spark 入门教程
发布时间:2024年01月21日
一、安装scala环境
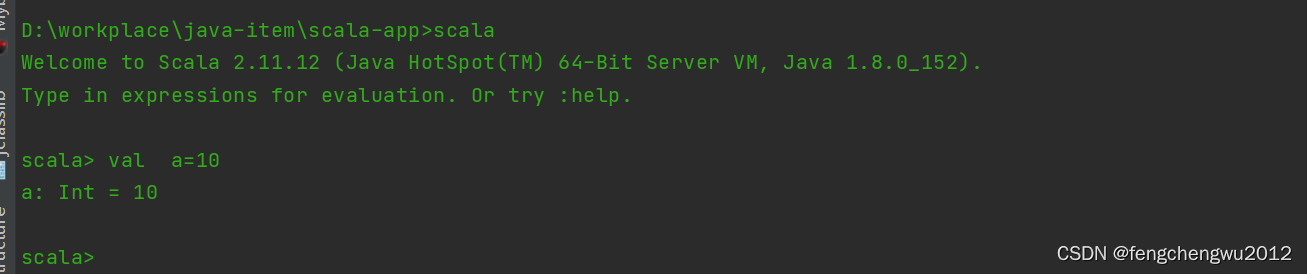
? ? ? ? 官网下载地址?Download | The Scala Programming Language,本次使用版本为sacla2.11.12,将压缩包解压至指定目录,配置好环境变量,控制台验证是否安环境是否可用:
 二、添加pom依赖
二、添加pom依赖
? ? ?创建一个maven项目
1、添加scala的sdk依赖
<properties>
<scala.version>2.11.12</scala.version>
</properties>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency>2、添加spark依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.8</version>
<scope>provided</scope>
</dependency>三、入门应用
1、数据源
? ?test_spark.txt
中国 河南
中国 浙江
河南 郑州
浙江 杭州
河南 洛阳
浙江 宁波
美国 纽约
纽约 华尔街
美国 吉利福尼亚
加利福尼亚 落砂机2、编码实现
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
///使用本地模式连接spark
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
///读取文件中每一行字符 存入到是数据集合RDD中
val lines: RDD[String] = sc.textFile("D:/workplace/java-item/res/file/test_spark.txt")
/// 将数据集合进行扁平化操作 以字符空格分割
val tuples = lines.flatMap(_.split(" ")).groupBy(word => word).map({ case (w, l) => (w, l.size) }).collect()
tuples.foreach(println)
}
}
文章来源:https://blog.csdn.net/fengchengwu2012/article/details/135729263
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 渗透测试中信息收集
- 百模大战中AI行业的新趋势
- 微信小程序canvas画布实现元素缩放、移动、自由绘制源代码
- ReactHooks:渲染与useState
- innerHTML与inner Text理解
- postgresql 流复制原理
- 中国社科院与新加坡新跃社科大联合培养博士—未来是我们自己创造的
- AI大语言模型学习笔记之一:大型语言模型(LLMs)概览
- Python---多进程的使用
- 第十天:信息打点-APP&amp;小程序篇&amp;抓包封包&amp;XP框架&amp;反编译&amp;资产提取