【OpenGauss源码学习 —— 执行器(execMain)】
执行器(execMain)
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》和《PostgresSQL数据库内核分析》一书
概述
??在 OpenGauss 数据库系统中,execMain.cpp 文件是执行器(Executor)模块的核心部分之一。这个文件主要负责实现查询的执行逻辑,是数据库查询处理的关键组成部分。其中,execMain.cpp 文件所对应的部分如下图中的红色框区域所示。其中,本文主要介绍蓝色框区域的内容。
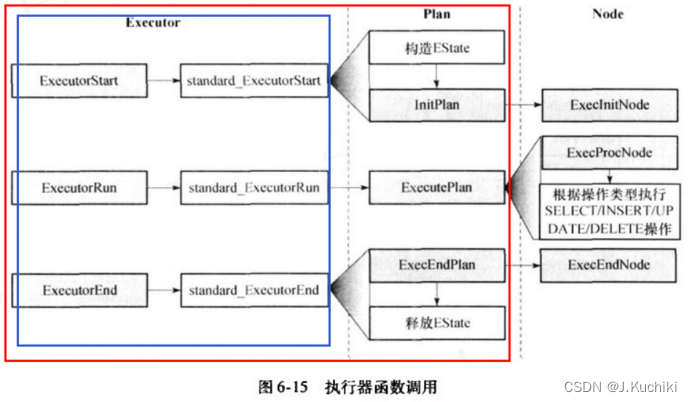
??以下是对 execMain.cpp 文件内容、作用以及其执行的操作的详细概述:
文件内容
??execMain.cpp 包含了执行查询的核心函数和逻辑。这包括但不限于:
- 查询执行的初始化和结束: 实现了查询执行的初始化(ExecutorStart)和结束(ExecutorEnd)功能,为查询执行准备必要的状态、上下文和资源,并在执行完成后进行清理。
- 主执行循环: 定义了主执行循环(ExecutorRun),这是执行计划的中心部分,负责按顺序处理查询计划树的节点。
- 行处理逻辑: 包含了处理每一行数据的逻辑,包括从数据源获取数据、应用各种操作(如过滤、聚合)以及将结果传递到下一处理阶段。
- 支持函数: 定义了一系列支持函数,以协助完成特定的子任务,例如处理参数、处理触发器事件等。
作用
??execMain.cpp 文件在 OpenGauss 的查询执行过程中扮演着核心角色。其主要作用包括:
- 查询计划执行: 将优化器生成的查询计划转化为实际操作,负责按照计划执行数据库操作,如读取表数据、执行连接操作、进行过滤和聚合等。
- 结果生成: 处理和生成查询结果,确保返回给用户或调用者的数据是准确和符合预期的。
- 事务和并发控制: 确保查询执行遵守事务规则和并发控制,维护数据的一致性和隔离性。
执行的操作
??在查询执行过程中,execMain.cpp 执行了以下主要操作:
- 始化执行环境: 设置执行所需的内存上下文、状态变量和执行环境。
- 遍历执行计划: 按照查询计划的指示逐步执行,包括访问表、执行连接、过滤和聚合等。
- 数据处理: 对获取的数据进行处理,如应用谓词、计算表达式等。
- 触发器处理: 如果涉及,处理相关的数据库触发器。
- 生成结果: 最终产生查询结果,可能涉及格式化数据以满足客户端的要求。
- 资源清理: 执行结束后,清理占用的资源,如释放内存、关闭文件等。
??总的来说,execMain.cpp 在 OpenGauss 中是执行查询的关键组件,负责将查询计划转化为实际的数据库操作,并生成查询结果。
主要函数概述
??在 OpenGauss 的 execMain.cpp 文件中,以下列出的函数各自承担着查询执行流程的不同责任。这些函数共同协作,确保从查询计划的初始化到执行的每个步骤都能正确进行。下面依次列出了这些函数并随后进行了具体描述:
void InitPlan(QueryDesc *queryDesc, int eflags);
static void CheckValidRowMarkRel(Relation rel, RowMarkType markType);
static void ExecPostprocessPlan(EState *estate);
static void ExecEndPlan(PlanState *planstate, EState *estate);
static void ExecCollectMaterialForSubplan(EState *estate);
#ifdef ENABLE_MOT
static void ExecutePlan(EState *estate, PlanState *planstate, CmdType operation, bool sendTuples, long numberTuples,
ScanDirection direction, DestReceiver *dest, JitExec::JitContext* mot_jit_context);
#else
static void ExecutePlan(EState *estate, PlanState *planstate, CmdType operation, bool sendTuples, long numberTuples,
ScanDirection direction, DestReceiver *dest);
#endif
static void ExecuteVectorizedPlan(EState *estate, PlanState *planstate, CmdType operation, bool sendTuples,
long numberTuples, ScanDirection direction, DestReceiver *dest);
static bool ExecCheckRTEPerms(RangeTblEntry *rte);
static bool ExecCheckRTEPermsModified(Oid relOid, Oid userid, Bitmapset *modifiedCols, AclMode requiredPerms);
void ExecCheckXactReadOnly(PlannedStmt *plannedstmt);
static void EvalPlanQualStart(EPQState *epqstate, EState *parentestate, Plan *planTree);
extern char* ExecBuildSlotValueDescription(
Oid reloid, TupleTableSlot *slot, TupleDesc tupdesc, Bitmapset *modifiedCols, int maxfieldlen);
extern void BuildStreamFlow(PlannedStmt *plan);
extern void StartUpStreamInParallel(PlannedStmt* pstmt, EState* estate);
extern void CodeGenThreadRuntimeSetup();
extern bool CodeGenThreadObjectReady();
extern void CodeGenThreadRuntimeCodeGenerate();
extern void CodeGenThreadTearDown();
extern bool anls_opt_is_on(AnalysisOpt dfx_opt);
| 函数 | 功能 |
|---|---|
| InitPlan | 初始化查询计划。这个函数负责准备执行环境,包括分配和设置执行状态(EState)以及其他查询执行所需的资源。 |
| CheckValidRowMarkRel | 检查行标记关系的有效性。这个函数用于确保行标记操作(如 SELECT FOR UPDATE)应用于适当的关系类型。 |
| ExecPostprocessPlan | 执行计划的后处理。在查询计划执行完毕后,这个函数执行必要的清理和后处理操作。 |
| ExecEndPlan | 结束查询计划的执行。释放计划状态树(PlanState)中占用的资源,并进行必要的清理工作。 |
| ExecCollectMaterialForSubplan | 为子计划收集材料。这通常涉及缓存子计划的结果以供后续操作使用。 |
| ExecutePlan | 执行查询计划。这个函数是查询执行的核心,它遍历并执行计划状态树,处理数据并生成结果。 |
| ExecuteVectorizedPlan | 执行向量化查询计划。这是对 ExecutePlan 的变种,专门用于处理向量化查询,可以提高某些查询类型的性能。 |
| ExecCheckRTEPerms | 检查关系表条目(Range Table Entry)的权限。确保对表的访问符合权限要求。 |
| ExecCheckRTEPermsModified | 检查修改后的关系表条目的权限。特别是在涉及列级权限时使用。 |
| ExecCheckXactReadOnly | 检查事务是否为只读。这对于预防在只读事务中执行写操作尤为重要。 |
| EvalPlanQualStart | 开始评估计划质量。用于启动执行计划的一部分,以评估特定的行或条件。 |
| ExecBuildSlotValueDescription | 构建插槽值描述。用于生成关于元组插槽的详细描述,这在调试和日志记录中很有用。 |
| BuildStreamFlow | 构建流处理流程。这与处理流数据相关,涉及设置流处理的路径和方式。 |
| StartUpStreamInParallel | 并行启动流处理。在并行环境中初始化流处理。 |
| CodeGenThreadRuntimeSetup | 设置代码生成线程的运行时环境。用于即时编译(JIT)优化。 |
| CodeGenThreadObjectReady, CodeGenThreadRuntimeCodeGenerate, CodeGenThreadTearDown | 与代码生成线程的生命周期管理有关的一系列函数,从确认就绪状态到生成代码再到拆卸环境。 |
| anls_opt_is_on | 检查分析优化选项是否开启。这与查询优化和性能分析相关。 |
部分函数详细分析
??这里不一一的对以上所有的函数进行分析,我们重点挑选执行器的外部接口函数来进行详细的学习,其余的函数有感兴趣的小伙伴可以根据自身的需求去阅读源码。
??其中,四个核心执行器接口函数:ExecutorStart(), ExecutorRun(), ExecutorFinish(), 和 ExecutorEnd()。以下是对这段文字的中文总结及对这四个函数的说明:
- ExecutorStart():
??在执行任何查询计划的开始时必须调用。它负责初始化执行环境,准备所需的资源和状态。- ExecutorRun():
??用于执行查询计划。接受方向和数量参数,指定执行的方向(向前或向后)和处理的元组数量。这个函数可能被多次调用,以处理计划的所有元组,特别是在查询计划涉及多个阶段或者需要分步处理时。对于 SELECT 查询,也可以提前停止执行。- ExecutorFinish():
??在最后一次调用 ExecutorRun() 之后、在调用 ExecutorEnd() 之前必须调用。这一步是执行过程的收尾阶段,但在只执行 EXPLAIN 时可以省略这一步。- ExecutorEnd():
??在查询计划执行的最后必须调用。它用于清理执行过程中分配的资源,无论执行是否因为错误而中断,都必须调用此函数。
??这四个函数共同构成了查询执行的生命周期:
- ExecutorStart():初始化阶段,准备执行环境。
- ExecutorRun():执行阶段,可以多次调用,负责实际的查询处理。
- ExecutorFinish():结束阶段的一部分,处理执行后的收尾工作。
- ExecutorEnd():清理阶段,释放资源,结束查询执行。
??下面,我们依次来学习一下这几个函数的具体执行流程。
ExecutorStart 函数
??ExecutorStart 函数是查询执行流程的起始点。它的主要作用是初始化查询执行环境,包括设置内部状态(如 estate 和 planstate)和返回元组的描述(tupDesc)。这个函数处理 QueryDesc 结构,这是一个包含了查询描述信息的关键数据结构。此外,函数支持通过钩子(hook)机制允许插件介入查询执行的初始化过程,提供了扩展和自定义的可能性。在函数开始和结束时,通过 gstrace 进行跟踪,以便监控函数的执行情况。如果没有设置特定的钩子,函数会调用 standard_ExecutorStart 来进行标准的初始化流程。这个函数对于确保查询计划能够正确执行是至关重要的,因为它准备了执行查询所需的所有必要的上下文和状态。函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
/* ----------------------------------------------------------------
* ExecutorStart
*
* 这个程序必须在任何查询计划执行的开始时调用。
*
* 接收由 CreateQueryDesc 创建的 QueryDesc(分开是因为某些地方使用 QueryDesc 执行实用程序命令)。
* QueryDesc 的 tupDesc 字段填充了描述将返回的元组的信息,内部字段(estate 和 planstate)也被设置好。
*
* eflags 包含 executor.h 中描述的标志位。
*
* 注意:调用此函数时的 CurrentMemoryContext 将成为此 Executor 调用的每个查询上下文的父级。
*
* 我们提供了一个函数钩子变量,允许可加载的插件在调用 ExecutorStart 时获得控制权。
* 这样的插件通常会调用 standard_ExecutorStart()。
* ----------------------------------------------------------------
*/
void ExecutorStart(QueryDesc* queryDesc, int eflags)
{
gstrace_entry(GS_TRC_ID_ExecutorStart); // 进入函数的跟踪点
/* 在处理插件钩子时要小心,因为动态库可能已被释放 */
if (ExecutorStart_hook && !(g_instance.status > NoShutdown))
(*ExecutorStart_hook)(queryDesc, eflags); // 如果设置了 ExecutorStart 钩子,则调用它
else
/* ----------------------------------------------------------------
* ExecutorStart
*
* 这个程序必须在任何查询计划执行的开始时调用。
*
* 接收由 CreateQueryDesc 创建的 QueryDesc(分开是因为某些地方使用 QueryDesc 执行实用程序命令)。
* QueryDesc 的 tupDesc 字段填充了描述将返回的元组的信息,内部字段(estate 和 planstate)也被设置好。
*
* eflags 包含 executor.h 中描述的标志位。
*
* 注意:调用此函数时的 CurrentMemoryContext 将成为此 Executor 调用的每个查询上下文的父级。
*
* 我们提供了一个函数钩子变量,允许可加载的插件在调用 ExecutorStart 时获得控制权。
* 这样的插件通常会调用 standard_ExecutorStart()。
* ----------------------------------------------------------------
*/
void ExecutorStart(QueryDesc* queryDesc, int eflags)
{
gstrace_entry(GS_TRC_ID_ExecutorStart); // 进入函数的跟踪点
/* 在处理插件钩子时要小心,因为动态库可能已被释放 */
if (ExecutorStart_hook && !(g_instance.status > NoShutdown))
(*ExecutorStart_hook)(queryDesc, eflags); // 如果设置了 ExecutorStart 钩子,则调用它
else
standard_ExecutorStart(queryDesc, eflags); // 否则,调用标准的 ExecutorStart 实现
gstrace_exit(GS_TRC_ID_ExecutorStart); // 退出函数的跟踪点
}
(queryDesc, eflags); // 否则,调用标准的 ExecutorStart 实现
gstrace_exit(GS_TRC_ID_ExecutorStart); // 退出函数的跟踪点
}
standard_ExecutorStart 函数
??standard_ExecutorStart 函数是数据库查询执行器的一部分,主要负责初始化查询的执行环境和状态。这个函数为数据库查询执行提供了全面的准备,包括内存管理、状态设置、性能监控和触发器处理等。代码中使用了宏定义和条件编译,这表明其具有处理不同编译设置和运行时情况的灵活性。函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
void standard_ExecutorStart(QueryDesc *queryDesc, int eflags)
{
/* 定义执行状态、内存上下文和性能测量相关的变量 */
EState *estate = NULL;
MemoryContext old_context;
instr_time starttime;
double totaltime = 0;
/* 确保查询描述符有效且尚未开始执行 */
Assert(queryDesc != NULL);
Assert(queryDesc->estate == NULL);
#ifdef MEMORY_CONTEXT_CHECKING
/* 执行器开始时检查所有内存上下文 */
MemoryContextCheck(t_thrd.top_mem_cxt, false);
#endif
/* 如果事务是只读的,检查是否有计划写入非临时表 */
if (u_sess->attr.attr_common.XactReadOnly && !(eflags & EXEC_FLAG_EXPLAIN_ONLY)) {
ExecCheckXactReadOnly(queryDesc->plannedstmt);
}
/* 重置内存上下文的连续编号 */
t_thrd.utils_cxt.mctx_sequent_count = 0;
/* 初始化内存跟踪信息 */
MemoryTrackingInit();
/* 创建执行状态(EState),并切换到查询特定的内存上下文 */
estate = CreateExecutorState();
queryDesc->estate = estate;
/* 根据编译选项记录执行器的内存追踪信息 */
#ifndef ENABLE_MEMORY_CHECK
t_thrd.utils_cxt.ExecutorMemoryTrack = ((AllocSet)(estate->es_query_cxt))->track;
#else
t_thrd.utils_cxt.ExecutorMemoryTrack = ((AsanSet)(estate->es_query_cxt))->track;
#endif
/* 初始化流式处理和性能监控(如果适用) */
// 这部分代码涉及特定于流处理的性能监控初始化
/* 切换到查询执行的内存上下文 */
old_context = MemoryContextSwitchTo(estate->es_query_cxt);
/* 初始化代码生成对象(如果使用代码生成) */
CodeGenThreadRuntimeSetup();
/* 从查询描述符中填充外部参数,并为内部参数分配空间 */
estate->es_param_list_info = queryDesc->params;
if (queryDesc->plannedstmt->nParamExec > 0) {
estate->es_param_exec_vals =
(ParamExecData *)palloc0(queryDesc->plannedstmt->nParamExec * sizeof(ParamExecData));
}
/*
* 如果查询不是只读的,设置命令ID以标记输出元组
*/
switch (queryDesc->operation) {
case CMD_SELECT:
/*
* 对于包含SELECT FOR UPDATE/SHARE和修改CTE的查询,需要标记元组
*/
if (queryDesc->plannedstmt->rowMarks != NIL || queryDesc->plannedstmt->hasModifyingCTE) {
estate->es_output_cid = GetCurrentCommandId(true);
}
/*
* 如果查询中不包含修改CTE,就不可能触发触发器,所以强制跳过触发器模式。
* 这只是一种边缘效率的优化,因为AfterTriggerBeginQuery/AfterTriggerEndQuery的成本不高,
* 但我们还是这样做吧。
*/
if (!queryDesc->plannedstmt->hasModifyingCTE) {
eflags |= EXEC_FLAG_SKIP_TRIGGERS;
}
break;
case CMD_INSERT:
case CMD_DELETE:
case CMD_UPDATE:
case CMD_MERGE:
estate->es_output_cid = GetCurrentCommandId(true);
break;
default:
ereport(ERROR, (errcode(ERRCODE_UNRECOGNIZED_NODE_TYPE),
errmsg("不识别的操作代码:%d", (int)queryDesc->operation)));
break;
}
/*
* 复制其他重要信息到 EState
*/
// 这部分代码复制了快照信息、执行标志、性能监控选项等到执行状态
estate->es_snapshot = RegisterSnapshot(queryDesc->snapshot); // 注册快照信息到执行状态
estate->es_crosscheck_snapshot = RegisterSnapshot(queryDesc->crosscheck_snapshot); // 注册交叉检查快照到执行状态
estate->es_top_eflags = eflags; // 将执行标志复制到执行状态的顶层标志
estate->es_instrument = queryDesc->instrument_options; // 复制仪表选项到执行状态
/* 应用 BloomFilter 数组空间。 */
// 这部分代码涉及到为查询计划中可能使用的布隆过滤器分配空间
if (queryDesc->plannedstmt->MaxBloomFilterNum > 0) {
int bloom_size = queryDesc->plannedstmt->MaxBloomFilterNum;
estate->es_bloom_filter.array_size = bloom_size; // 设置 BloomFilter 数组的大小
estate->es_bloom_filter.bfarray = (filter::BloomFilter **)palloc0(bloom_size * sizeof(filter::BloomFilter *)); // 分配 BloomFilter 数组的内存
}
/* 语句总是从协调节点 (CN) 开始 */
// 这部分代码处理时间戳设置,以确保语句执行时间的准确性
if (IS_PGXC_COORDINATOR || IS_SINGLE_NODE) {
SetCurrentStmtTimestamp(); // 设置当前语句的时间戳
} /* 否则从协调节点同步 stmtSystemTimestamp 时间戳 */
/*
* 初始化计划状态树
*/
// 这部分代码负责初始化整个查询计划的执行状态树
(void)INSTR_TIME_SET_CURRENT(starttime); // 记录当前时间
IPC_PERFORMANCE_LOG_OUTPUT("standard_ExecutorStart InitPlan start."); // 记录性能日志,表示计划初始化开始
InitPlan(queryDesc, eflags); // 初始化查询计划
IPC_PERFORMANCE_LOG_OUTPUT("standard_ExecutorStart InitPlan end."); // 记录性能日志,表示计划初始化结束
totaltime += elapsed_time(&starttime); // 计算计划初始化时间
/*
* 如果当前计划用于表达式计算,不需要收集仪表信息。
*/
// 这部分代码处理性能数据的收集
if (estate->es_instrument != INSTRUMENT_NONE && StreamTopConsumerAmI() && u_sess->instr_cxt.global_instr &&
u_sess->instr_cxt.thread_instr) {
int node_id = queryDesc->plannedstmt->planTree->plan_node_id - 1;
int *m_instrArrayMap = u_sess->instr_cxt.thread_instr->m_instrArrayMap;
// 更新仪表数据的初始化时间
u_sess->instr_cxt.thread_instr->m_instrArray[m_instrArrayMap[node_id]].instr.instruPlanData.init_time =
totaltime;
}
/*
* 设置 AFTER 触发器语句上下文,除非明确不需要,或者是 EXPLAIN-only 模式(不会调用 ExecutorFinish)。
*/
// 这部分代码负责初始化与触发器相关的上下文
if (!(eflags & (EXEC_FLAG_SKIP_TRIGGERS | EXEC_FLAG_EXPLAIN_ONLY))) {
AfterTriggerBeginQuery(); // 设置 AFTER 触发器的语句上下文
}
(void)MemoryContextSwitchTo(old_context); // 切换回原来的内存上下文
}
??其中,switch 中代码主要功能是根据查询的操作类型(queryDesc->operation)来设置命令 ID(es_output_cid),以便标记输出元组,同时根据查询类型决定是否跳过触发器。
- 对于 SELECT 查询,如果查询中包含了 FOR UPDATE 或 FOR SHARE 锁定语句,或者查询计划中包含了修改通用表表达式(CTE),则会设置命令 ID 为当前事务的命令 ID,用于标记输出元组。如果查询不包含修改 CTE,则会强制设置执行标志 eflags 中的 EXEC_FLAG_SKIP_TRIGGERS,以跳过触发器的执行。
- 对于 INSERT、DELETE、UPDATE 和 MERGE 操作,无论是否包含修改CTE,都会设置命令 ID 为当前事务的命令 ID,用于标记输出元组。
- 如果查询的操作类型不是上述任何一种,会触发一个错误报告,指示出现了不识别的操作代码。
??下面以举一个具体的案例来说明,假设我们有一个包含以下 SQL 查询的数据库:
-- 查询1:一个只读查询
SELECT name, age FROM employees WHERE department = 'HR';
-- 查询2:一个更新查询
UPDATE employees SET salary = salary + 500 WHERE department = 'Engineering';
-- 查询3:一个插入查询
INSERT INTO employees (name, age, department) VALUES ('Alice', 28, 'Marketing');
-- 查询4:一个删除查询
DELETE FROM employees WHERE name = 'Bob';
-- 查询5:一个选择性更新查询
MERGE INTO employees AS tgt
USING updated_salaries AS src
ON tgt.id = src.id
WHEN MATCHED THEN UPDATE SET tgt.salary = src.new_salary;
- 对于查询1,这是一个只读查询(CMD_SELECT),不包含任何修改操作。因此,不需要标记输出元组的命令 ID,而且触发器也不会被触发。这是通过将 eflags 中的 EXEC_FLAG_SKIP_TRIGGERS 设置为 true 来实现的。
- 对于查询2、3、4 和 5,它们都是更新查询,包括插入、更新和删除操作(CMD_INSERT、CMD_DELETE、CMD_UPDATE 和 CMD_MERGE)。对于这些查询,需要标记输出元组的命令ID,以便将来跟踪它们的修改。因此,estate->es_output_cid 被设置为当前事务的命令 ID(使用 GetCurrentCommandId(true))。
- 如果查询的操作类型不是上述任何一种,将触发错误报告,指示出现了不识别的操作代码。这可以帮助开发人员及时发现并修复代码中的问题。
??综上所述,这段代码的作用是根据查询的操作类型来确定是否需要标记输出元组的命令ID,并且在必要时设置执行标志 eflags 以跳过触发器的执行。这有助于确保在数据库操作中的元组修改能够正确地跟踪和标记。
ExecutorRun 函数
??ExecutorRun 函数主要功能是接受查询描述符并执行查询计划。它首先进行准备工作,包括解释查询计划和进行性能分析。然后,根据配置决定是否进行资源跟踪和操作符历史统计,并调用相应的函数执行查询。在查询执行完成后,它还负责记录执行时间、报告查询计划以及记录操作符历史统计信息,以便后续性能分析和查询优化。函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
/*
* ExecutorRun
*
* 这是执行器模块的主要例程。它接受来自交通警察的查询描述符,并执行查询计划。
*
* ExecutorStart 必须已经被调用。
*
* 如果 direction 是 NoMovementScanDirection,那么除了启动/关闭目标外,什么都不会执行。
* 否则,我们按指定方向检索最多 'count' 个元组。
*
* 注意:count = 0 被解释为没有门户限制,即运行到完成为止。还要注意,计数限制仅适用于检索的元组,
* 而不适用于由 ModifyTable 计划节点插入/更新/删除的元组。
*
* 没有返回值,但输出元组(如果有的话)将发送到 QueryDesc 中指定的目标接收器;并且顶层处理的元组数量
* 可以在 estate->es_processed 中找到。
*
* 我们提供了一个函数钩子变量,允许可加载插件在调用 ExecutorRun 时获取控制权。这样的插件通常会调用 standard_ExecutorRun()。
*/
void ExecutorRun(QueryDesc *queryDesc, ScanDirection direction, long count)
{
// 以下部分代码主要用于执行器运行前的准备工作和性能分析
// 检查是否需要进行操作符历史统计以及记录执行计划
int instrument_option = 0;
bool has_track_operator = false;
char* old_stmt_name = u_sess->pcache_cxt.cur_stmt_name;
// 如果 SPI 连接打开,则设置当前语句名为空
if (u_sess->SPI_cxt._connected >= 0) {
u_sess->pcache_cxt.cur_stmt_name = NULL;
}
// 执行计划解释和分析
exec_explain_plan(queryDesc);
// 根据配置决定是否进行资源跟踪和操作符历史统计
if (u_sess->attr.attr_resource.use_workload_manager &&
u_sess->attr.attr_resource.resource_track_level == RESOURCE_TRACK_OPERATOR &&
queryDesc != NULL && queryDesc->plannedstmt != NULL &&
queryDesc->plannedstmt->is_stream_plan && u_sess->exec_cxt.need_track_resource) {
#ifdef STREAMPLAN
if (queryDesc->instrument_options) {
instrument_option = queryDesc->instrument_options;
}
if (IS_PGXC_COORDINATOR && instrument_option != 0 && u_sess->instr_cxt.global_instr == NULL &&
queryDesc->plannedstmt->num_nodes != 0) {
has_track_operator = true;
queryDesc->plannedstmt->instrument_option = instrument_option;
// 初始化操作符历史统计相关数据结构
AutoContextSwitch streamCxtGuard(t_thrd.mem_cxt.msg_mem_cxt);
int dop = queryDesc->plannedstmt->query_dop;
u_sess->instr_cxt.global_instr = StreamInstrumentation::InitOnCn(queryDesc, dop);
MemoryContext old_context = u_sess->instr_cxt.global_instr->getInstrDataContext();
u_sess->instr_cxt.thread_instr = u_sess->instr_cxt.global_instr->allocThreadInstrumentation(
queryDesc->plannedstmt->planTree->plan_node_id);
(void)MemoryContextSwitchTo(old_context);
}
#endif
}
// 根据条件决定是否可以进行操作符历史统计
bool can_operator_history_statistics = false;
if (u_sess->exec_cxt.need_track_resource && queryDesc &&
(has_track_operator || (IS_PGXC_DATANODE && queryDesc->instrument_options))) {
can_operator_history_statistics = true;
}
// 如果允许操作符历史统计,执行 ExplainNodeFinish
if (can_operator_history_statistics) {
ExplainNodeFinish(queryDesc->planstate, NULL, (TimestampTz)0.0, true);
}
// 如果存在执行器运行的钩子函数,调用它
if (ExecutorRun_hook) {
(*ExecutorRun_hook)(queryDesc, direction, count);
} else {
standard_ExecutorRun(queryDesc, direction, count);
}
// 在协调节点或单节点上,报告插入、删除、更新等操作的时间
if (IS_PGXC_COORDINATOR || IS_SINGLE_NODE) {
if (queryDesc->operation == CMD_INSERT || queryDesc->operation == CMD_DELETE ||
queryDesc->operation == CMD_UPDATE || queryDesc->operation == CMD_MERGE) {
report_iud_time(queryDesc);
}
}
// SQL Self-Tuning:在查询执行完成后基于运行时信息分析查询计划问题
if (u_sess->exec_cxt.need_track_resource && queryDesc != NULL && has_track_operator &&
(IS_PGXC_COORDINATOR || IS_SINGLE_NODE)) {
List *issue_results = PlanAnalyzerOperator(queryDesc, queryDesc->planstate);
// 如果找到计划问题,将其记录到 sysview gs_wlm_session_history
if (issue_results != NIL) {
RecordQueryPlanIssues(issue_results);
}
}
// 打印查询执行时间
print_duration(queryDesc);
// 仪表统计信息报告查询计划
instr_stmt_report_query_plan(queryDesc);
// 如果允许操作符历史统计,最终记录统计信息
if (can_operator_history_statistics) {
u_sess->instr_cxt.can_record_to_table = true;
ExplainNodeFinish(queryDesc->planstate, queryDesc->plannedstmt, GetCurrentTimestamp(), false);
#ifdef ENABLE_MULTIPLE_NODES
if ((IS_PGXC_COORDINATOR) && u_sess->instr_cxt.global_instr != NULL) {
#else
if (StreamTopConsumerAmI() && u_sess->instr_cxt.global_instr != NULL) {
#endif
delete u_sess->instr_cxt.global_instr;
u_sess->instr_cxt.thread_instr = NULL;
u_sess->instr_cxt.global_instr = NULL;
}
}
// 恢复原来的语句名
u_sess->pcache_cxt.cur_stmt_name = old_stmt_name;
}
standard_ExecutorRun 函数
??standard_ExecutorRun 函数的主要功能是执行给定的查询计划,包括生成机器代码、记录执行时间、处理元组的接收和发送、进行仪表统计以及维护内存上下文等。它会根据查询的操作类型和目标接收器的要求来发送查询结果,同时还会记录查询执行的总时间,用于性能分析和监控。此外,代码还处理了一些特殊情况,如矢量化查询计划和分桶查询。具体功能如下:
- 初始化一些变量,包括执行状态 (estate)、操作类型 (operation)、目标接收器 (dest) 等,以及记录时间变量。
- 进行一些健全性检查,确保查询描述符和执行状态存在,且不处于仅解释执行的模式。
- 切换到查询内存上下文 (es_query_cxt),以便在执行期间进行内存分配。
- 生成查询的机器代码,用于执行查询计划。如果启用 LLVM 编译优化并且需要仪表统计信息,则记录 LLVM 编译时间。
- 允许仪表统计整个执行器的运行时间,如果查询描述符中指定了时间节点。
- 提取查询描述符中的操作类型和目标接收器。
- 启动元组接收器,如果查询将输出元组,并初始化元组接收相关状态。
- 设置全局桶映射 (
u_sess->exec_cxt.global_bucket_map),如果查询涉及到分布式表分桶。- 记录执行计划的开始时间,并执行查询计划。
- 在执行计划后,更新执行状态,记录已处理的元组数量,并记录执行时间。
- 标记查询描述符为已执行。
- 如果当前查询计划用于表达式计算且需要仪表统计信息,则记录执行时间到仪表统计信息中。
- 关闭元组接收器,如果启动了接收器。
- 如果查询描述符中指定了时间节点,则停止仪表统计信息节点,记录已处理的元组数量。
- 恢复到先前的内存上下文。
??函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
void standard_ExecutorRun(QueryDesc *queryDesc, ScanDirection direction, long count)
{
EState *estate = NULL; // 初始化执行状态指针
CmdType operation; // 初始化操作类型
DestReceiver *dest = NULL; // 初始化目标接收器
bool send_tuples = false; // 初始化是否发送元组的标志
MemoryContext old_context; // 保存旧的内存上下文
instr_time starttime; // 记录执行时间
double totaltime = 0; // 记录总执行时间
/* 健全性检查 */
Assert(queryDesc != NULL); // 断言查询描述符不为空
estate = queryDesc->estate; // 获取查询描述符中的执行状态
Assert(estate != NULL); // 断言执行状态不为空
Assert(!(estate->es_top_eflags & EXEC_FLAG_EXPLAIN_ONLY)); // 断言不处于仅解释执行的模式
/*
* 切换到查询内存上下文
*/
old_context = MemoryContextSwitchTo(estate->es_query_cxt);
/*
* 为此查询生成机器代码
*/
if (CodeGenThreadObjectReady()) {
if (anls_opt_is_on(ANLS_LLVM_COMPILE) && estate->es_instrument > 0) {
TRACK_START(queryDesc->planstate->plan->plan_node_id, LLVM_COMPILE_TIME); // 记录 LLVM 编译开始时间
CodeGenThreadRuntimeCodeGenerate(); // 生成机器代码
TRACK_END(queryDesc->planstate->plan->plan_node_id, LLVM_COMPILE_TIME); // 记录 LLVM 编译结束时间
} else {
CodeGenThreadRuntimeCodeGenerate(); // 生成机器代码
}
}
/* 允许仪表统计整个执行器的运行时间 */
if (queryDesc->totaltime) {
queryDesc->totaltime->memoryinfo.nodeContext = estate->es_query_cxt; // 设置仪表统计信息的内存上下文
InstrStartNode(queryDesc->totaltime); // 开始记录仪表统计信息节点
}
/*
* 从查询描述符和查询特性中提取信息
*/
operation = queryDesc->operation; // 获取操作类型
dest = queryDesc->dest; // 获取目标接收器
/*
* 如果将发出元组,则启动元组接收器
*/
estate->es_processed = 0; // 初始化已处理的元组数量
estate->es_last_processed = 0; // 初始化上一次已处理的元组数量
estate->es_lastoid = InvalidOid; // 初始化上一次的对象标识符
send_tuples = (operation == CMD_SELECT || queryDesc->plannedstmt->hasReturning); // 根据操作类型判断是否需要发出元组
/*
* 为了确保消息(T-C-Z)的完整性,无论 u_sess->exec_cxt.executor_stop_flag 的值如何,
* 都应该发送消息'T'。
*/
if (send_tuples)
(*dest->rStartup)(dest, operation, queryDesc->tupDesc); // 启动元组接收器
if (queryDesc->plannedstmt->bucketMap != NULL) {
u_sess->exec_cxt.global_bucket_map = queryDesc->plannedstmt->bucketMap[0]; // 设置全局桶映射
} else {
u_sess->exec_cxt.global_bucket_map = NULL; // 如果没有桶映射,则设置为空
}
(void)INSTR_TIME_SET_CURRENT(starttime); // 记录当前时间
/*
* 执行查询计划
*/
if (!ScanDirectionIsNoMovement(direction)) {
if (queryDesc->planstate->vectorized) {
ExecuteVectorizedPlan(estate, queryDesc->planstate, operation, send_tuples, count, direction, dest); // 执行矢量化查询计划
} else {
#ifdef ENABLE_MOT
ExecutePlan(estate, queryDesc->planstate, operation, send_tuples,
count, direction, dest, queryDesc->mot_jit_context); // 执行查询计划
#else
ExecutePlan(estate, queryDesc->planstate, operation, send_tuples, count, direction, dest); // 执行查询计划
#endif
}
}
totaltime += elapsed_time(&starttime); // 计算总执行时间
queryDesc->executed = true; // 标记查询描述符为已执行
/*
* 如果当前查询计划用于表达式计算且需要仪表统计信息,则记录执行时间到仪表统计信息中
*/
if (estate->es_instrument != INSTRUMENT_NONE && StreamTopConsumerAmI() && u_sess->instr_cxt.global_instr &&
u_sess->instr_cxt.thread_instr) {
int node_id = queryDesc->plannedstmt->planTree->plan_node_id - 1; // 获取计划节点的ID
int* m_instrArrayMap = u_sess->instr_cxt.thread_instr->m_instrArrayMap; // 获取仪表统计信息映射数组
u_sess->instr_cxt.thread_instr->m_instrArray[m_instrArrayMap[node_id]].instr.instruPlanData.run_time =
totaltime; // 记录执行时间到仪表统计信息中
}
/*
* 关闭元组接收器,如果启动了的话
*/
if (send_tuples) {
(*dest->rShutdown)(dest); // 关闭元组接收器
}
if (queryDesc->totaltime) {
InstrStopNode(queryDesc->totaltime, estate->es_processed); // 停止记录仪表统计信息节点,记录已处理的元组数量
}
(void)MemoryContextSwitchTo(old_context); // 恢复到先前的内存上下文
}
ExecutorFinish 函数
??ExecutorFinish 函数的主要作用是在最后一次执行器运行调用之后执行清理操作,例如触发 AFTER 触发器等。它是 ExecutorEnd 的独立函数,因为在执行 EXPLAIN ANALYZE 时需要将这些操作包括在总运行时间中。如果有加载的插件需要在 ExecutorFinish 被调用时执行额外操作,可以通过函数钩子 ExecutorFinish_hook 来实现,通常会调用 standard_ExecutorFinish 来完成标准的清理工作。函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
/* ----------------------------------------------------------------
* ExecutorFinish
*
* 此例程必须在最后一次 ExecutorRun 调用之后被调用。
* 它执行清理操作,例如触发 AFTER 触发器等。
* 之所以与 ExecutorEnd 分开,是因为 EXPLAIN ANALYZE 需要将这些操作的耗时计入总运行时间。
*
* 我们提供了一个函数钩子变量,允许可加载插件在调用 ExecutorFinish 时获得控制权。
* 这样的插件通常会调用 standard_ExecutorFinish 来执行标准的清理工作。
*
* ----------------------------------------------------------------
*/
void ExecutorFinish(QueryDesc *queryDesc)
{
// 如果有 ExecutorFinish_hook 函数钩子,就调用它
if (ExecutorFinish_hook) {
(*ExecutorFinish_hook)(queryDesc);
}
// 否则,调用标准的 ExecutorFinish 函数完成清理操作
else {
standard_ExecutorFinish(queryDesc);
}
}
怎么理解下面这句话呢:
??“之所以与 ExecutorEnd 分开,是因为 EXPLAIN ANALYZE 需要将这些操作的耗时计入总运行时间。”
??这句话的意思是,将 ExecutorFinish 和 ExecutorEnd 分开的原因是因为在性能分析工具(如 EXPLAIN ANALYZE )中,我们希望能够准确地统计每个查询执行的时间,包括清理操作所花费的时间。
??举个例子来说明:假设我们有一个包含多个查询的 SQL 脚本,我们想要使用 EXPLAIN ANALYZE 来分析每个查询的性能。如果将 ExecutorFinish 的清理操作合并到 ExecutorEnd 中,那么在执行完最后一个查询后,所有的清理操作会一起计入总运行时间。这将导致我们无法区分每个查询的实际执行时间,因为清理操作的时间会被分摊到所有查询上。
??通过将 ExecutorFinish 与 ExecutorEnd 分开,我们可以确保每个查询的执行时间只包括查询本身的时间,清理操作的时间会被单独计算并添加到总运行时间中。这使得我们能够更精确地分析每个查询的性能,并识别性能瓶颈或优化机会。这对于数据库性能调优和查询分析非常有用。
standard_ExecutorFinish 函数
??standard_ExecutorFinish 函数的作用是在执行器完成所有查询执行后进行清理工作,包括运行 ModifyTable 节点以确保所有修改操作已完成,并执行等待触发的 AFTER 触发器。这些清理操作需要确保在性能分析工具(如 EXPLAIN ANALYZE)中能够准确地计入总运行时间。函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
void standard_ExecutorFinish(QueryDesc *queryDesc)
{
EState *estate = NULL;
MemoryContext old_context;
/* sanity checks */
Assert(queryDesc != NULL); // 断言确保传入的queryDesc参数不为空
estate = queryDesc->estate; // 获取查询状态信息
Assert(estate != NULL); // 断言确保查询状态信息不为空
Assert(!(estate->es_top_eflags & EXEC_FLAG_EXPLAIN_ONLY)); // 断言确保不是处于解释执行模式下
/* This should be run once and only once per Executor instance */
Assert(!estate->es_finished); // 断言确保此方法只会在Executor实例中运行一次
/* Switch into per-query memory context */
old_context = MemoryContextSwitchTo(estate->es_query_cxt); // 切换到查询内存上下文
/* Allow instrumentation of Executor overall runtime */
if (queryDesc->totaltime)
InstrStartNode(queryDesc->totaltime); // 启动执行器总运行时间的性能计数
/* Run ModifyTable nodes to completion */
ExecPostprocessPlan(estate); // 执行ModifyTable节点的后处理,确保所有修改操作完成
/* Execute queued AFTER triggers, unless told not to */
if (!(estate->es_top_eflags & EXEC_FLAG_SKIP_TRIGGERS)) {
AfterTriggerEndQuery(estate); // 执行等待触发的AFTER触发器,除非明确禁止
}
if (queryDesc->totaltime) {
InstrStopNode(queryDesc->totaltime, 0); // 停止执行器总运行时间的性能计数
}
(void)MemoryContextSwitchTo(old_context); // 切换回之前的内存上下文
estate->es_finished = true; // 设置Executor实例为已完成状态
}
ExecutorEnd 函数
??ExecutorEnd 函数的作用是在任何查询计划执行结束后调用,它可以通过钩子函数的方式来扩展功能,允许外部插件介入执行器的结束阶段。如果没有钩子函数,它将调用标准的 ExecutorEnd 函数来完成必要的清理和资源释放工作。函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
/* ----------------------------------------------------------------
* ExecutorEnd
*
* This routine must be called at the end of execution of any
* query plan
*
* We provide a function hook variable that lets loadable plugins
* get control when ExecutorEnd is called. Such a plugin would
* normally call standard_ExecutorEnd().
*
* ----------------------------------------------------------------
*/
void ExecutorEnd(QueryDesc *queryDesc)
{
if (ExecutorEnd_hook) {
(*ExecutorEnd_hook)(queryDesc); // 如果有ExecutorEnd的挂钩函数,则调用挂钩函数,否则调用标准的ExecutorEnd函数
} else {
standard_ExecutorEnd(queryDesc); // 调用标准的ExecutorEnd函数
}
}
standard_ExecutorEnd 函数
??standard_ExecutorEnd 函数的作用是在查询计划执行结束后进行必要的清理工作。它首先执行一些断言和内存检查,以确保执行器状态正常,然后切换到每个查询的内存上下文,并调用 ExecEndPlan 来结束查询计划的执行,释放与执行相关的资源。接着,它注销已注册的快照信息,关闭代码生成线程(如果存在),并输出内存跟踪信息到文件。最后,它计算查询执行的总时间,并记录到工具信息中,用于性能分析。函数源码如下所示:(路径:src\gausskernel\runtime\executor\execMain.cpp)
void standard_ExecutorEnd(QueryDesc *queryDesc)
{
EState *estate = NULL;
MemoryContext old_context;
instr_time starttime;
double totaltime = 0;
(void)INSTR_TIME_SET_CURRENT(starttime); // 设置开始时间
/* sanity checks */
Assert(queryDesc != NULL); // 断言确保查询描述不为空
estate = queryDesc->estate; // 获取查询状态信息
Assert(estate != NULL); // 断言确保查询状态不为空
#ifdef MEMORY_CONTEXT_CHECKING
/* 检查内存上下文,用于内存泄漏检测 */
MemoryContextCheck(t_thrd.top_mem_cxt, false);
#endif
/*
* 检查是否调用了ExecutorFinish,除非是在仅解释模式下,这是必要的,因为ExecutorFinish是从9.1版本开始的新功能,调用者可能会忘记调用它。
*/
Assert(estate->es_finished || (estate->es_top_eflags & EXEC_FLAG_EXPLAIN_ONLY));
/*
* 切换到每个查询的内存上下文以运行ExecEndPlan
*/
old_context = MemoryContextSwitchTo(estate->es_query_cxt);
/* 执行计划结束,释放与执行相关的资源 */
ExecEndPlan(queryDesc->planstate, estate);
/* 释放快照信息 */
UnregisterSnapshot(estate->es_snapshot);
UnregisterSnapshot(estate->es_crosscheck_snapshot);
if (!t_thrd.codegen_cxt.g_runningInFmgr) {
CodeGenThreadTearDown();
}
/*
* 在销毁之前必须切换出上下文
*/
(void)MemoryContextSwitchTo(old_context);
#ifdef MEMORY_CONTEXT_CHECKING
/* 检查每个查询的内存上下文,用于内存泄漏检测 */
MemoryContextCheck(estate->es_query_cxt, (estate->es_query_cxt->session_id > 0));
#endif
/*
* 释放EState和每个查询的内存上下文,这应该释放执行器分配的所有资源。
*/
FreeExecutorState(estate);
/* 重置不再指向任何内容的查询描述字段 */
queryDesc->tupDesc = NULL;
queryDesc->estate = NULL;
queryDesc->planstate = NULL;
queryDesc->totaltime = NULL;
/* 输出内存跟踪信息到文件 */
MemoryTrackingOutputFile();
totaltime += elapsed_time(&starttime); // 计算执行结束的总时间
/*
* 如果当前计划用于表达式计算,则无需收集工具信息。
*/
if (queryDesc->instrument_options != 0 && StreamTopConsumerAmI() && u_sess->instr_cxt.global_instr &&
u_sess->instr_cxt.thread_instr) {
int node_id = queryDesc->plannedstmt->planTree->plan_node_id - 1;
int *m_instrArrayMap = u_sess->instr_cxt.thread_instr->m_instrArrayMap;
u_sess->instr_cxt.thread_instr->m_instrArray[m_instrArrayMap[node_id]].instr.instruPlanData.end_time =
totaltime;
}
/* 重置永久空间的全局值 */
perm_space_value_reset();
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Leetcode26-按身高排序(2418)
- 区块链技术是什么?解析其基本原理及应用
- 使用adb安装app
- 数据库表1和表2对比出差异列 将表1的插入表2
- 1、springboot项目运行报错
- 回归预测 | MATLAB实现SABO-LSTM基于减法平均优化器优化长短期记忆神经网络的多输入单输出数据回归预测模型 (多指标,多图)
- 笙默考试管理系统-MyExamTest----codemirror(68)
- 二分查找(二)
- JKD的组成、Java跨平台、Path环境变量设置
- 跨国制造业组网方案解析,如何实现总部-分支稳定互联?