力扣● 435. 无重叠区间 ● 763.划分字母区间 ● 56. 合并区间
发布时间:2024年01月18日
● 435. 无重叠区间
跟弓箭题一样的原理:先集体对左边界排序,然后从第1个区间开始,当下一个区间的左边界比该区间的右边界要小的时候,就得去掉这个区间(count++),然后应该①直接更新该区间的右边界为和他重叠的所有区间的最小右边界(取这个和上一个的较小值,会使得更新的右边界越来越小,直到最小)。或者②维护一个right代表这个最小右边界,每一次统计之后更新这个right。
直接改:
class Solution {
public:
static bool cmp(vector<int> a,vector<int> b){
return a[0]<b[0];
}
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if(intervals.empty())return 0;
sort(intervals.begin(),intervals.end(),cmp); //左边界从小到大排
int count=0;
for(int i=1; i<intervals.size(); ++i){
if(intervals[i][0]<intervals[i-1][1]){
count++;
intervals[i][1]=min(intervals[i-1][1],intervals[i][1]);
}
}
return count;
}
};使用变量right(注意下一个区间和这个不重叠的话要更新一下right为现在区间的右边界):
class Solution {
public:
static bool cmp(vector<int> a,vector<int> b){
return a[0]<b[0];
}
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
if(intervals.empty())return 0;
sort(intervals.begin(),intervals.end(),cmp); //左边界从小到大排
int count=0,right=intervals[0][1];
for(int i=1; i<intervals.size(); ++i){
if(intervals[i][0]<right){
count++;
right=min(right,intervals[i][1]);
}
else{
right=intervals[i][1];
}
}
return count;
}
};● 763.划分字母区间
最主要的:每个节点的最远出现位置都要先求出来,挨个统计。
在遍历的过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。
可以分为如下两步:
- 统计每一个字符最后出现的位置
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
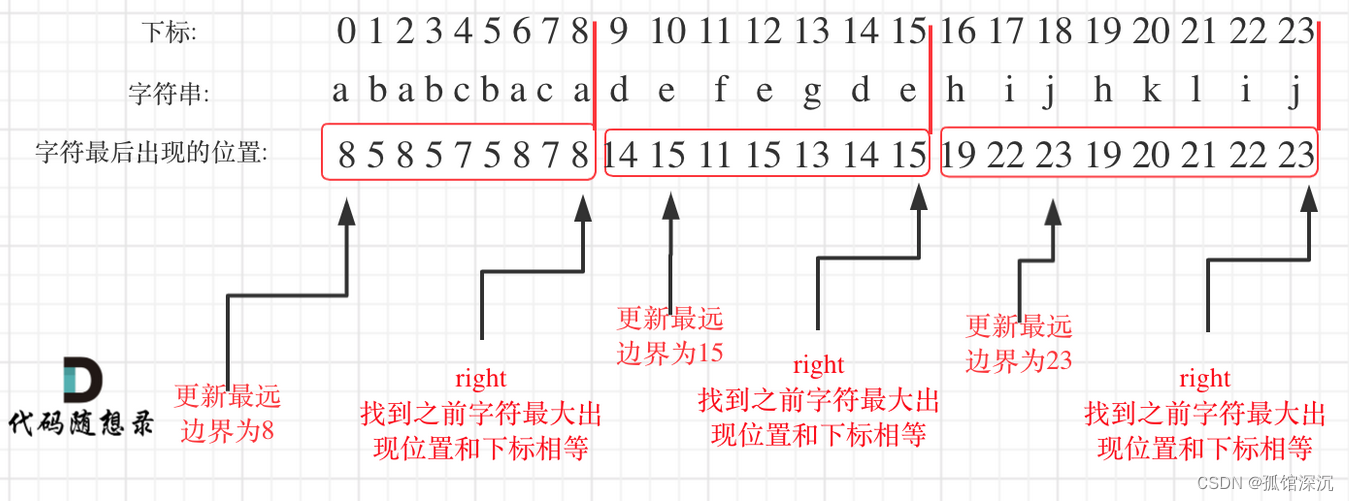
方案一:不用哈希映射(时间开销大)
class Solution {
public:
vector<int> partitionLabels(string s) {
vector<int> result;
int right=INT_MIN,left=-1;//left是上一次的right,最远距离
for(int i=0; i<s.size(); ++i){
int j=s.size()-1;
for(; j>=0; --j){
if(s[j]==s[i]){
break; //j是s[i]最远的出现距离
}
}
right=max(right,j); //更新
if(i==right){ //找到之前字符最大出现位置和下标相等
result.push_back(right-left);
left=right;
}
}
return result;
}
};用哈希映射:
class Solution {
public:
vector<int> partitionLabels(string s) {
vector<int> result;
map<char,int> hash;
for(int i=0; i<s.size(); ++i){
hash[s[i]]=i;
}
int right=hash[s[0]],left=-1;
for(int i=0;i<s.size();++i){
right=max(hash[s[i]],right);
if(right==i){
result.push_back(right-left);
left=right;
}
}
return result;
}
};● 56. 合并区间
文章来源:https://blog.csdn.net/weixin_45706374/article/details/135658895
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 旅游海报图怎么做二维码展示?扫码即可查看图片
- libzmq ZMQ_SERVER and ZMQ_CLIENT was not declared in this scope
- Prometheus实战篇:Prometheus告警简介
- 什么是序列化?什么是反序列化?
- 腾讯云服务器CVM和轻量应用服务器优惠价格表2024年更新
- Windows文件目录结构及其解析
- 日处理100立方污水的污水成套设备需要哪些
- 半监督学习 - 自训练(Self-training)
- SpringBoot代码混淆与反混淆加密工具详解
- 80V 72V 60V 48V 降12V 5V 3.3V 功耗低降压恒压芯片H6603