Kafka集群的安装与配置
一、安装JDK
1、在usr目录下新建Java目录,然后将下载的JDK拷贝到这个新建的Java目录中1
创建目录命令:mkdir /usr/java
2、进入到Java目录中解压下载的JDK
解压命令:tar -zxvf jdk-18_linux-x64_bin.tar.gz
在1主机上,将安装包分发到其他机器
scp -r ?/opt/jdk1.8/ node2:/opt/
3、设置环境变量
设置命令:vim /etc/profile
输入上面的命令后,shift+g快速将光标定位到最后一行,然后按“i”,再输入下面代码
#set java environment
JAVA_HOME=/usr/java/jdk1.8
CLASSPATH=$JAVA_HOME/lib
PATH=$PATH:$JAVA_HOME/bin
export PHTH JAVA_HOME CLASSPATH
填写完代码后按ESC键,输入“:wq”保存并退出编辑页面
4、输入下面命令让设置的环境变量生效
生效命令:source /etc/profile
5、验证JDK是否安装成功java
验证命令:Java -version
二、安装Zookeeper
Zookeeper集群搭建指的是ZooKeeper分布式模式安装。通常由2n+1台server组成。这是因为为了保证Leader选举(基于Paxos算法的实现)能过得到多数的支持,所以ZooKeeper集群的数量一般为奇数。
Zookeeper运行需要java环境,所以需要提前安装jdk。对于安装leader+follower模式的集群,大致过程如下:
配置主机名称到IP地址映射配置
修改ZooKeeper配置文件
远程复制分发安装文件
设置myid
启动ZooKeeper集群
如果要想使用Observer模式,可在对应节点的配置文件添加如下配置:
peerType=observer ?
其次,必须在配置文件指定哪些节点被指定为Observer,如:
server.1:node1:2181:3181:observer ?
其次,必须在配置文件指定哪些节点被指定为 Observer,如:
server.1:localhost:2181:3181:observer
这里,我们安装的是leader+follower模式
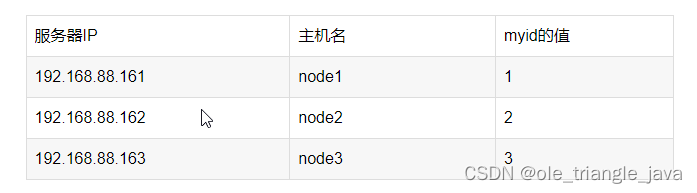
服务器IP
主机名? ?myid的值
第一步:下载zookeeeper的压缩包,下载网址如下
我们在这个网址下载我们使用的zk版本为3.4.6
下载完成之后,上传到我们的linux的/opt路径下准备进行安装
第二步:解压
在node1主机上,解压zookeeper的压缩包到/opt路径下去,然后准备进行安装
tar -zxvf zookeeper-3.4.6.tar.gz?
第三步:修改配置文件
在node1主机上,修改配置文件
cd /zookeeper-3.4.6/conf/
cp zoo_sample.cfg zoo.cfg
mkdir zkdatas
vim ?zoo.cfg
修改以下内容
#Zookeeper的数据存放目录
dataDir=/opt/zookeeper-3.4.6/zkdatas
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小时清理一次
autopurge.purgeInterval=1
# 集群中服务器地址
#当前服务器的ip设置为0.0.0.0
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
第四步:添加myid配置
在node1主机的/opt/zookeeper-3.4.6/zkdatas/这个路径下创建一个文件,文件名为myid ,文件内容为1
vim myid?
echo 1 > /opt/zookeeper/data//myid
第五步:安装包分发并修改myid的值
在node1主机上,将安装包分发到其他机器
第一台机器上面执行以下两个命令
scp -r ?/opt/zookeeper-3.4.6/ node2:/opt/
scp -r ?/opt/zookeeper-3.4.6/ node3:/opt/第二台机器上修改myid的值为2
echo 2 > /export/server/zookeeper-3.4.6/zkdatas/myid
第三台机器上修改myid的值为3
echo 3 > /export/server/zookeeper-3.4.6/zkdatas/myid
第六步:三台机器启动zookeeper服务
三台机器分别启动zookeeper服务
这个命令三台机器都要执行
/export/server/zookeeper-3.4.6/bin/zkServer.sh start
三台主机分别查看启动状态
/export/server/zookeeper-3.4.6/bin/zkServer.sh ?status
配置Path环境变量
1:分别在三台中,修改/etc/proflie,添加以下内容
export ZOOKEEPER_HOME=/export/server/zookeeper-3.4.6
export PATH=:$ZOOKEEPER_HOME/bin:$PATH
2:分别在三台主机中,source /etc/profile
切记:必须source,不然不生效
# 启动服务
./zkServer.sh start
?
# 查看状态
./zkServer.sh status
?
# 停止服务
./zkServer.sh stop
?
# 重启服务
./zkServer.sh restart
原文链接:https://blog.csdn.net/qq_64495672/article/details/124371474
三、安装Kafka
通过jps命令查看运行的情况

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年【建筑电工(建筑特殊工种)】报名考试及建筑电工(建筑特殊工种)新版试题
- python装饰器扩展类方法和元类管理实例
- 《手把手教你》系列基础篇之3-python+ selenium自动化测试-驱动浏览器和元素定位大法(详细)
- 一文梳理金融风控建模全流程(Python)
- Unity中URP下的添加雾效支持
- vue和jQuery有什么区别
- 第十三章 线程安全与锁优化
- 了解JavaScript的执行环境及作用域
- Java小案例-被玩烂了的9种设计模式
- Jmeter 性能 —— 模拟百万高并发压测思路!