Scrapyd——Scrapy爬虫部署神器
🍅 写在前面
👨?🎓 博主介绍:大家好,这里是hyk写算法了吗,一枚致力于学习算法和人工智能领域的小菜鸟。
🔎个人主页:主页链接(欢迎各位大佬光临指导)
??近期专栏:机器学习与深度学习
??????????????????????LeetCode算法实例
前言
?? 首先本篇文章是基于Scrapy技术,大家都已经很清楚Scrapy爬虫项目的强大之处,但是在使用这项技术时会遇到很多其本身无法解决的问题;如:想要在服务器上部署Scrapy或者在Django项目中整合Scrapy爬虫等问题,由此可以引出一个Scrapy项目部署工具——Scrapyd
Scrapyd简介
??scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
Scrapyd使用
安装
scrapyd服务:
pip install scrapyd
scrapyd客户端:
pip install scrapyd-client
这里下载的版本可能与环境版本有冲突,大家可以自行搜索适合自己环境的版本
运行
直接在命令行输入命令即可
scrapyd
出现以下即表示运行成功

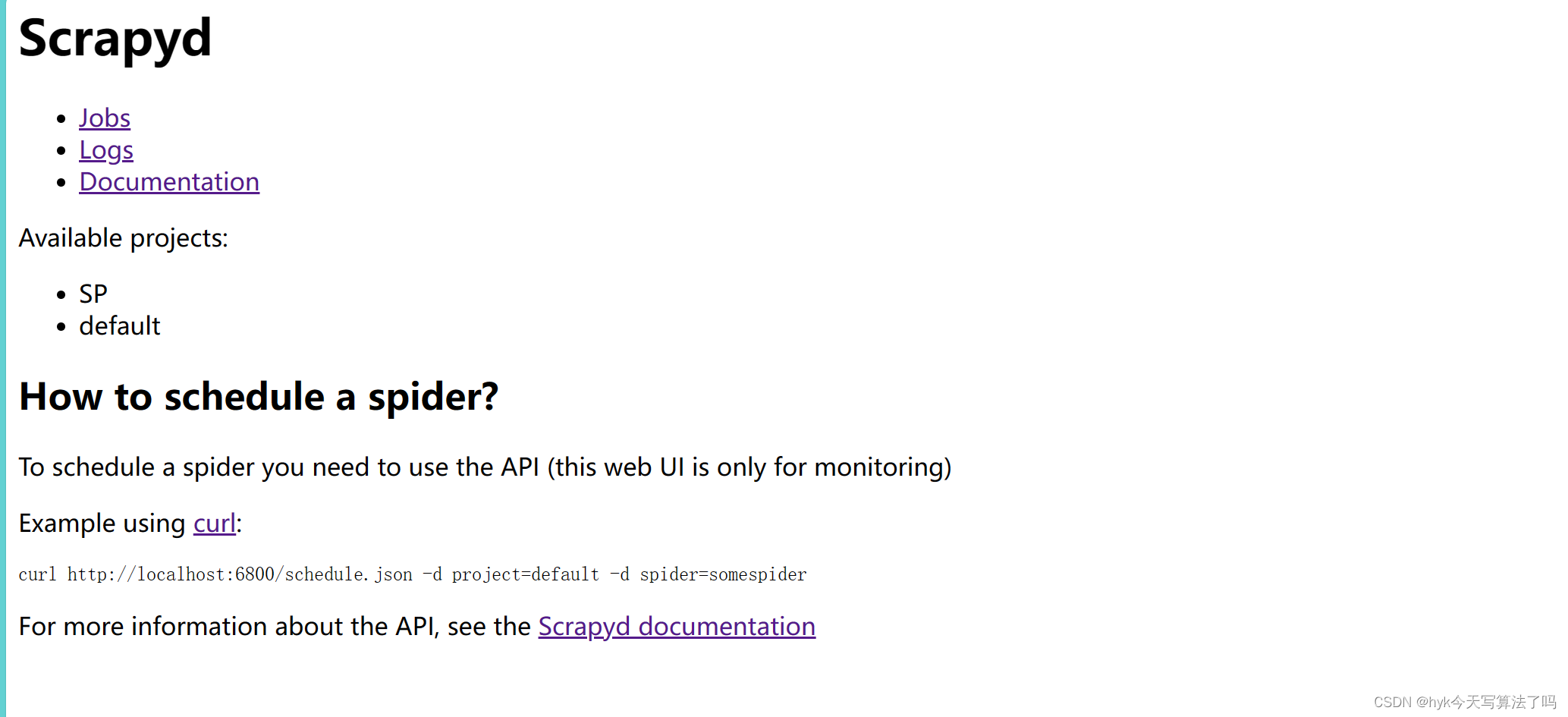
启动成功之后,我们就可以访问服务器的 6800 端口看到一个 WebUI 页面了,例如地址为127.0.0.1,在上面安装好了 Scrapyd 并成功运行,那么我就可以在本地的浏览器中打开: http://127.0.0.1:6800,就可以看到 Scrapyd 的首页,这里请自行替换成你的服务器地址查看即可,如图所示:
部署项目
??部署方法有很多(大家可以自行搜索),这里提供一个最简便易行的方法,使用Scrapyd-Client 部署。使用这个方法我们不需要再去关心 Egg 文件是怎样生成的,也不需要再去读 Egg 文件并请求接口上传了,这一切的操作只需要执行一个命令即可一键部署。
??①要部署 Scrapy 项目,我们首先需要修改一下项目的配置文件,例如我们之前写的 Scrapy 项目,在项目的第一层会有一个 scrapy.cfg 文件,我们需要修改该文件如下:
[settings]
default = SP.settings
[deploy:SP]
url = http://localhost:6800/
project = SP
](https://img-blog.csdnimg.cn/direct/b98bcf0ef0d14227bf91b5c26ceb8e9b.png)
这里爬虫项目名1以及部署爬虫名2可以自拟
url是你确定要部署的地址及端口号
②在命令行输入scrapyd-deploy 爬虫项目名1 -p 部署爬虫名2
出现以下即表示部署成功

启动爬虫
①使用curl:
#启动爬虫
curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
# 关闭爬虫
curl http://localhost:6800/cancel.json -d project=project_name -d job=jobid
project_name是部署项目名称
spider_name是你要运行的爬虫名称
jobid是启动爬虫成功后返回的id
②使用requests模块控制,附上各种操作代码
import requests
def get_status():
# 获取状态
url = "http://127.0.0.1:6800/daemonstatus.json"
res = requests.get(url)
return res.json()
def get_project_list():
# 获取项目列表
url = "http://127.0.0.1:6800/listprojects.json"
res = requests.get(url)
return res.json()
def get_spider_list(project):
# 获取项目下已发布的爬虫列表
url = "http://127.0.0.1:6800/listspiders.json?project={}".format(project)
res = requests.get(url)
return res.json()
def spider_list_ver(project):
# 获取项目下已发布的爬虫版本列表
url = "http://127.0.0.1:6800/listversions.json?project={}".format(project)
res = requests.get(url)
return res.json()
def get_spider_status(spider):
# 获取爬虫运行状态
url = "http://localhost:6800/listjobs.json?project={}".format(spider)
res = requests.get(url)
return res.json()
def start_spider(project, spider, kwargs=None):
# 运行一个爬虫
url = "http://localhost:6800/schedule.json"
data = {
"project": project,
"spider": spider,
}
if kwargs:
data["data"] = kwargs
res = requests.post(url, data=data)
return res.json()
def del_spider(project, version):
# 删除某一版本爬虫
url = "http://127.0.0.1:6800/delversion.json"
data = {
"project": project,
"version": version,
}
res = requests.post(url, data=data)
return res.json()
def del_pro(project):
# 删除项目。注意:删除之前需要停止爬虫,才可以再次删除
url = "http://127.0.0.1:6800/delproject.json"
data = {
"project": project,
}
res = requests.post(url, data=data)
return res.json()
def get_jobs(project):
# 获取jobs
url = "http://127.0.0.1:6800/listjobs.json?project={}".format(project)
res = requests.get(url)
return res.json()
def cancel(project, job_id):
# 取消job
url = "http://localhost:6800/cancel.json"
data = {
"project": project,
"job": job_id
}
res = requests.post(url, data=data)
return res.json()
def publish():
# 发布项目
url = "http://127.0.0.1:6800/addversion.json"
data = {
"project": "mySpider",
"version": 1,
"egg": '1.egg'
}
res = requests.post(url, data=data)
return res.json()
补充
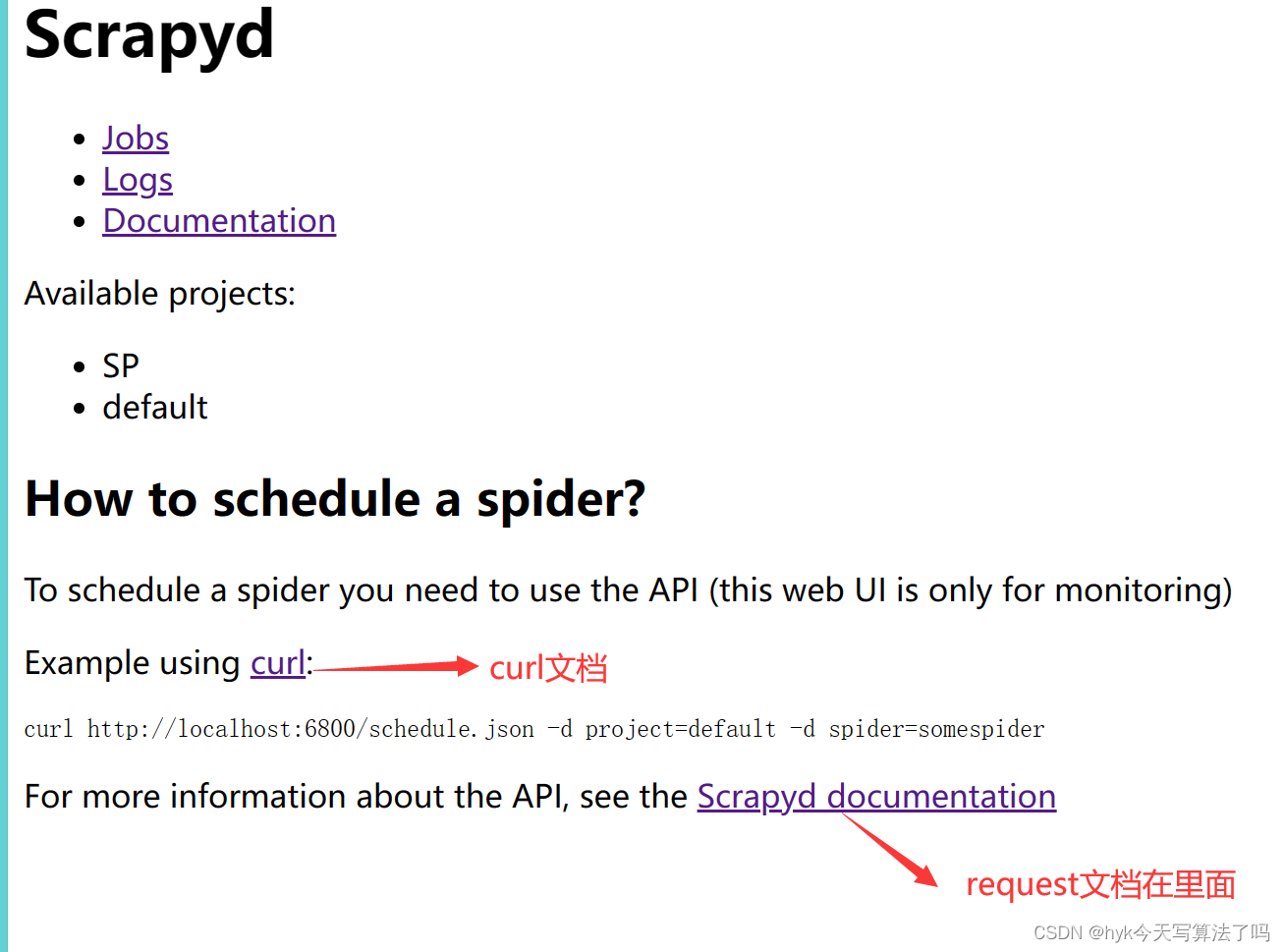
各种操作API可以在Scrapy的UI页面中找到文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!