pytorch09:可视化工具-TensorBoard,实现卷积核和特征图可视化

目录
一、TensorBoard简介
当我们在模型训练过程中想要将部分参数进行可视化,例如:精确度、损失等参数,想通过一个可视化工具实时观察,可以使用tensorboard工具。

在使用pytorch进行一些深度学习测试的过程中,首先将生成的数据使用Python脚本进行保存,将数据保存到电脑硬盘当中,然后使用tensorboard将硬盘中的数据绘制成图,在浏览器端展示出来。
二、TensorBoard安装
打开终端,进入到项目所在的虚拟环境当中输入以下安装命令。
安装命令:
pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
三、TensorBoard运行可视化
代码案例:
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard') # 使用SummaryWriter记录我们想要可视化的数据
for x in range(100):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow(2, x)', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
执行该代码会在当前代码文件夹目录下生成一个runs文件夹,该文件夹目录下保存的就是使用tensorboard中方法保存的可视化文件。

打开pycharm自带的终端,输入以下命令 tensorboard --logdir=./05-02-代码-TensorBoard简介与安装/lesson-20/runs
注意:logdir后面的文件夹路径一定要输入正确,然后会在终端显示一个本地端口号

点击端口号就能跳转到浏览器,观看到可视化界面,我们代码中的三个函数都进行可绘图可视化。

四、TensorBoard详细使用
4.1 SummaryWriter

功能:提供创建event file的高级接口
主要属性:
? log_dir:event file输出文件夹
? comment:不指定log_dir时,文件夹后缀
? filename_suffix:event file文件名后缀
代码实现:
flag = 1
if flag:
log_dir = "./train_log/test_log_dir" # 指定可视化文件保存路径
writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
# writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
文件创建结果:
文件指定路径train_log/test_log_dir,生成的event 文件后缀名为12345678,_scalars并没有出现在路径当中,因为我们设置log_dir 指定路径。

不使用log_dir代码实现
flag = 1
if flag:
log_dir = "./train_log/test_log_dir" # 指定可视化文件保存路径
# writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
文件创建结果:
创建的文件夹带有comment指定后缀名_scalars。

4.2 add_scalar()

功能:记录标量
? tag:图像的标签名,图的唯一标识
? scalar_value:要记录的标量
? global_step:x轴
该方法有一定局限性,只能记录一条曲线,所以一般我们不使用该方法
4.3 add_scalars()

功能:记录多个标量,可以绘制多条曲线。
? main_tag:该图的标签。
? tag_scalar_dict:key是变量的tag,value是变量的值,使用字典的形式去记录多条曲线。
scalar 和 scalars代码实现
flag = 1
if flag:
max_epoch = 100
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x)}, x) #字典存储的两个函数
writer.close()
可视化结果:

4.4 add_histogram()

功能:统计参数直方图与多分位数折线图
? tag:图像的标签名,图的唯一标识。
? values:要统计的参数,可以是权重、偏执或者是梯度。
? global_step:y轴。
? bins:取直方图的bins。
代码实现1:
flag = 1
if flag:
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(2):
np.random.seed(x)
data_union = np.arange(100)
data_normal = np.random.normal(size=1000) #1000个数据正态分布
writer.add_histogram('distribution union', data_union, x) # 使用tensorboard绘制直方图
writer.add_histogram('distribution normal', data_normal, x)
plt.subplot(121).hist(data_union, label="union") # 使用plt绘制直方图
plt.subplot(122).hist(data_normal, label="normal")
plt.legend()
plt.show()
writer.close()
plt直方图两次绘制结果:


tensorboard两次绘制结果:

4.4.1实际项目开发使用
代码实现:
将训练、验证过程中的损失已经精度都使用add_scalars写入进去,同时将每一个epoch的梯度都使用add_histogram方法添加。
# -*- coding:utf-8 -*-
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import torch.optim as optim
from matplotlib import pyplot as plt
from lenet import LeNet
from my_dataset import RMBDataset
from common_tools import set_seed
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
iter_count = 0
# 构建 SummaryWriter
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
iter_count += 1
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i + 1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i + 1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
# 记录数据,保存于event file
writer.add_scalars("Loss", {"Train": loss.item()}, iter_count)
writer.add_scalars("Accuracy", {"Train": correct / total}, iter_count)
# 每个epoch,记录梯度,权值
# net.named_parameters() 返回我们的参数以及对应的名字
for name, param in net.named_parameters():
writer.add_histogram(name + '_grad', param.grad, epoch)
writer.add_histogram(name + '_data', param, epoch)
scheduler.step() # 更新学习率
# validate the model
if (epoch + 1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss.item())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j + 1, len(valid_loader), loss_val, correct / total))
# 记录数据,保存于event file
writer.add_scalars("Loss", {"Valid": np.mean(valid_curve)}, iter_count)
writer.add_scalars("Accuracy", {"Valid": correct / total}, iter_count)
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve) + 1) * train_iters * val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
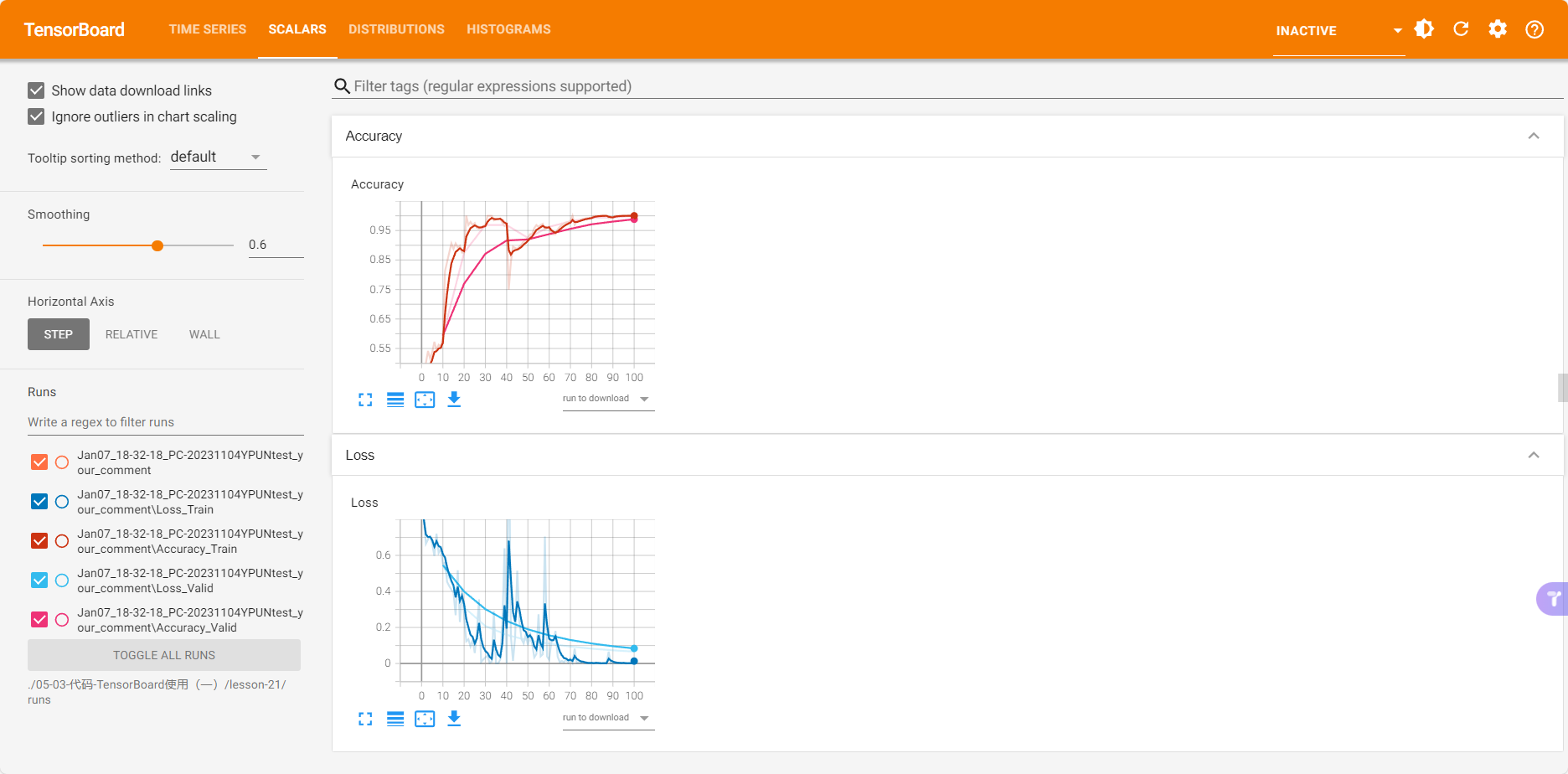
训练精度和验证集精度(图1),以及训练损失和验证集损失(图2)
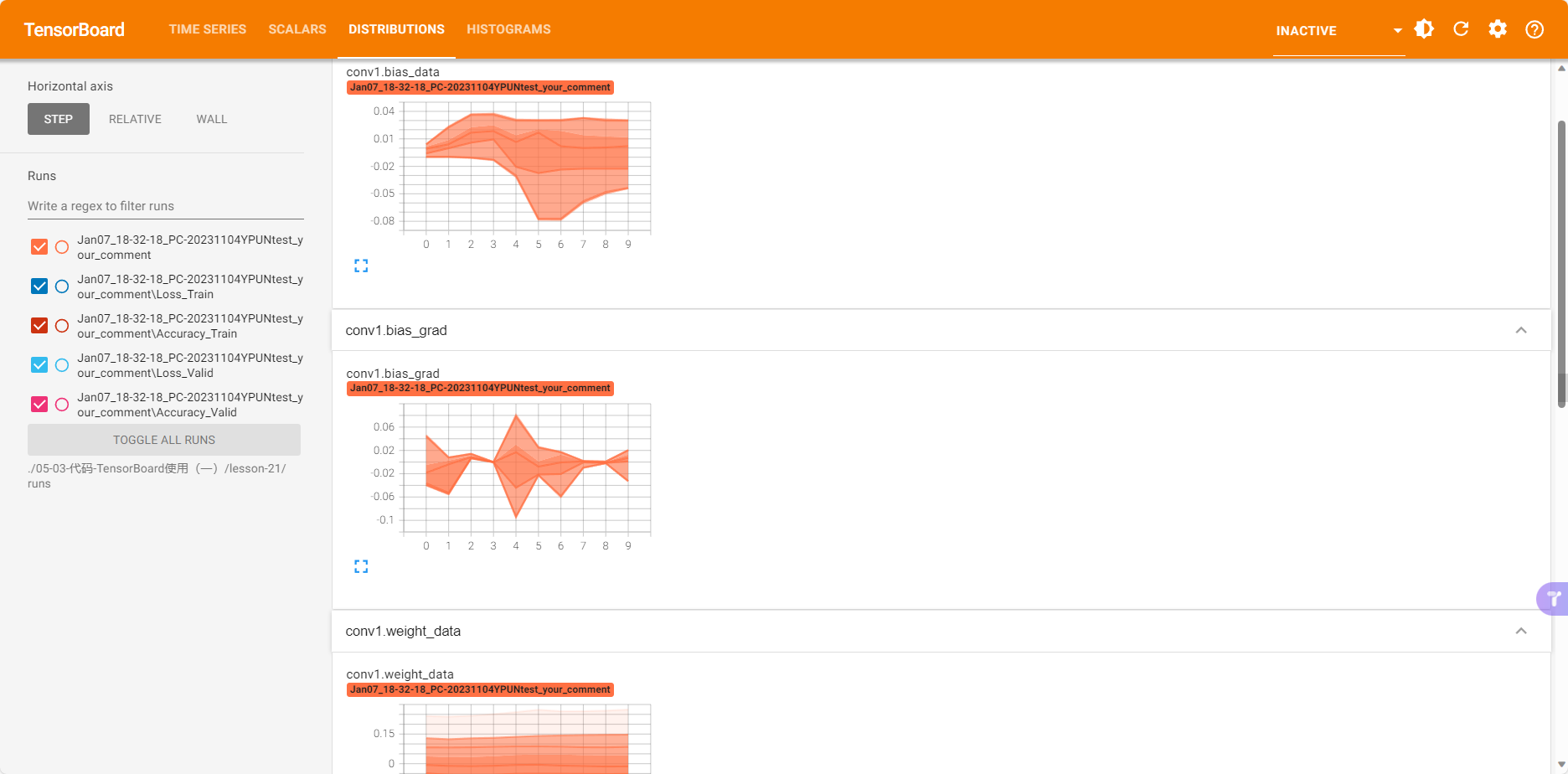
训练过程中的参数分布
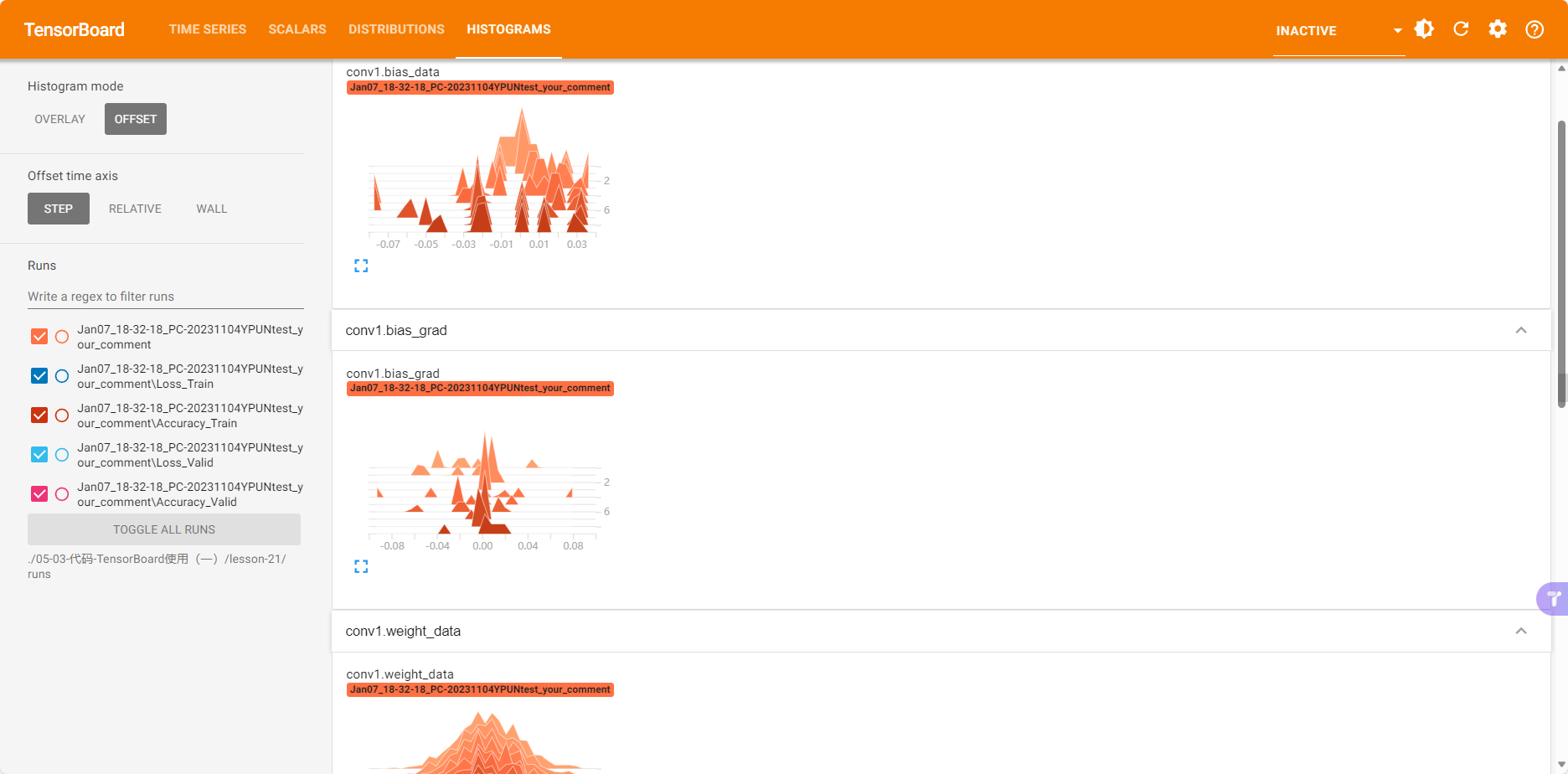
直方图分布情况
会发现越往下,梯度值越小,因为梯度是loss的导数,loss随着epoch的增加减少,所以越往后梯度也就越小。
4.5 add_image()
功能:记录图像

? tag:图像的标签名,图的唯一标识
? img_tensor:图像数据,注意尺度
? global_step:x轴
? dataformats:数据形式,CHW,HWC,HW
代码实现:
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# img 1 random
fake_img = torch.randn(3, 512, 512)
writer.add_image("fake_img", fake_img, 1)
time.sleep(1)
# img 2 ones
fake_img = torch.ones(3, 512, 512)
time.sleep(1)
writer.add_image("fake_img", fake_img, 2)
# img 3 1.1
fake_img = torch.ones(3, 512, 512) * 1.1
time.sleep(1)
writer.add_image("fake_img", fake_img, 3)
# img 4 HW
fake_img = torch.rand(512, 512) # 灰度图
writer.add_image("fake_img", fake_img, 4, dataformats="HW")
# img 5 HWC
fake_img = torch.rand(512, 512, 3)
writer.add_image("fake_img", fake_img, 5, dataformats="HWC")
writer.close()
展示结果:

4.6 torchvision.utils.make_grid
功能:制作网格图像
? tensor:图像数据, BCH*W形式,pytorch训练图像格式
? nrow:行数(列数自动计算)
? padding:图像间距(像素单位),也就是网格线的宽度
? normalize:是否将像素值标准化,0~225之间
? range:标准化范围
? scale_each:是否单张图维度标准化
? pad_value:padding的像素值,也就是网格线的颜色
代码实现:
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
split_dir = os.path.join("rmb_split")
train_dir = os.path.join(split_dir, "train")
transform_compose = transforms.Compose([transforms.Resize((32, 64)), transforms.ToTensor()])
train_data = RMBDataset(data_dir=train_dir, transform=transform_compose)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data_batch, label_batch = next(iter(train_loader)) # 取出一个batch数据,data_batch图片数据以及数据标签
img_grid = vutils.make_grid(data_batch, nrow=4, normalize=True, scale_each=True)
writer.add_image("input img", img_grid, 0)
writer.close()
展示结果:

4.7 卷积核和特征图可视化
4.7.1 AlexNet卷积核可视化
代码实现:
对单个卷积核的三个通道图展示,以及对64个卷积核直接进行可视化。
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
alexnet = models.alexnet(pretrained=True) # 获取一个预训练好的alexnet
kernel_num = -1 # 当前第几个卷积核层
vis_max = 1 # 最大可视化卷积层
for sub_module in alexnet.modules(): # 递归当前网络下的所有网络层
if isinstance(sub_module, nn.Conv2d): # 判断当前递归的网络层是否是卷积层
kernel_num += 1
if kernel_num > vis_max: # 只展示前两个卷积层
break
kernels = sub_module.weight # 获取当前卷积核的权重
c_out, c_int, k_w, k_h = tuple(kernels.shape)
# 对c_out单独可视化
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度
kernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
# 对64个卷积核直接进行可视化
kernel_all = kernels.view(-1, 3, k_h, k_w) # b,3, h, w
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=322)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
writer.close()
展示结果:

4.7.2 特征图可视化
代码实现:
将经过第一层卷积之后的特征图展示出来;
# ----------------------------------- 特征图可视化 -----------------------------------
# flag = 0
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "3.jpg" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
# 图片预处理
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(normMean, normStd)
])
# 将图片转换成RGB格式
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
# 增加一个维度
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# forward
convlayer1 = alexnet.features[0] # 获取第一个卷积层
fmap_1 = convlayer1(img_tensor) # 将图片交给第一个卷积层进行处理
# 预处理 希望batch能够大一些
fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)
fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=322)
writer.close()
展示结果:
4.8 add_graph()
功能:可视化模型计算图

? model:模型,必须是 nn.Module
? input_to_model:输出给模型的数据
? verbose:是否打印计算图结构信息
代码实现:
flag = 1
if flag:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 模型
fake_img = torch.randn(1, 3, 32, 32)
lenet = LeNet(classes=2)
writer.add_graph(lenet, fake_img)
writer.close()
展示结果:

五、summary网络查看工具
功能:查看模型信息,便于调试,用于观察网络结构很好的工具。

? model:pytorch模型
? input_size:模型输入size
? batch_size:batch size
? device:“cuda” or “cpu”
代码实现:
from torchsummary import summary
lenet = LeNet(classes=2)
print(summary(lenet, (3, 32, 32), device="cpu"))
输出结果:

第一层456个参数是如何计算的?
LeNet网络结构如下,可以看出第一层网络input通道数为3,output输出通道数为6,卷积核大小为5x5,所以参数量为6x3x5x5=450,因为加了6个bias,所以总参数量为456.

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于标准库中的 stack / queue / 优先级队列(涉及部分仿函数,deque)
- 【头歌-数据分析与实践-python】数据分析与实践-python——python基础
- HTML5的完整学习笔记
- 如何启动、停止rocketmq
- Pytest用例执行顺序和跳过执行详解
- 精进单元测试技能——Pytest断言的艺术
- sqlite | c++ | demo
- 美业分销小程序开发案例分销
- Linux系统管理命令---- at 命令
- shell 计算两个数据百分比,bc高级运算,bc计算系统磁盘剩余内存