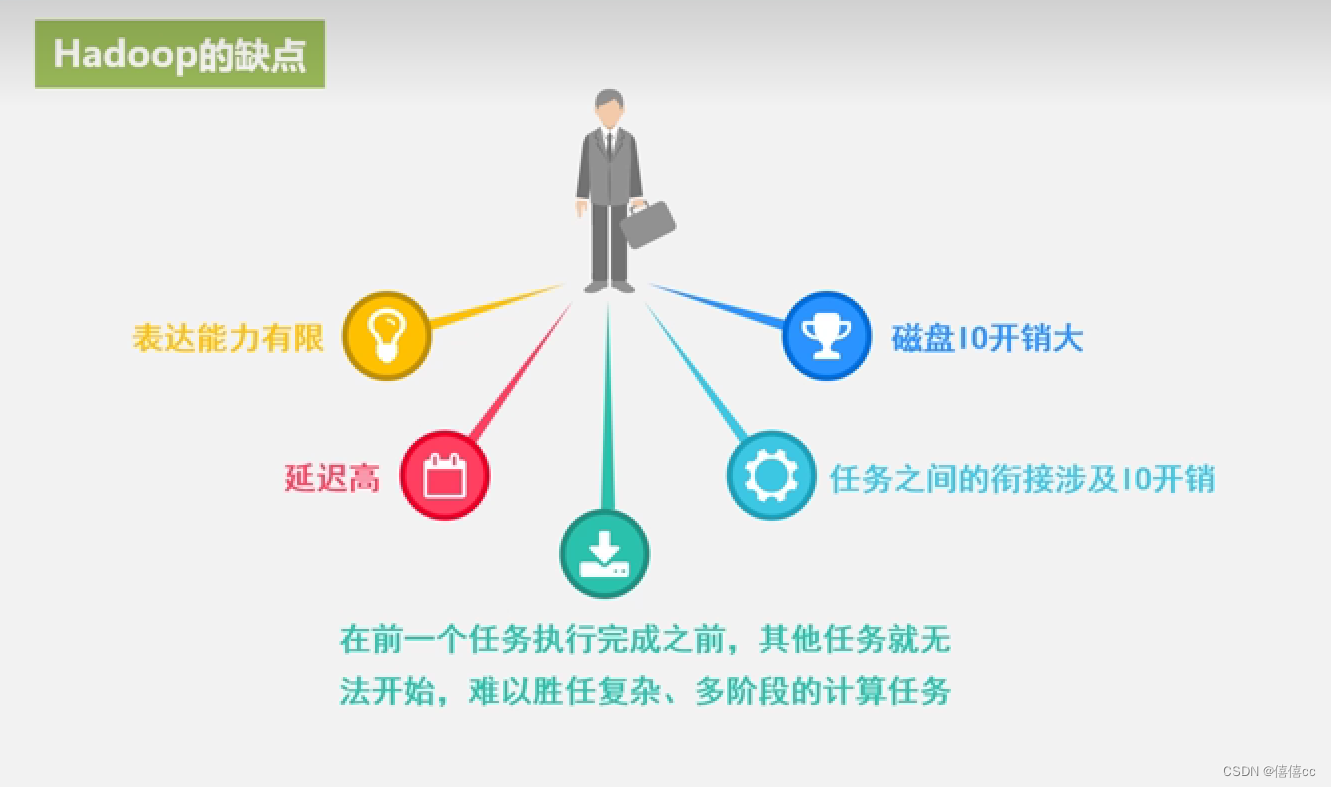
??? 适用性有限:MapReduce适用于一些需要进行大规模数据处理和分析的场景,但对于一些需要实时计算和交互式查询的场景,MapReduce的延迟较高,不太适合。
??? 复杂性:尽管MapReduce提供了高级抽象,但对于开发人员来说,编写和调试MapReduce作业仍然是一项复杂的任务。需要熟悉MapReduce的编程模型和框架,并理解分布式计算的概念和原理。
??? 磁盘IO开销:在MapReduce中,数据需要在Map和Reduce阶段之间进行磁盘IO,这可能会导致性能瓶颈。尽管可以通过合理的数据分区和调优来减少磁盘IO的开销,但仍然需要考虑和处理数据移动和复制的开销。
综上所述,MapReduce是一种适用于大规模数据处理的编程模型和计算框架,具有可伸缩性、容错性、灵活性和易用性等优点。然而,它在实时计算和交互式查询等场景下的适用性有限,同时开发和调试MapReduce作业的复杂性也需要考虑
Spark
一.Spark 基础
1.1 Spark 为何物
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
??? Hadoop 之父 Doug Cutting 指出:Use of MapReduce engine for Big Data projects will decline, replaced by Apache Spark (大数据项目的 MapReduce 引擎的使用将下降,由 Apache Spark 取代)。
spark概述
第一阶段:Spark最初由美国加州伯克利大学( UC Berkelcy)的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序
第二阶段:2013年Spark加入Apache孵化器项日后发展迅猛,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一( Hadoop磁盘MR离线式、Spark基于内存实时数据分析框架、Storm数据流分析框架 )
第三阶段:
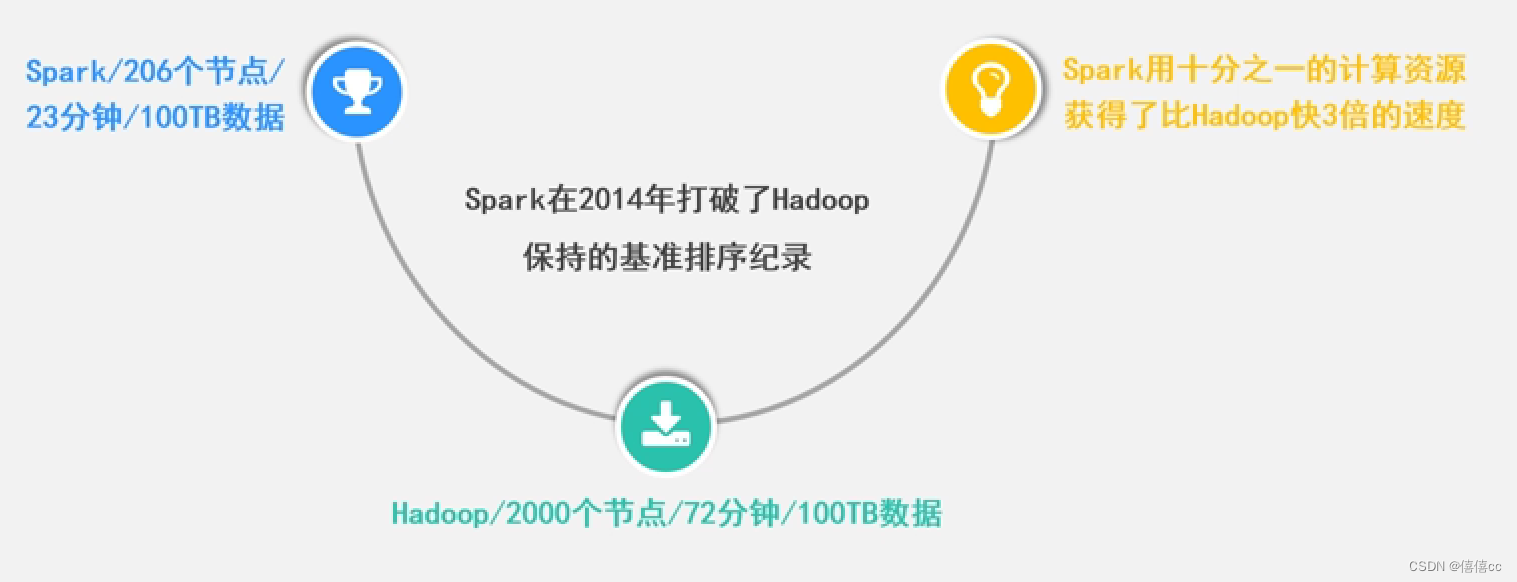
1.3Spark的主要特点

Scala简介
Scala是一门现代的多范式编程语言 ,运行于IAVA平台(JVM,JAVA虚拟机)并兼容现有的JAVA程序

Scala的特点
① Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统。
② Scala语法简洁,能提供优雅的API。
③ Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
二.Spark VS Hadoop
尽管 Spark 相对于 Hadoop 而言具有较大优势,但 Spark 并不能完全替代 Hadoop,Spark 主要用于替代Hadoop中的 MapReduce 计算模型。存储依然可以使用 HDFS,但是中间结果可以存放在内存中;调度可以使用 Spark 内置的,也可以使用更成熟的调度系统 YARN 等。
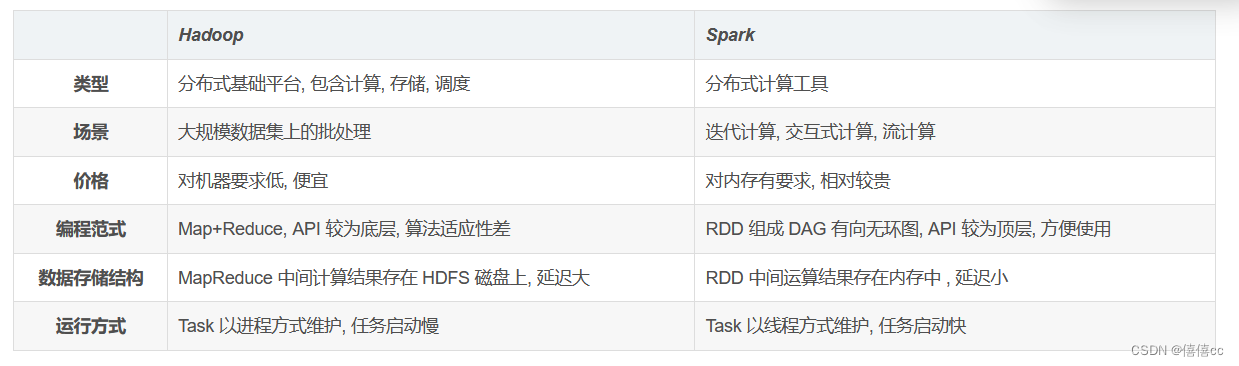
实际上,Spark 已经很好地融入了 Hadoop 生态圈,并成为其中的重要一员,它可以借助于 YARN 实现资源调度管理,借助于 HDFS 实现分布式存储。
此外,Hadoop 可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark 对硬件的要求稍高一些,对内存与 CPU 有一定的要求


Spark生态系统
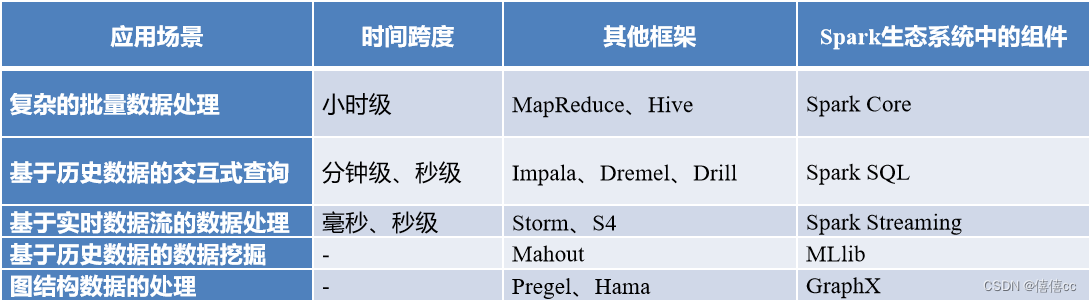
在实际应用中,大数据处理主要包括一下3个类型:
?????? ① 复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间。
?????? ② 基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间。
?????? ③ 基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
当同时存在以上三种场景时,就需要同时部署三种不同的软件



核心组件:

Spark的应用场景
?Spark的运行架构
1.基本概念
在具体讲解Spark运行架构之前,需要先了解以下7个重要的概念。
① RDD:是弹性分布式数据集的英文缩写,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
② DAG:是有向无环图的英文缩写,反映RDD之间的依赖关系。
③ Executor:是运行在工作节点上的一个进程,负责运行任务,并为应用程序存储数据。
④ 应用:用户编写的Spark应用程序。
⑤ 任务:运行在Executor上的工作单元。
⑥ 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作。
⑦ 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”
2.Spark运行架构


(1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点创建一个SparkContext,由SparkContext负责和资源管理器的通信以及进行资源的申请、任务的分配和监控等。SparkContext 会向资源管理器注册并申请运行Executor的资源。
(2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上。
(3)SparkContext 根据 RDD 的依赖关系构建 DAG 图,DAG 图提交给 DAG 调度器进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器进行处理;Executor 向 SparkContext 申请任务,任务调度器将任务分发给 Executor 运行,同时SparkContext将应用程序代码发放给Executor。
(4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
Spark运行架构特点:
1.每个application都有自己专属的Executor进程,并且该进程在application运行期间一直驻留,executor进程以多线程的方式运行Task
2.Spark运行过程与资源管理无关,子要能够获取Executor进程并保持通信即可
3.Task采用了数据本地性和推测执行等优化机制,实现“计算向数据靠拢”
核心-RDD
1.设计背景
1.许多迭代式算法《比如机器学习、图算法等)和交互式数据挖掘工具,共同之处是,不同计算阶段之间会重用中间结果
2.目前的MapReduce框架都是把中间结果写入到磁盘中,带来大量的数据复制、磁盘Io和序列化开销
3.RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据结构
4.我们不必担心底层数据的分布式持性,只需将具体的应用逻辑表达为一系列转换处理
5.不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
RDD概念
1.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,不同节点上进行并行计算
2.RDD提供了一种高度受限的共享内存模型,RDD是只读的记录分区集合,不能直接修改,只能通过在转换的过程中改
RDD典型的执行过程如下

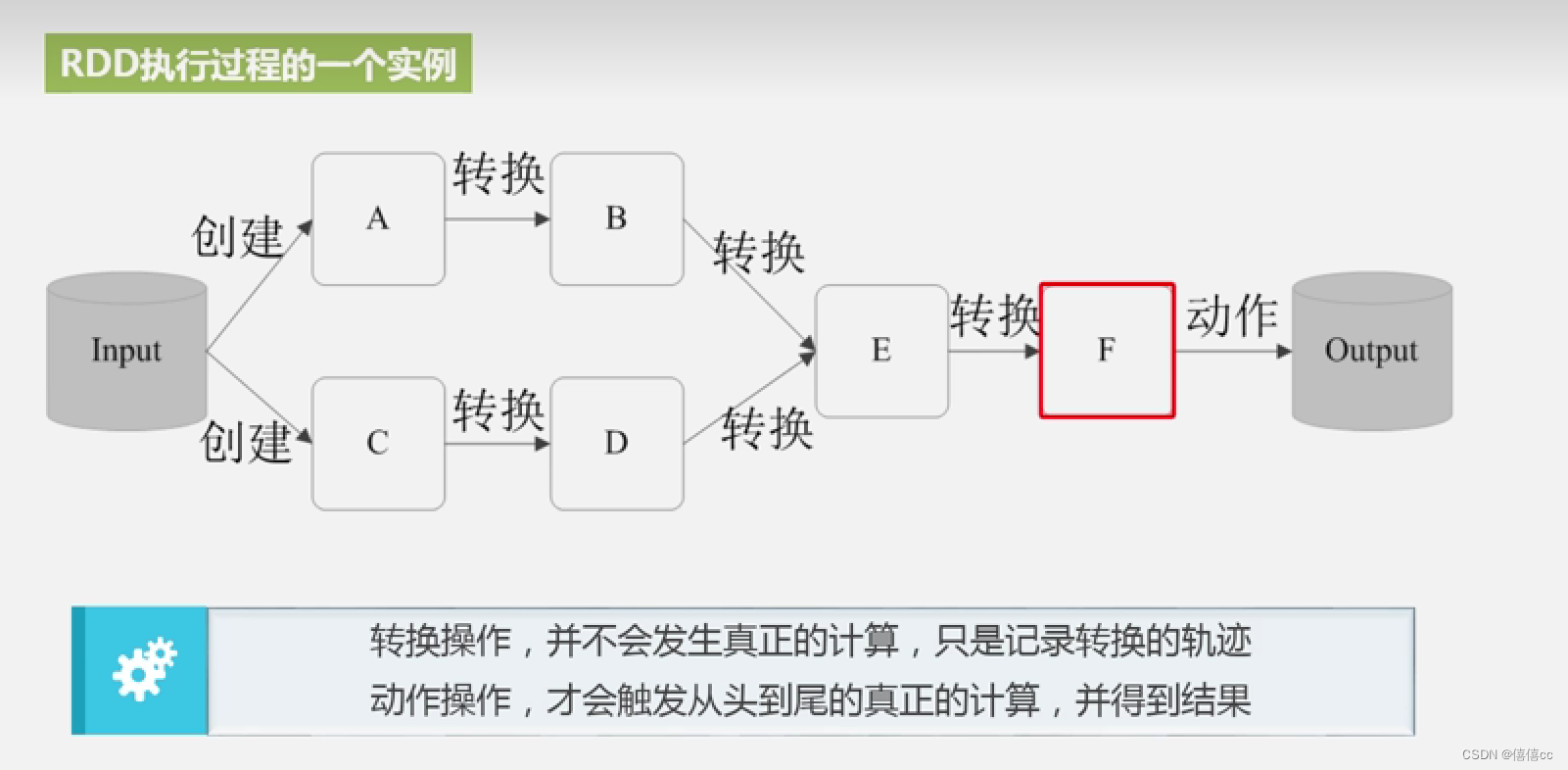
优点:惰性调用,管道化,避免同步等待,不需要保存中间结果,每次操变得简单
RDD特性
1.高效的容错性
现有容错机制:数据复制或者记录日志RDD具有天生的容错性:血缘关系,重新计算丢失分区,无需回滚系统,重算过程在不同节点之间并行,只记录粗粒度的操作
2.中间结果持久化到内存,数据在内存中的多个RDD操作直接按进行传递,避免了不必要的读写磁盘开销
3.存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
RDD之间的依赖关系

父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。

阶段的划分

RDD运行过程
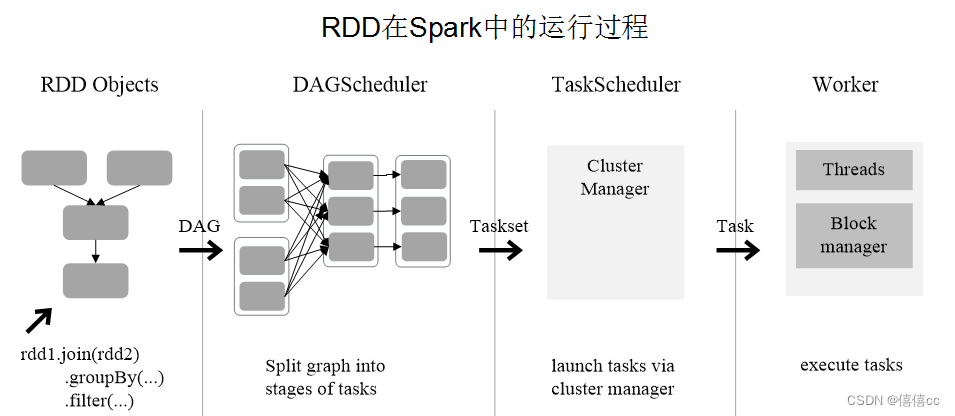
过上述对RDD概念、依赖关系和Stage划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD在Spark架构中的运行过程:
??? (1)创建RDD对象;
??? (2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
??? (3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Qt界面篇:Qt停靠控件QDockWidget、树控件QTreeWidget及属性控件QtTreePropertyBrowser的使用
- 重生奇迹mu武器镶嵌顺序
- show processlist 显示的MySQL语句不全的解决方法
- Alist挂载window11本地教程
- 用友GRP-U8 obr_zdybxd_check.jsp SQL注入漏洞复现
- SpringBoot知识03
- 实用的业务逻辑漏洞
- 电脑pdf如何转换成word格式?用它实现pdf文件一键转换
- 使用Python的requests库在Linux中进行HTTP通信
- Python-扫雷游戏【附完整源码】