R语言数据探索和分析2-人口统计信息聚类分析
1.数据介绍
本文提供的数据包含了不同地区的人口统计信息,这些数据来自于统计局,本文针对这些数据用于进行聚类分析。数据中的特征包括地区名称、人口总数、出生率、死亡率、性别比例、老龄化比例以及青少年比例等。
读取数据
library(ggplot2)
library(stats)
data <- read.csv("data.csv")
data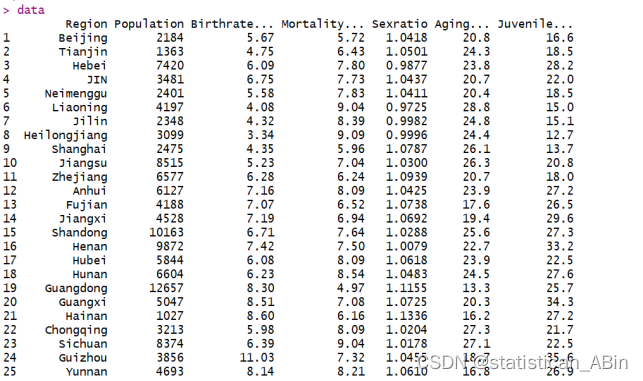
从上面可以看到,横向依次是2022年人口总数,出生率,死亡率,性别比,老龄占比,少年占比,纵向为各个省份。
2.人口数据结构分析
str(data)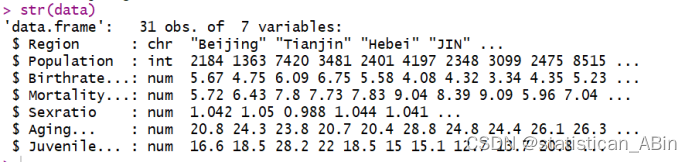
这个输出展示了数据框中包含7个变量(列),包括地区名称、人口数量、出生率、死亡率、性别比例、老龄化比例和青少年比例。每个变量的数据类型也被显示出来,如 int 表示整数,num 表示数值型数据,Factor 表示因子类型等。
使用summary函数获取数据框的汇总统计信息
# 获取数据框的汇总统计信息
summary(data)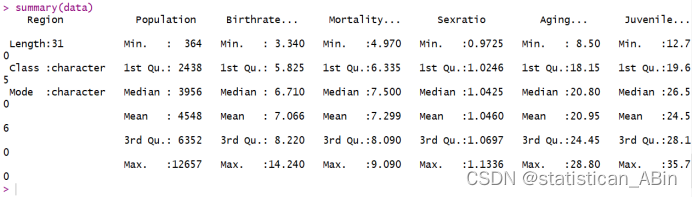
接下来进行可视化:
# 绘制每个特征的箱线图
par(mfrow = c(2, 4)) # 设置画布布局
for (i in 2:7) { # 假设特征是从第二列到第七列
boxplot(data[, i], main = names(data)[i], ylab = names(data)[i]) # 绘制箱线图
} 可以画出每个特征的箱线图,每个箱线图显示了该特征的数据分布情况,其中:箱体:包含了数据的 25% 至 75% 分位数,箱体长度表示数据的分散程度。中位线:位于箱体内部的线表示数据的中位数。须:延伸出箱体的线段(即箱线图上方和下方的线),表示数据的分布范围。
可以画出每个特征的箱线图,每个箱线图显示了该特征的数据分布情况,其中:箱体:包含了数据的 25% 至 75% 分位数,箱体长度表示数据的分散程度。中位线:位于箱体内部的线表示数据的中位数。须:延伸出箱体的线段(即箱线图上方和下方的线),表示数据的分布范围。
# 创建散点图矩阵
# 绘制每个特征的散点图矩阵
pairs(data[, 2:7], main = "Scatterplot Matrix of Features") # 假设特征是从第二列到第七列
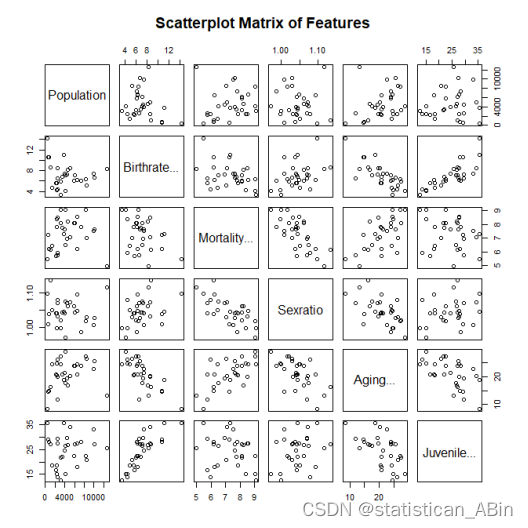
散点图矩阵中,对角线是每个特征的直方图,非对角线上的图表是两两特征之间的散点图。从图上可以看出,大多都是非线性关系。同时,也能绘制热力图,来看哥哥特征之间的关系。
# 计算特征之间的相关系数矩阵
correlation_matrix <- cor(data[, 2:7]) # 假设特征是从第二列到第七列
# 创建特征之间的热力图
heatmap(correlation_matrix,
Colv = NA, Rowv = NA,
xlab = "Features", ylab = "Features",
main = "Heatmap of Feature Correlations")
热力图以颜色的不同深浅来表示特征之间的相关性,颜色越深表示相关性越高,颜色越浅表示相关性越低。对角线上一般会是深色,因为特征与自身的相关性为最高,所以通常不会进行聚类。
3.聚类分析
本文选择k均值聚类K均值聚类(K-means clustering)是一种常用的无监督学习算法,它将数据集分成K个簇,其中每个样本属于与其最近的均值(质心)所代表的簇。
features_for_clustering <- data[, 2:7]
# 对数据进行标准化(可选,但通常在聚类前会进行)
scaled_features <- scale(features_for_clustering)
# 执行K均值聚类,假设要分成4个簇
k <- 4
kmeans_model <- kmeans(scaled_features, centers = k)
# 聚类结果
cluster_labels <- kmeans_model$cluster
# 将聚类结果添加到原始数据中
data_with_clusters <- cbind(data, Cluster = cluster_labels)
# 显示聚类结果
data_with_clusters
# 显示每个簇的汇总统计信息
print(data_with_clusters)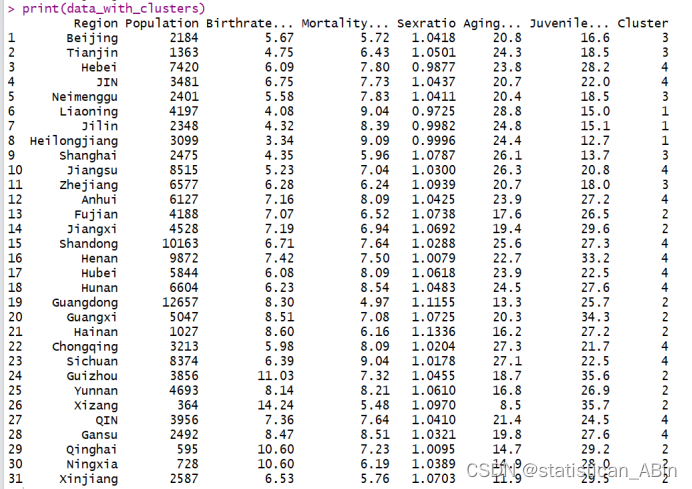
代码中的 features_for_clustering <- data[, 2:7] 将选择数据集中的这些列作为聚类的特征。然后使用K均值算法对这些特征进行聚类,将数据集划分为假设的3个簇。
聚类分析的目的是根据这些特征的数值情况,找到它们之间的相似性,将具有相似特征值模式的样本分为同一簇。聚类的结果将每个样本分配到了某个簇中,并在 Cluster 列中标记了每个样本所属的簇编号。K均值聚类中的K值是一个需要预先设定的超参数,代表着聚类的数量。选择K的值通常是一个挑战,因为并没有一个确定的规则来确定最佳的K值,它通常是基于数据的特点和具体的问题而定的。
要画出聚类结果的可视化图,可以选择两个特征并根据聚类结果对它们进行散点图可视化。以下是一个示例代码,假设你选择了前两列作为特征,并使用ggplot2库进行可视化:
library(ggplot2)
# 假设数据集中的第一列和第二列是你选择的特征列
feature1 <- data_with_clusters[, 6]
feature1
feature2 <- data_with_clusters[, 3]
feature2
# 创建散点图,以特征1和特征2为坐标,使用Cluster列的不同值来区分颜色
ggplot(data_with_clusters, aes(x = feature1, y = feature2, color = factor(Cluster))) +
geom_point() +
labs(x = "Aging(%)", y = "Birthrate", color = "Cluster") +
ggtitle("Cluster Visualization based on Feature 1 and Feature 2") +
theme_minimal()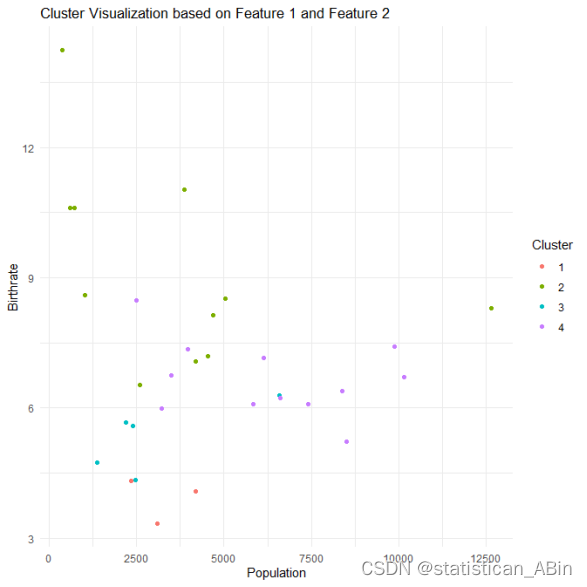
这段代码创建了一个散点图,横坐标为第一个特征(人口数量),纵坐标为第二个特征(出生率),不同簇的样本以不同颜色显示。可以从上图看出,根据相应的特征我们将整体分别聚成了4类.可以从上面看到,紫色第四类分布最为广泛,其次是绿色、蓝色和红色。
总结
针对这个案例,涉及对中国各地区的人口统计数据进行聚类分析。通过分析人口数量、出生率、死亡率、性别比例、老龄化比例以及青少年比例等特征,可以获得一些有趣的启示和结论:
区域特征差异:中国各地区在人口统计特征上存在明显的差异。不同省份可能有不同的人口数量、出生率和死亡率等数据,这反映了各地区的经济、文化、教育和社会发展状况的差异。聚类分析:通过聚类分析可以将地区进行分类,从而辅助了解地区之间的相似性和差异性。聚类分析是一种利用数据进行洞察和决策支持的强大工具。通过深入分析人口数据,可以为政府、社会组织和企业等提供关键信息,从而更好地服务社会。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java开发的常见报错
- 外汇天眼:LCH RepoClear SA推出新的€GCPlus普通抵押品清算服务
- Java八股文面试全套真题【含答案】- Elasticsearch篇
- AnyText多语言文字生成与编辑模型——让AI绘图自由添加精美文字
- 深度优先和广度优先
- 如何利用烛龙和谷歌插件优化CLS(累积布局偏移) | 京东云技术团队
- Leetcode242有效的字母异位词(java实现,详细易懂想学会的进!!!)
- 深度解析运维工程师职业发展:技能提升、行业趋势与未来出路
- 黑马头条--day04--文章审核
- shell 编程中内置的变量(冷门又好用)