Chatgpt的崛起之路
Chatgpt的崛起之路
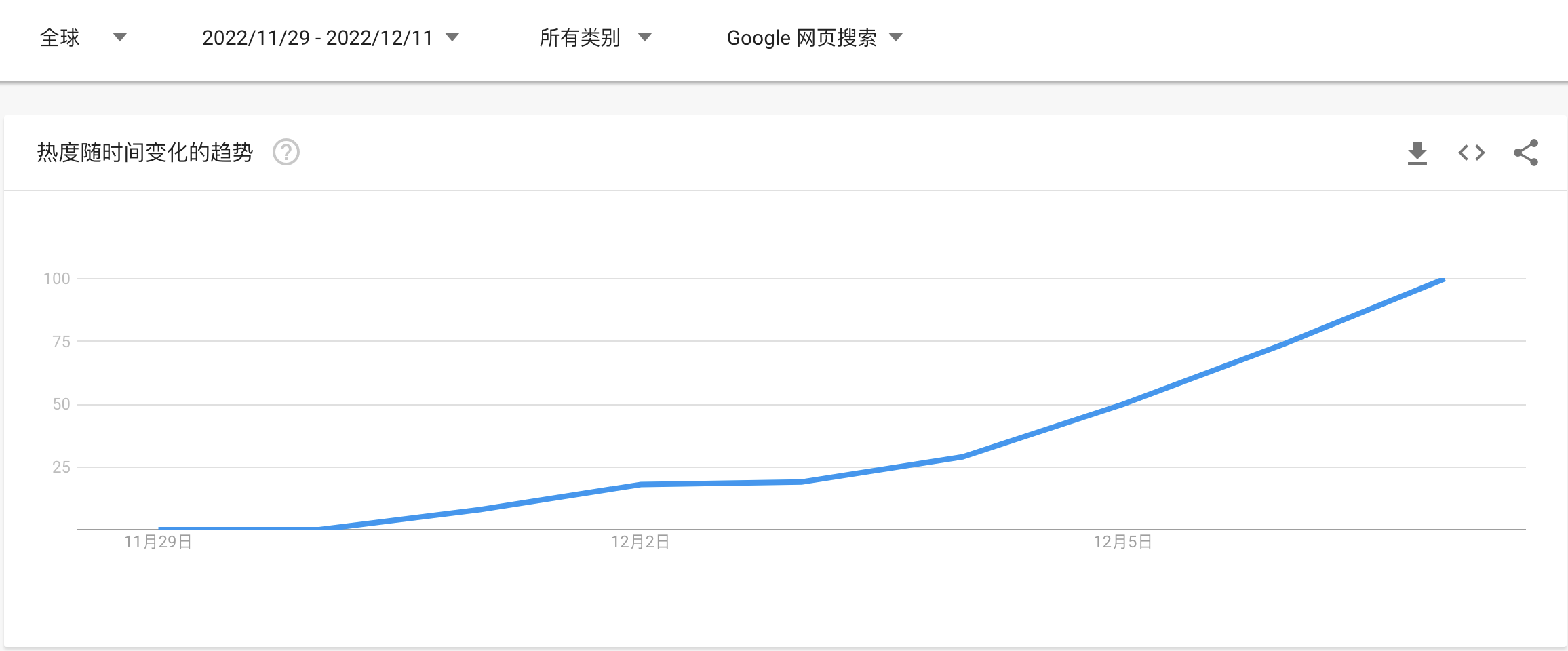
OpenAI 11月30号发布,首先在北美、欧洲等已经引发了热烈的讨论。随后在国内开始火起来。全球用户争相晒出自己极具创意的与ChatGPT交流的成果。ChatGPT在大量网友的疯狂测试中表现出各种惊人的能力,如流畅对答、写代码、写剧本、纠错等,甚至让记者编辑、程序员等从业者都感受到了威胁,更不乏其将取代谷歌搜索引擎之说。继AlphaGo击败李世石、AI绘画大火之后,ChatGPT成为又一新晋网红。下面是谷歌全球指数,我们可以看到火爆的程度。
国内对比各大平台,最先火起来是在微信上,通过微信指数我们可以看到,97.48%来自于公众号,开始于科技圈,迅速拓展到投资圈等。我最先了解到ChatGPT相关信息的也是在关注的科技公众号上,随后看到各大公众号出现关于介绍ChatGPT各种震惊体关键词地震、杀疯了、毁灭人类等。随后各行各业都参与进来有趣的整活,问数学题,问历史,还有写小说,写日报,写代码找BUG…
背景与发展历程
背景
ChatGPT是由OpenAI开发的一个人工智能聊天机器人程序,于2022年11月推出。该程序使用基于GPT3.5架构的大型语言模型并通过强化学习进行训练。
ChatGPT以文字方式互动,除了可以透过人类自然对话方式进行交互,还可以用于相对复杂的语言工作,包括自动文本生成、自动问答、自动摘要等在内的多种任务。如:在自动文本生成方面,ChatGPT可以根据输入的文本自动生成类似的文本,在自动问答方面,ChatGPT可以根据输入的问题自动生成答案。还具有编写和调试计算机程序的能力。
ChatGPT因其在许多知识领域给出详细的回答和清晰的答案而迅速获得关注,但其事实准确性参差不齐被认为是一重大缺陷。ChatGPT于2022年11月发布后,OpenAI估值已涨至290亿美元。上线两个月后,用户数量达到1亿。
ChatGPT主要包含以下特点:
- OpenAI使用 RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)技术对 ChatGPT 进行了训练,且加入了更多人工监督进行微调。
- 可以主动承认自身错误。若用户指出其错误,模型会听取意见并优化答案。
- ChatGPT 可以质疑不正确的问题。例如被询问 “哥伦布 2015 年来到美国的情景” 的问题时,机器人会说明哥伦布不属于这一时代并调整输出结果。
- ChatGPT 可以承认自身的无知,承认对专业技术的不了解。
- 支持连续多轮对话。
- ChatGPT可以通过分析语料库中的模式和敏感词或句子来识别敏感话题(种族,政治,人身攻击等)。它将会自动识别可能触发敏感问题的输入,并且可以自动过滤掉敏感内容,最大程度地确保用户的安全。此外,它也可以帮助用户识别出可能触发敏感问题的话题,从而避免他们无意中使用不当的语言破坏聊天气氛。
发展历程
在过去几年中,Google一直是NLP领域大规模预训练模型的引领者,而2022年11月ChatGPT的发布,其效果惊艳了众多专业以及非专业人士,虽然Google也紧接着发布了类似的Bard模型,但已经错失了先机。下图是这场旷日持久的AI暗战之下的关键技术时间线。
技术原理
在整体技术路线上,ChatGPT在效果强大的GPT 3.5大规模语言模型(LLM,Large Language Model)基础上,引入“人工标注数据+强化学习”(RLHF,Reinforcement Learning from Human Feedback)来不断微调(Fine-tune)预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义(比如给我写一段小作文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于用户给定的问题(也称prompt),什么样的答案是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
具体而言,ChatGPT的训练过程分为三个阶段:
第一阶段:训练监督策略模型
GPT 3.5本身很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由专业的人类标注人员,给出每个问题(prompt)的高质量答案,形成<prompt,answer>问答对,然后用这些人工标注好的数据来微调 GPT-3.5模型(获得SFT模型, Supervised Fine-Tuning)。
经过这个过程,可以认为SFT初步具备了理解人类问题中所包含意图,并根据这个意图给出相对高质量回答的能力,但是很明显,仅仅这样做是不够的,因为其回答不一定符合人类偏好。
第二阶段:训练奖励模型
这个阶段主要是通过人工标注训练数据,来训练奖励模型(Reward Mode)。在数据集中随机抽取问题,使用第一阶段训练得到的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑(例如:相关性、富含信息性、有害信息等诸多标准)给出排名顺序。这一过程类似于教练或老师辅导。
接下来,使用这个排序结果数据来训练奖励模型。对多个排序结果,两两组合,形成多个训练数据对。奖励模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
第三阶段:采用强化学习来增强模型的能力。
PPO(Proximal Policy Optimization,近端策略优化)强化学习模型的核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为Importance Sampling。PPO由第一阶段的监督策略模型来初始化模型的参数,这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。具体而言,在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的奖励模型给出质量分数。把奖励分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
如果我们不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
从上述原理可以看出,ChatGPT具有以下几个优势:(1) ChatGPT 的基模型GPT3.5使用了千亿级的数据进行了预训练,模型可谓是“见多识广”;(2) ChatGPT 在强化学习的框架下,可以不断学习和优化。
国内使用情况及应用的领域
ChatGPT 目前仍然处于体验和试用阶段,且未在国内进行开放注册,所以国内暂时还没有实际性的应用。不过在ChatGPT发布之后,国内开始出现平替产品,例如近期国内正式发布的首个功能对话大模型ChatYuan。
ChatGPT 由美国OpenAI公司于2022年11月发布,官网暂未对国内进行开放,但有其他方法可以使用,教程详见这里。
ChatYuan由中国初创公司元语智能2022年12月发布,在线体验网址为:www.clueai.cn/chat。
面临的数据安全挑战与建议
ChatGPT存在一些数据安全问题,这些问题分为两类,一类是ChatGPT获取数据产生的问题,一类是ChatGPT恶意利用产生的问题。
ChatGPT获取数据产生的问题
数据泄露问题
用户在使用ChatGPT时会输入信息,由于ChatGPT强大的功能,一些员工使用ChatGPT辅助其工作,这引起了公司对于商业秘密泄露的担忧。因为输入的信息可能会被用作ChatGPT进一步迭代的训练数据。
建议:ChatGPT可提升工作生产力,不建议完全禁用,公司可以制定相应的规则制度,并且开发相应的机密信息检测工具,指导并辅助员工更安全地使用ChatGPT。
删除权问题
ChatGPT用户必须同意公司可以使用用户和ChatGPT产生的所有输入和输出,同时承诺ChatGPT会从其使用的记录中删除所有个人身份信息。然而ChatGPT未说明其如何删除信息,而且由于被收集的数据将用于ChatGPT不断的学习中,很难保证完全擦除个人信息痕迹。
建议:要求ChatGPT给出明确的删除信息的流程,与使用的公司达成协议。
语料库获取合规问题
如果ChatGPT通过抓取互联网上的信息获得其训练数据,可能并不合法。网站上的隐私政策条款本身表明数据不能被第三方收集,ChatGPT抓取数据会涉及违反合同。在许多司法管辖区,合理使用原则在某些情况下允许未经所有者同意或版权使用信息,包括研究、引用、新闻报道、教学讽刺或批评目的。但是ChatGPT并不适用该原则,因为合理使用原则只允许访问有限信息,而不是获取整个网站的信息。在个人层面,ChatGPT需要解决未经用户同意大量数据抓取是否涉及侵犯个人信息的问题。
建议:要求ChatGPT公布数据的使用明细与脱敏流程,对于不符合规范的行为,要求其进行删除。在使用的过程中,如果发现有侵犯隐私信息的情况,也可以要求其进行改进。
ChatGPT恶意利用产生的问题
用户对ChatGPT的恶意利用也会带来很多数据安全问题,如:(1) 撞库:生成大量可用于对在线帐户进行自动攻击的潜在用户名和密码组合,进行撞库攻击;(2) 生成恶意软件:利用自然语言编写的能力,编写恶意软件,从而逃避防病毒软件的检测;(3) 诱骗信息:利用ChatGPT的编写功能,生成钓鱼电子邮件;利用对话功能,冒充真实的人或者组织骗取他人信息。
建议:对于使用ChatGPT的用户,需要要求其明确指出内容是使用ChatGPT生成的。也可以使用技术手段,自动检测ChatGPT生成的内容(例如近期斯坦福大学推出DetectGPT,以应对学生通过ChatGPT生成论文),并进行进一步的干预。
结语
ChatGPT 现在还处于测试阶段,可以看出在未来它可以极大地提升人类的生产力。但由于这是一个新鲜事物,还没有完善的法规和政策对它进行约束和规范,所以可能会存在一些数据安全等问题。要想实现ChatGPT以及类似产品在国内的落地与商业化,还有很长的路要走。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 告别高昂存储,高效灵活管理数据
- 【GoLang】Go语言几种标准库介绍(三)
- 5、Pandas分组和排序
- 接口测试-Mock测试方法
- 翼辉 SylixOS 正式支持“申威“处理器架构
- Rasterization(光栅化)
- MATLAB算法实战应用案例精讲-【图像处理】图像增强(补充篇)
- 01 数据结构前言
- idea提示unable to import maven project
- Vagrant Centos 7 环境配置