机器学习---lightGBM
1.?lightGBM演进过程
![]()
![]()
AdaBoost是?种提升树的方法,和三个臭皮匠,赛过诸葛亮的道理?样。 AdaBoost两个问题:
(1) 如何改变训练数据的权重或概率分布提高前?轮被弱分类器错误分类的样本的权重,降低前?
轮被分对的权重 (2) 如何将弱分类器组合成?个强分类器,亦即,每个分类器,前面的权重如何设
置采取”多数表决”的方法。加大分类错误率小的弱分类器的权重,使其作用较大,而减小分类错误
率大的弱分类器的权重,使其在表决中起较小的作用。
GBDT和AdaBosst很类似,但是又有所不同。 GBDT和其它Boosting算法?样,通过将表现?般的
几个模型(通常是深度固定的决策树)组合在?起来集成?个表现较好的模型。 AdaBoost是通过
提升错分数据点的权重来定位模型的不足, Gradient Boosting通过负梯度来识别问题,通过计算
负梯度来改进模型,即通过反复地选择?个指向负梯度方向的函数,该算法可被看做在函数空间里
对目标函数进行优化。 因此可以说 。 GradientBoosting = GradientDescent + Boosting
GBDT ->预排序方法(pre-sorted) (1) 空间消耗大。 这样的算法需要保存数据的特征值,还保存了
特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍
的内存。(2) 时间上也有较大的开销。 在遍历每?个分割点的时候,都需要进行分裂增益的计算,
消耗的代价大。(3) 对内存(cache)优化不友好。 在预排序后,特征对梯度的访问是?种随机访问,
并且不同的特征访问的顺序不?样,?法对cache进行优化。 同时,在每?层长树的时候,需要随
机访问?个行索引到叶子索引数组,并且不同特征访问顺序也不?样,也会造成较?cache miss。
常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不
会受到内存限制。 而GBDT在每?次迭代的时候,都需要遍历整个训练数据多次。 如果把整个训
练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常?
的时间。 尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。 LightGBM提出的
主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
2. lightGBM原理
lightGBM 主要基于以下方面优化,提升整体特性: 1. 基于Histogram(直方图)的决策树算法
2. Lightgbm 的Histogram(直方图)做差加速 3. 带深度限制的Leaf-wise的叶子生长策略 4. 直接支
持类别特征 5. 直接支持高效并行
2.1?基于Histogram(直方图)的决策树算法
直方图算法的基本思想是:先把连续的浮点特征值离散化成k个整数,同时构造?个宽度为k的直方
图。 在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历?次数据
后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。

使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储
预排序的结果,而且可以只保存特征离散化后的值,而这个值?般用8位整型存储就足够了,内存
消耗可以降低为原来的1/8。?

然后在计算上的代价也大幅降低,预排序算法每遍历?个特征值就需要计算?次分裂的增益,而直
方图算法只需要计算 k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到
O(k#features)。 当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确
的分割点,所以会对结果产生影响。 但在不同的数据集上的结果表明,离散化的分割点对最终的
精度影响并不是很大,甚至有时候会更好?点。原因是决策树本来就是弱模型,分割点是不是精确
并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差
比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
2.2?Lightgbm 的Histogram(直方图)做差加速
?个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。 通常构造直方图,
需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。 利?这个方法,
LightGBM可以在构造?个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在
速度上可以提升?倍。

2.3?带深度限制的Leaf-wise的叶子生长策略
Level-wise遍历?次数据可以同时分裂同?层的叶子,容易进行多线程优化,也好控制模型复杂
度,不容易过拟合。 但实际上Level-wise是?种低效的算法,因为它不加区分的对待同?层的叶
子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是?种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的?个叶子,然
后分裂,如此循环。 因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多
的误差,得到更好的精度。 Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此
LightGBM在Leaf-wise之上增加了?个最大深度的限制,在保证高效率的同时防止过拟合。
2.4?直接支持类别特征
实际上大多数机器学习?具都无法直接支持类别特征,?般需要把类别特征,转化到多维的0/1特
征,降低了空间和时间的效率。 而类别特征的使用是在实践中很常用的。基于这个考虑,
LightGBM优化了对类别特征的?持,可以直接输?类别特征,不需要额外的0/1展开。并在决策树
算法上增加了类别特征的决策规则。 在Expo数据集上的实验,相比0/1展开的方法,训练速度可以
加速8倍,并且精度?致。目前来看,LightGBM是第?个直接支持类别特征的GBDT工具。 Expo
数据集介绍:数据包含1987年10月至2008年4月美国境内所有商业航班的航班到达和离开的详细信
息。这是?个庞大的数据集:总共有近1.2亿条记录。主要用于预测航班是否准时。
2.5?直接支持高效并行
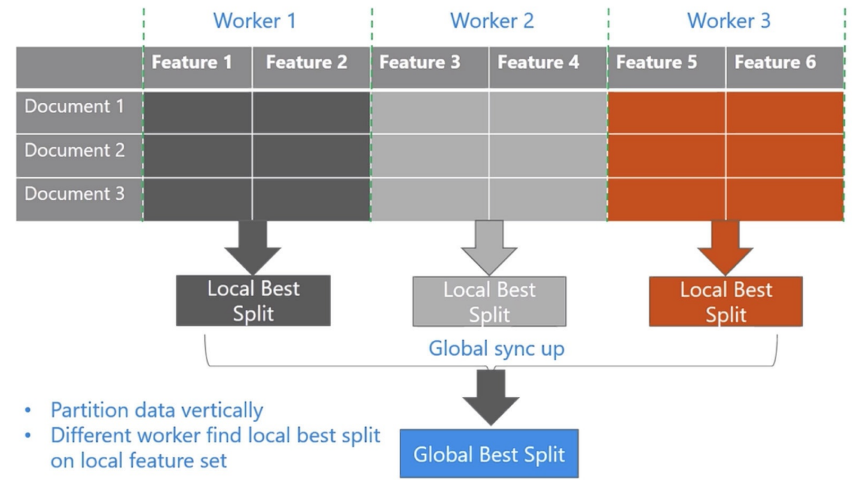
LightGBM还具有支持高效并行的优点。LightGBM原?支持并行学习,目前支持特征并行和数据并
行的两种。 特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后
在机器间同步最优的分割点。 数据并行则是让不同的机器先在本地构造直方图,然后进行全局的
合并,最后在合并的直方图上面寻找最优分割点。 LightGBM针对这两种并行方法都做了优化: 在
特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;
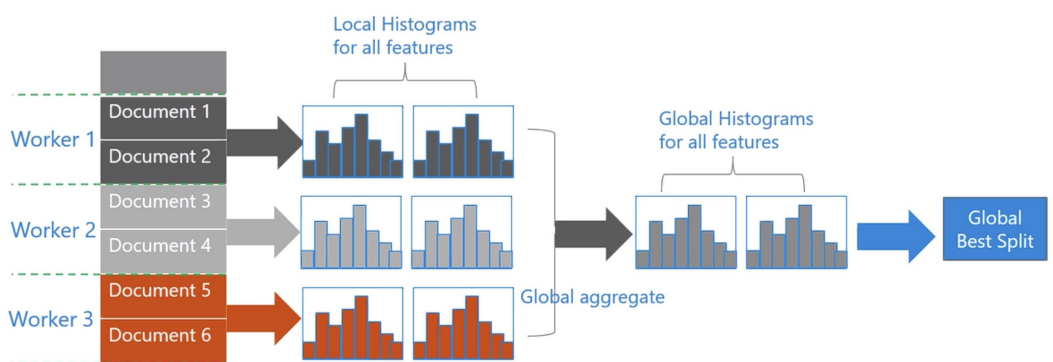
在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和
计算,并利用直方图做差,进?步减少了?半的通信量。
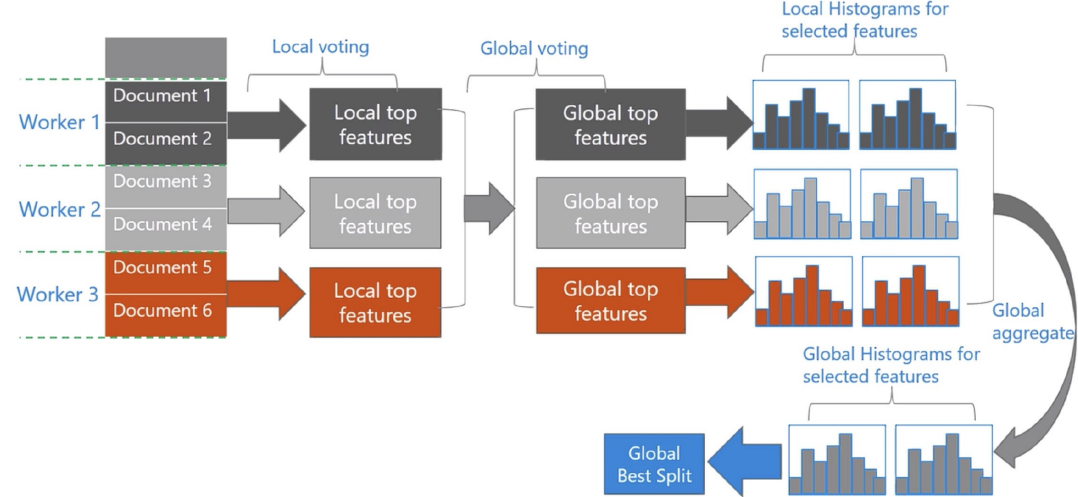
基于投票的数据并行(Voting Parallelization)则进?步优化数据并行中的通信代价,使通信代价变成
常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。
3.?lightGBM参数介绍?
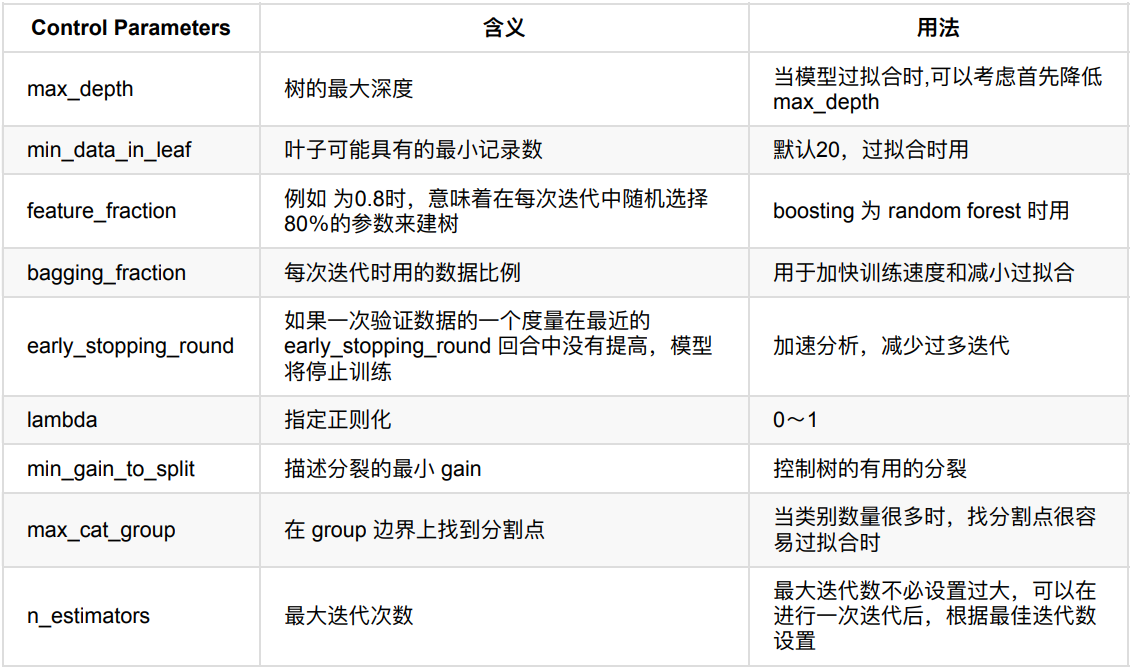

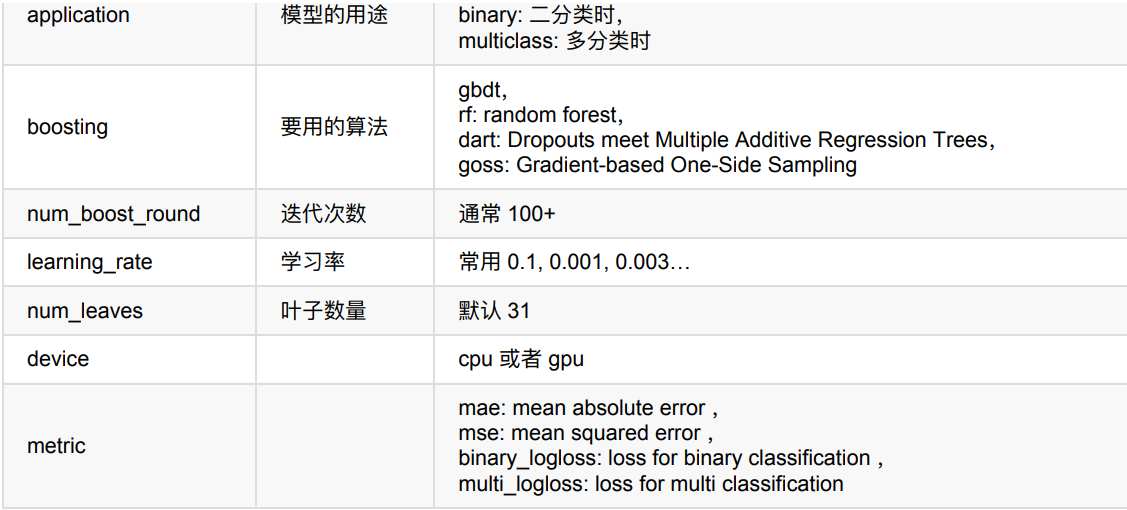


下表对应了 Faster Speed ,better accuracy ,over-fitting 三种目的时,可以调的参数
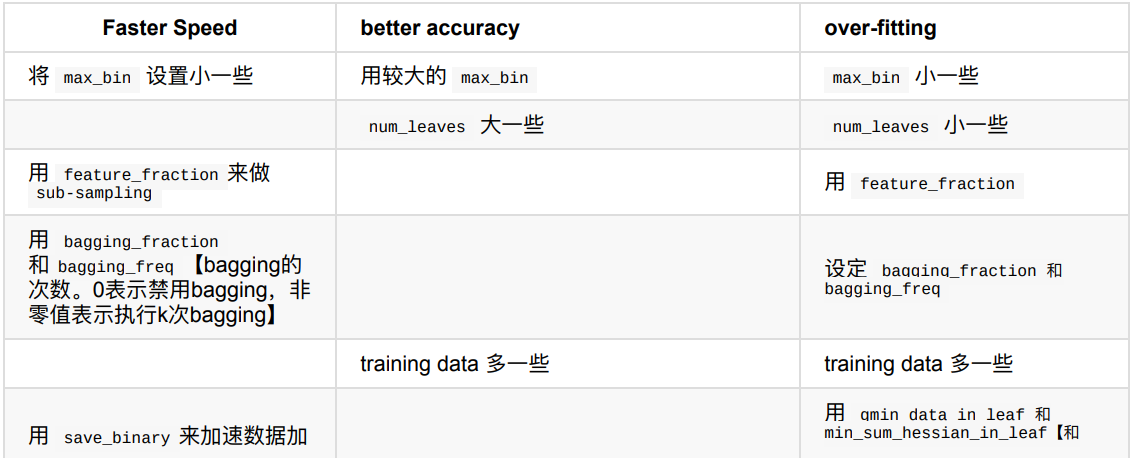
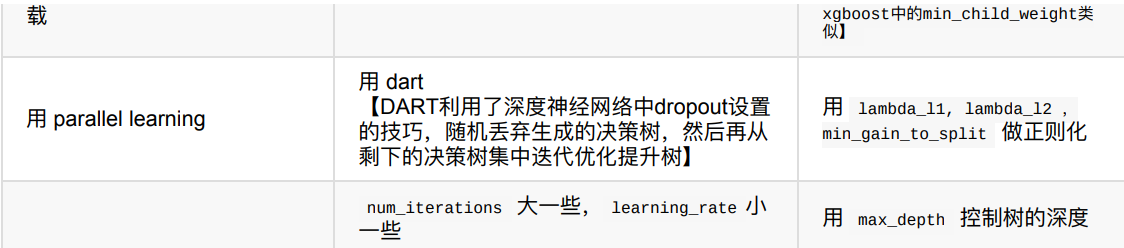
4.?lightGBM案例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
gbm = lgb.LGBMRegressor(objective='regression', learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
gbm.score(X_test, y_test)
# 0.810605595102488
# ?格搜索,参数优化
estimator = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40]
}
gbm = GridSearchCV(estimator, param_grid, cv=4)
gbm.fit(X_train, y_train)
print('Best parameters found by grid search are:', gbm.best_params_)
# Best parameters found by grid search are: {'learning_rate': 0.1, 'n_estimators': 40}
gbm = lgb.LGBMRegressor(num_leaves=31, learning_rate=0.1, n_estimators=40)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
gbm.score(X_test, y_test)
# 0.9536626296481988
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue如何通过$http的post方法请求下载二进制的Excel文件
- 希尔顿花园酒店喜迎入华十周年里程碑
- 【Python特征工程系列】教你利用XGBoost模型分析特征重要性(源码)
- Xcode 15 libarclite 缺失问题
- 全国1900+监测站点空气质量日数据,shp/excel格式,2023年最新数据
- 【深度学习每日小知识】Co-occurrence matrix 共现矩阵
- 遥感影像正射校正
- 【并发编程】锁
- C语言——详解字符函数和字符串数组(上)
- 【云服务器】阿里云飞天计划 - 学生免费云服务器(超详细的图文介绍)