redis 从0到1完整学习 (十九):IO多路复用之select和poll
1. 引言
前情提要:
《redis 从0到1完整学习 (一):安装&初识 redis》
《redis 从0到1完整学习 (二):redis 常用命令》
《redis 从0到1完整学习 (三):redis 数据结构》
《redis 从0到1完整学习 (四):字符串 SDS 数据结构》
《redis 从0到1完整学习 (五):集合 IntSet 数据结构》
《redis 从0到1完整学习 (六):Hash 表数据结构》
《redis 从0到1完整学习 (七):ZipList 数据结构》
《redis 从0到1完整学习 (八):QuickList 数据结构》
《redis 从0到1完整学习 (九):SkipList 数据结构》
《redis 从0到1完整学习 (十):RedisObject 数据结构》
《redis 从0到1完整学习 (十一):RedisObject 之 String 类型》
《redis 从0到1完整学习 (十二):RedisObject 之 List 类型》
《redis 从0到1完整学习 (十三):RedisObject 之 Set 类型》
《redis 从0到1完整学习 (十四):RedisObject 之 ZSet 类型》
《redis 从0到1完整学习 (十五):RedisObject 之 Hash 类型》
《redis 从0到1完整学习 (十六):内存回收之 key 过期处理策略》
《redis 从0到1完整学习 (十七):内存回收之内存淘汰策略》
《redis 从0到1完整学习 (十八):阻塞/非阻塞 IO》
之前介绍了阻塞、非阻塞 I/O 技术,本文主要介绍 IO 多路复用机制的select 和 poll 的机制。
2. redis 源码下载
Redis 源码可以点击这里下载,方便查看其中定义的一些数据结构。
3. IO多路复用
IO多路复用(I/O Multiplexing)是一种同步 IO 模型,主要用于网络编程中高效地处理多个文件描述符(通常是 socket 连接)的事件。在单个进程中,通过调用特定的系统 API,程序可以同时监听多个文件描述符的状态变化,而无需为每一个单独的连接创建一个线程或进程。
IO多路复用模型:
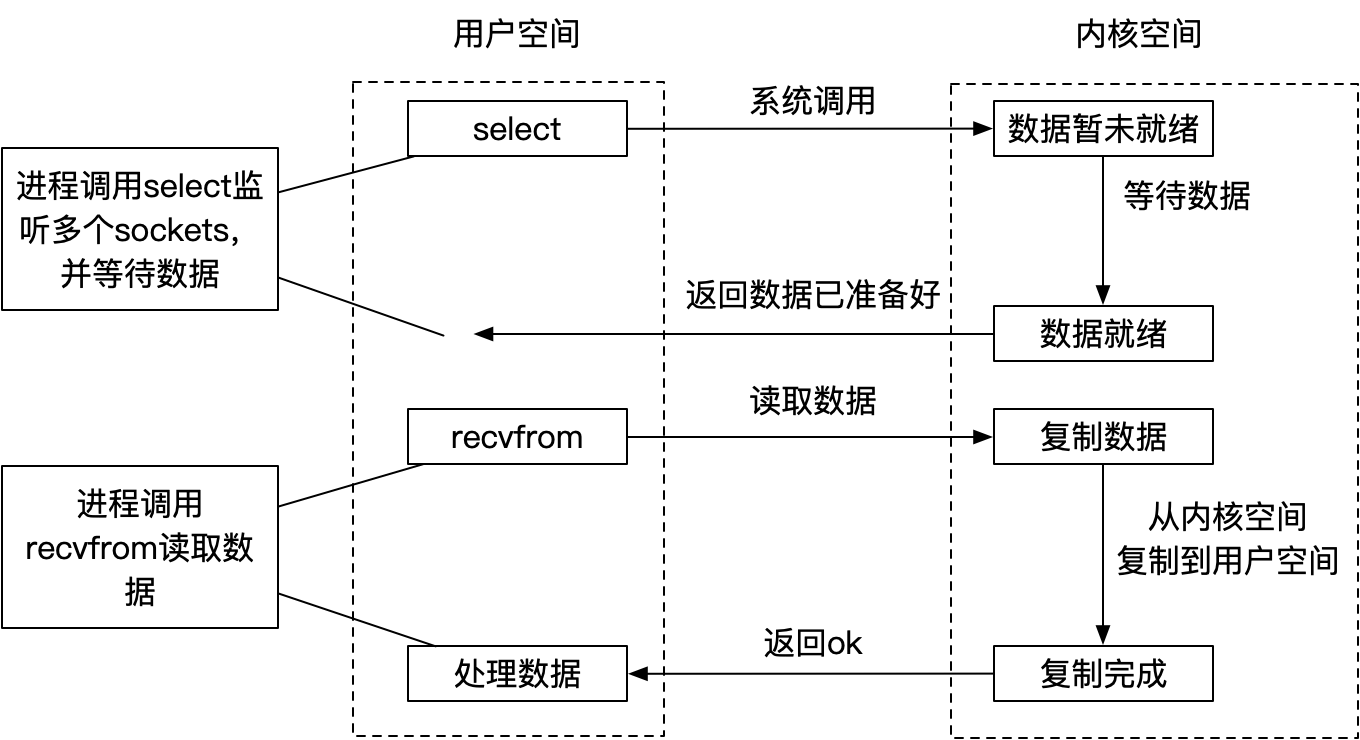
在 IO 多路复用机制下,当没有 IO 事件发生时,调用会阻塞进程等待,直到至少有一个文件描述符准备好进行读写操作为止。一旦某个文件描述符就绪(例如有数据可读或可写),系统会立即通知应用程序,并返回所有准备好的文件描述符列表,然后应用程序就可以针对性地对这些已就绪的文件描述符进行相应的读取或写入操作。
以下是 IO 多路复用常见的系统调用实现方式:
-
select:能够同时监控多个文件描述符的读写状态,但其性能受限于内核硬编码的最大文件描述符数,并且每次调用都需要将所有监视的文件描述符复制到内核空间,随着连接数增加,效率逐渐降低。 -
poll:类似于select,但去除了最大文件描述符数量的限制,采用链表结构存储待监控的文件描述符集合,但仍存在需要遍历整个集合来确定就绪文件描述符的问题。 -
epoll( Linux 系统):相较于select和poll,它提供了更高效的解决方案。epoll使用事件驱动的方式,在内核中维护了一个红黑树结构来管理待监控的文件描述符,仅返回真正有事件发生的文件描述符,从而避免了无谓的循环扫描,极大地提升了大规模并发连接下的性能。
IO多路复用的优势在于:
- 有效地利用系统资源,减少上下文切换。
- 在高并发场景下能够更好地扩展,适合构建高性能服务器应用。
3.1 select
select 是一个在许多操作系统中(包括Unix和Windows)广泛使用的I/O多路复用技术,它允许单个进程或线程同时监控多个文件描述符的读写事件。在处理网络编程时,特别是在服务器端需要管理大量并发连接的情况下,select 能够有效地监听多个套接字(socket)的状态变化,从而避免为每个连接创建单独的线程或进程。
基本原理与使用流程:
-
初始化:
- 程序首先调用
fd_set结构体来维护一组待监控的文件描述符集合,通常分为三类:读就绪、写就绪和异常就绪。
- 程序首先调用
-
添加监控:
- 使用
FD_SET函数将需要监控的套接字加入到相应的fd_set集合中。
- 使用
-
调用 select 函数:
- 函数原型通常如下:
参数含义:int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);nfds:一般设置为所有待监控文件描述符中的最大值加1。readfds:指向读操作就绪的文件描述符集合。writefds:指向写操作就绪的文件描述符集合。exceptfds:指向异常就绪(如错误条件)的文件描述符集合。timeout:指定等待超时时间或者设置为NULL表示无限制等待。
- 函数原型通常如下:
-
阻塞等待:
- 当调用
select时,如果没有任何文件描述符准备好,函数会阻塞直到至少有一个描述符变为可读、可写或发生异常,或者到达了指定的超时时间。
- 当调用
-
检查结果:
select返回后,程序通过FD_ISSET函数检查各个集合,找出哪些文件描述符已经准备就绪进行读取、写入或其他操作。
-
执行对应操作:
- 对于检测到已就绪的文件描述符,程序可以立即进行读取或写入等相应操作。
-
循环处理:
- 往往在一个无限循环中重复上述步骤,以持续监控并处理新的IO事件。
缺点:
select的性能瓶颈在于每次调用都需要将整个监视集复制到内核空间,并且随着被监控的文件描述符数量的增长,效率会急剧下降。- 它有硬编码的最大文件描述符数量限制,大小固定为1024,在一些系统上可能不够用。
- 对于大型的连接数,即使没有事件发生,
select在返回时仍然需要遍历整个描述符集合,这在高并发情况下是低效的。
3.2 poll
poll 是对 select 函数的改进版,用于解决同时监控多个文件描述符(如网络套接字)的读写事件问题。与 select 相似,poll 允许程序在单个线程中等待多个文件描述符中的任何一个变为可读或可写状态,从而避免了为每个连接创建单独的线程或进程所带来的资源开销。
基本原理与使用流程:
-
初始化:
- 使用
struct pollfd结构体数组来定义待监控的文件描述符集合,每个结构体成员包含一个文件描述符及其关注的事件类型(POLLIN、POLLOUT等)。
- 使用
-
添加监控:
- 将需要监控的文件描述符及其事件类型填充到
pollfd结构体数组中。
- 将需要监控的文件描述符及其事件类型填充到
-
调用 poll 函数:
- 函数原型如下:
参数含义:int poll(struct pollfd *fds, nfds_t nfds, int timeout);fds:指向struct pollfd结构体数组的指针。nfds:数组中元素的数量,即要监控的文件描述符总数。timeout:超时时间(毫秒),负数表示无限等待,0表示立即返回当前状态而不阻塞。
- 函数原型如下:
-
阻塞等待:
- 当调用
poll时,如果没有文件描述符就绪,函数将阻塞直到至少有一个描述符变为可读、可写或其他指定的状态,或者达到指定的超时时间。
- 当调用
-
检查结果:
poll返回后,通过查看pollfd结构体数组中每个元素的revents成员,确定哪些文件描述符发生了关注的事件。
-
执行操作:
- 对于检测到已就绪的文件描述符,可以进行相应的读取或写入操作。
优缺点:
优点:
- 不再受
FD_SETSIZE的限制,poll 在内核中采用链表,理论上能够处理任意数量的文件描述符。 - 结构化数据管理方式比
select更加灵活和易于理解。
缺点:
- 虽然相比
select解决了最大文件描述符数量的问题,但仍然存在效率上的瓶颈,因为每次调用poll都会遍历整个待监控的文件描述符列表,即使没有事件发生。
相较于更高级的 epoll 机制,poll 在处理大量并发连接时性能相对较差,因为它同样不具备高效的内核事件通知机制。epoll 使用了一种更为优化的方法来跟踪和报告就绪的文件描述符,因此在高并发场景下,epoll 常被推荐作为首选的 I/O 多路复用技术。
下一篇会继续介绍 epoll 的相关内容。
4. 参考
《redis 从0到1完整学习 (一):安装&初识 redis》
《redis 从0到1完整学习 (二):redis 常用命令》
《redis 从0到1完整学习 (三):redis 数据结构》
《redis 从0到1完整学习 (四):字符串 SDS 数据结构》
《redis 从0到1完整学习 (五):集合 IntSet 数据结构》
《redis 从0到1完整学习 (六):Hash 表数据结构》
《redis 从0到1完整学习 (七):ZipList 数据结构》
《redis 从0到1完整学习 (八):QuickList 数据结构》
《redis 从0到1完整学习 (九):SkipList 数据结构》
《redis 从0到1完整学习 (十):RedisObject 数据结构》
《redis 从0到1完整学习 (十一):RedisObject 之 String 类型》
《redis 从0到1完整学习 (十二):RedisObject 之 List 类型》
《redis 从0到1完整学习 (十三):RedisObject 之 Set 类型》
《redis 从0到1完整学习 (十四):RedisObject 之 ZSet 类型》
《redis 从0到1完整学习 (十五):RedisObject 之 Hash 类型》
《redis 从0到1完整学习 (十六):内存回收之 key 过期处理策略》
《redis 从0到1完整学习 (十七):内存回收之内存淘汰策略》
《redis 从0到1完整学习 (十八):阻塞/非阻塞 IO》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
也欢迎关注我的wx公众号:一个比特定乾坤
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 产品经理必看 使用说明书的制作策略
- 找不到api-mswin-crt-runtime-|1-1-0.dll的修复方法解析
- 已解决Error:AttributeError: module ‘numpy‘ has no attribute ‘complex‘
- 钟馗之眼ZoomEye
- 如何写出csdn博客中包含前置可跳转目录的博文
- CGAL 过滤三角网算法求取凹包面积
- OpenAI 网站上的关于 API 文档中各菜单的结构介绍
- 外汇交易中的“滑点”是什么?
- Java项目:156SpringBoot Vue的生鲜商城系统
- java8实战 lambda表达式、函数式接口、方法引用双冒号(中)