C++力扣题目46--全排列
46.全排列
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
- 输入: [1,2,3]
- 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
#思路
此时我们已经学习了77.组合问题?(opens new window)、?131.分割回文串?(opens new window)和78.子集问题?(opens new window),接下来看一看排列问题。
相信这个排列问题就算是让你用for循环暴力把结果搜索出来,这个暴力也不是很好写。
所以正如我们在关于回溯算法,你该了解这些!?(opens new window)所讲的为什么回溯法是暴力搜索,效率这么低,还要用它?
因为一些问题能暴力搜出来就已经很不错了!
我以[1,2,3]为例,抽象成树形结构如下:
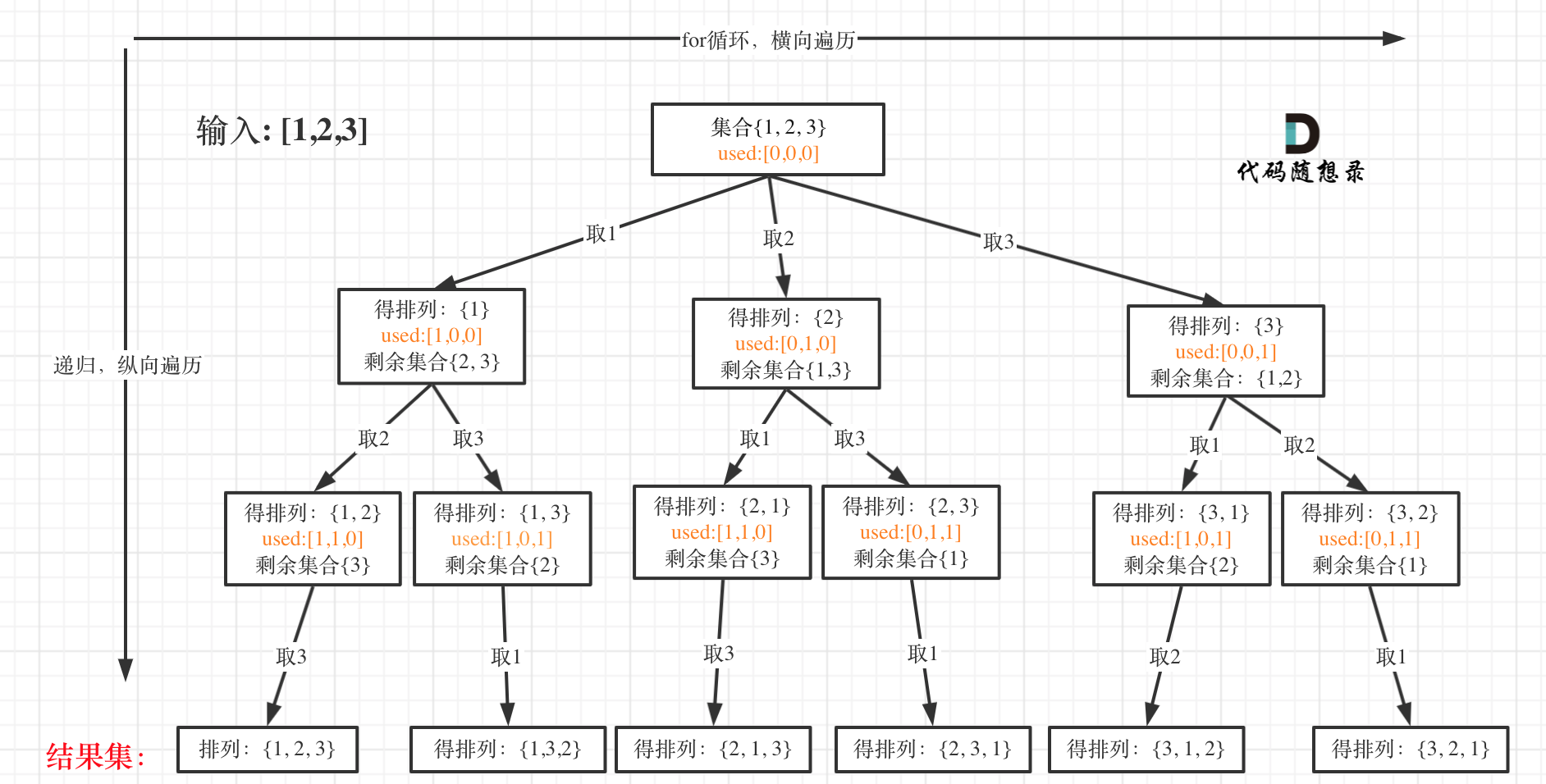
#回溯三部曲
- 递归函数参数
首先排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
但排列问题需要一个used数组,标记已经选择的元素,如图橘黄色部分所示:
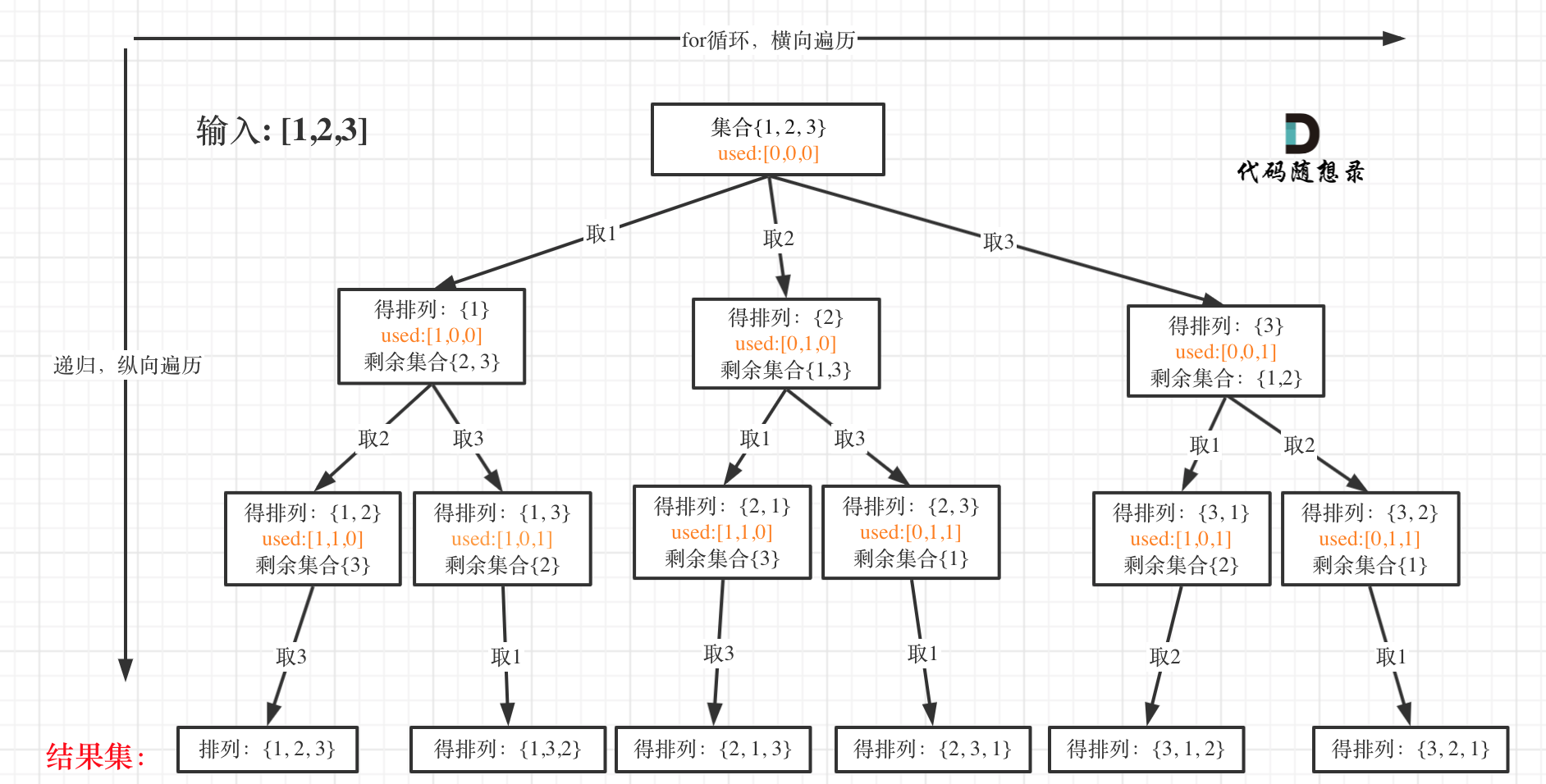
代码如下:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used)
- 递归终止条件
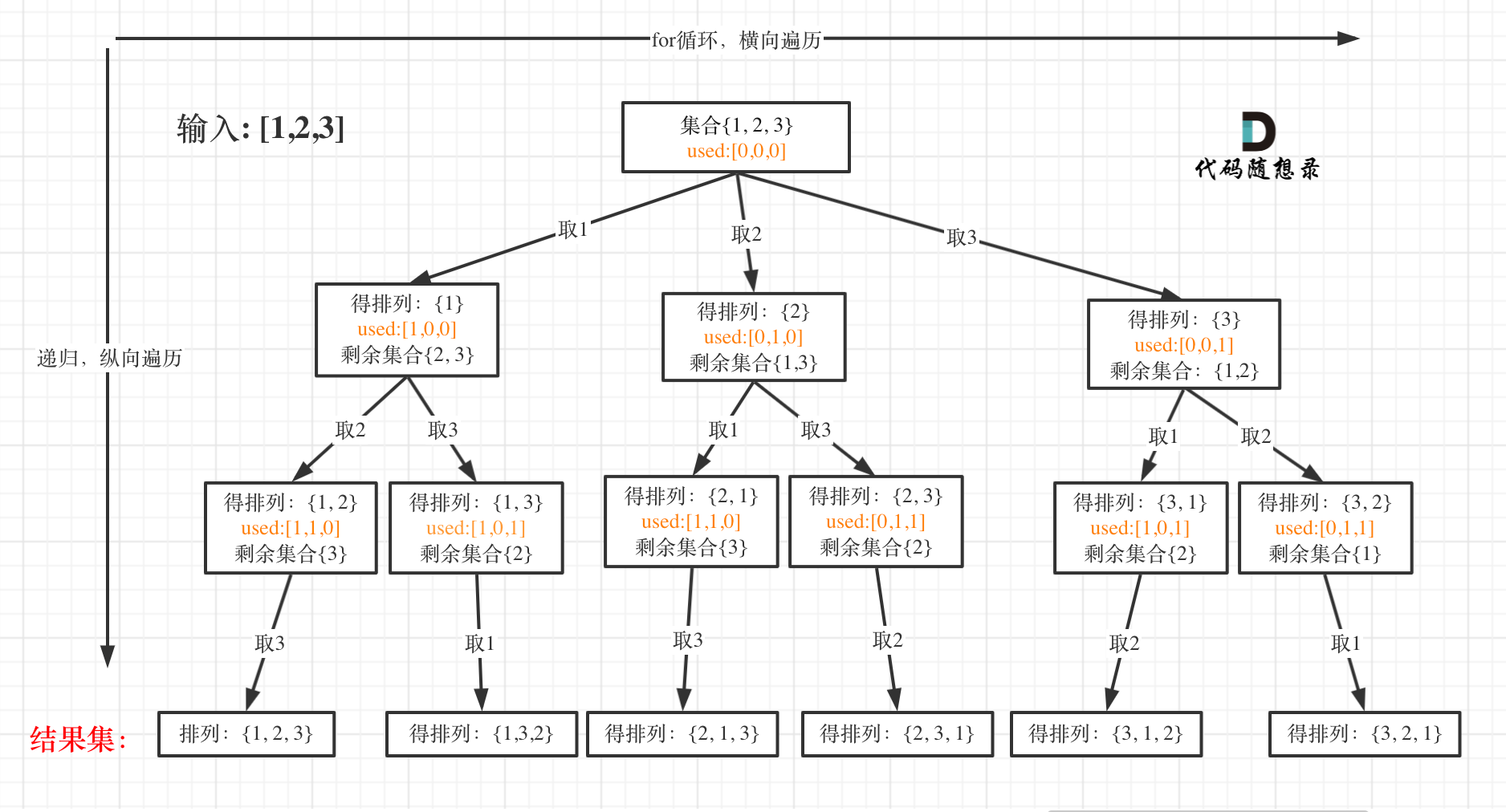
可以看出叶子节点,就是收割结果的地方。
那么什么时候,算是到达叶子节点呢?
当收集元素的数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点。
代码如下:
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
- 单层搜索的逻辑
这里和77.组合问题?(opens new window)、131.切割问题?(opens new window)和78.子集问题?(opens new window)最大的不同就是for循环里不用startIndex了。
因为排列问题,每次都要从头开始搜索,例如元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1。
而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
代码如下:
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
整体C++代码如下:
class Solution {
public:
vector<vector<int>> result;
vector<int> path;
void backtracking (vector<int>& nums, vector<bool>& used) {
// 此时说明找到了一组
if (path.size() == nums.size()) {
result.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // path里已经收录的元素,直接跳过
used[i] = true;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
result.clear();
path.clear();
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return result;
}
};
- 时间复杂度: O(n!)
- 空间复杂度: O(n)
#总结
大家此时可以感受出排列问题的不同:
- 每层都是从0开始搜索而不是startIndex
- 需要used数组记录path里都放了哪些元素了
排列问题是回溯算法解决的经典题目,大家可以好好体会体会
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 运算符的优先级(规矩是人定的)
- leetcode面试经典二分系列刷题心得
- YOLOv8改进 | 损失函数篇 | SlideLoss、FocalLoss分类损失函数助力细节涨点(全网最全)
- boost::graph学习
- UE5.1_AI随机漫游
- 1.7 实战:Postman请求Post接口-登录
- jvm垃圾回收器
- Go 语言中 For 循环:语法、使用方法和实例教程
- 关于Microsoft Edge的扩展插件,看这篇就够了
- 【toolschain】关于anaconda安装包时候 系统级全局安装还是安装在虚拟环境里的问题总结