01-分布式链路追踪起源
发布时间:2024年01月13日
1.1:分布式链路追踪系统起源
1.1.1:现状
-
在较大型web集群和微服务环境中,客户端的一次请求可能需要经过多个不同的模块,多个不同中间件,多台不同机器的一起协作才能处理完成客户端请求,而在这一系列的请求过程中,处理流程可能是串行执行也有可能是并行执行的。那么如何确定客户端一次请求到结束的背后究竟调用了哪些应用以及哪些模块并经过哪些节点,且每个模块调用先后顺序是怎样的,每个模块处理的相应的性能如何?后期随着业务系统的不断增多,业务处理逻辑会越来越来复杂,而分布式系统中急需一套追踪(Trace)系统来解决这些痛点,从而让运维人员对整个业务系统一目了然,了如指掌。 -
分布式服务跟踪系统是整个分布式系统中跟踪一个用户请求的完整过程,包括数据采集,数据传输,数据存储,数据分析和数据可视化,获取并存储和分享此类跟踪可以让运维清晰了解用户请求与业务系统交互背后的整个调用链的调用关系,链路追踪系统是针对微服务不可或缺。
1.1.2:google 链路追踪系统
-
Dapper是google公司在2008年就开始内部使用经过生产环境验证的链路追踪系统。 -
2010年Google发布的Dapper论文:https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/papers/dapper-2010-1.pdf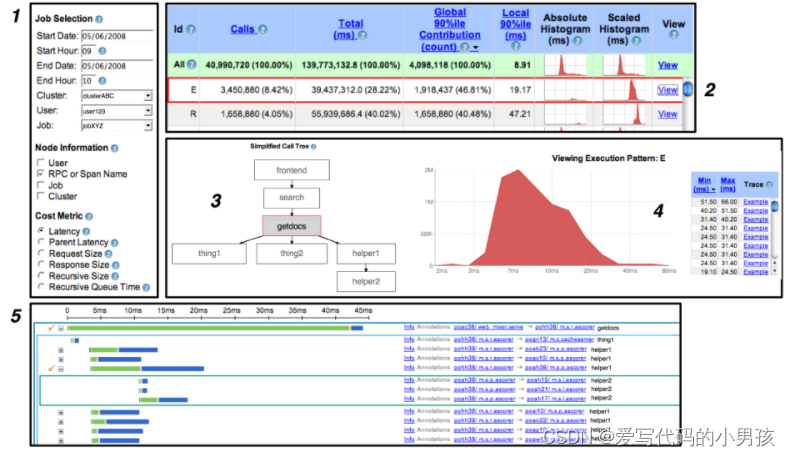
1.1.3:面临的业务环境
-
业务系统是使用复杂的,大规模的分布式集群实现,并且由很多服务组成。 每个服务可能使用不同的开发框架或者语言。 服务可能运行在数千台服务器,并且分布在不同的数据中心,对管理和监控产生挑战。 因此,需要专门的工具去追踪请求,理解整体系统的瓶颈。假如一个请求太慢,那么要通过工具快速找到rootcause。 -
一个前端服务作为访问入口,用户的请求可能会被转发至多个后端服务处理,当出现系统响应慢的时候,运维工程师很难对各个请求了如指掌,因为其中每个服务都可能由不同的团队开发和维护的。而且不同的后端服务还可能被不同的前端进行调用。
文章来源:https://blog.csdn.net/weixin_38753143/article/details/135570056
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 加域不成功,提示SMB版本原因报错
- IP定位应对恶意IP攻击:保护网络安全的新策略
- maven限制内存使用峰值/最大内存
- 如何优化PID控制参数以提高变频器性能?
- activiti流程图+动态表单
- 中国成为全球最大汽车出口国 | 百能云芯
- 【跟着暴躁哥学 Python】 http.server:快速搭建你的本地服务器
- 基于springboot+vue的在线拍卖系统(前后端分离)
- yarn包管理器在添加、更新、删除模块时,在项目中是如何体现的
- 常用Java代码-Java中的并发集合(ConcurrentHashMap、CopyOnWriteArrayList等)