U-ViT【All are Worth Words: A ViT Backbone for Diffusion Models】
Motivation
Diffusion中常用的Backbone是UNet,使用 resnet 和 transformer 交替进行的,这样内存memory存储 其实也是不断shuffle变化的,resnet 以 feature 看 memory,而 transformer 以 token 看memory。如果可以统一memory的计算架构,那么memory的view就会好看很多。
用ViT结构代替UNet结构来做扩散模型
U-ViT的一篇同期工作 DiT: Scalable Diffusion Models with Transformers 也提出了使用ViT代替U-Net的思想,不同的是DiT中没有引入long skip connection也依然取得了杰出的效果,且DIT用ViT做 class-label 的 conditional image generation,U-ViT则进一步完成了ViT的 class-label、text、image等任意 的 conditional image generation。
Method
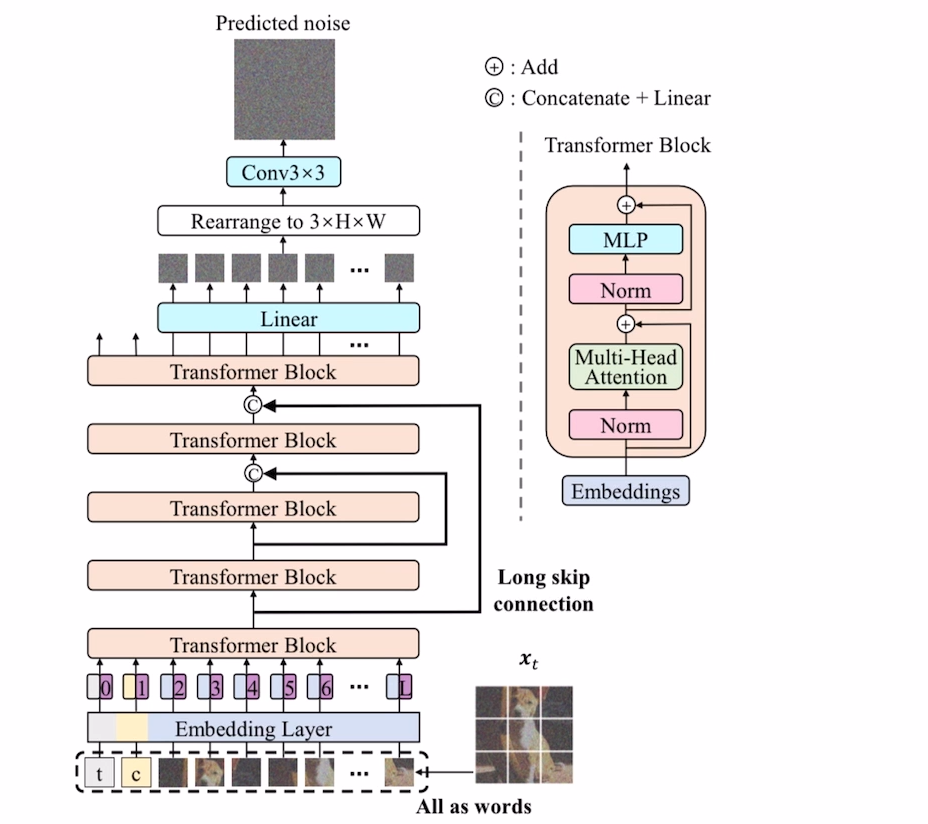
如下图所示,U-ViT 延续了 ViT 的方法,将带噪图片划分为多个patch之后,将时间t,条件c,图像patch,视作token输入到Transformer block,同时加上position encoding,同时在网络浅层和深层之间引入long skip connection。经过 5 层 transformer block,得到输出的token,经过Linear Layer将token变为patch,最后经过3x3的Conv得到最终的pred_noise image。
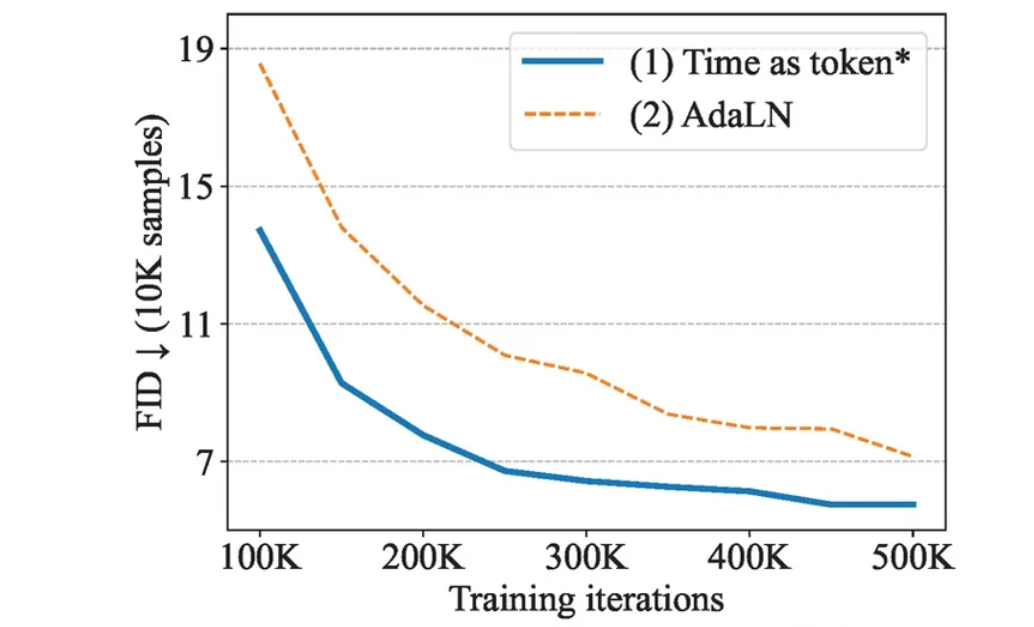
Ablation Study

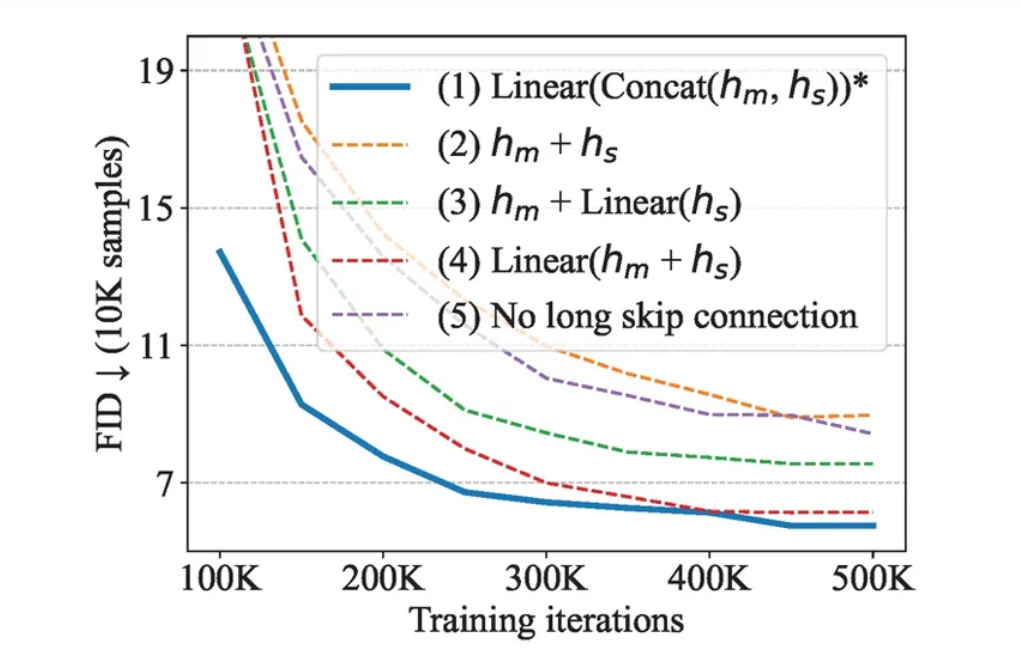
可以看出,long skip connection对于图像生成的FID分数是至关重要的。



总结
U-ViT是一种简单且通用的基于ViT的扩散概率模型的主干网络,U-ViT把所有输入,包括图片、时间、条件都当作token输入,并且引入了long skip connection。U-ViT在无条件生成、类别条件生成以及文到图生成上均取得了可比或者优于CNN的结果。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!