Kafka消息延迟和时序性详解(文末送书)

大家好,我是哪吒。
文末送5本《从零开始学架构:照着做,你也能成为架构师》

一、概括
1.1 介绍 Kafka 消息延迟和时序性
Kafka 消息延迟和时序性对于大多数实时数据流应用程序至关重要。本章将深入介绍这两个核心概念,它们是了解 Kafka 数据流处理的关键要素。
1.1.1 什么是 Kafka 消息延迟?
Kafka 消息延迟是指消息从生产者发送到消息被消费者接收之间的时间差。这是一个关键的概念,因为它直接影响到数据流应用程序的实时性和性能。在理想情况下,消息应该以最小的延迟被传递,但在实际情况中,延迟可能会受到多种因素的影响。

消息延迟的因素包括:
-
网络延迟:消息必须通过网络传输到 Kafka 集群,然后再传输到消费者。网络延迟可能会受到网络拓扑、带宽和路由等因素的影响。
-
硬件性能:Kafka 集群的硬件性能,包括磁盘、内存和 CPU 的速度,会影响消息的写入和读取速度。
-
Kafka 内部处理:Kafka 集群的内部处理能力也是一个关键因素。消息必须经过分区、日志段和复制等处理步骤,这可能会引入一些处理延迟。
1.1.2 为什么消息延迟很重要?
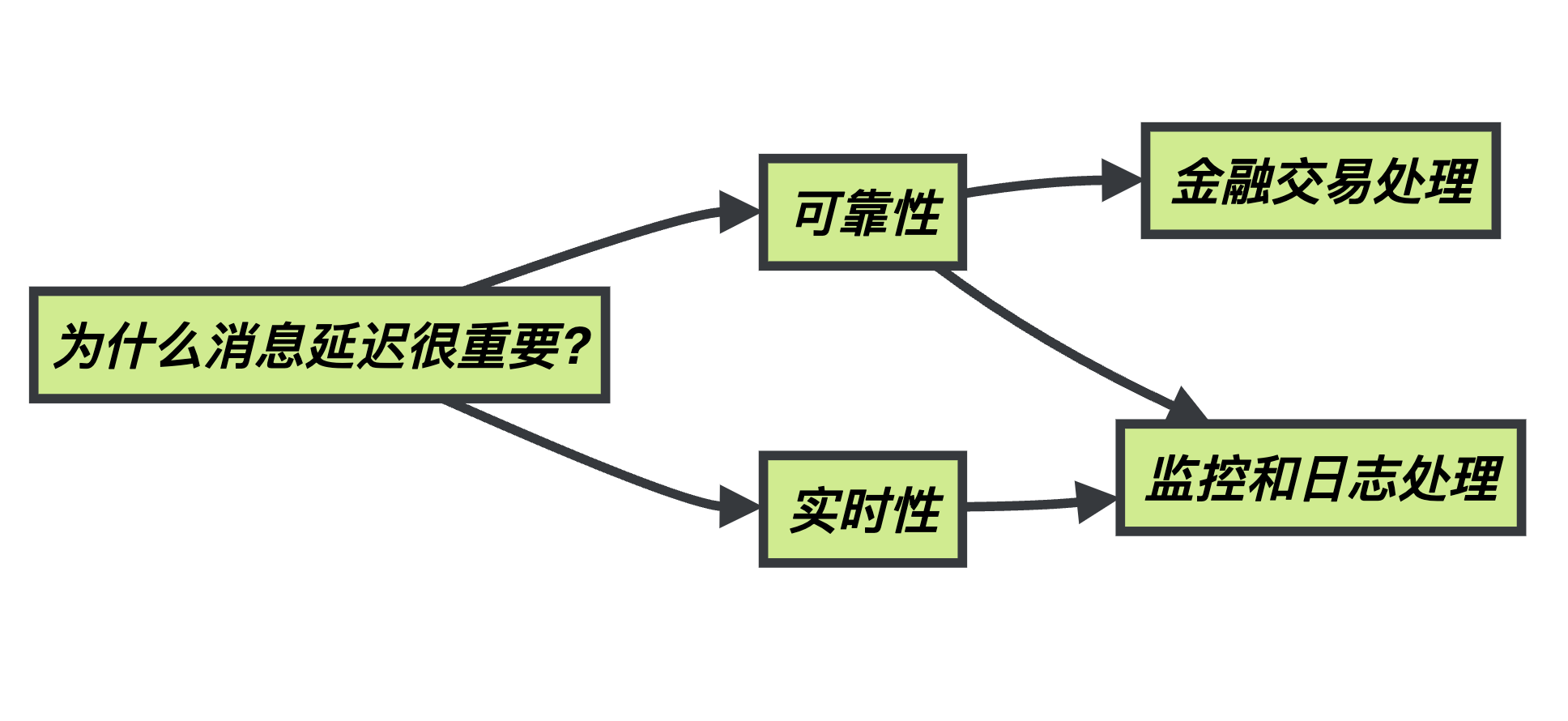
消息延迟之所以如此重要,是因为它直接关系到实时数据处理应用程序的可靠性和实时性。在一些应用中,如金融交易处理,甚至毫秒级的延迟都可能导致交易失败或不一致。在监控和日志处理应用中,过高的延迟可能导致数据不准确或失去了时序性。
管理和优化 Kafka 消息延迟是确保应用程序在高负载下仍能快速响应的关键因素。不仅需要了解延迟的来源,还需要采取相应的优化策略。
1.1.3 什么是 Kafka 消息时序性?
Kafka 消息时序性是指消息按照它们发送的顺序被接收。这意味着如果消息 A 在消息 B 之前发送,那么消息 A 应该在消息 B 之前被消费。保持消息的时序性对于需要按照时间顺序处理的应用程序至关重要。
维护消息时序性是 Kafka 的一个强大特性。在 Kafka 中,每个分区都可以保证消息的时序性,因为每个分区内的消息是有序的。然而,在多个分区的情况下,时序性可能会受到消费者处理速度不一致的影响,因此需要采取一些策略来维护全局的消息时序性。
1.1.4 消息延迟和时序性的关系
消息延迟和消息时序性之间存在密切的关系。如果消息延迟过大,可能会导致消息失去时序性,因为一条晚到的消息可能会在一条早到的消息之前被处理。因此,了解如何管理消息延迟也包括了维护消息时序性。
在接下来的章节中,我们将深入探讨如何管理和优化 Kafka 消息延迟,以及如何维护消息时序性,以满足实时数据处理应用程序的需求。
1.2 延迟的来源
为了有效地管理和优化 Kafka 消息延迟,我们需要深入了解延迟可能来自哪些方面。下面是一些常见的延迟来源:
1.2.1 Kafka 内部延迟
Kafka 内部延迟是指与 Kafka 内部组件和分区分配相关的延迟。这些因素可能会影响消息在 Kafka 内部的分发、复制和再平衡。
-
分区分布不均:如果分区分布不均匀,某些分区可能会变得拥挤,而其他分区可能会滞后,导致消息传递延迟。
-
复制延迟:在 Kafka 中,消息通常会进行复制以确保冗余。复制延迟是指主题的所有副本都能复制消息所需的时间。
-
再平衡延迟:当 Kafka 集群发生再平衡时,消息的重新分配和复制可能导致消息传递延迟。
二、衡量和监控消息延迟
在本节中,我们将深入探讨如何度量和监控 Kafka 消息延迟,这将帮助你更好地了解问题并采取相应的措施来提高延迟性能。
2.1 延迟的度量
为了有效地管理 Kafka 消息延迟,首先需要能够度量它。下面是一些常见的延迟度量方式:
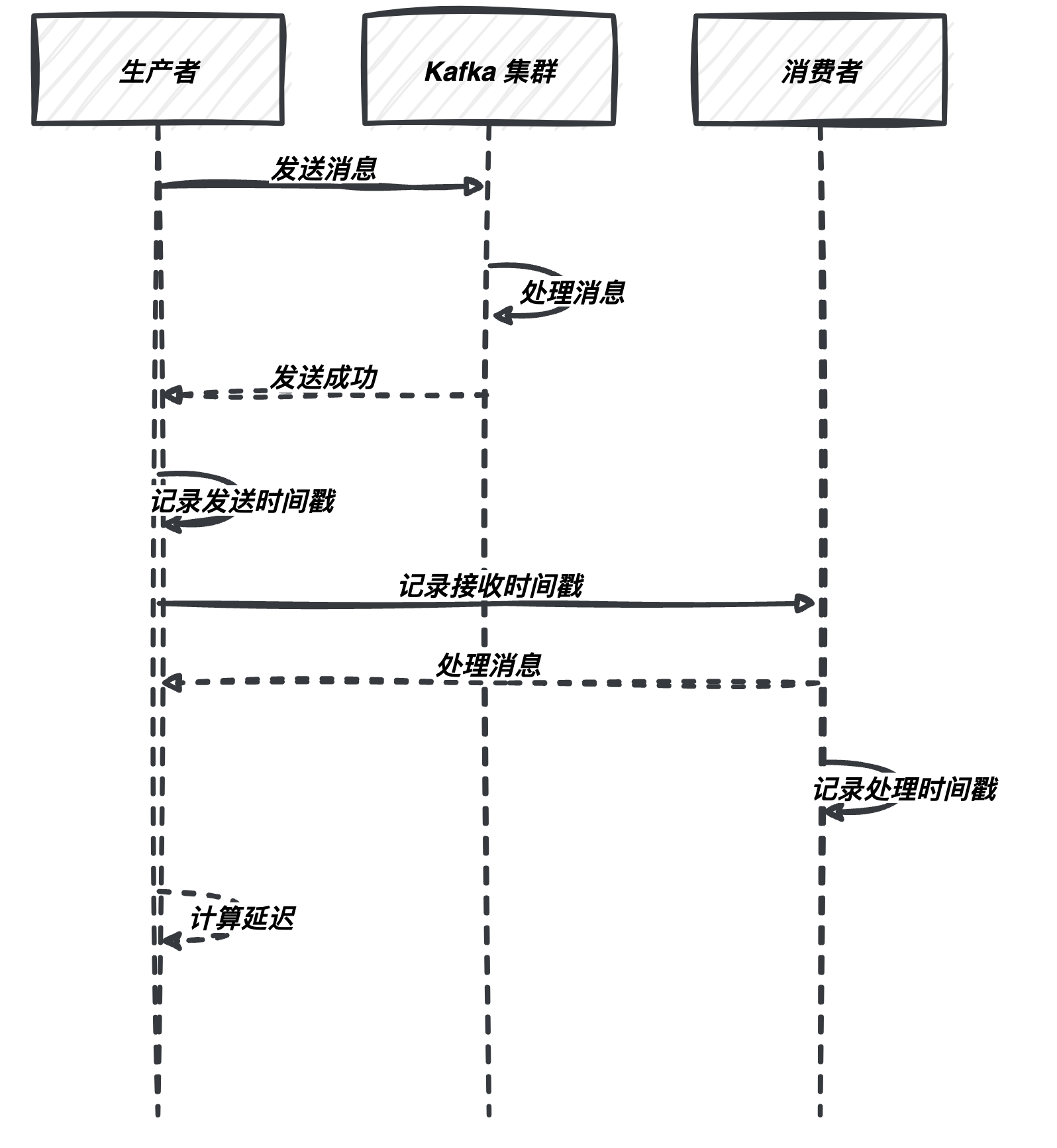
2.1.1 生产者到 Kafka 延迟
这是指消息从生产者发送到 Kafka 集群之间的延迟。为了度量这一延迟,你可以采取以下方法:
- 记录发送时间戳:在生产者端,记录每条消息的发送时间戳。一旦消息成功写入 Kafka,记录接收时间戳。然后,通过将这两个时间戳相减,你可以获得消息的生产者到 Kafka 的延迟。
以下是如何记录发送和接收时间戳的代码示例:
// 记录消息发送时间戳
long sendTimestamp = System.currentTimeMillis();
ProducerRecord<String, String> record = new ProducerRecord<>("my_topic", "key", "value");
producer.send(record, (metadata, exception) -> {
if (exception == null) {
long receiveTimestamp = System.currentTimeMillis();
long producerToKafkaLatency = receiveTimestamp - sendTimestamp;
System.out.println("生产者到 Kafka 延迟:" + producerToKafkaLatency + " 毫秒");
} else {
System.err.println("消息发送失败: " + exception.getMessage());
}
});
2.1.2 Kafka 内部延迟
Kafka 内部延迟是指消息在 Kafka 集群内部传递的延迟。你可以使用 Kafka 内置度量来度量它,包括:
- Log End-to-End Latency:这是度量消息从生产者发送到消费者接收的总延迟。它包括了网络传输、分区复制、再平衡等各个环节的时间。
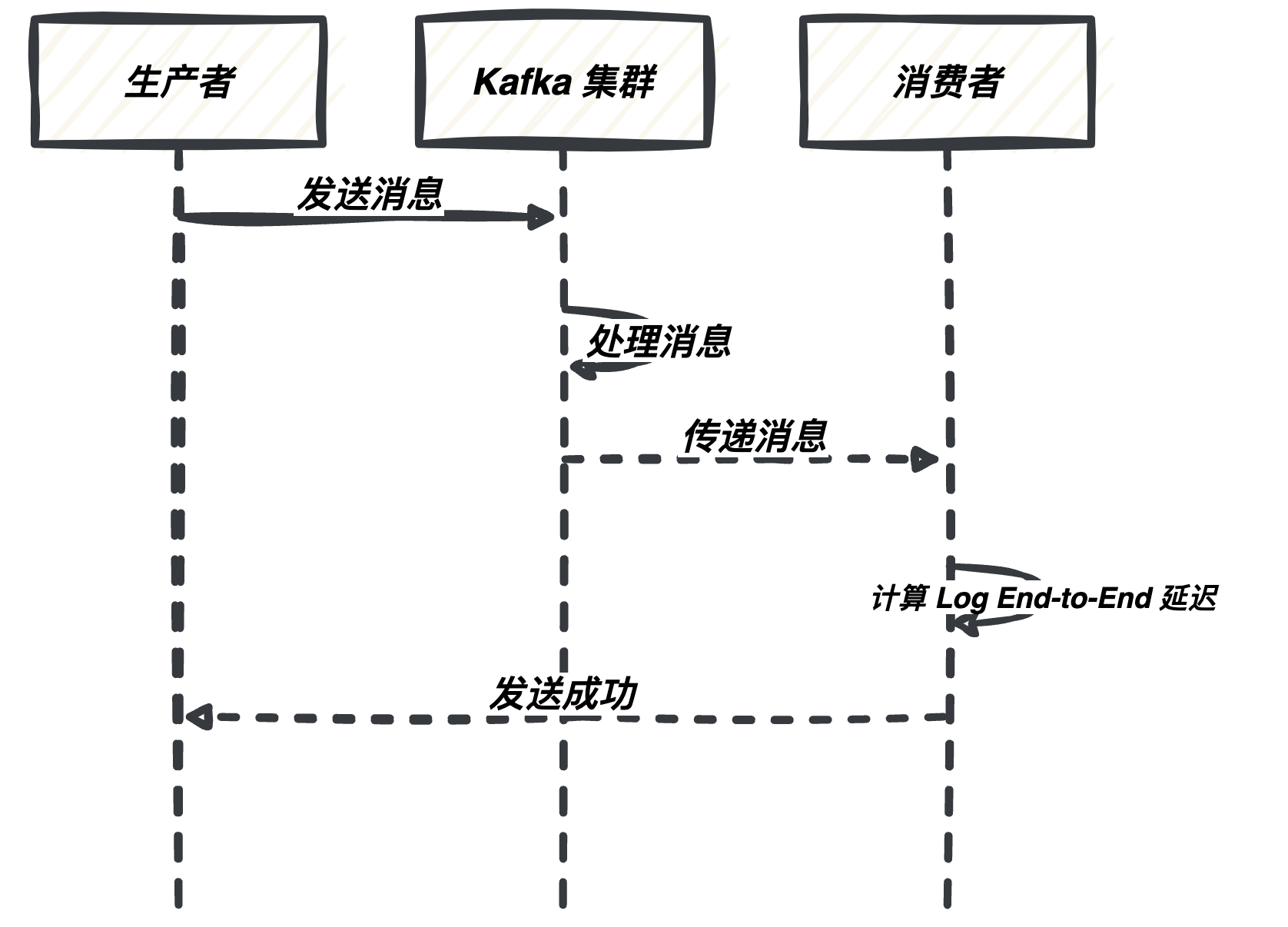
以下是一个示例:
// 创建 Kafka 消费者
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "kafka-broker:9092");
consumerProps.put("group.id", "my-group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
// 订阅主题
consumer.subscribe(Collections.singletonList("my_topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long endToEndLatency = record.timestamp() - record.timestampType().createTimestamp();
System.out.println("Log End-to-End 延迟:" + endToEndLatency + " 毫秒");
}
}
2.1.3 消费者处理延迟
消费者处理延迟是指消息从 Kafka 接收到被消费者实际处理的时间。为了度量这一延迟,你可以采取以下方法:
- 记录消费时间戳:在消费者端,记录每条消息的接收时间戳和处理时间戳。通过计算这两个时间戳的差值,你可以得到消息的消费者处理延迟。
以下是如何记录消费时间戳的代码示例:
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList("my_topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
long receiveTimestamp = System.currentTimeMillis();
long consumerProcessingLatency = receiveTimestamp - record.timestamp();
System.out.println("消费者处理延迟:" + consumerProcessingLatency + " 毫秒");
}
}
2.2 监控和度量工具
在度量和监控 Kafka 消息延迟时,使用适当的工具和系统是至关重要的。下面是一些工具和步骤,帮助你有效地监控 Kafka 消息延迟,包括代码示例:
2.2.1 Kafka 内置度量
Kafka 提供了内置度量,可通过多种方式来监控。以下是一些示例,演示如何通过 Kafka 的 JMX 界面访问这些度量:
使用 JConsole 直接连接到 Kafka Broker:
- 启动 Kafka Broker。
- 打开 JConsole(Java 监控与管理控制台)。
- 在 JConsole 中选择 Kafka Broker 进程。
- 导航到 “kafka.server” 和 “kafka.consumer”,以查看各种度量。
使用 Jolokia(Kafka JMX HTTP Bridge):
- 启用 Jolokia 作为 Kafka Broker 的 JMX HTTP Bridge。
- 使用 Web 浏览器或 HTTP 请求访问 Jolokia 接口来获取度量数据。例如,使用 cURL 进行 HTTP GET 请求:
curl http://localhost:8778/jolokia/read/kafka.server:name=BrokerTopicMetrics/TotalFetchRequestsPerSec
这将返回有关 Kafka Broker 主题度量的信息。
2.2.2 第三方监控工具
除了 Kafka 内置度量,你还可以使用第三方监控工具,如 Prometheus 和 Grafana,来收集、可视化和警报度量数据。以下是一些步骤:
配置 Prometheus:
- 部署和配置 Prometheus 服务器。
- 创建用于监控 Kafka 的 Prometheus 配置文件,定义抓取度量数据的频率和目标。
- 启动 Prometheus 服务器。
设置 Grafana 仪表板:
- 部署和配置 Grafana 服务器。
- 在 Grafana 中创建仪表板,使用 Prometheus 作为数据源。
- 添加度量查询,配置警报规则和可视化图表。
可视化 Kafka 延迟数据:
在 Grafana 仪表板中,你可以设置不同的图表来可视化 Kafka 延迟数据,例如生产者到 Kafka 延迟、消费者处理延迟等。通过设置警报规则,你还可以及时收到通知,以便采取行动。
2.2.3 配置和使用监控工具
为了配置和使用监控工具,你需要执行以下步骤:
定义度量指标:确定你要度量的关键度量指标,如生产者到 Kafka 延迟、消费者处理延迟等。
设置警报规则:为了快速响应问题,设置警报规则,以便在度量数据超出预定阈值时接收通知。
创建可视化仪表板:使用监控工具(如 Grafana)创建可视化仪表板,以集中展示度量数据并实时监测延迟情况。可配置的图表和仪表板有助于更好地理解数据趋势。
以上步骤和工具将帮助你更好地度量和监控 Kafka 消息延迟,以及及时采取行动来维护系统的性能和可靠性。
三、降低消息延迟
既然我们了解了 Kafka 消息延迟的来源以及如何度量和监控它,让我们继续探讨如何降低消息延迟。以下是一些有效的实践方法,可以帮助你减少 Kafka 消息延迟:
3.1 优化 Kafka 配置
3.1.1 Producer 和 Consumer 参数
生产者参数示例:
# 生产者参数示例
acks=all
compression.type=snappy
linger.ms=20
max.in.flight.requests.per.connection=1
acks设置为all,以确保生产者等待来自所有分区副本的确认。这提高了可靠性,但可能增加了延迟。compression.type使用 Snappy 压缩消息,减小了网络传输延迟。linger.ms设置为 20 毫秒,以允许生产者在发送消息之前等待更多消息。这有助于减少短暂的消息发送延迟。max.in.flight.requests.per.connection设置为 1,以确保在收到分区副本的确认之前不会发送新的消息。
消费者参数示例:
# 消费者参数示例
max.poll.records=500
fetch.min.bytes=1
fetch.max.wait.ms=100
enable.auto.commit=false
max.poll.records设置为 500,以一次性拉取多条消息,提高吞吐量。fetch.min.bytes设置为 1,以确保即使没有足够数据,也立即拉取消息。fetch.max.wait.ms设置为 100 毫秒,以限制拉取消息的等待时间。enable.auto.commit禁用自动提交位移,以确保精确控制消息的确认。
3.1.2 Broker 参数
优化 Kafka broker 参数可以提高整体性能。以下是示例:
# Kafka Broker 参数示例
num.network.threads=3
num.io.threads=8
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
num.network.threads和num.io.threads设置为适当的值,以充分利用硬件资源。log.segment.bytes设置为 1 GB,以充分利用磁盘性能。log.retention.check.interval.ms设置为 300,000 毫秒,以降低清理日志段的频率。
3.1.3 Topic 参数
优化每个主题的参数以满足应用程序需求也很重要。以下是示例:
# 创建 Kafka 主题并设置参数示例
kafka-topics.sh --create --topic my_topic --partitions 8 --replication-factor 2 --config cleanup.policy=compact
--partitions 8设置分区数量为 8,以提高并行性。--replication-factor 2设置复制因子为 2,以提高可靠性。--config cleanup.policy=compact设置清理策略为压缩策略,以减小数据保留成本。
通过适当配置这些参数,你可以有效地优化 Kafka 配置以降低消息延迟并提高性能。请根据你的应用程序需求和硬件资源进行调整。
3.2 编写高效的生产者和消费者
最后,编写高效的 Kafka 生产者和消费者代码对于降低延迟至关重要。以下是一些最佳实践:
3.2.1 生产者最佳实践
-
使用异步发送:将多个消息批量发送,而不是逐条发送。这可以减少网络通信的次数,提高吞吐量。
-
使用 Kafka 生产者的缓冲机制:充分利用 Kafka 生产者的缓冲功能,以减少网络通信次数。
-
使用分区键:通过选择合适的分区键,确保数据均匀分布在不同的分区上,从而提高并行性。
3.2.2 消费者最佳实践
-
使用多线程消费:启用多个消费者线程,以便并行处理消息。这可以提高处理能力和降低延迟。
-
调整消费者参数:调整消费者参数,如
fetch.min.bytes和fetch.max.wait.ms,以平衡吞吐量和延迟。 -
使用消息批处理:将一批消息一起处理,以减小处理开销。
3.2.3 数据序列化
选择高效的数据序列化格式对于降低数据传输和存储开销很重要。以下是一些建议的格式:
-
Avro:Apache Avro 是一种数据序列化框架,具有高度压缩和高性能的特点。它适用于大规模数据处理。
-
Protocol Buffers:Google Protocol Buffers(ProtoBuf)是一种轻量级的二进制数据格式,具有出色的性能和紧凑的数据表示。
四、Kafka 消息时序性
消息时序性是大多数实时数据流应用程序的核心要求。在本节中,我们将深入探讨消息时序性的概念、为何它如此重要以及如何保障消息时序性。
4.1 什么是消息时序性?
消息时序性是指消息按照它们发送的顺序被接收和处理的特性。在 Kafka 中,每个分区内的消息是有序的,这意味着消息以它们被生产者发送的顺序排列。然而,跨越多个分区的消息需要额外的工作来保持它们的时序性。
4.1.1 为何消息时序性重要?
消息时序性对于许多应用程序至关重要,特别是需要按照时间顺序处理数据的应用。以下是一些应用领域,消息时序性非常关键:
-
金融领域:在金融交易中,确保交易按照它们发生的确切顺序进行处理至关重要。任何失去时序性的交易可能会导致不一致性或错误的交易。
-
日志记录:在日志记录和监控应用程序中,事件的时序性对于分析和排查问题非常关键。失去事件的时序性可能会导致混淆和数据不准确。
-
电商应用:在线商店的订单处理需要确保订单的创建、支付和发货等步骤按照正确的顺序进行,以避免订单混乱和不准确。
4.2 保障消息时序性
在分布式系统中,保障消息时序性可能会面临一些挑战,特别是在跨越多个分区的情况下。以下是一些策略和最佳实践,可帮助你确保消息时序性:
4.2.1 分区和消息排序
使用合适的分区策略对消息进行排序,以确保相关的消息被发送到同一个分区。这样可以维护消息在单个分区内的顺序性。对于需要按照特定键排序的消息,可以使用自定义分区器来实现。
以下是如何使用合适的分区策略对消息进行排序的代码示例:
// 自定义分区器,确保相关消息基于特定键被发送到同一个分区
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 在此处根据 key 的某种规则计算分区编号
// 例如,可以使用哈希函数或其他方法
int numPartitions = cluster.partitionsForTopic(topic).size();
return Math.abs(key.hashCode()) % numPartitions;
}
@Override
public void close() {
// 可选的资源清理
}
@Override
public void configure(Map<String, ?> configs) {
// 可选的配置
}
}
4.2.2 数据一致性
确保生产者发送的消息是有序的。这可能需要在应用程序层面实施,包括对消息进行缓冲、排序和合并,以确保它们按照正确的顺序发送到 Kafka。
以下是如何确保数据一致性的代码示例:
// 生产者端的消息排序
ProducerRecord<String, String> record1 = new ProducerRecord<>("my-topic", "key1", "message1");
ProducerRecord<String, String> record2 = new ProducerRecord<>("my-topic", "key2", "message2");
// 发送消息
producer.send(record1);
producer.send(record2);
// 消费者端保证消息按照键排序
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 处理消息,确保按照键的顺序进行
}
4.2.3 消费者并行性
在消费者端,使用适当的线程和分区分配来确保消息以正确的顺序处理。这可能涉及消费者线程数量的管理以及确保每个线程只处理一个分区,以避免顺序混乱。
以下是如何确保消费者并行性的代码示例:
// 创建具有多个消费者线程的 Kafka 消费者
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "kafka-broker:9092");
consumerProps.put("group.id", "my-group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 创建 Kafka 消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
// 订阅主题
consumer.subscribe(Collections.singletonList("my-topic"));
// 创建多个消费者线程
int numThreads = 3;
for (int i = 0; i < numThreads; i++) {
Runnable consumerThread = new ConsumerThread(consumer);
new Thread(consumerThread).start();
}
五、总结
在本篇技术博客中,我们深入探讨了 Kafka 消息延迟和时序性的重要性以及如何度量、监控和降低消息延迟。我们还讨论了消息时序性的挑战和如何确保消息时序性。对于构建实时数据流应用程序的开发人员来说,深入理解这些概念是至关重要的。通过合理配置 Kafka、优化网络和硬件、编写高效的生产者和消费者代码,以及维护消息时序性,你可以构建出高性能和可靠的数据流系统。
无论你的应用是金融交易、监控、日志记录还是其他领域,这些建议和最佳实践都将帮助你更好地处理 Kafka 消息延迟和时序性的挑战,确保数据的可靠性和一致性。
六、从零开始学架构:照着做,你也能成为架构师

1、内容介绍
京东购买链接:从零开始学架构:照着做,你也能成为架构师
本书的内容主要包含以下几部分:
- 架构设计基础,包括架构设计相关概念、历史、原则、基本方法,让架构设计不再神秘;
- 架构设计流程,通过一个虚拟的案例,描述了一个通用的架构设计流程,让架构设计不再依赖天才的创作,而是有章可循;
- 架构设计专题:包括高性能架构设计、高可用架构设计、可扩展架构设计,这些模式可以直接参考和应用;
- 架构设计实战,包括重构、开源方案引入、架构发展路径、互联网架构模板等
2、作者简介
阿里巴巴资深技术专家专注于Java、Linux、MySQL、开源技术、系统分析、架构设计,热爱技术,CSDN社区之星,CSDN博客认证专家,UC资深软件工程师。
- 本书由浅入深地阐述了架构设计的相关内容,比较适合以下类型的读者:
- 没有架构设计经验,但对架构设计非常有兴趣,希望学习架构设计技术,提升技术能力,成为“大厂面霸”的读者;
- 已经尝试了一些架构设计,但挖了各种“坑”或踩了各种“坑”,希望知道“为什么”的技术人员;
- 具备一定的架构设计经验,想进一步系统化地提升架构设计能力,成为令人羡慕的“高级技术专家”“资深技术专家”的读者。
3、参与方式
图书数量:本次送出 5 本《从零开始学架构:照着做,你也能成为架构师》 !!!
活动时间:截止到 2023-12-21 21:00:00
🏆抽奖方式:
????点击下方名片,回复1221,即可参与????
🏆哪吒会在朋友圈公布中奖名单。
名单公布时间:2023-12-21 21:10:00
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于Boost的HTTP客户端程序编程
- K8S陈述式资源管理(1)
- 实施企业增长战略:明确需求和战略咨询公司选择尤为重要
- KMP- 简单的子串匹配
- 探索无限:山海鲸可视化搭建的地理展览馆的奇幻之旅
- 救护车使用4G工业路由器的优势及实现方法
- 79 DFS和BFS解求根到叶子节点数字之和
- 微信小程序使用canvas制作海报并保存到本地相册(超级详细)
- Simply简洁博客主题源码 | EmlogPro主题模版
- 记录汇川:H5U与Factory IO测试15